10. 广播变量
10.1 广播变量的使用场景
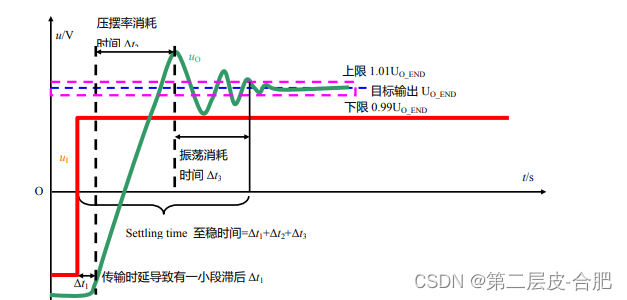
在很多计算场景,经常会遇到两个RDD进行JOIN,如果一个RDD对应的数据比较大,一个RDD对应的数据比较小,如果使用JOIN,那么会shuffle,导致效率变低。广播变量就是将相对较小的数据,先收集到Driver,然后再通过网络广播到属于该Application对应的每个Executor中,以后处理大量数据对应的RDD关联数据,就不用shuffle了,而是直接在内存中关联已经广播好的数据,即通实现mapside join,可以将Driver端的数据广播到属于该application的Executor,然后通过Driver广播变量返回的引用,获取实现广播到Executor的数据
广播变量的特点:广播出去的数据就无法在改变了,在没有Executor中是只读的操作,在每个Executor中,多个Task使用一份广播变量
10.2 广播变量的实现原理
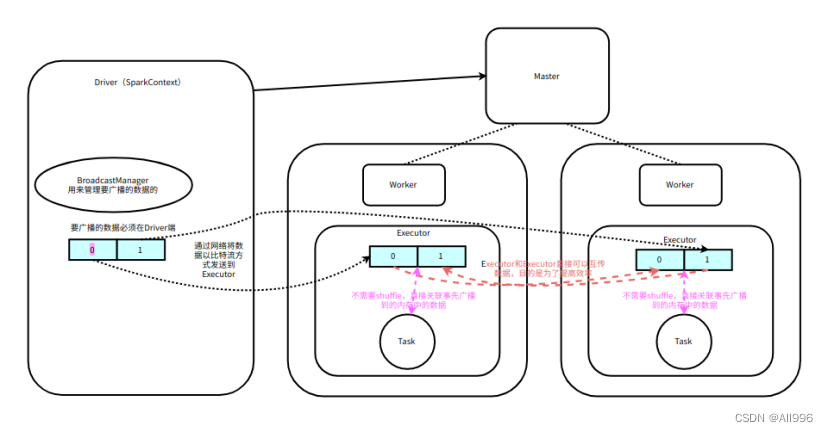
广播变量是通过BT的方式广播的(TorrentBroadcast),多个Executor可以相互传递数据,可以提高效率
sc.broadcast这个方法是阻塞的(同步的)
广播变量一但广播出去就不能改变,为了以后可以定期的改变要关联的数据,可以定义一个object[单例对象],在函数内使用,并且加一个定时器,然后定期更新数据
广播到Executor的数据,可以在Driver获取到引用,然后这个引用会伴随着每一个Task发送到Executor,然后通过这个引用,获取到事先广播好的数据
10.3 案例:根据IP计算归属地
10.3.1 需求
根据IP规则数据,计算出给定日志中ip地址对应的省份信息,由于IP地址的规则数据相对较小,所以可以将IP规则数据先广播出去,以后关联IP规则数据,就可以在内存中进行关联了,这样可以避免shuffle,提高执行效率!
