[CVPR 2023] Imagic:使用扩散模型进行基于文本的真实图像编辑

Paper Title: Imagic: Text-Based Real Image Editing with Diffusion Models
The first author performed this work as an intern at Google Research.
Project page: https://imagic-editing.github.io/.
原文链接: Imagic:使用扩散模型进行基于文本的真实图像编辑(by 小样本视觉与智能前沿)
目录
文章目录
- [CVPR 2023] Imagic:使用扩散模型进行基于文本的真实图像编辑
- 01 现有工作的不足?
- 02 文章解决了什么问题?
- 03 关键的解决方案是什么?
- 04 主要的贡献是什么?
- 05 有哪些相关的工作?
- 06 方法具体是如何实现的?
- 文本嵌入优化
- 模型fine-tuning
- 文本嵌入插值
- 实现细节
- 07 实验结果和对比效果如何?
- 定性评估
- 对比
- TEdBench和用户研究
- 08 消融研究告诉了我们什么?
- 微调和优化
- 插值强度
- 09 这个工作还是可以如何优化?
- 10 结论
01 现有工作的不足?
目前,大多数方法仅限于以下其中一种:特定的编辑类型(例如,对象覆盖、样式转换)、合成生成的图像或需要一个公共对象的多个输入图像。
02 文章解决了什么问题?
本文首次展示了对单个真实图像应用复杂(例如,非刚性)基于文本的语义编辑的能力。例如,我们可以改变图像中一个或多个对象的姿势和组成,同时保留其原始特征。
03 关键的解决方案是什么?
利用预先训练的文本到图像扩散模型来完成此任务。它生成与输入图像和目标文本对齐的文本嵌入,同时微调扩散模型以捕获图像特定的外观。
04 主要的贡献是什么?
- 我们提出Imagic,第一种基于文本的语义图像编辑技术,允许在单个真实输入图像上进行复杂的非刚性编辑,同时保留其整体结构和组成。
- 我们展示了两个文本嵌入序列之间语义上有意义的线性插值,揭示了文本到图像扩散模型的强大组合能力。
- 我们引入了TEdBench, 一个新颖而具有挑战性的复杂图像编辑基准,它可以比较不同的基于文本的图像编辑方法。
05 有哪些相关的工作?
- image manipulations [3,19,36,43,56,57]
