目录
一、为什么会有类加载机制
二、类加载机制原理是什么
1、什么是类加载器:宏观
2、类加载器工作原理
1、装载
2、链接
3、初始化
3、何为装载的机制:微观
4、上面既然我们已经知道了啥是双亲委派了,那么怎么去破坏呢?
三、类加载机制分析
1、类加载
1、那么何为对应的区域?
2、为什么是静态存储结构?
2、链接
1、验证
2、准备
3、解析
3、何为初始化?
四、运行时数据区
1、运行时常量池
2、虚拟机stacks
3、本地方法栈
4、寄存器pcthe pc register
五、总结
六、详聊运行时数据区
1、方法区(Meathod Area)
2、堆(heap)
3、Java虚拟机栈
4、总结
七、聊聊官网没有介绍的
1、方法区
2、运行时数据区与内存模型
3、java虚拟机栈,执行方法的时候,到底经历了什么?
一、为什么会有类加载机制
我们首先从jdk组成开始切入,再到jdk在java中作用,在到jvm中javac过程。
javac(编译)只是做了由源码到类格式的转换,里面的内容并没有进行这样一个变幻,只不过是采用另外一种方式表现出来了。就是转化为 jvm能够识别的格式。
javac:就是做了编译原理方面的事情:词法分析->语法分析->语法树->字节码生成器->class文件。
所以其他编译器只要也按照这个clas格式去编译,那么他也就是能在jvm中去运行。所以此时此刻jvm也是能够运行其他运行语言的代码。
由此而知,这个class就该交给jvm运行了,那么下面我们就可以去看看到底jvm到底干了什么事?
那么class交给jvm你肯定是通过某种机制去交给jvm..所以这一块加载就涉及到:面试常问的“类加载机制。
所以此时我们就知道类加载器他到底是为了干嘛的,为什么要有他?
他发挥的作用其实就是从类文件到jvm这个过程中,它必须有一个这样的机制将我们的class文件交给jvm.这就是我们类加载机制。
所以我们就顺其自然的从class类到类加载机制这一块。
二、类加载机制原理是什么
1、什么是类加载器:宏观
比如我们现在要把生成的class文件通过类加载机制加载到jvm,那么如果使我们自己去实现这个类加载机制。
那么我们会怎么去实现呢?其实就是类加载步骤。
我们不管怎么做,其实他的第一步一定有一个操作:就是他先去找到class类文件的位置。不管你是在磁盘当中,还是网盘当中,还是数据库。
所以第一步我认为他一定是先找到他,就是类文件的全路径。
那么接下来找到之后干什么呢?
找到之后不就是交给jvm吗。但是我们是如何去交的,那么他一定也有一个顺序的。
比如从两个大的维度能看到的是:
第一步肯定是要把类文件信息交给jvm(类文件的所有描述信息,时间信息等等能够交给jvm。让他去存储。)
第二再把类文件所对应的的类文件class对象交给jvm,因为java万事万物都是对象,所有jvm他一定有一个东西去表示对象。
所以这些可以宏观的视为类加载器的装载过程。
2、类加载器工作原理
1、装载
(1).先找到类文件所在的位置
(2).类文件的信息交给jvm
(3).类文件所对应的的class对象交给jvm
这也是我们装载的过程,也就是我们背的类装载机制中第一个内容。就是我们看到图解的第一部分内容。
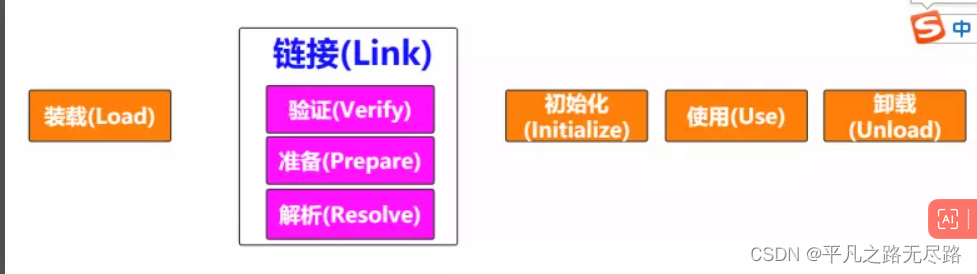
所以然后他就会进入接下来的链接和初始化;他的使用和卸载我们可以不用管他。
所以接下来第二步就是链接
2、链接
他包含三部分:
- 验证
- 准备
- 解析
下面我们会进行对其详细解释。
3、初始化
下面我们会进行对其详细解释。
以上这三个就是类加载机制的的三个过程。
这三步不是凭空想象,是根据官网得知的。
那么再往下走的话,思考一下,往下每一步如何去深究?
简单的来说:第一步我们是去寻找?那么我们该如何是进行寻找类的这一块内容?
实际上java是一个面向对象的开发语言。万物万事皆对象,如果我们要去找类。那么在java中有一个内置的对象可以帮我们去找类。
也就是类加载器classloader,更确切可以称之为类装载器,我们可以通过他来找到类。下面的先不管他。第一步我们就是先去加载去找类。
如果我们是这个类装载器的一个设计者的话,我们该如何去设计他?
我们不可能直接通过这个类装载器classloader.find(类的全路径)直接去查找,因为这样他是无法去管理的。
如果我去设计的,我会对这些类去分门别类,怎么去分门别类呢?