10.3.2 代码实现
11. 序列化问题
11.1 序列化问题的场景
spark任务在执行过程中,由于编写的程序不当,任务在执行时,会出序列化问题,通常有以下两种情况,
- 封装数据的Bean没有实现序列化接口(Task已经生成了),在ShuffleWirte之前要将数据溢写磁盘,会抛出异常
- 函数闭包问题,即函数的内部,使用到了外部没有实现序列化的引用(Task没有生成)
11.2 数据Bean未实现序列化接口
spark在运算过程中,由于很多场景必须要shuffle,即向数据溢写磁盘并且在网络间进行传输,但是由于封装数据的Bean没有实现序列化接口,就会导致出现序列化的错误!
| Scala
object C02_CustomSort {
def main(args: Array[String]): Unit = {
val sc = SparkUtil.getContext(this.getClass.getSimpleName, true)
//使用并行化的方式创建RDD
val lines = sc.parallelize(
List(
"laoduan,38,99.99",
"nianhang,33,99.99",
"laozhao,18,9999.99"
)
)
val tfBoy: RDD[Boy] = lines.map(line => {
val fields = line.split(",")
val name = fields(0)
val age = fields(1).toInt
val fv = fields(2).toDouble
new Boy(name, age, fv) //将数据封装到一个普通的class中
})
implicit val ord = new Ordering[Boy] {
override def compare(x: Boy, y: Boy): Int = {
if (x.fv == y.fv) {
x.age - y.age
} else {
java.lang.Double.compare(y.fv, x.fv)
}
}
}
//sortBy会产生shuffle,如果Boy没有实现序列化接口,Shuffle时会报错
val sorted: RDD[Boy] = tfBoy.sortBy(bean => bean)
val res = sorted.collect()
println(res.toBuffer)
}
}
//如果以后定义bean,建议使用case class
class Boy(val name: String, var age: Int, var fv: Double) //extends Serializable
{
override def toString = s"Boy($name, $age, $fv)"
} |
11.3 函数闭包问题
11.3.1 闭包的现象
在调用RDD的Transformation和Action时,可能会传入自定义的函数,如果函数内部使用到了外部未被序列化的引用,就会报Task无法序列化的错误。原因是spark的Task是在Driver端生成的,并且需要通过网络传输到Executor中,Task本身实现了序列化接口,函数也实现了序列化接口,但是函数内部使用到的外部引用不支持序列化,就会函数导致无法序列化,从而导致Task没法序列化,就无法发送到Executor中了

在调用RDD的Transformation或Action是传入函数,第一步就进行检测,即调用sc的clean方法