- 扩散模型被用于类似的图像处理任务:SDEdit [38] ,DDIB [62],DiffusionCLIP [33],DDIM inversion [59],Liu et al. [37],Hertz et al. [20],Textual Inversion [17] and DreamBooth [51]
06 方法具体是如何实现的?
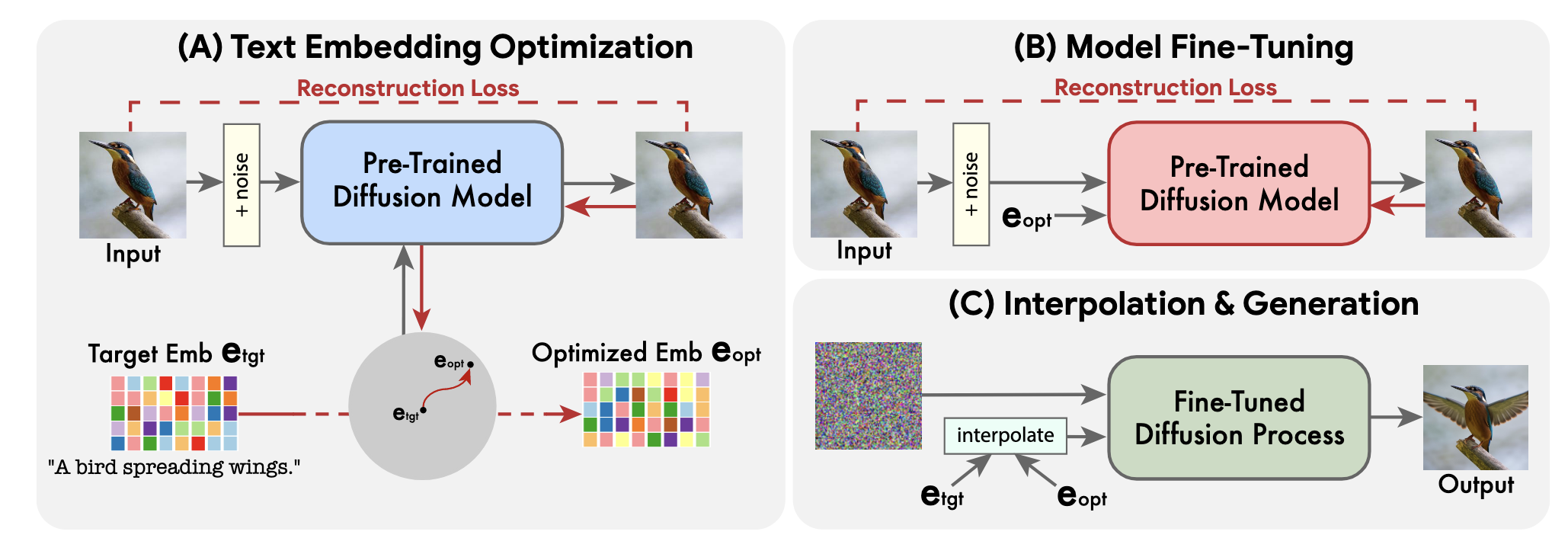
如图 3 所示,我们的方法由 3 个阶段组成:
- 我们优化文本嵌入以找到与目标文本嵌入附近给定图像最匹配的一个;
- 我们微调扩散模型以更好地匹配给定图像;
- 我们在优化的嵌入和目标文本嵌入之间进行线性插值,以找到实现输入图像和目标文本对齐的保真度的点。
文本嵌入优化
目标文本首先通过文本编码器 [46],输出其对应的文本嵌入 e t g t e_{tgt} etgt, 然后我们冻结生成扩散模型 f θ f_{\theta} fθ的参数,并使如下去噪扩散目标 [22] 优化目标文本嵌入 e t g t e_{tgt} etgt:
![]()
这导致文本嵌入尽可能地匹配我们的输入图像。
经过较少的步骤运行此过程,以保持接近初始目标文本嵌入,获得
e
o
p
t
e_{opt}
eopt
模型fine-tuning
上述获得的优化嵌入
e
o
p
t
e_{opt}
eopt在通过生成扩散过程时不一定会生成输入图像
x
x
x,因为我们的优化仅运行了少量步骤。
我们通过使用等式 2 中提出的相同损失函数优化模型参数 θ 来缩小这一差距,同时冻结优化的嵌入。
与此同时,我们对底层生成方法中存在的任何辅助扩散模型进行微调,例如超分辨率模型。我们以相同的重建损失对它们进行微调,但以 e t g t e_{tgt} etgt为条件,因为它们将对编辑过的图像进行操作。这些辅助模型的优化确保了基本分辨率中不存在的 x x x的高频细节的保留。
文本嵌入插值
给定超参数: η ∈ [ 0 , 1 ] \eta \in [0,1] η∈[0,1], 可获得所需编辑图像的嵌入:
![]()
实现细节
我们使用两种不同的最先进的文本到图像生成扩散模型来证明我们的框架是通用的,可以与不同的生成模型相结合:Imagen[53]和Stable diffusion[50]。
07 实验结果和对比效果如何?
定性评估
Imagic能够对一般输入图像和文本应用各种编辑类别,如图1和补充材料所示。我们在图2中对相同的图像使用不同的文本提示进行实验,显示了Imagic的多功能性。

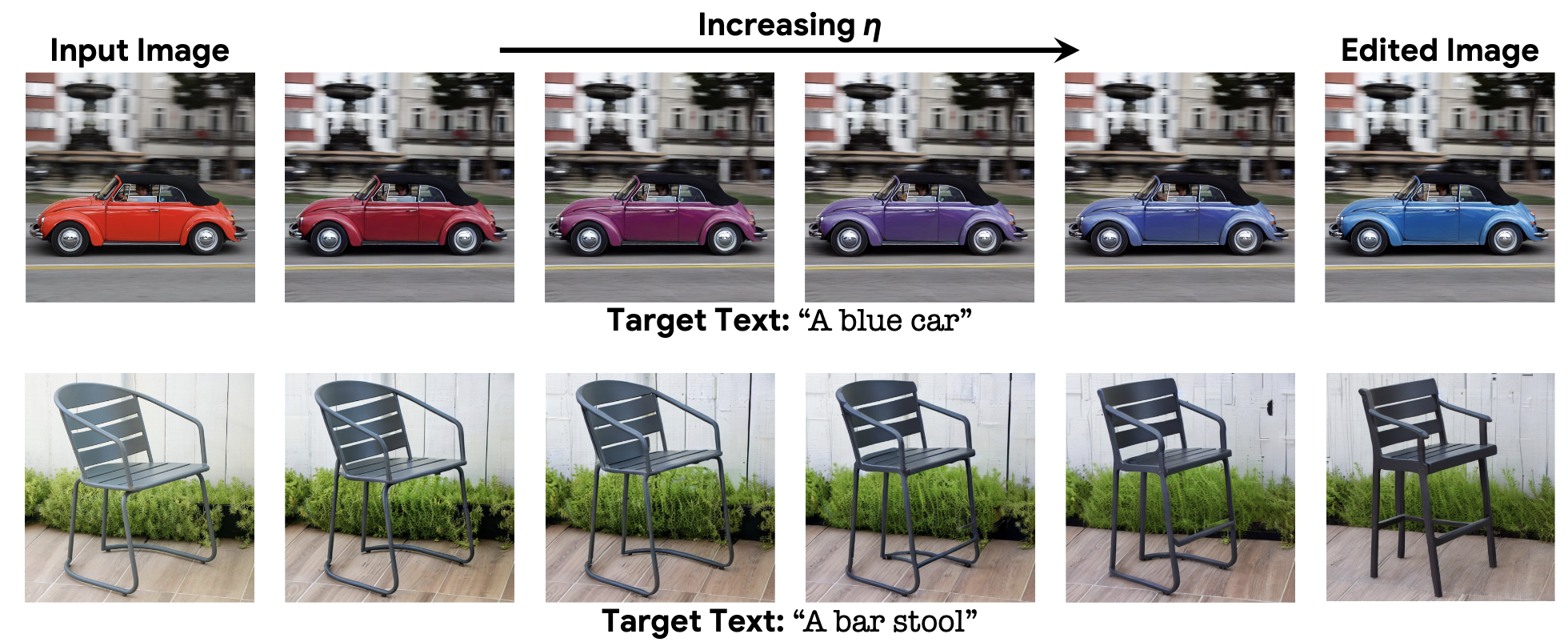
