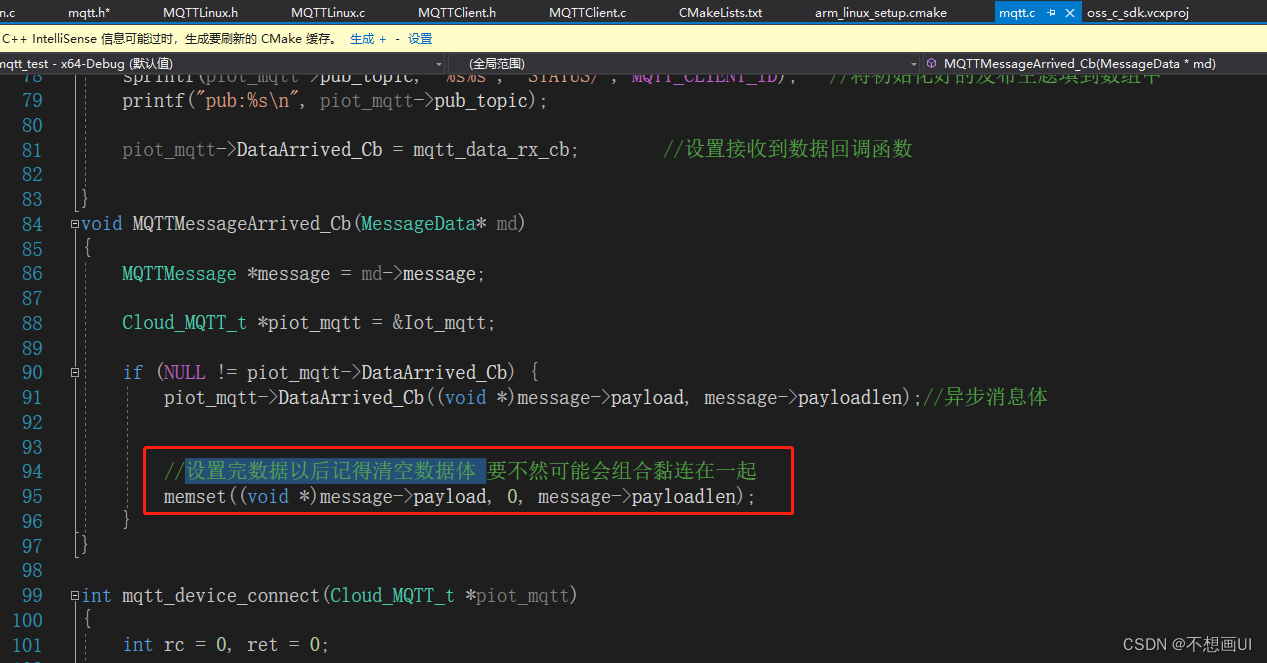
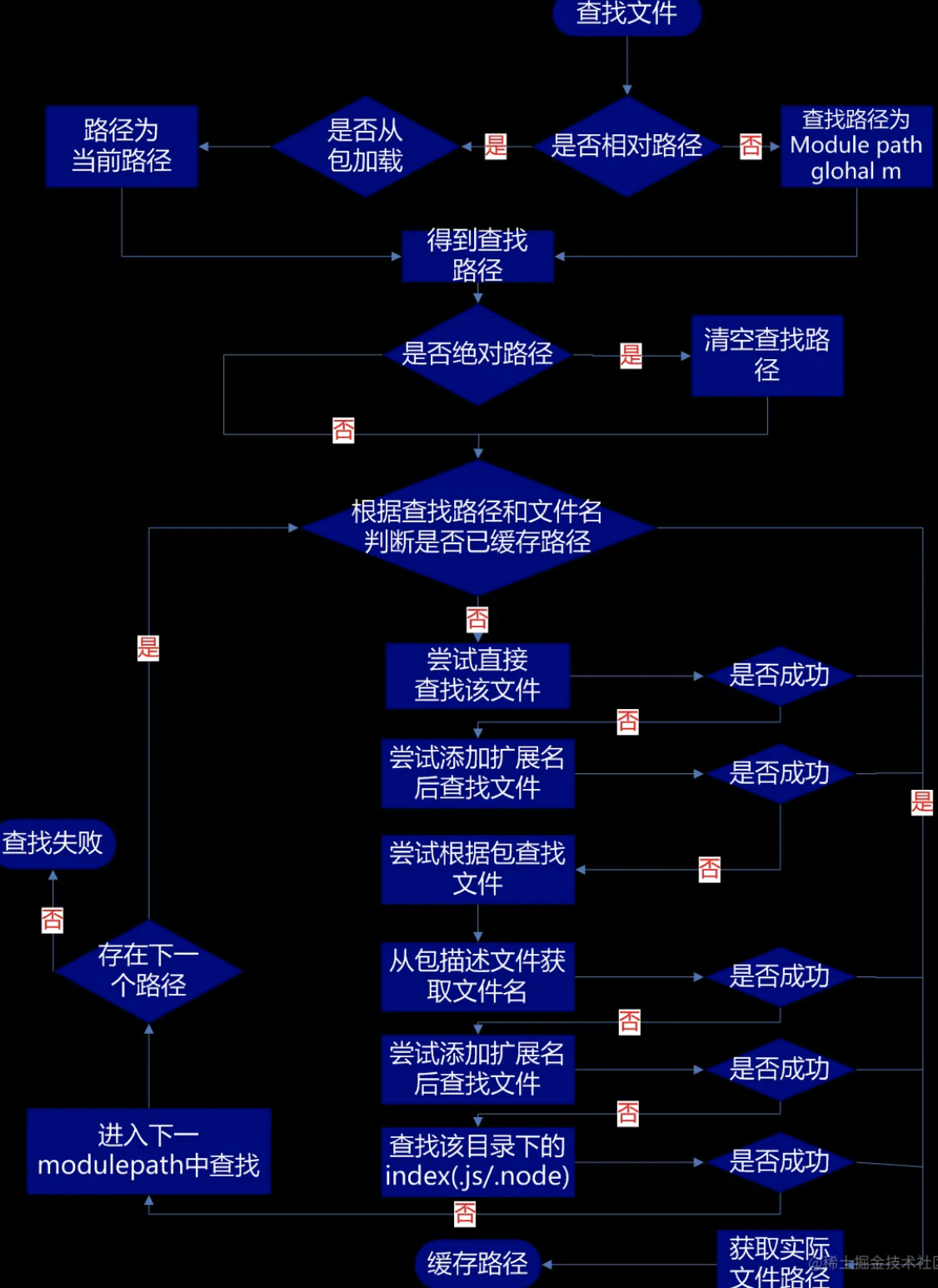
原创/文 BFT机器人

近日,麻省理工学院的研究人员开发出一种新技术,让AI智能体能够思考更远的未来,寻找更合适的合作与竞争长期解决方案。
想象一个游戏规则:两支足球队在球场上PK,玩家们可以选择相互合作合作来实现目标,也可以选择与其他玩家们竞争,以取得游戏胜利。
创建一个可以像人类一样高效地学习竞争和合作的AI智能体并不容易,其中具有挑战性的关键难点是:让 AI 智能体能够预测其他智能体的未来行为。由于这个问题的复杂性,目前的方法机器学习方法往往是短视的;AI智能体只能猜测队友或对手接下来的几个动作。这并不利于他们的长期发展。
为解决这一难点,来自麻省理工学院、MIT-IBM Watson人工智能实验室,和其他实验室的研究人员开发了一种新方法,为AI智能体提供了一个更长远的学习视角。他们的机器学习框架能使AI智能体,不仅仅能够考虑其他合作或竞争的智能体接下来的几个动作,而是考虑到他们在更长远时间范围内的更多行为。然后,AI智能体会根据预测到的结果,相应地调整自身的行为,从而影响其他智能体接下来的行为,并得出最优的长期解决方案。
这个框架可以用于自动无人机在茂密的森林中寻找迷路的徒步旅行者,或用于自动驾驶汽车预测高速公路上行驶的其他车辆的动线来保护乘客的安全。
“当 AI 智能体进行合作或竞争时,最重要的是它们的行为在未来的某个时刻融合。在这一过程中有很多暂时性的行为,从长远来看并不重要。“我们真正关心的是如何达到这种融合,现在正好有一种数学方法可以实现。”麻省理工学院信息与决策系统实验室 (LIDS) 研究生、一篇描述该框架论文的主要作者Dong-Ki Kim说。