我们认为不同的类装载器应该去装载不同区域的这样一个类。
怎么理解?说白的就是面试中常会被问到的这张图: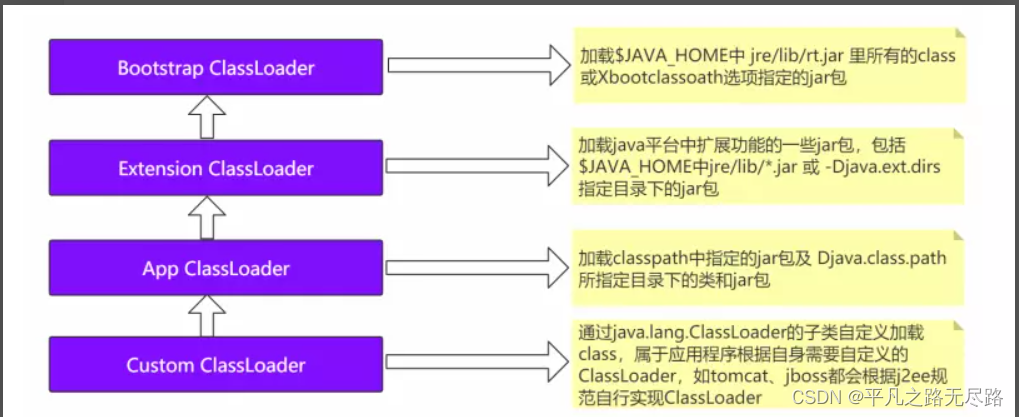
不同的装载器去装载不同目录下的类。
比如说:Bootstrap是我们根的类装载器,他是装载我们系统中rt.jar包下所有的类。就是所谓不同的类去分工别类。然后依次往下,我们可以看到他们分别装载哪些目录下的类。
最下面的一个自定义的类装载器,我们可以根据自己定义按照我们自己的规则去进行相应的装载。
然后这个图我们看了就算了,那么他还有什么点是好聊的吗?
看了看,他还是有些点是可聊的;比如说:装载的机制我们可以来聊一下。
3、何为装载的机制:微观
装载的机制就是:我该如何进行装载;
不就是不同装载器去装载不同目录下的吗?是,看似很假单
但他有一个问题是:当我们在存在同一个完全相同的类的全路径的时候。我该如何去进行装载呢?
也就是说我们jvm中不能存在类的全路径是一样的类了,不然我调用就会出错,比如:我们在系统下的rt.jar包有一个java.long.String这样一个类,那么此时我们自己也创建了一个相同的类。此时此刻就会出现问题了。你装载一个,我又去装载一个此时系统里就会有两全路径完全一个类,当被调用时就会有问题。所以我们要避免全路径名的不能存在两份。所以我们就需要一个机制,也就是说我们装载的时候就不能各干各的。那么怎么做呢?
就是假如说我们在自定义装载器想要去装载某一个类的时候,我自己先不装载,我先去问下我的父装载器,让你去装载,此时他也不装载,他就继续往上,让父节点去装载,同样他也不装载,就是继续往上。直到找到他的一个根节点。让他先去优先去装载一下。看你能不能找到这个全路径的类。如果根节点说它找到了,怎么办,那么此时下面的这些子类就不用装载了。这样就确保我们jvm中只有这样一个全路径的类了。如果没有找到就直接往下,交给他直接的子节点,让他去找。如果他找到,下面同样不用找了。如果没有同理,继续往下去找。直到都没有找到,那就是我自己去装载了。这样就确保了这样一个唯一的全路径的类。
这个也就是我么常说的双亲委派模式
所以我们常说的双亲委派模式就是这个。这个加载我们就可以认为他是双亲委派。不需要弄的明明白白,我们只需要知道:
当我们自己某一个类装载器有一个类的装载请求的话,自己不会去优先装载。而是让顶层的这样一个哥们去装载。直到一层一层的装载不到,我在去进行装载,那么我们就能够去保证他就有一份。
那么这种装载机制我们是否能够去破坏他?
就是说java开发这都是好事之徒;肯定有人不想采用这个装载机制,他去按照自己的方式去实现。
因此就涉及到我们能够去破坏它?所以这也是面试中除了常会被问到的双亲委派常问题,另一大问题,
4、上面既然我们已经知道了啥是双亲委派了,那么怎么去破坏呢?
首先我得要想清楚的一个点就是:
jvm当中,我们jdk是如何实现这个双亲委派的?
我先把这个问题搞清楚之后;我才知道我如何把他去破坏;
我们根据他是如何实现的搞清楚之后,我们自然而然就知道怎么去破坏他。
假入我们是springboot的设计者的话?
我设计的方式就是我的这个类Bootstrap ClassLoader
一定是,有一个loader方法。这个方法里面有一个findParent()方法,就是我先去在我的parent,让他们去加载。如果他没有加载到,再让我自己去加载。
所以他一定会是有这样一段代码。他会去做这样一件事情。
也就是说我们想去破坏他的话,我们只需要去复写他这样一个方法就行了(源码是loadClass()方法;这个方法里面有一个parent.loadClass()去加载父类的方法,所以在此去重写这个方法可以做到)。这是我们可以想到一个思路,当然还有其他的方式:在我们线程层面也能去进行破坏。
至此,我们通过这种方式找到这个类之后呢?如果我们作为jvm的设计者,我们接下会去要怎么设计呢?
