文章目录
- 一、导读
- 二、逐像素分类和掩码分类的区别
- 2.1 逐像素分类
- 2.2 掩码分类
- 2.3 区别
- 三、DETR
- 四、MaskFormer
- 五、MaskFormer用于语义和实例分割
- 六、总结
一、导读
目标检测和实例分割是计算机视觉的基本任务,在从自动驾驶到医学成像的无数应用中发挥着关键作用。目标检测的传统方法中通常利用边界框技术进行对象定位,然后利用逐像素分类为这些本地化实例分配类。但是当处理同一类的重叠对象时,或者在每个图像的对象数量不同的情况下,这些方法通常会出现问题。
诸如Faster R-CNN、Mask R-CNN等经典方法虽然非常有效,但由于其固有的固定大小输出空间,它们通常预测每个图像的边界框和类的固定数量,这可能与图像中实例的实际数量不匹配,特别是当不同图像的实例数量不同时。并且它们可能无法充分处理相同类的对象重叠的情况,从而导致分类不一致。

本文中将介绍Facebook AI Research在21年发布的一种超越这些限制的实例分割方法MaskFormer。可以看到从那时候开始,FB就对Mask和Transformer进行整合研究了。
论文地址:
https://arxiv.org/abs/2107.06278

二、逐像素分类和掩码分类的区别
2.1 逐像素分类
逐像素分类(Pixel-wise Classification)是一种计算机视觉任务,旨在对图像中的每个像素进行分类。该任务要求将图像划分为不同的类别,并为每个像素分配一个标签,以便对图像进行语义分割、实例分割或对象检测等应用。
在逐像素分类中,通常使用深度学习方法来解决这个问题。以下是逐像素分类的一般步骤和常用技术:
- 数据准备:首先需要准备一个带有像素级标签的训练数据集。训练数据集由输入图像和相应的像素级标签组成,标签指定了每个像素的类别。通常,这些标签可以通过手动注释、众包标注或使用已有的数据集(如COCO、PASCAL VOC等)获取。
- 模型选择:选择适合逐像素分类的深度学习模型。常用的模型包括全卷积网络(Fully Convolutional Networks,FCN)、U-Net、DeepLab等。这些模型在图像分类任务中引入了空间上下文信息,并通过卷积层和上采样层来保留空间分辨率。
- 模型训练:使用训练数据集对选定的模型进行训练。训练过程中,通常使用交叉熵损失函数来度量模型的预测结果与真实标签之间的差异。通过反向传播算法和优化算法(如随机梯度下降法)来更新模型的权重,以最小化损失函数。
- 模型推理:在训练完成后,使用训练好的模型对新的图像进行推理和分类。对于每个像素,模型将输出其所属类别的概率分布。可以通过选择概率最高的类别作为像素的标签,或者使用阈值进行二值化处理。
- 后处理:在获得像素级分类结果后,可以进行一些后处理步骤来进一步优化结果。例如,可以使用像素连接、条件随机场等技术来平滑边界,提高分割的准确性和连续性。