为了避免错误,在Driver初始化的object或class必须实现序列化接口,不然会报错误
| Scala
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f) //检测函数是否可以序列化,如果可以直接将函数返回,如果不可以,抛出异常
new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.map(cleanF))
} |
| Scala
private def ensureSerializable(func: AnyRef): Unit = {
try {
if (SparkEnv.get != null) {
//获取spark执行换的的序列化器,如果函数无法序列化,直接抛出异常,程序退出,根本就没有生成Task
SparkEnv.get.closureSerializer.newInstance().serialize(func)
}
} catch {
case ex: Exception => throw new SparkException("Task not serializable", ex)
}
} |
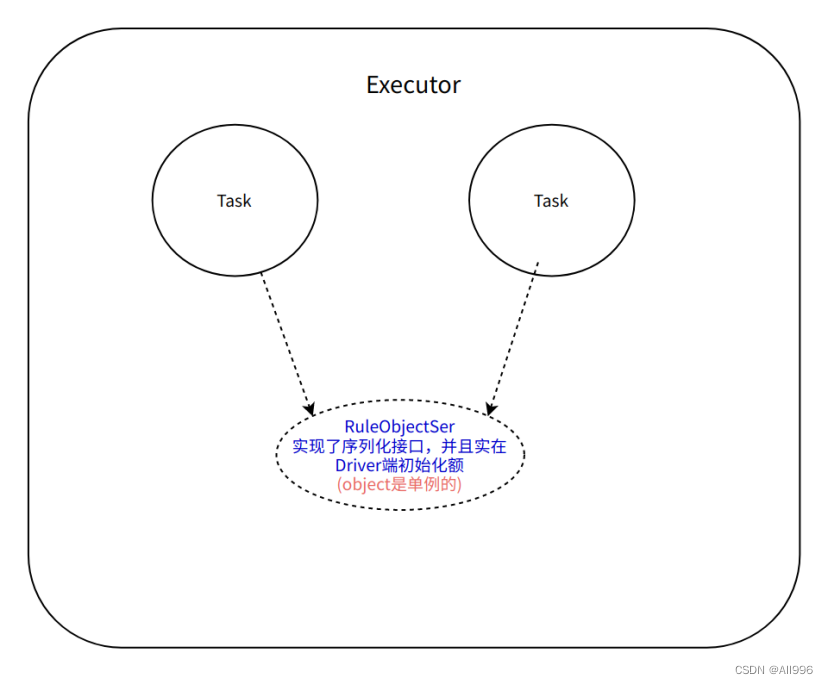
11.3.2 在Driver端初始化实现序列化的object
在一个Executor中,多个Task使用同一个object对象,因为在scala中,object就是单例对象,一个Executor中只有一个实例,Task会反序列化多次,但是引用的单例对象只反序列化一次
| Scala
//从HDFS中读取数据,创建RDD
//HDFS指定的目录中有4个小文件,内容如下:
//1,ln
val lines = sc.textFile(args(1))
//函数外部定义的一个引用类型(变量)
//RuleObjectSer是一个静态对象,实在第一次使用的时候被初始化了(实在Driver被初始化的)
val rulesObj = RuleObjectSer
//函数实在Driver定义的
val func = (line: String) => {
val fields = line.split(",")
val id = fields(0).toInt
val code = fields(1)
val name = rulesObj.rulesMap.getOrElse(code, "未知") //闭包
//获取当前线程ID
val treadId = Thread.currentThread().getId
//获取当前Task对应的分区编号
val partitiondId = TaskContext.getPartitionId()
//获取当前Task运行时的所在机器的主机名
val host = InetAddress.getLocalHost.getHostName
(id, code, name, treadId, partitiondId, host, rulesObj.toString)
}
//处理数据,关联维度
val res = lines.map(func)
res.saveAsTextFile(args(2)) |
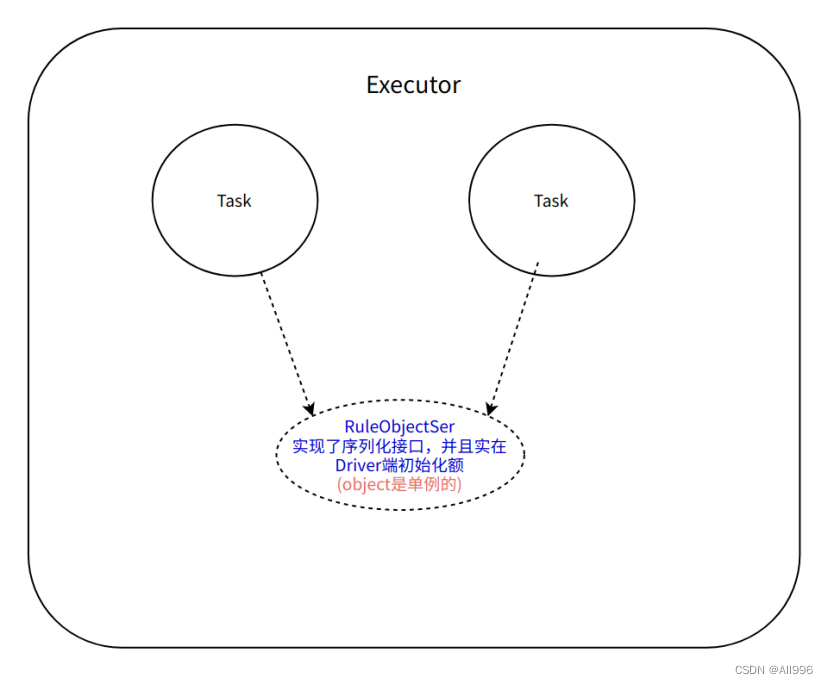
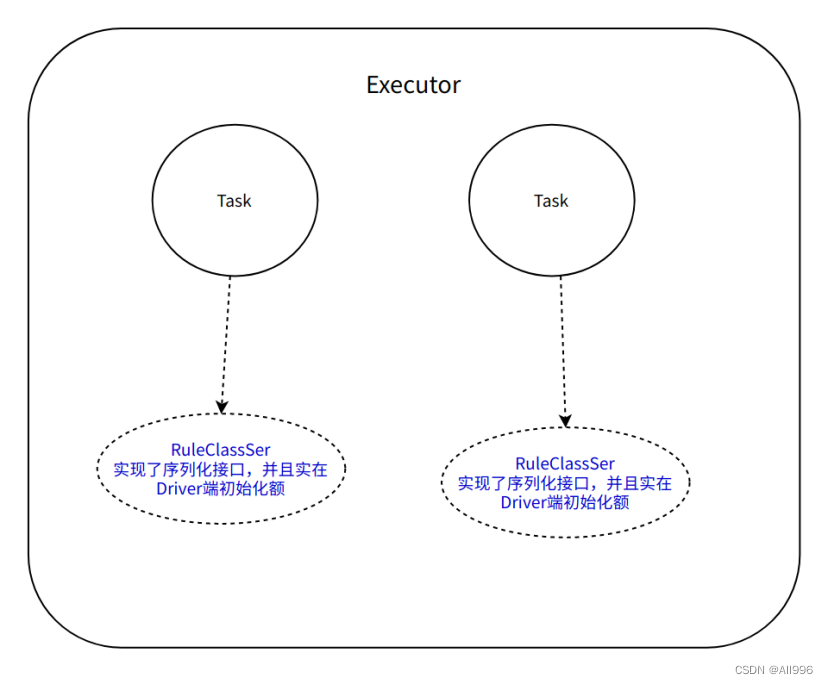
11.3.3 在Driver端初始化实现序列化的class
