目录
分布式文件处理系统HDFS
分布式文件系统
HDFS简介
块(block)
主要组件的功能
**名称节点
FsImage文件
名称节点的启动
名称节点运行期间EditLog不断变大的问题
SecondaryNameNode的工作情况
数据节点
HDFS体系结构
HDFS体系结构的局限性
HDFS存储原理
冗余数据保存
数据存取策略
数据错误与恢复
***HDFS读写数据的流程
分布式数据库HBase
概述
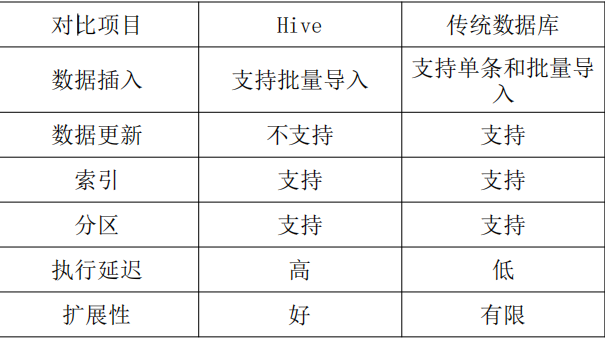
HBase与传统关系数据库的对比分析
HBase数据模型
数据坐标
行式存储结构和列式存储结构
Hbase的实现原理
表和Region的关系
Region的定位
HBase的三层结构中各层次的名称和作用
客户端访问数据时的“三级寻址”
Hbase的运行机制
HBase系统架构
Region服务器工作原理
Store工作原理
HLog工作原理
MapReduce
概述
mapreduce的优点
mapreduce设计理念
Master/slave架构
MapReduce体系结构
MapReduce工作流程
Shuffle过程原理
WordCount实例
Hive
概述
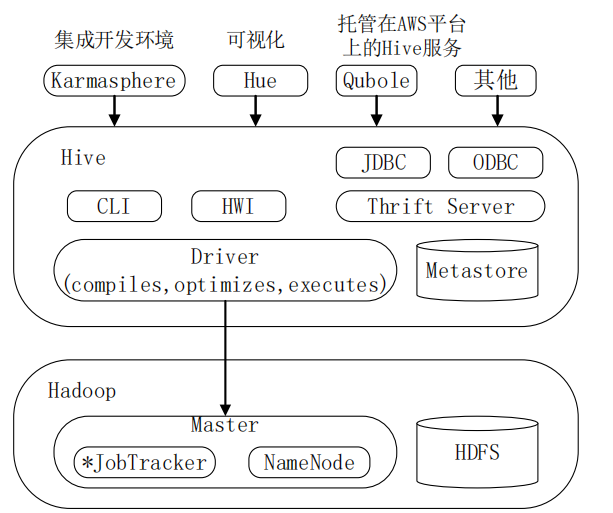
Hive与Hadoop生态系统中其他组件的关系
Hive与传统数据库的对比分析
Hive系统架构
Hive工作原理
SQL语句转换成MapReduce的基本原理
SQL查询转换成MapReduce作业的过程
Spark
概述
spark的特点
Spark与Hadoop的对比
Spark和Hadoop的执行流程对比
Spark运行架构
基本概念
架构设计
Application
Spark运行基本流程
RDD
RDD在Spark架构中的运行过程
代码+shell
MapReduce
HBase
Hive
分布式文件处理系统HDFS
分布式文件系统
分布式文件系统中计算机集群的结构:
- 分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群;
- 优点:与之前使用多个处理器和专用高级硬件的并行化处理装置不同的是,目前的分布式文件系统所采用的计算机集群,都是由普通硬件构成的,这就大大降低了硬件上的开销
分布式文件系统组成:
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode),另一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)
HDFS简介
目标:

局限性:

块(block)
HDFS默认一个块64MB(Hadoop3中是128MB),一个文件被分成多个块,以块作为存储单位
块的大小远远大于普通文件系统,可以最小化寻址开销
优点:

主要组件的功能
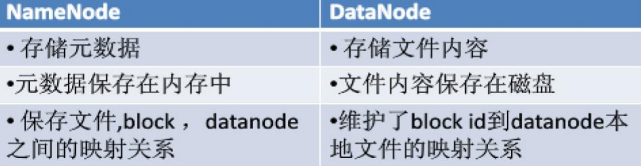
**名称节点
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog
- FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
- 操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作
名称节点记录了每个文件中各个块所在的数据节点的位置信息。
FsImage文件
- FsImage文件包含文件系统中所有目录和文件inode的序列化形式。每个inode是一个文件或目录的元数据的内部表示,并包含此类信息:文件的复制等级、修改和访问时间、访问权限、块大小以及组成文件的块。对于目录,则存储修改时间、权限和配额元数据
- FsImage文件没有记录块存储在哪个数据节点。而是由名称节点把这些映射保留在内存中,当数据节点加入HDFS集群时,数据节点会把自己所包含的块列表告知给名称节点,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的
名称节点的启动
- 在名称节点启动的时候,它会将FsImage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
- 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件
- 名称节点起来之后,HDFS中的更新操作会重新写到EditLog文件中,因为FsImage文件一般都很大(GB级别的很常见),如果所有的更新操作都往FsImage文件中添加,这样会导致系统运行的十分缓慢,但是,如果往EditLog文件里面写就不会这样,因为EditLog 要小很多。每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新
名称节点运行期间EditLog不断变大的问题
- 在名称节点运行期间,HDFS的所有更新操作都是直接写到EditLog中,久而久之, EditLog文件将会变得很大
- 虽然这对名称节点运行时候是没有什么明显影响的,但是,当名称节点重启的时候,名称节点需要先将FsImage里面的所有内容映像到内存中,然后再一条一条地执行EditLog中的记录,当EditLog文件非常大的时候,会导致名称节点启动操作非常慢,而在这段时间内HDFS系统处于安全模式,一直无法对外提供写操作,影响了用户的使用
解决方法:
使用2NN:第二名称节点是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS元数据信息的备份,并减少名称节点重启的时间。SecondaryNameNode一般是单独运行在一台机器上
SecondaryNameNode的工作情况
(1)SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
(2)SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
(3)SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;
(4)SecondaryNameNode执行完(3)操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上
(5)NameNode将从SecondaryNameNode接收到的新的FsImage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了
数据节点
- 数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
- 每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中
HDFS体系结构
主从结构模型:

命名空间管理:
- HDFS的命名空间包含目录、文件和块
- 在HDFS1.0体系结构中,在整个HDFS集群中只有一个命名空间,并且只有唯一一个名称节点,该节点负责对这个命名空间进行管理
- HDFS使用的是传统的分级文件体系,因此,用户可以像使用普通文件系统一样,创建、删除目录和文件,在目录间转移文件,重命名文件等
通信协议:

客户端:

HDFS体系结构的局限性

HDFS存储原理
冗余数据保存
作为一个分布式文件系统,为了保证系统的容错性和可用性,HDFS采用了多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分布到不同的数据节点上
优点:

数据存取策略
数据存放:

数据读取:

数据错误与恢复
名称节点出错:

数据节点出错:

数据出错:

***HDFS读写数据的流程
分布式数据库HBase
概述
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表

HBase与传统关系数据库的对比分析

HBase数据模型
Hbase数据模型的结构:

数据坐标
HBase中需要根据行键、列族、列限定符和时间戳来确定一个单元格,因此,可以视为一个“四维坐标”,即[行键, 列族, 列限定符, 时间戳]
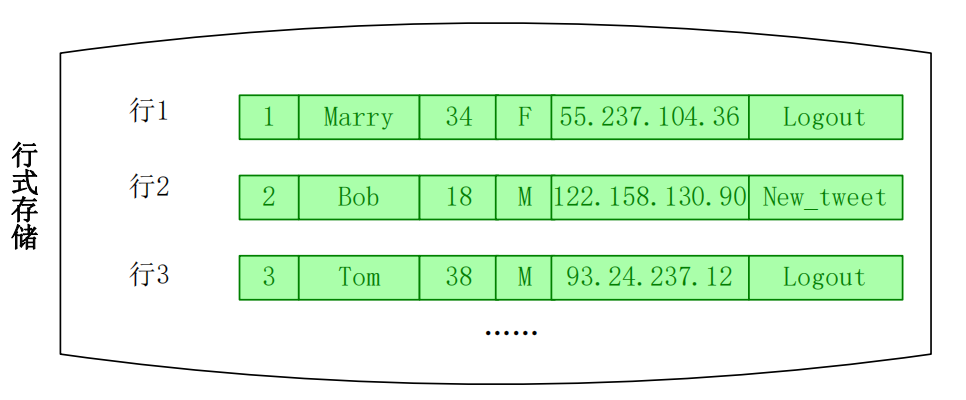
行式存储结构和列式存储结构
Hbase的实现原理
HBase的实现包括三个主要的功能组件:
(1)库函数:链接到每个客户端
(2)一个Master主服务器
(3)许多个Region服务器