三、类加载机制分析
1、类加载
那么接下来是不是把找到的类去交给jvm去运行了。那么问题来了我怎去交呢?我难道要一下子把整个文件全部拿过来吗?这样也不合理,这样不符合我们一个的优秀。我们想要的优秀应该是将class当中的内容按照不同的类别去分门别类的去存储到我们jvm当中。而不是将整个class中的数据全部都放到jvm(此时jvm看做一个整块的内存区域)当中。所以他要去做一个分门别类,那么怎么样去分门别类呢?
如果我是一个设计者的话,我会把jvm这个区域去做相应的划分。想一想是不是应该去划分,划分的目的不就是把class文件的信息去进行打散吗。就是我们类信息放哪?变量放哪?方法放哪?既然我们要去进行打散的话,是不是先要把类文件的信息交给jvm(装载的第二步)。
在交给jvm的同时把类的信息相关信息存在jvm当中,那么我会有一个专业的方式去做,这个方式就是把对应的信息去放入对应的jvm区域当中。
1、那么何为对应的区域?
也就是把类文件字节码流放入静态存储结构。
2、为什么是静态存储结构?
原因是他是一个静止的文本流。这一块我们会放到jvm里面的某一块区域。
这个区域就是我们类的信息的存储的区域:Method Area.就是把我们类文件的信息放入这里面。这是第一点;
第二就是我们类的信息存放在这里面的,那么我们class文件对应的类对像我们该如何去存储?
那么我们认为在jvm当中应该也有一块区域去存储:称为我们一个堆。这就是我们常看到jvm运行时区的一个head:堆。
到这里我们已经划分出两块区域,肯定还有其他区域,暂时先不引出。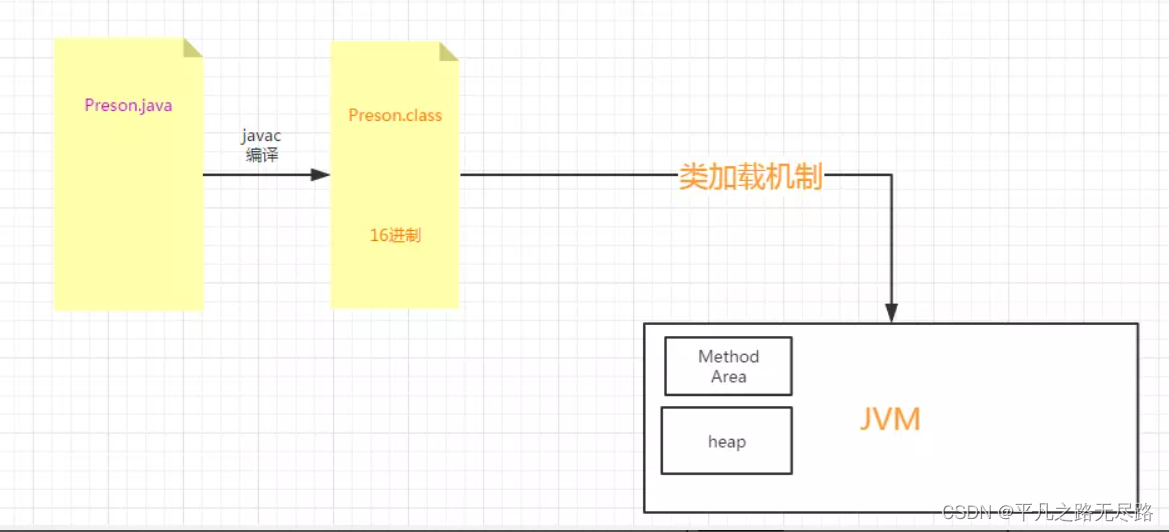
这两块区域也不是我们凭空捏造出来的。而是官网中有对应的说明。
我们从官网可知:方法区他不是存类的属性信息的等等,而是存的是类的,比如文件的创建时间,作者等等这些信息。
上面我们说对象信息他是存在堆里面的,是这样的吗?我们看他官网,继续看:他说堆存的是all class。所以不用说了。
再往下看:那么类加载器中的这个链接呢?
2、链接
1、验证
链接首先就是验证我们的类文件:我们看首先他是怎么验证呢?
保证被加载类的正确性。就是类的格式是不是正确,元数据是不是正确,字节码是不是正确等等。
2、准备
那么链接的第二个阶段是准备;那么何为准备?
重点记住:要为类的静态变量分配内存空间,并将其的值初始化默认值(记住)
比如说:我们class文件有一个静态变量;static int a=10;那么此时到了链接阶段中的准备阶段,他就会为这个静态变量去分配对应的内存空间,然后给这个值默认出化为0.这就是准备阶段需要做的事情。
3、解析
那么何为解析呢?