在一个Executor中,每个Task都会使用自己独享的class实例,因为在scala中,class就是多例,Task会反序列化多次,每个Task引用的class实例也会被序列化
| Scala
//从HDFS中读取数据,创建RDD
//HDFS指定的目录中有4个小文件,内容如下:
//1,ln
val lines = sc.textFile(args(1))
//函数外部定义的一个引用类型(变量)
//RuleClassNotSer是一个类,需要new才能实现(实在Driver被初始化的)
val rulesClass = new RuleClassSer
//处理数据,关联维度
val res = lines.map(e => {
val fields = e.split(",")
val id = fields(0).toInt
val code = fields(1)
val name = rulesClass.rulesMap.getOrElse(code, "未知") //闭包
//获取当前线程ID
val treadId = Thread.currentThread().getId
//获取当前Task对应的分区编号
val partitiondId = TaskContext.getPartitionId()
//获取当前Task运行时的所在机器的主机名
val host = InetAddress.getLocalHost.getHostName
(id, code, name, treadId, partitiondId, host, rulesClass.toString)
})
res.saveAsTextFile(args(2)) |
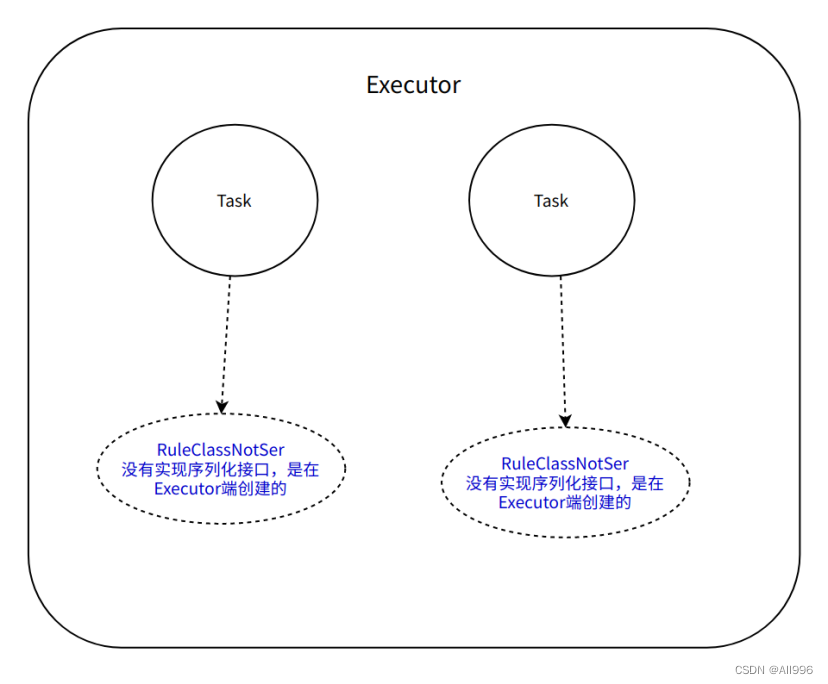
11.3.4 在函数内部初始化未序列化的object
object没有实现序列化接口,不会出现问题,因为该object实现函数内部被初始化的,而不是在Driver初始化的
| Scala
//从HDFS中读取数据,创建RDD
//HDFS指定的目录中有4个小文件,内容如下:
//1,ln
val lines = sc.textFile(args(1))
//不再Driver端初始化RuleObjectSer或RuleClassSer
//函数实在Driver定义的
val func = (line: String) => {
val fields = line.split(",")
val id = fields(0).toInt
val code = fields(1)
//在函数内部初始化没有实现序列化接口的RuleObjectNotSer
val name = RuleObjectNotSer.rulesMap.getOrElse(code, "未知")
//获取当前线程ID
val treadId = Thread.currentThread().getId
//获取当前Task对应的分区编号
val partitiondId = TaskContext.getPartitionId()
//获取当前Task运行时的所在机器的主机名
val host = InetAddress.getLocalHost.getHostName
(id, code, name, treadId, partitiondId, host, RuleObjectNotSer.toString)
}
//处理数据,关联维度
val res = lines.map(func)
res.saveAsTextFile(args(2))