该论文的高级作者是 Jonathan P. How,他是 Richard C. Maclaurin 航空航天学教授,也是MIT-IBM Watson人工智能实验室的成员。论文的共同作者包括MIT-IBM Watson人工智能实验室、IBM 研究院、Mila-Quebec人工智能研究所和牛津大学的其他人。这项研究将在神经信息处理系统会议上发表。

更多人工智能体,更多问题
研究人员专注于一个称为多智能体强化学习的问题。强化学习是机器学习的一种形式,其中AI 智能体通过反复试验和试错来进行学习。研究人员会对其帮助实现其目标的“良好”行为给予奖励,AI智能体会调整其行为以获得最大化奖励,直到它最终成为这项任务的专家。
但是当许多合作或竞争的AI智能体同时学习时,事情就会变得越来越复杂。随着AI智能体考虑到更多其他同伴的未来行为,以及他们自己的行为如何影响他人,这个问题的有效解决就需要更多的计算能力。这就是为什么其他方法只关注短期,而忽视未来的原因。
AI真的很想预测游戏的结局,但他们不知道游戏什么时候结束。他们需要思考如何不断地调整自己的行为,以便在未来某个遥远的时间点获胜。“我们的论文实质上提出了一个新目标,使 AI 能够思考无穷大” Kim说。
但是,由于不可能在算法中插入无穷大,研究人员设计了他们的系统,使AI智能体专注于他们的行为,将与其他AI智能体的行为趋同的一个未来点,称为平衡点。一个平衡点决定了AI智能体的长期表现,多智能体场景中可以存在多个平衡点。因此,一个有效的AI智能体会积极影响其他智能体的未来行为,从而使他们从智能体的角度来看达到一个理想的平衡点。如果所有智能体都相互影响,他们就会汇聚成一个一般的概念,研究人员称之为“主动均衡”。
