2023年4月17日,多模态问答模型MiniGPT-4发布,实现了GPT-4里的宣传效果《MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models》《MiniGPT-4:使用高级大语言模型增强视觉语言理解》
- 模型介绍
- 模型架构
- 微调
- 效果
- Let's try it out!
- 前期准备
- Vicuna Weight
- 下载 MiniGPT-4 checkpoint
- 搭建环境
- 在本地启动MiniGPT-4 demo
- 训练MiniGPT-4
模型介绍
《MiniGPT-4:使用高级大语言模型增强视觉语言理解》
阿卜杜拉国王科技大学的几位博士(看名字都是中国人)开发,他们认为GPT-4 先进的多模态生成能力,主要原因在于利用了更先进的大型语言模型。为了验证这一想法,团队成员将一个冻结的视觉编码器(Q-Former&ViT)与一个冻结的文本生成大模型(Vicuna小🦙) 进行对齐,造出了 MiniGPT-4。
模型架构
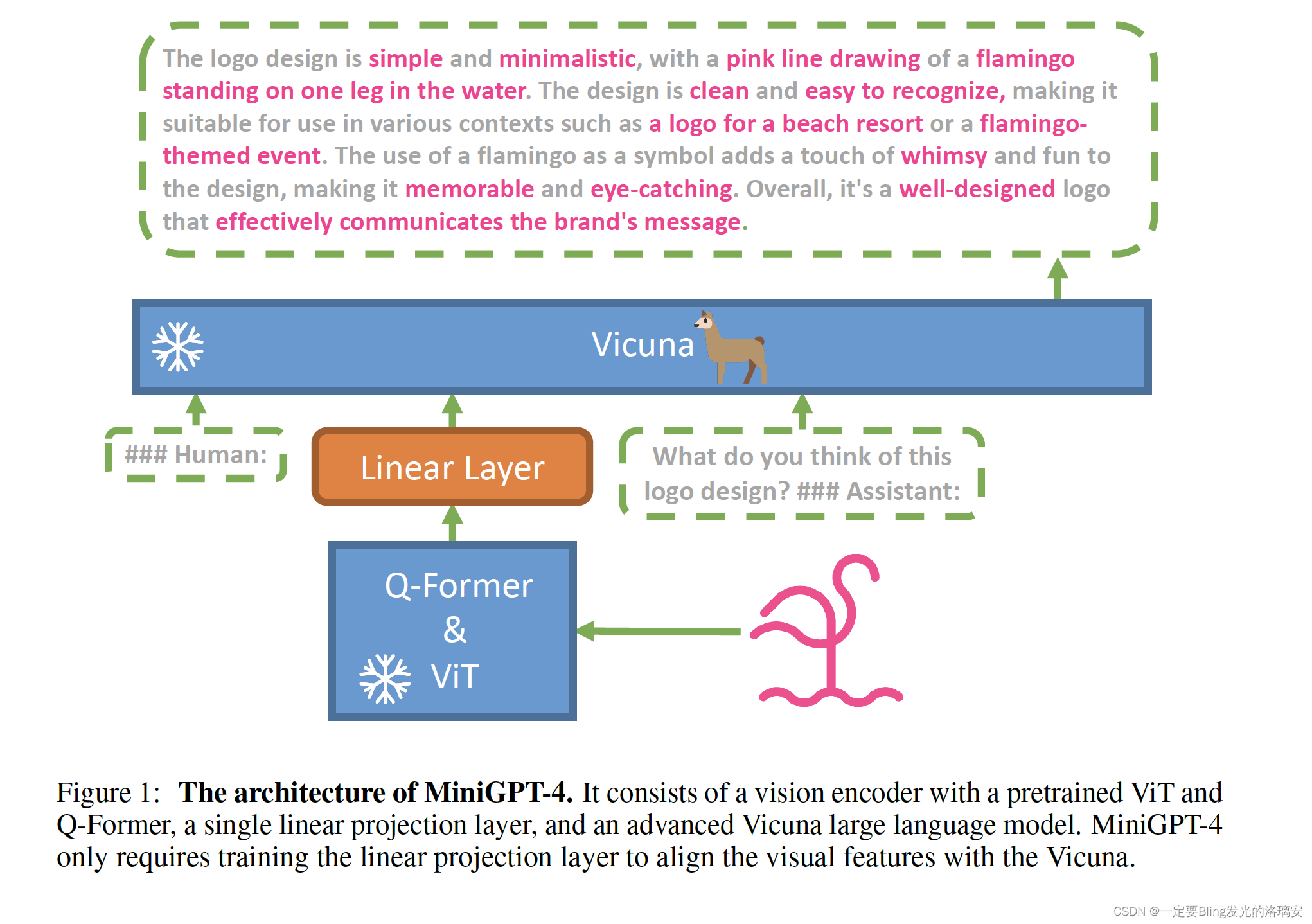
⬆️ MiniGPT-4的架构:由一个带有预训练ViT和Q-Former的视觉编码器、一个单一的线性投影层和一个先进的Vicuna大型语言模型组成。MiniGPT-4只需要训练线性投影层,使视觉特征与Vicuna对齐。
- MiniGPT-4 具有许多类似于 GPT-4 的能力, 图像描述生成、从手写草稿创建网站等;
- MiniGPT-4 还能根据图像创作故事和诗歌,为图像中显示的问题提供解决方案,教用户如何根据食物照片做饭等。
微调
- 在 4 个 A100 上用 500 万图文对训练;
- 再用一个小的高质量数据集训练,单卡 A100 训练只需要 7 分钟。
效果
在零样本 VQAv2 上,BLIP-2 相较于 80 亿参数的 Flamingo 模型,使用的可训练参数数量少了 54 倍,性能提升了 8.7 %。
Let’s try it out!
前期准备