解析的阶段就是将类中的符号引用转换为直接引用。
那么符号引用和直接引用是什么?我们要去推敲,不然只是记忆,没法有理可据。
符号引用应该讲的就是我们class file format里面的信息,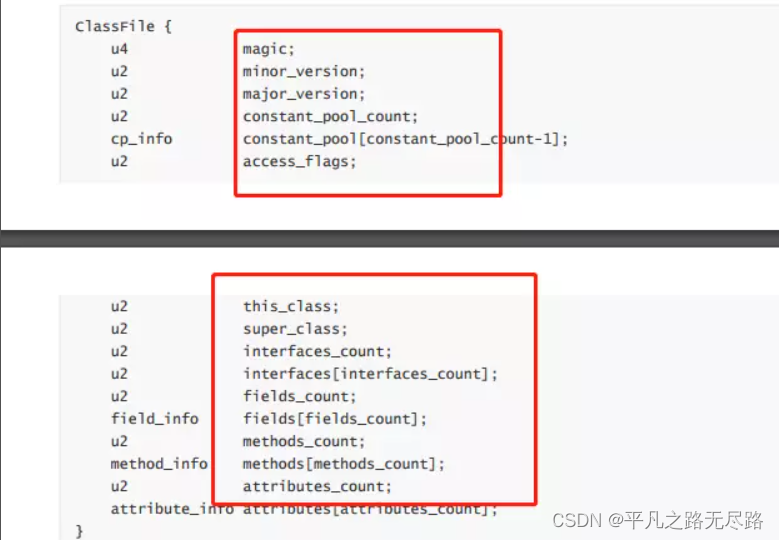
这些就是我们的符号引用,符号引用是因为我们class文件里面存的还是这个状态,这个class文件格式的规范,只是一个符号的表示,跟我们的内存没有关系(存储在jvm什么地方),他只是说你在我class文件里面叫什么,那么这些符号引用到了内存当中我要把他编变成直接引用。这就是说明了原来我在class中代表的是String str[ace0 flag]=这样一个地址或符号,那么它就是对应j内存中某一个真实的地址指向了;就是说在class文件他只是一个代称,class能认识就行了,那么现在到真正内存中了,你就要被别调用被赋值了嘛,就是需要真正的某个地址了嘛(简单说把符号转化为内存需要引用的内存地址)。
所以我要做的的事情就是他这个符号引用转化为直接引用。
这个直接引用就是我们在java当中能看到的地址,说白了就是String str= 这个str它所对应的真实的地址是什么。
除此之外,解析还有其他内容,如官网介绍:第 5 章.加载、链接和初始化 (oracle.com)
比如:类与接口解析,接口方法解析,方法类型和方法句柄解析,字段分辨率解析等等
除了上面上面三个检验步骤,他还有另外两个:可自行查看官网
4、访问控制
5、覆盖
3、何为初始化?
是为静态变量初始化真正的值。上面那个a就会真正的被赋值为a=10.
至此我们Person类就经过我们类加载机制了,现在已经到达了jvm.
那么如我们是jvm设计者,jvm这个快区域需要怎么设计呢?我们前面已经讲到,他已经分出了两块区域了
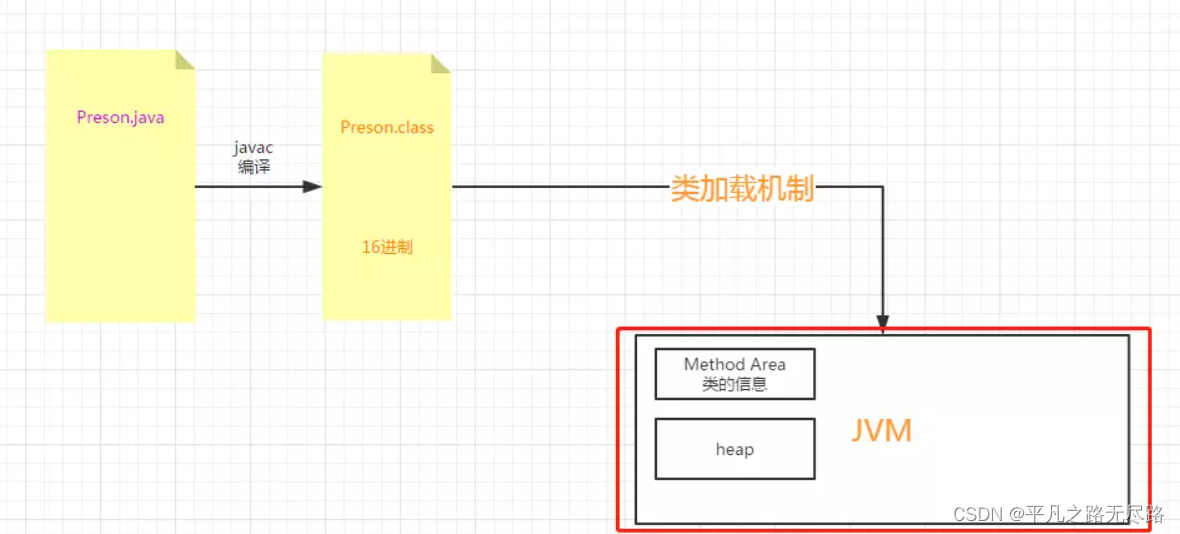 我们走到这里看到的结果就是看到我们类的信息和堆的信息分别再两块内存当中。
我们走到这里看到的结果就是看到我们类的信息和堆的信息分别再两块内存当中。
如果我认为我这jvm这一块区域的设计者的话,这个地方我该如何设计?