逐像素分类在许多计算机视觉应用中都得到了广泛应用,如医学图像分析、自动驾驶、遥感图像分析等。它可以提供更细粒度的图像分割结果,使得对图像中的每个像素进行更精细的分析和理解成为可能。

2.2 掩码分类
掩码分类(Mask Classification)是一种计算机视觉任务,结合了目标检测和逐像素分类的概念。该任务旨在对图像中的每个目标实例进行分类,并生成与每个实例对应的二进制掩码(Mask),以标识目标的精确位置。
在掩码分类中,常用的方法是使用全卷积网络(Fully Convolutional Networks,FCN)或类似的架构。以下是掩码分类的一般步骤和常见技术:
- 数据准备:首先需要准备一个带有目标实例的训练数据集。数据集包括图像、目标实例的边界框坐标和对应的像素级掩码。掩码是二进制图像,与目标实例的形状相匹配,其中目标区域被标记为前景(1),背景区域标记为背景(0)。
- 目标检测和分类:使用目标检测算法(如Faster R-CNN、YOLO等)来检测图像中的目标实例,并获取它们的边界框坐标。
- 掩码生成网络:在每个目标实例的边界框上,使用全卷积网络或类似的架构,将边界框内的图像区域作为输入,生成与目标实例精确匹配的像素级掩码。
- 掩码分类训练:将生成的像素级掩码与目标标签一起作为训练样本,使用交叉熵损失函数来训练掩码分类器。该分类器可以是一个基于卷积神经网络的分类器,用于将像素级掩码与对应的目标类别进行分类。
- 掩码分类推理:在测试阶段,对于新的图像,使用目标检测算法检测目标实例,并使用训练好的掩码分类器对每个目标实例的边界框区域生成像素级掩码。这样可以获得每个目标实例的分类标签和精确掩码。
掩码分类在许多计算机视觉应用中得到广泛应用,如实例分割、医学图像分析、遥感图像分析等。它可以提供更精确的目标定位和更准确的像素级分割结果,对于需要对目标进行精细分析和定位的任务非常有用。
2.3 区别
逐像素分类(Pixel-wise Classification)和掩码分类(Mask Classification)是两种不同的计算机视觉任务,有以下区别:
- 定义和目标:逐像素分类的目标是对图像中的每个像素进行分类,即将每个像素分配到不同的类别。而掩码分类的目标是对图像中的每个目标实例生成像素级的二进制掩码,用于标识目标的精确位置。
- 输出形式:逐像素分类的输出是一个与输入图像大小相同的像素级分类标签图,其中每个像素都被分配了一个类别标签。而掩码分类的输出是与目标实例的形状相匹配的二进制掩码,其中目标区域被标记为前景,背景区域被标记为背景。
- 模型结构:逐像素分类通常使用全卷积网络(FCN)或类似的架构,以保留输入图像的空间分辨率,并进行像素级的分类。掩码分类结合了目标检测和逐像素分类的概念,通常使用目标检测算法检测目标实例,然后使用全卷积网络或类似的架构生成与每个目标实例对应的精确像素级掩码。