由于我们使用的底层生成扩散模型是概率的,因此我们的方法可以为单个图像-文本对生成不同的结果。在图4中,我们使用不同的随机种子显示了同一编辑的多个选项,对每个种子的η值进行了轻微调整。这种随机性允许用户在这些不同的选项中进行选择,因为自然语言文本提示通常是模糊和不精确的。

在图5(以及补充材料)中,我们展示了imagic在保留图像特定外观的同时,也使用了Stable Diffusion成功地执行了复杂的非刚性编辑。此外,随着η的变化,Imagic(使用稳定扩散)表现出平滑的语义插值特性。我们假设这种平滑特性是在语义潜在空间而不是在图像像素空间中发生的扩散过程的副产品。
对比
图6显示了不同方法的编辑结果。对于SDEdit和Imagic,我们使用不同的随机种子对8张图像进行采样,并显示与目标文本和输入图像最佳对齐的结果。可以观察到,我们的方法在适当执行所需编辑的同时保持了对输入图像的高保真度。当任务是复杂的非刚性编辑时,如让狗坐,我们的方法明显优于以前的技术。Imagic构成了这种复杂的基于文本的编辑应用于单个真实世界图像的第一个演示。
![Fig 6. 方法比较。我们将SDEdit[38]、DDIB[62]和Text2LIVE[8]与我们的方法进行比较。Imagic成功地应用了所需的编辑,同时很好地保留了原始图像细节。](https://img-blog.csdnimg.cn/img_convert/63b5cbc0798243832de09604bbb175d7.png)
TEdBench和用户研究
基于文本的图像编辑方法是一个相对较新的发展,而image是第一个应用复杂的非刚性编辑的方法。因此,没有标准的基准来评估非刚性的基于文本的图像编辑。我们介绍了tedbench(文本编辑基准),这是一个由100对输入图像和目标文本组成的新颖集合,描述了所需的复杂非刚性编辑。我们希望未来的研究将受益于TEdBench作为这一任务的标准化评估集。
![Fig 8. 用户研究结果。Imagic相对于SDEdit[8]、DDIB[62]和Text2LIVE[8]的图像编辑质量偏好率(95%置信区间)。](https://img-blog.csdnimg.cn/img_convert/c4447485da50fc53c38998343d9d1d77.png)
我们通过在TEdBench上进行广泛的人类感知评估研究,定量评估Imagic的性能。
向参与者展示输入图像和目标文本,并要求他们使用双选项强制选择(2AFC)的标准实践从两个选项中选择更好的编辑结果[8,35,42]。
我们总共收集了9213个答案,其结果总结在图8中。可以看到,评估者对我们的方法表现出强烈的偏好,在所有考虑的基线中,偏好率超过70%。
08 消融研究告诉了我们什么?