Vicuna Weight
四步走:
- 下载 Vicuna Weight;
- 下载原始LLAMA-7B或LLAMA-13B权重;
- 构建真正的 working weight
- 配置模型路径:MiniGPT-4/minigpt4/configs/models/minigpt4.yaml第16行,将 “/path/to/vicuna/weights/” 修改为本地weight地址
# Vicuna
llama_model: "chat/vicuna/weight" # 将 "/path/to/vicuna/weights/" 修改为本地 weight 地址
前三步参考【LLMs 入门实战 】第一式:Vicuna模型学习与实战
下载 MiniGPT-4 checkpoint
- 方法一:从 google drive 下载
Checkpoint Aligned with Vicuna 13B
Checkpoint Aligned with Vicuna 7B - 方法二:从 huggingface 平台下载
prerained_minigpt4_7b.pth
pretrained_minigpt4.pth
然后在 MiniGPT-4/eval_configs/minigpt4_eval.yaml 的 第11行 设置 MiniGPT-4 checkpoint 路径
ckpt: '/path/to/pretrained/ckpt/' # 修改为 MiniGPT-4 checkpoint 路径
搭建环境
这里插一句:如何在Colab中安装Conda
还有每一句命令前面都要记得加感叹号
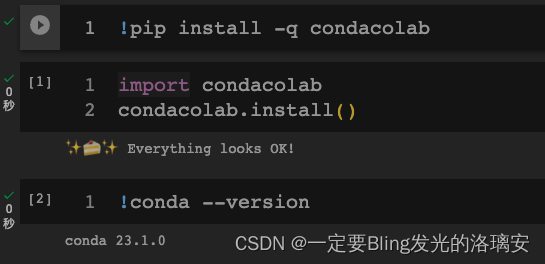
!pip install -q condacolab
import condacolab
condacolab.install()
!conda --version
!conda env create -f environment.yml # 这一句很费劲,A100跑了8min!我的小钱钱啊!