我们看官网,他的运行时数据区不仅上面分的两块:
所以接下来就是看看他这一块的运行时数据区。
四、运行时数据区
在装载阶段的第(2),(3)步可以发现有运行时数据,堆,方法区等名词
(2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
(3)在Java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口 说白了就是类文件被类装载器装载进来之后,类中的内容(比如变量,常量,方法,对象等这些数 据得要有个去处,也就是要存储起来,存储的位置肯定是在JVM中有对应的空间)
这个运行时方法区不仅涉及到上面这两块,他还有其他四个区域。所以这个时候我们就来到了运行时数据区。如官网:第 2 章。Java 虚拟机的结构 (oracle.com)
那么我们应该先看哪一个呢?
关于方法区和堆我们已经讲过他的来通去脉,所以接下来我们先看剩下的几个
1、运行时常量池
根据官网来看:我们会看到一句话:每一个运行时常量池是从java虚拟机的方法区所去进行分配的,这是jdk8版本的官网描述。
我们按照这句话来理解的话,运行时常量池应该是在我们的方法区里面。
就变成了这样了
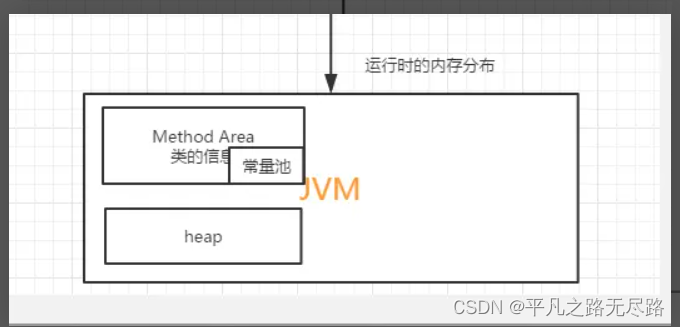
我们根据官网看他还有两个管stacks栈的描述:
2、虚拟机stacks
它是一种数据结构,这种数据结构他有一个特点就是:先进后出,或者后进先出。
这个东西是干嘛的呢?
我是这么来理解的:jvm的一个设计者他认为,我们类的信息存在我们的方法区了,我们类的常量也存在这里面了,我们对照我们类文件去看,这里面我们该存的都存了,这是不是除了存储一些数据的话,是不是还要存储其他数据或者他的灵魂,这里面的灵魂是应该是他方法的执行,或者说java每一个线程去调用方法去执行才是进程间的灵魂。不执行方法的话我们这个还有什么么意义呢?
那么方法的执行与否,方法被线程调用与否的话,这种关系在我们的运行时数据区,如果你仅仅是一个存储的结构的话,好像不能够去表示。既然这样,我去设计一个栈出来。这个栈呢就代表是一个线程。是要去表示一个方法的执行的话没我就设计一个栈。线程中每一个方法就是我们这个栈里面存储的元素了。就是有一个方法被执行了就把方法压入栈里面,又有一个方法就在把这个方法压入栈里面。依次往下。然后有一个方法被执行完,他就去出栈,执行完就是出栈,
所以从这里面我们可以去感受到 ,为什么会有一个栈的设计。
实际上他解决的问题应该是:线程执行方法的表示
这是我们简单的一个了解,先不去深入。
那么为题来了?具体是这样的吗?
我们看官网:说每一个java线程都有一个java虚拟机栈,他的创建时机,就是在这个线程被创建的时候就会去创建一个虚拟机栈。他的每一个栈存的就是我们方法执行。
所以在我么jvm内存分布中又多了一快区域:java虚拟机栈
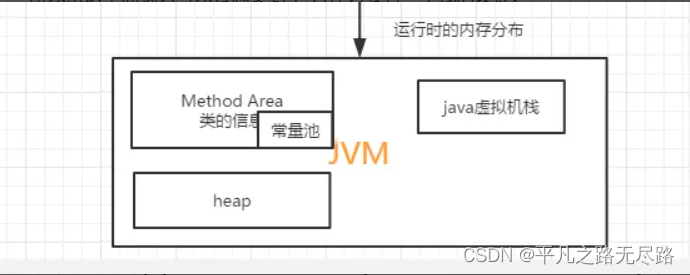