表和Region的关系
一个HBase表被划分成多个Region
一个Region会分裂成多个新的Region
- 开始只有一个Region,后来不断分裂
- Region拆分操作非常快,接近瞬间,因为拆分之后的Region读取的仍然是原存储文件,直到“合并”过程把存储文件异步地写到独立的文件之后,才会读取新文件

Region的定位
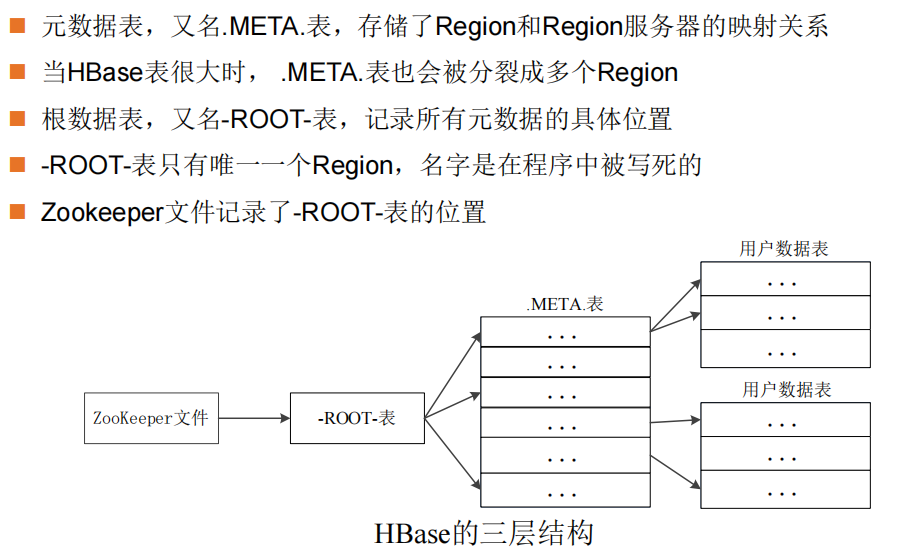
HBase的三层结构中各层次的名称和作用
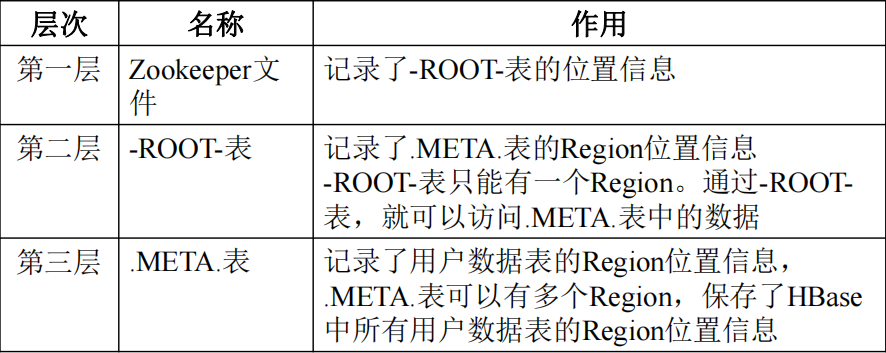
三层结构保存Region的能力:

客户端访问数据时的“三级寻址”
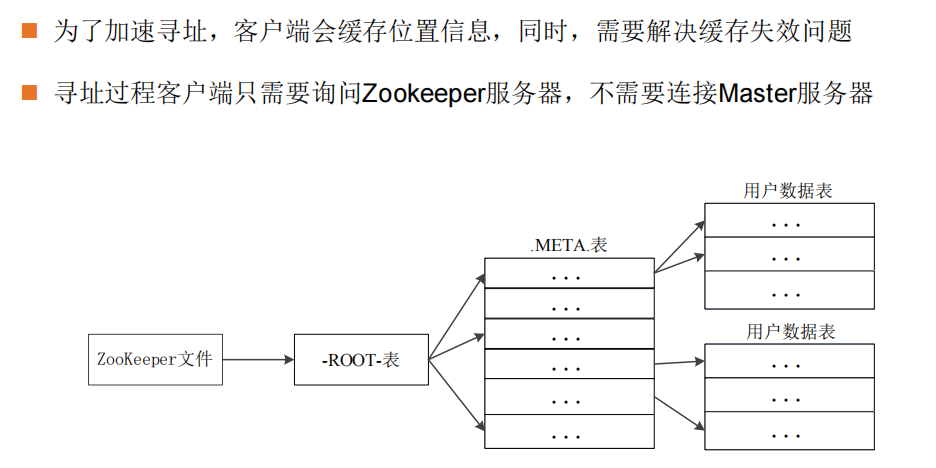
Hbase的运行机制
HBase系统架构
- 客户端
– 客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程 - Zookeeper服务器
– Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题 - Master:主服务器Master主要负责表和Region的管理工作:
– 管理用户对表的增加、删除、修改、查询等操作
– 实现不同Region服务器之间的负载均衡
– 在Region分裂或合并后,负责重新调整Region的分布
– 对发生故障失效的Region服务器上的Region进行迁移
- Region服务器
– Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求分布式数据库
Region服务器工作原理
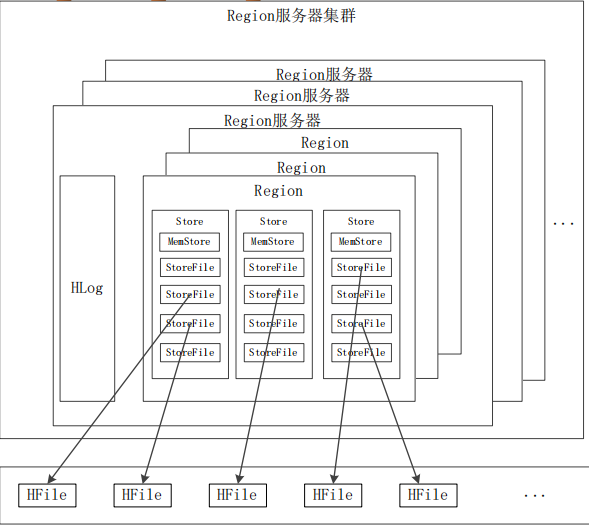

Store工作原理

HLog工作原理
HLog的作用:保证系统恢复
- HBase系统为每个Region服务器配置了一个HLog文件,它是一种预写式日志(Write Ahead Log)
- 用户更新数据必须首先写入日志后,才能写入MemStore缓存,并且,直到MemStore缓存内容对应的日志已经写入磁盘,该缓存内容才能被刷写到磁盘
HLog工作流程:

MapReduce
概述
mapreduce的优点
mapreduce设计理念
计算向数据靠拢:移动数据需要大量的网络传输开销

Master/slave架构

MapReduce体系结构
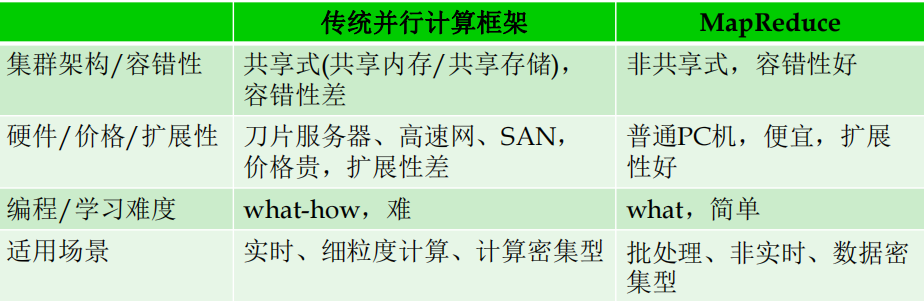
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
![]()