!source activate minigpt4
在本地启动MiniGPT-4 demo
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
注:为了节省GPU内存,Vicuna默认加载为8位,波束搜索宽度为1。这种配置对于Vicuna 13B需要大约23G GPU内存,对于Vicuna7B需要大约11.5G GPU内存。对于更强大的GPU,您可以通过在配置文件minigpt4_eval.yaml中将low_resource设置为False以16位运行模型,并使用更大的波束搜索宽度。
效果图⬇️
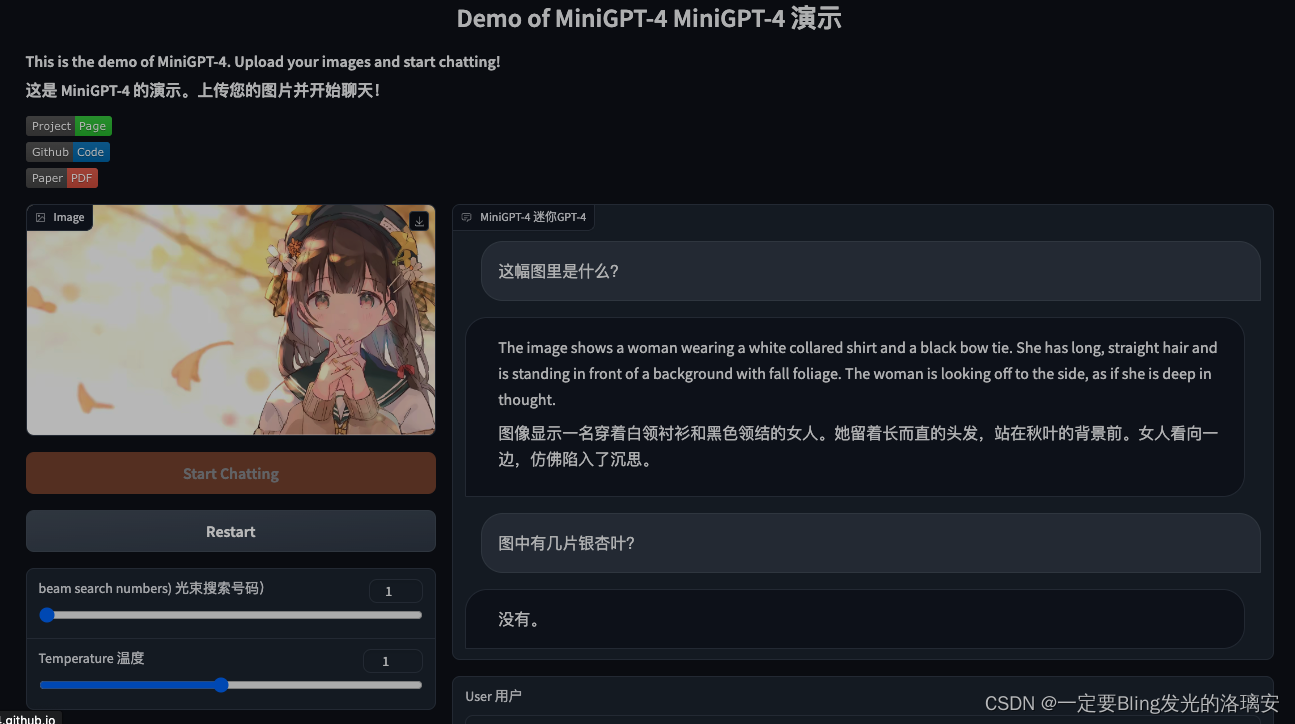
图中有三片银杏叶,但是没有识别到;给的图片解释有点差强人意。
训练MiniGPT-4
MiniGPT-4的训练包含两个 alignment stages:
- 预训练阶段:使用 Laion和CC数据集的图像-文本对 来 训练模型,以对齐视觉和语言模型。要下载和准备数据集,请查看第一阶段数据集准备说明。在第一阶段之后,视觉特征被映射,并且可以被语言模型理解。要启动第一阶段培训,请运行以下命令。在我们的实验中,我们使用了4个A100(被优雅地劝退了==)。您可以在配置文件 train_configs/minigpt4_stage1_pretrain.yaml 中更改保存路径。只有第一阶段训练的MiniGPT-4 checkpoint 可以在这里下载:与第二阶段之后的模型相比,该 checkpoint 频繁地生成不完整和重复的句子。
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage1_pretrain.yaml
- 在第二阶段,我们使用自己创建的小型高质量图像-文本对数据集,并将其转换为对话格式,以进一步对齐MiniGPT-4。要下载和准备我们的 第二阶段数据集,请查看我们的 second stage dataset preparation instruction。要启动第二阶段对齐,首先在 train_configs/minigpt4_stage1_pretrain.yaml 中指定阶段1中训练的 checkpoint 文件的路径。您也可以在那里指定输出路径。然后,运行以下命令。在我们的实验中,我们使用1 A100(这个可以有!)
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage2_finetune.yaml
在第二阶段对齐后,MiniGPT-4能够连贯地谈论图像并且用户友好。
有了第一式做铺垫,再打第二式就不难啦!(▽)
原图奉上⬇️

参考链接🔗:https://github.com/km1994/LLMsNineStoryDemonTower/tree/main/mingpt4