所以我们认为这个是能够理解的。此时我们会有一个不经意的想法:就是如果我们java 方法是基于java虚拟机栈去表示的,如果我java去调用c语言代码的话,那么我是不是也应该有一个类似于虚拟机栈呢?这就是我们所说的native method stacks本地方法栈
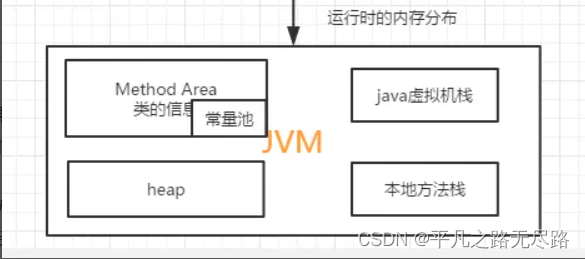
3、本地方法栈
根据官网可知:本地方法栈就是调用C语言的这个栈。C语言实现的栈策存储结构就跟java实现方式是差不多的。他就可以类比我们java虚拟机栈去学习。
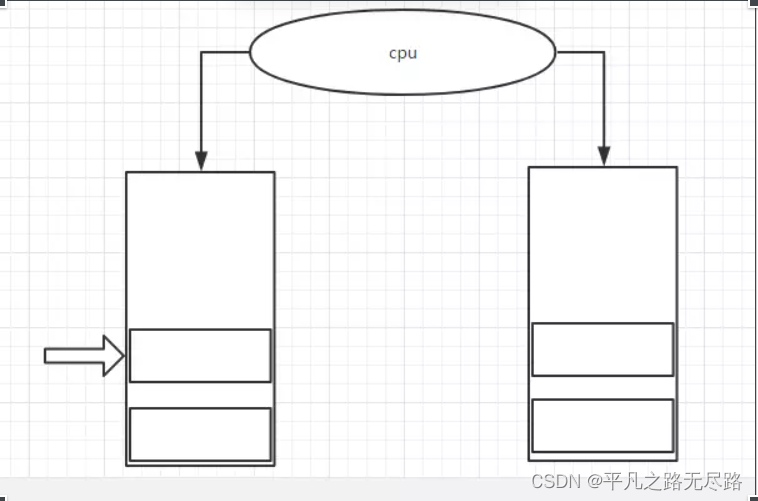
如果说现在我们有两个线程,这两个线程都有各自的java虚拟机栈,那每一个线程都会去调用方法的话,那么这个栈针就会去相应的去压栈。当这两个线程不断去调用方法,就会不断的去压栈。此时就会出现一个问题:
因为此时我们会有一个大大的cpu给我们每一个线程一个相应的资源,会有一个相应的执行权,当我们cpu执行到了虚拟机栈的A栈针(方法)的地方之后,此时失去了执行调度,我就会去执行另一个虚拟机栈,当我们第一个虚拟机栈再次获取一个调度执行权的时候,我是不是还需要从A栈针这个地方去继续执行。如果我要去继续从这个地方去执行,那么我就要去保存记录我刚刚失去cpu资源方法所执行的这个地方。
所以在整个运行时数据区中他应还有一个数据区域,代表着记录每一个线程继续执行方法所在的位置。这就是我们所说的 the pc register
4、寄存器pcthe pc register
何为 the pc register?我们看官网就知道:一个java进程可以支持非常多的java线程,每一个java线程都有一个自己独立的一个pc register,他的作用是什么?他是为了进行记录当前方法正在执行所在的这样一个位置。那么这个时候我们就认为这个就有存在的必要了。
这样就可以把我们看到的六块区域划分为5块区域。
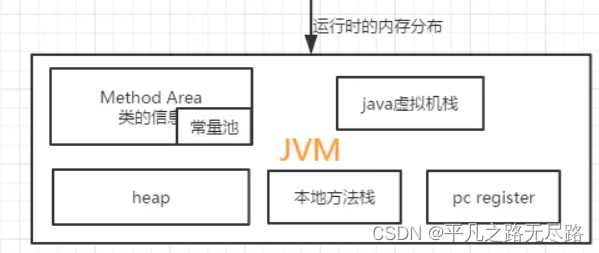
到这里我们就对整体有了一个认知。
五、总结
所以总结他整个流程图就是这样的:
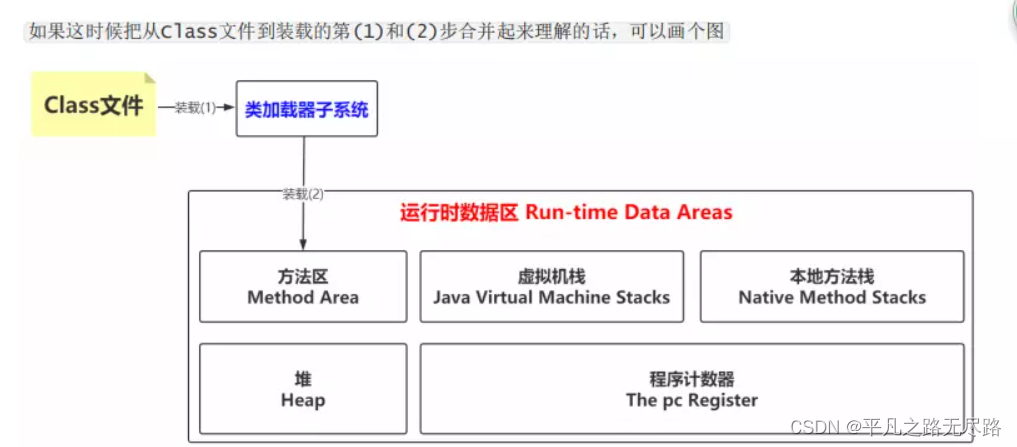
值得说明的
(1)方法区在JDK 8中就是Metaspace,在JDK6或7中就是Perm Space
(2)Run-Time Constant Pool
Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池,用于存放编译时期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
Each run-time constant pool is allocated from the Java Virtual Machine's method
area (§2.5.4).s
至此我们java 类如何到jvm的我们已经聊完了。现在我们就可以去真正的聊聊jvm这里面的东西了。
六、详聊运行时数据区
那么我们有必要去详聊吗?那么详聊什么?