MapReduce工作流程

Map任务数量:Hadoop为每个split创建一个Map任务,split 的多少决定了Map任务的数目。大多数情况下,理想的分片大小是一个HDFS块
Reduce任务的数量:
- 最优的Reduce任务个数取决于集群中可用的reduce任务槽(slot)的数目
- 通常设置比reduce任务槽数目稍微小一些的Reduce任务个数(这样可以预留一些系统资源处理可能发生的错误)
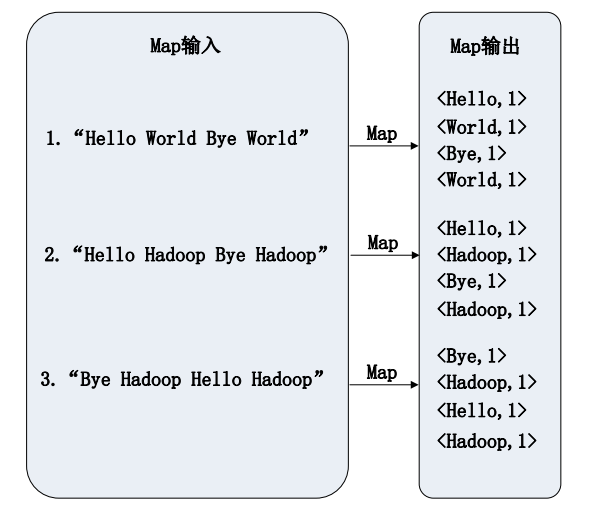
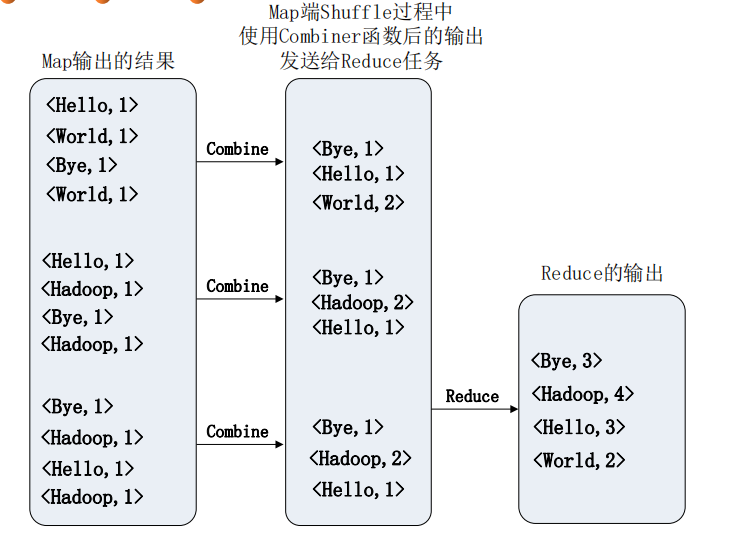
Shuffle过程原理
Map端的Shuffle过程:

Reduce端的Shuffle过程:

合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>
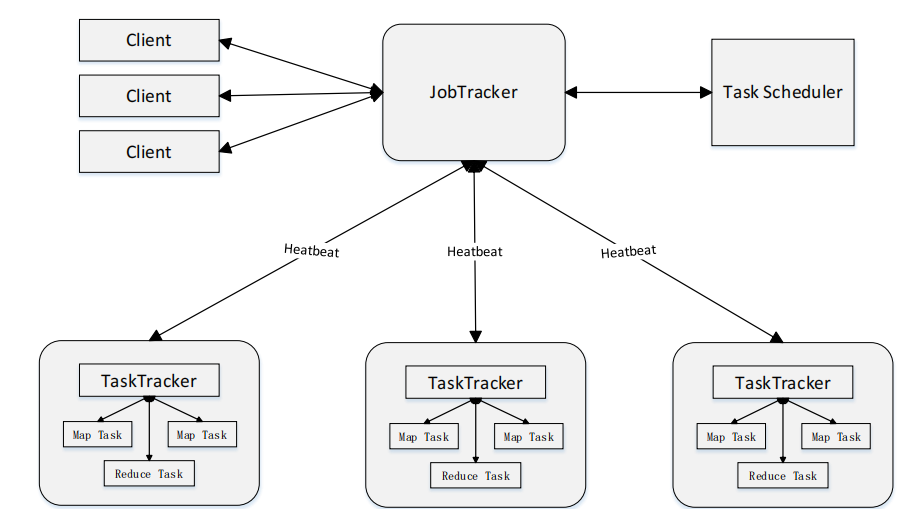
WordCount实例
Map阶段:
Shuffle:
Combine:
Hive
概述
Hive是一个构建于Hadoop顶层的数据仓库工具
- 依赖分布式文件系统HDFS存储数据(HDFS作为高可靠性的底层存储,用来存储海量数据)
- 依赖分布式并行计算模型MapReduce处理数据(Hive需要把HiveQL语句转换成MapReduce任务进行运行)
Hive与Hadoop生态系统中其他组件的关系