他们开发的机器学习框架被称为 FURTHER(代表通过平均奖励充分加强主动影响),使智能体能够学习如何在与其他智能体交互时调整自己的行为,以实现这种主动平衡。
FURTHER进一步使用两个机器学习模块来做到这一点。第一个是推理模块,它使智能体能够仅根据其他先前的行为,来猜测其他智能体的未来行为以及他们使用的学习算法。这一信息被输入强化学习模块,智能体利用该模块调整其行为,并以最大化的回报方式来影响其他智能体。
“挑战在于思考无限。我们必须使用许多不同的数学工具来实现这一点,并做出一些假设,才能使其在实践中发挥作用,”Kim说。
胜利在远方
他们在几种不同的场景中用他们的方法,针对其他多智能体强化学习框架进行了测试,包括一对机器人的相扑式比赛,和两个 25智能体团队的较量。在这两种情况下,使用 FURTHER 的 AI智能体能更大概率赢得比赛。
Kim解释说,由于他们的方法是去中心化的,这意味着AI智能体学会了独立赢得比赛,因此它也比其他需要中央计算机控制AI智能体的方法更具可扩展性。
研究人员使用游戏来测试他们的方法,但FURTHER可以用来解决任何类型的多智能体问题。例如,在许多相互作用的权利具有随时间变化的行为和利益的情况下, 经济学家可以应用它来制定合理的政策。
本文为原创文章,版权归BFT机器人所有,如需转载请与我们联系。若您对该文章内容有任何疑问,请与我们联系,将及时回应。
![[附源码]Python计算机毕业设计Django学生宿舍管理系统](https://img-blog.csdnimg.cn/99a828a27c734875b0a9abcc808390f9.png)