- 应用场景:逐像素分类通常用于语义分割任务,旨在将图像划分为不同的语义类别,如道路、建筑物、车辆等。掩码分类常用于实例分割任务,要求对图像中的每个目标实例生成精确的二进制掩码,以实现目标的像素级分割。
总的来说,逐像素分类和掩码分类都是基于图像的像素级分类任务,但目标和输出形式有所不同。逐像素分类将图像中的每个像素分配到不同的类别,而掩码分类生成与每个目标实例对应的精确像素级掩码,用于目标的精确定位和分割。
三、DETR
DETR的核心是一个被称为Transformer的强大机制,它允许模型克服传统逐像素和掩码分类方法的一些关键限制。
在传统的掩模分类方法中,如果两辆车重叠,可能难以将它们区分为不同的实体。而DETR为这类问题提供了一个优雅的解决方案。DETR不是为每辆车生成掩码,而是预测一组固定的边界框和相关的类概率。这种“集合预测”方法允许DETR以惊人的效率处理涉及重叠对象的复杂场景。
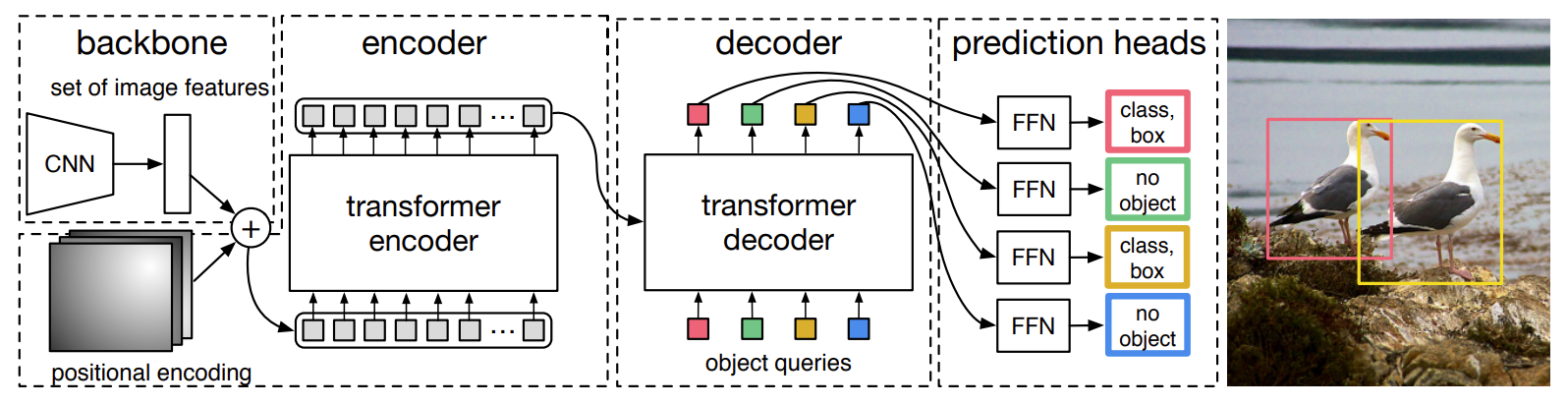
虽然DETR彻底改变了边界框预测,但它并没有直接提供分割掩码——这是许多应用程序中至关重要的细节。这时就出现了MaskFormer:它扩展了DETR的鲁棒集预测机制,为每个检测到的对象创建特定于类的掩码。所以MaskFormer建立在DETR的优势之上,并增强了生成高质量分割掩码的能力。
比如在上面提到的汽车场景中,MaskFormer不仅将每辆车识别为一个单独的实体(感谢DETR的集合预测机制),而且还为每辆车生成一个精确的掩码,准确捕获它们的边界,即使在重叠的情况下也是如此。
DETR和MaskFormer之间的这种协同作用为更准确、更高效的实例分割打开了一个可能性的世界,超越了传统的逐像素和掩码分类方法的限制。
四、MaskFormer
下面是MaskFormer的架构:
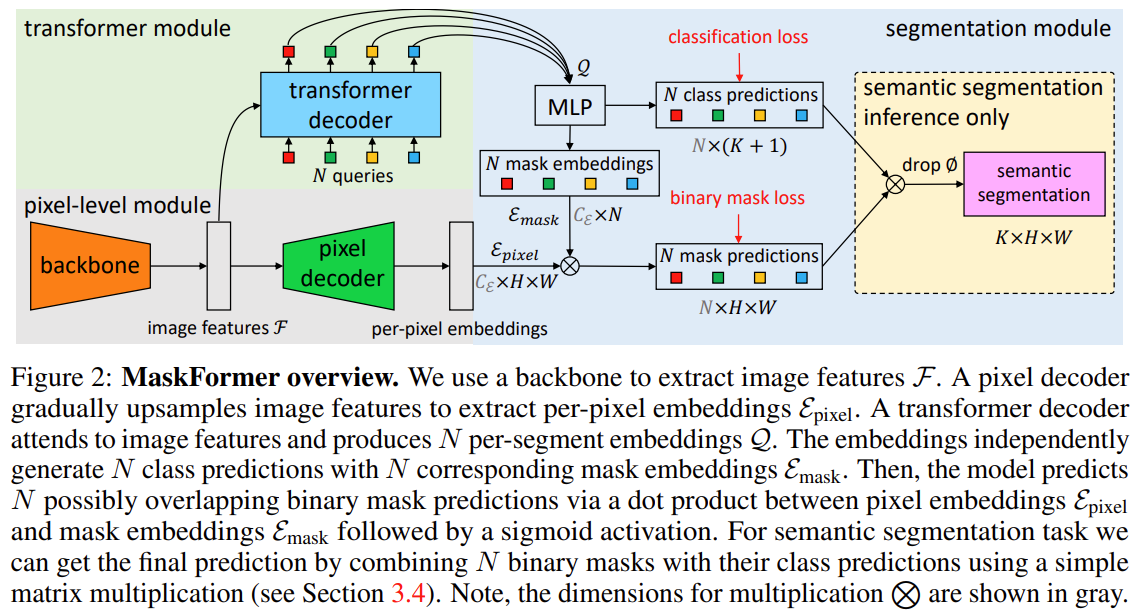
通过主干提取特征:MaskFormer主干网络负责从输入中提取关键的图像特征。这个主干可以是任何流行的CNN(卷积神经网络)架构,比如ResNet,它处理图像并提取一组特征,用F表示。
逐像素嵌入生成:然后将这些特征F传递给像素解码器,该解码器逐渐对图像特征进行上采样,生成我们所说的“逐像素嵌入”(E像素)。这些嵌入捕获图像中每个像素的局部和全局上下文。
段(Per-Segment )嵌入生成:与此同时,Transformer Decoder关注图像特征F并生成一组“N”段嵌入,用Q表示,通过“注意力”的机制为图像的不同部分分配不同的重要性权重。这些嵌入本质上代表了我们想要分类和定位的图像中的潜在对象(或片段)。
这里的术“Segment ”是指模型试图识别和分割的图像中对象的潜在实例。
