1.介绍
1.1 核心观点
当时的所有的重建目标都是关于低级图像元素的,低估了高级语义。
【Q】怎么去定义高级和低级语义
1.2 基本流程
VQ-KD编码器首先根据可学习码本将输入图像转换为离散令牌
然后,解码器学习重建由教师模型编码的语义特征,以离散令牌为条件
在训练VQ-KD之后,其编码器被用作BEIT预训练的语义视觉标记器,其中离散代码用作监督信号。
1.3 核心贡献
•我们提出了矢量量化的知识提取(vector-quantized knowledge distillation),将掩蔽图像建模从像素级提升到语义级,用于自监督表示学习。
•我们引入了一种补丁聚合策略,该策略在给定离散语义令牌的情况下强制执行全局结构,并提高了学习表示的性能。
2. 方法
该框架使用视觉标记器将每个图像转换为一组离散的视觉标记。训练目标是恢复掩蔽的视觉标记,每个视觉标记对应于一个图像补丁。
【Q】使用VQ-KD编码器有什么好处?

2.1 训练视觉分词器(Visual Tokenizer)
2.1.1 视觉分词器
分词器由Vit编码器和量化器组成。
2.1.2 训练视觉分词器的基本流程
- 标记器首先将输入图像编码为矢量。
- 矢量量化器在码本中查找每个补丁表示hi的最近邻居。
- 量化视觉标记送入解码器
- 最大化解码器输出
和教师指导
之间的余弦相似性。
2.1.3 量化过程
设{v1,v2,··,vK}表示码本嵌入。

这个公式表示了查找每个补丁在codebook中的最近邻居。
由于量化过程是不可微分的,所以梯度被直接从解码器输入复制到编码器输出(下图)
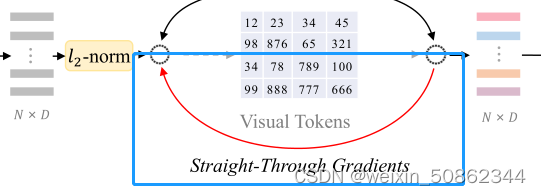
2.1.4 视觉分词器的训练目标
最大化解码器输出和教师指导
之间的余弦相似性。
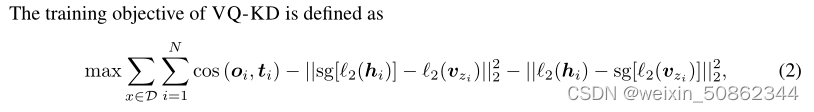
2.1.5 提高码本利用率
为了缓解码本崩溃(codebook collapse,即只使用了一小部分code)。
- 在被送入解码器之前被映射回高维空间,因为量化过程会将码本嵌入空间的维数减少到32-d
- 使用指数移动平均用于更新码本嵌入
2.2 预训练BEIT v2
- 输入准备了一个可学习的[CLS]token,最后的编码向量中的h0表示[CLS]令牌。
- 使用全连接层作为MIM头和softmax分类器预测掩蔽位置的视觉标记
,其中Wc、bc分别表示MIM头的权重和偏置。
- MIM的训练损失定义为

D表示预训练图像,M表示掩蔽位置
2.2.1 预训练全局表示

- 预训练了用于全局图像表示的[CLS]令牌,为了减轻补丁级预训练和图像级表示聚合之间的差异
- 为了预训练最后一层的[CLS]标记
,将最后一层的[CLS]标记
- 该令牌在预训练后被丢弃
3.代码
3.1 训练Vector-Quantized Visual Tokenizers

3.1.1 编码器
编码器部分 = base-vit + FFN降维 + NormEMAVectorQuantizer(量化器)
将作为encoder的vit得到的feature降维到32

3.1.2 解码器
编码器部分 = 一层的vit + FFN

3.1.3 损失
损失由两部分构成:①量化器得到的损失 ②余弦相似损失
【todo】量化器!!!!
3.2 预训练 beit V2
基本上和beit相近
代码中有两种vit:一种就是普通的vit,这个老生常谈就不说了,另一种就是论文中增加了cls的VisionTransformerForMaskedImageModelingCLS。(如下图)

3.2.1 补丁聚合
正如论文,
较浅的头部(即1/2层)比较深的头部(如3层)表现更好,这表明较浅的头比较深头部更关注输入[CLS]令牌。
取用了第6层(总共12层)的patch和最后一层的cls送入两层的一个vit结构中,作为全局聚合

全局聚合部分只取cls
损失函数最后就由两部分组成:①MIM损失②全局cls损失

![[Web程序设计]实验:会话技术应用](https://img-blog.csdnimg.cn/c14e06b98aa44457afcc4d499cb66fe0.jpeg)