这就是我们详聊的运行时数据区。但是我还是有点忐忑。为什么?
因为我们要学习jvm到底要学习什么呢?
我认为上面这张图是需要学习的,当我们把这张图学完之后,我们把数据不断的往里面去放,就会有内存空间不断的去使用,不够用的时候我就会去形成去做回收。那么我们就要去垃圾回收机制,垃圾回收机制这时候就要对应的就是看垃圾回收算法。就要有对应的垃圾收集器。
那么怎么回收?怎么去看我们垃圾回收日志?这不就我们需要学习jvm的内容的吗?
所以我们现在慢慢来,慢慢的往下推:
那么我们先想象,我们到底应该先看哪一个呢?
我们看左上角的方法区好像可以值得探究:
根据官网来看:首先看运行时数据区的讲解,是说有些数据区是根我们jvm一个生面周期的,随着jvm的创建而创建,销毁而销毁。有些是根据线程一个额生面周期的。所以这就涉及到了线程的安全性和不安全性问题。
那么我先来看方法区:
1、方法区(Meathod Area)
我们之前认知或者说对于方法区的一个理解来说;只保留在他保存类的这样一个信息,是在装载阶段的第二个阶段。
1、首先我们会看到一点是(生命周期):每一个java虚拟机只有一个方法区,而这一个方法区是被所有的线程去共享的。
从而我们得到的结论就是:方法区只有一个,线程共享的内存区域, 也就是【线程非安全】,生命周期是跟虚拟机一样的。
这就是我们而根据官网一句话得出来的结论。
2、然后继续看官网第二句描述;说方法区所存储的就是:类信息、常量、静态变量、还有及时编译器编译之后的代码。
所以我们就看到,除了类型信息,他的常量,静态变量也是存在里面的。
3、在继续往先看看官网,说方法区逻辑上是属于堆的一部分,然后垃圾回收不太会去讨论方法区的垃圾回收,虽然他也会存在垃圾回收,但是一般情况下,垃圾回收不会去讨论这块区域。
4、继续往下看说,当我们这些信息继续往方法区中去存,当他不够存了,他就会抱一个内存溢出的错误。
我们从上面来接可以清楚就从官网了解就可以知道他的一些特性。现在我们而对方法区有一个了解之后我们在去看堆这样一个信息。
2、堆(heap)
那么何为堆?
根据官网介绍。
1、首先第一句说:堆也是所有线程共享的。说白的就是堆只有一个,线程共享的内存区域, 也就是【线程非安全】,生命周期是跟虚拟机一样的。
2、第二句话:也就是说它存储我们的class对象或数据会在这里面去进行分配。
3、再往下看,也会看到当他的内存不够了,他也会发生一个oom内存溢出。
所以的我们oom不仅是我们堆内存会发生,我们的方法区也会发生,
然后我们就此了结之后再往下看,我们在往下看发现就是线程私有的了
3、Java虚拟机栈
这一个就比较好理解,他就是来存储线程所对应的的栈,然后栈里面去存储我们的栈针吗。
那么比如说我有一个方法在调用执行,那么该怎么去表示呢?
假如说,我a方法调用b方法,b方法调用c方法,。那么此时此刻我们该怎么去用栈表示呢?
如图所示:
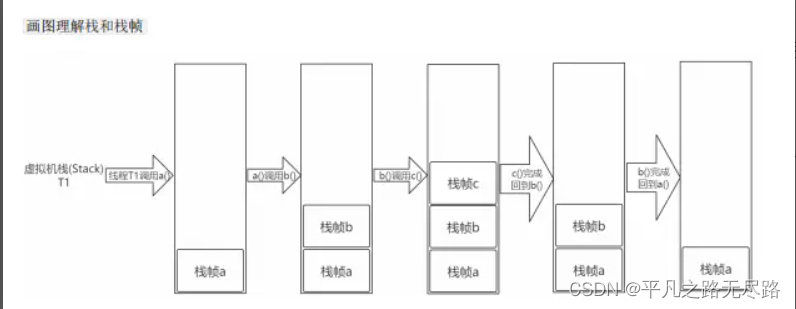
就是说我们有一个线程现在去调用a,当a没有执行完,他又去调用b了,此时b就会去进行压栈。b又去调用c了。b又会去进行压栈。当着一流程被调用完之后,就会去依次出栈。c执行完,出栈,b去执行,b执行完,a去执行,直到结束。
这就是我们看到java虚拟机栈的一个表现形式。
那么如果说我们去递归调用方法,当我们的栈的深度不够用了的时候,就会报:Stack Overflow。这就是我们看到关于栈匿出的这块情况。
然后我么在继续看,上面运行时数据区的途图中还有什么可以探讨的呢?
我们发现还有两个区域,发现这两个区域就没有什么好研讨的了,
一个是本地方法栈,他是调用c语言的,还有程序计数器,他其实跟我们java开发层面没有太大关系,所以我们了解他是干嘛的就行了。
4、总结
一个线程的创建代表的是一个栈。每一个方法被当前线程调用了,就代表一个栈针。
七、聊聊官网没有介绍的
这些也是我们面试中常会被问到的一下东西;
1、方法区
像方法区里面有一个我们不知道的知识点,而且是常聊的一个e东西:
1.7Jdk(及之前): PermSpace-------永久代
1.8Jdk(及以后) MetaSpace -------元空间
这一块其实并没有什么技术含量,我们只要知道,作为一个了解就可以了,
2、运行时数据区与内存模型
还有一个跟我们面试题相关联的就是:
大家所看到的jvm的运行时数据区,有一个地方我们难免会有一个想法就是运行时数据区和内存模型他们之间的关联是什么?