一般来说,编码器处理输入数据,解码器使用处理后的数据生成输出。编码器和解码器的输入通常是序列,就像机器翻译任务中的句子一样。
而maskformer的“编码器”是骨干网络(用于maskFormer的Resnet50),它处理输入图像并生成一组特征映射。这些特征映射与传统Transformer中的编码器输出具有相同的目的,提供输入数据的丰富的高级表示。
然后使用这些嵌入Q来预测N个类标签和N个相应的掩码嵌入(E掩码)。这就是MaskFormer真正的亮点所在。与传统分割模型预测每个像素的类标签不同,MaskFormer预测每个潜在对象的类标签,以及相应的掩码嵌入。
在获得掩码嵌入后,MaskFormer通过像素嵌入(E像素)与掩码嵌入(E掩码)之间的点积产生N个二进制掩码,然后进行s型激活。这个过程可能会将每个对象实例的二进制掩码重叠。
最后对于像语义分割这样的任务,MaskFormer可以通过将N个二进制掩码与其相应的类预测相结合来计算最终预测。这种组合是通过一个简单的矩阵乘法实现的,给我们最终的分割和分类图像。
五、MaskFormer用于语义和实例分割
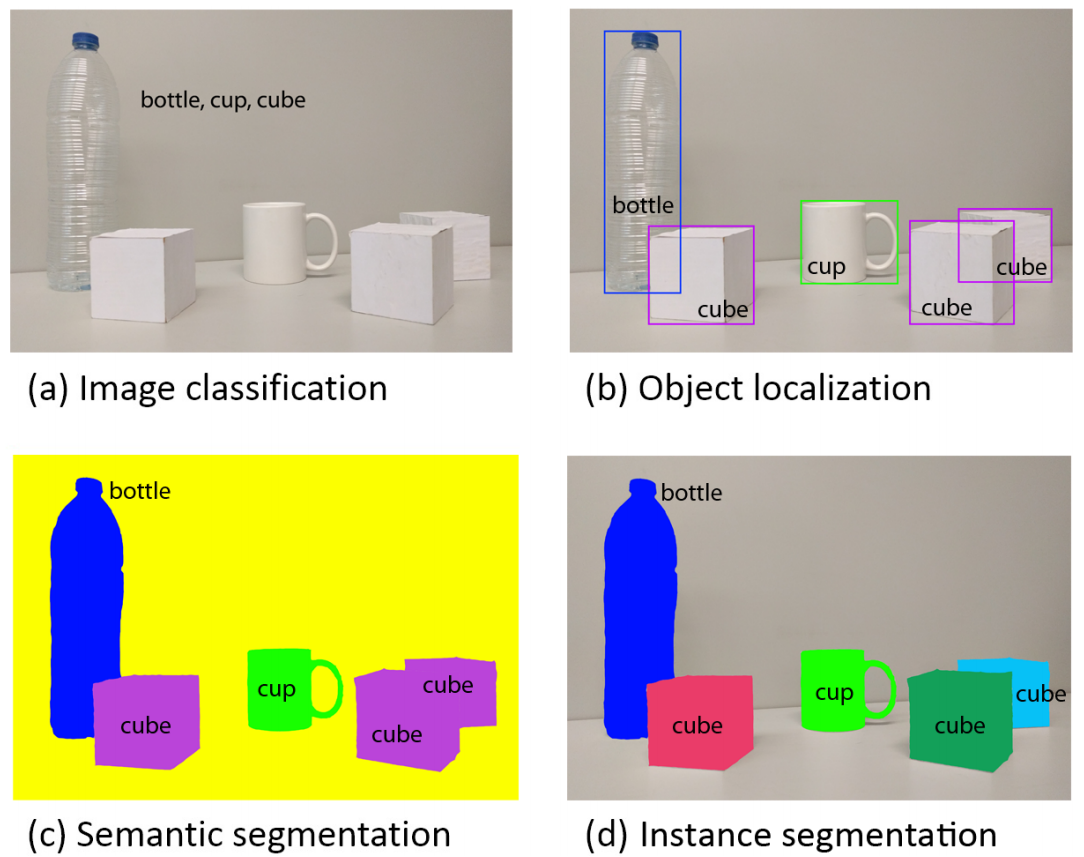
语义分割涉及到用类标签标记图像的每个像素(例如“汽车”,“狗”,“人”等)。但是它不区分同一类的不同实例。例如如果图像中有两个人,语义分割会将所有属于这两个人的像素标记为“人”,但它不会区分A和B。
而实例分割不仅对每个像素进行分类,而且对同一类的不同实例进行分离。比如实例分割需要将所有属于A的像素标记为“A”,所有属于B的像素标记为“B”。
大多数传统的计算机视觉模型将语义分割和实例分割视为独立的问题,需要不同的模型、损失函数和训练过程。但是MaskFormer设计了一个统一的方式处理这两个任务:它通过预测图像中每个对象实例的类标签和二进制掩码来工作。这种方法本质上结合了语义和实例分割的各个方面。
对于损失函数,MaskFormer使用统一的损失函数来处理这个掩码分类问题。这个损失函数以一种与语义和实例分割任务一致的方式评估预测掩码的质量。
所以使用相同的损失函数和训练过程得到的的MaskFormer模型可以不做任何修改地同时应用于语义和实例分割任务。
六、总结
MaskFormer提供了一种新的图像分割方法,集成了DETR模型和Transformer架构的优点。它使用基于掩码的预测,增强了对图像中复杂对象交互的处理。
MaskFormer的统一方法在图像分割方面向前迈出了一大步,为计算机视觉的进步开辟了新的可能性。它为进一步的研究奠定了基础,旨在提高我们理解和解释视觉世界的能力。

![[Spec] WiFi P2P Discovery](https://img-blog.csdnimg.cn/bc493d70bc014342aba6759bbc154e46.png)