微调和优化
我们使用相同的优化嵌入和随机种子,并对图7中的结果进行定性评价。

在没有微调的情况下,该方案不能完全重建η=0时的原始图像,并且随着η值的增加也不能保留图像的细节。相比之下,微调从输入图像中施加的细节不仅仅是优化的嵌入,允许我们的方案在η的中间值中保留这些细节,从而实现语义上有意义的线性插值。因此,我们得出结论,模型微调对我们的方法的成功至关重要。
我们的研究结果表明,用较少的步骤优化文本嵌入限制了我们的编辑能力,而优化超过100个步骤几乎没有增加价值。
插值强度
我们应用我们的编辑方案与不同的η值,并计算输出的CLIP分数[21,45]w.r.t.目标文本,和他们的LPIPS分数[68]w.r.t.输入图像减去1。更高的CLIP分数表明输出与目标文本的一致性更好,更高的1-LPIPS表明输入图像的保真度更高。
我们对150个图像-文本输入重复此过程,并在图9中显示平均结果。我们观察到,当η值小于0.4时,输出与输入图像几乎相同。
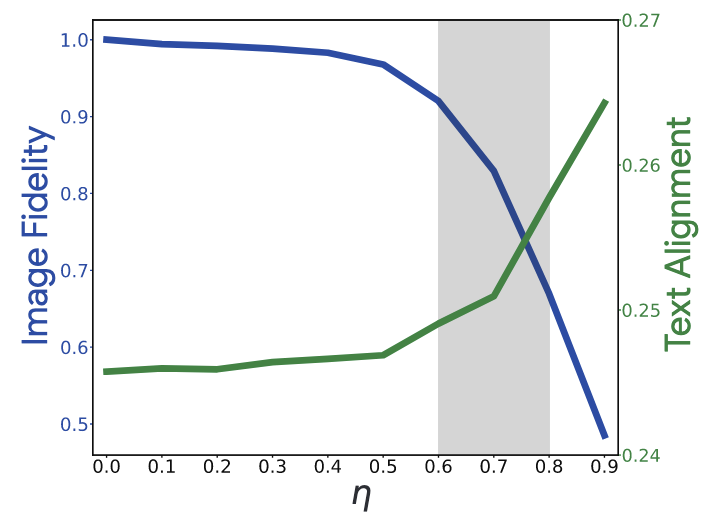
当η为[0.6,0.8]时,图像开始变化(根据LPIPS),并且与文本更好地对齐(随着CLIP分数的上升)。因此,我们认为这个区域最有可能获得令人满意的结果。
09 这个工作还是可以如何优化?
- 某些情况下,与目标文本不对齐。
- 某些情况下,编辑应用得很好,但它会影响外部图像细节,如变焦或相机角度
我们在图10的第一行和第二行中分别展示了这两个失败案例的示例。

这些限制可以通过优化文本嵌入或扩散模型来缓解,或者通过结合类似于Hertz等人的交叉注意控制来缓解。我们把这些选项留给未来的工作。
此外,由于我们的方法依赖于预训练的文本到图像扩散模型,因此它继承了模型的生成限制和偏差。因此,当所需的编辑涉及到生成底层模型的失败案例时,就会产生不需要的工件。例如,Imagen在人脸上的生成性能就不达标。
10 结论
文章提出了一种新的图像编辑方法Imagic。
- 方法接受单个图像和描述所需编辑的简单文本提示,目的是在应用此编辑的同时保留图像中的最大数量的细节。
- 为此,利用预训练的文本到图像扩散模型,并使用它来找到代表输入图像的文本嵌入。
- 然后对扩散模型进行微调以更好地拟合图像,
- 最后在代表图像的嵌入和目标文本嵌入之间进行线性插值,得到它们在语义上有意义的混合。这使得我们的方案能够使用插值嵌入提供编辑过的图像。
与其他编辑方法相反,我们的方法可以产生复杂的非刚性编辑,可以根据要求改变图像内对象的姿势,几何形状和/或组成,以及更简单的编辑,如风格或颜色。它只需要用户提供一个图像和一个简单的目标文本提示,而不需要额外的辅助输入,如图像遮罩。
我们未来的工作可能集中在进一步提高该方法对输入图像的保真度和身份保持,以及对随机种子和插值参数η的敏感性。另一个有趣的研究方向是为每个请求的编辑选择η的自动化方法的发展。
原文链接: Imagic:使用扩散模型进行基于文本的真实图像编辑(by 小样本视觉与智能前沿)