因为在我们的内存模型也会去讨论我们的一个堆,以及PermSpace和MetaSpace 等。
而这时候我们怎么样去理解呢?
既然有了运行时数据区,那么内存模型【JMM】又是什么?
我们可以这样去理解:
运行时数据区官网对他的一个描述其实是很清晰的:他表述的我们各种数据的一个运行时的状态,也就是说你程序执行的时候,你的数据在jvm中的他的一个运行时的一个状态。总的就是代码运行时的状态。
而所谓的一个java的内存模型,或者所谓的JMM则表示他实际的物理落地的内容。也就是说当我代码不在运行的时候,我此时此刻又是一种什么样的形式区存在?
那么我们就可以把它按照内存模型去划分。
再者说:我们可以这样认为运行时数据区他是jvm层面的事情。而内存模型他是java层面的事情。我们一般去讨论内存模型,一般是去讨论线程的安全与否,因为他去讨论内存模型的话,你会拿主内存和我们的一个工作内存去做一个对比。而这个内存模型真实会把哪两块去拿出来?
就是我们运行数据区中左边共享的两块会拿出来探讨。

所以我们会把内存模型区划分左边的一个MetaSpace ,和右边的这样的一个堆内存。我们可以做这样的一个对应。
这是这两者之间的关系,如果你非要把他们之间进行关联的话,上面这个是我们的JMM内存模型,那么其实我们可以看到他是这样对应的
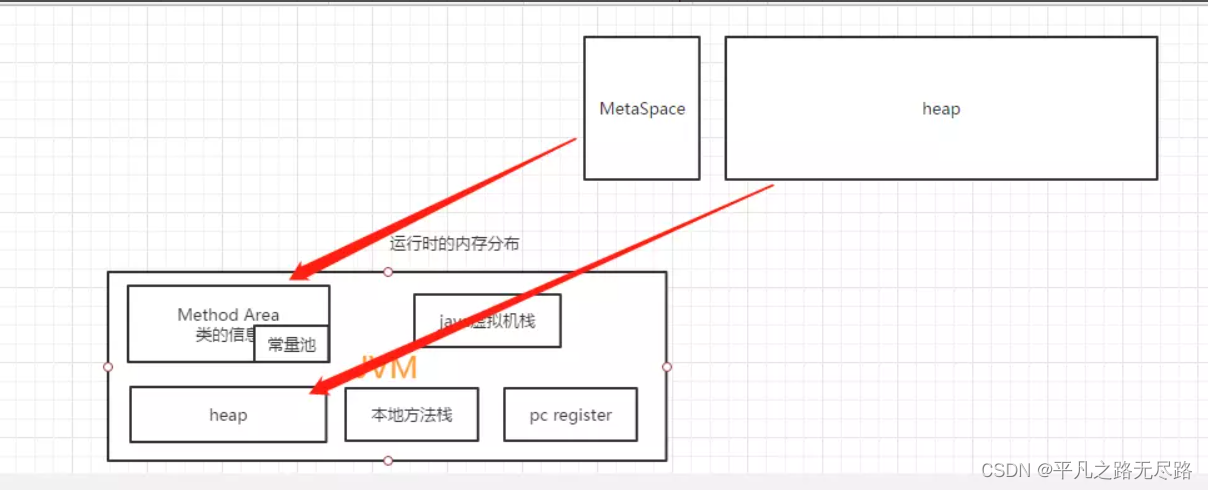
但是一个是表示运行的一个状态,一个是运行后落地的一个额状态。
那么我们为什么不去讨论线程私有的区域呢?
因为线程私有的相对的生命周期都比较短,我们不会再内存模型去做进一步的探讨。
然后回顾一下,我们上面没有细聊的有哪一块,我们发现堆和方法区都做了详细的探讨,或者后面会花大量时间去探讨,所以就发现虚拟机栈没有太多的探讨。只是看了方法的压栈过程
所以接下来我们会去探讨:
3、java虚拟机栈,执行方法的时候,到底经历了什么?
这就涉及到我们平时对java class文件进行反编译的时候,看到的字节码指令,这字节码指令就对应java虚拟机栈执行的过程。
那么怎么去理解?
我们查看class文件的方式除了查看16进制的方式还可以进行javap- c class文件进行查看class文件的方式。
然后我们打开看,他就是一个字节码指令。
那么何为字节码指令,坦白的说:他描述的你这个类文件他在虚拟机当中他的这样一个每一步的一个状态是干嘛的。
这个字节码指令我们看不懂,但是有人能看懂,那就是jvm官方文档。爪哇SE规范 (oracle.com)
JVM-java对象内存分布(二)_平凡之路无尽路的博客-CSDN博客

![[CVPR 2023] Imagic:使用扩散模型进行基于文本的真实图像编辑](https://img-blog.csdnimg.cn/img_convert/5c990ea9f7674e7e1bab2c127615339c.png)