sc.stop() |
11.3.5 在函数内部初始化未序列化的class
这种方式非常不好,因为每来一条数据,new一个class的实例,会导致消耗更多资源,jvm会频繁GC
| Scala
//从HDFS中读取数据,创建RDD
//HDFS指定的目录中有4个小文件,内容如下:
//1,ln
val lines = sc.textFile(args(1))
//处理数据,关联维度
val res = lines.map(e => {
val fields = e.split(",")
val id = fields(0).toInt
val code = fields(1)
//RuleClassNotSer是在Executor中被初始化的
val rulesClass = new RuleClassNotSer
//但是如果每来一条数据new一个RuleClassNotSer,不好,效率低,浪费资源,频繁GC
val name = rulesClass.rulesMap.getOrElse(code, "未知")
//获取当前线程ID
val treadId = Thread.currentThread().getId
//获取当前Task对应的分区编号
val partitiondId = TaskContext.getPartitionId()
//获取当前Task运行时的所在机器的主机名
val host = InetAddress.getLocalHost.getHostName
(id, code, name, treadId, partitiondId, host, rulesClass.toString)
})
res.saveAsTextFile(args(2)) |
11.3.6 调用mapPartitions在函数内部初始化未序列化的class
一个分区使用一个class的实例,即每个Task都是自己的class实例
| Scala
//从HDFS中读取数据,创建RDD
//HDFS指定的目录中有4个小文件,内容如下:
//1,ln
val lines = sc.textFile(args(1))
//处理数据,关联维度
val res = lines.mapPartitions(it => {
//RuleClassNotSer是在Executor中被初始化的
//一个分区的多条数据,使用同一个RuleClassNotSer实例
val rulesClass = new RuleClassNotSer
it.map(e => {
val fields = e.split(",")
val id = fields(0).toInt
val code = fields(1)
val name = rulesClass.rulesMap.getOrElse(code, "未知")
//获取当前线程ID
val treadId = Thread.currentThread().getId
//获取当前Task对应的分区编号
val partitiondId = TaskContext.getPartitionId()
//获取当前Task运行时的所在机器的主机名
val host = InetAddress.getLocalHost.getHostName
(id, code, name, treadId, partitiondId, host, rulesClass.toString)
})
})
res.saveAsTextFile(args(2))
sc.stop() |