Hive与传统数据库的对比分析
Hive系统架构
Hive工作原理
SQL语句转换成MapReduce的基本原理
①join的实现原理:
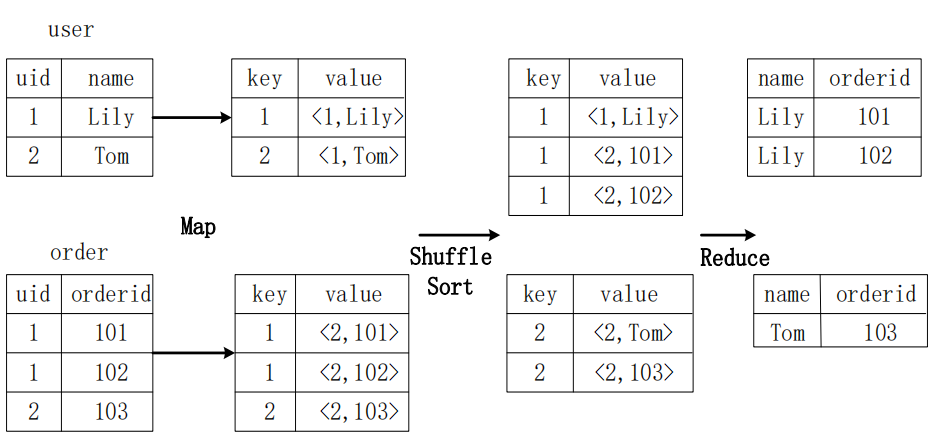
②group by的实现原理:
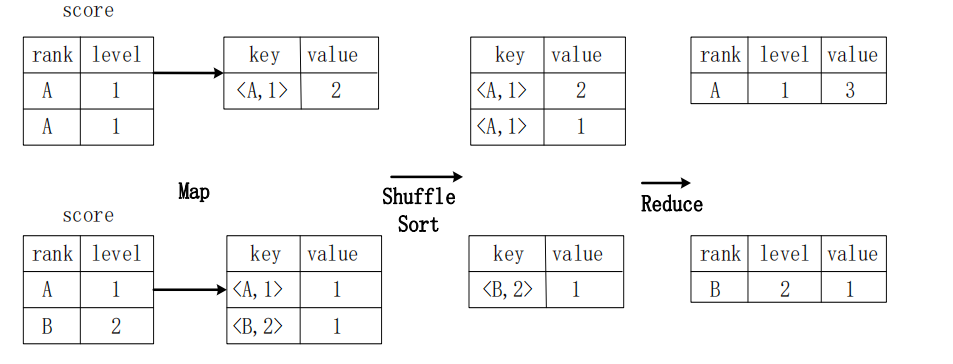
SQL查询转换成MapReduce作业的过程
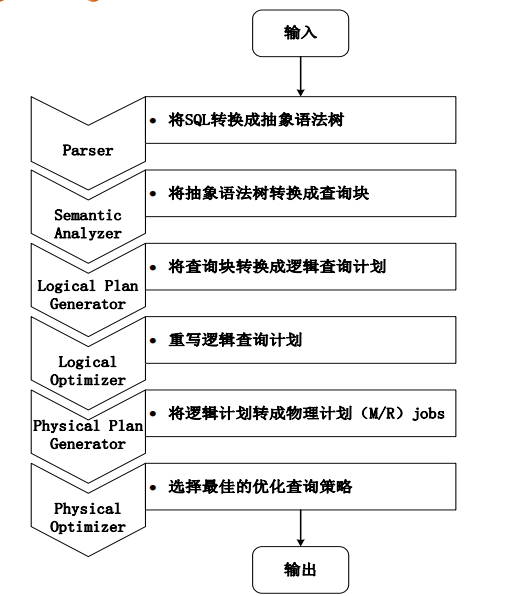
Spark
概述
spark的特点
- 运行速度快:使用DAG执行引擎以支持循环数据流与内存计算
- 容易使用:支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程
- 通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件
- 运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源
Spark与Hadoop的对比
相比于Hadoop MapReduce,Spark主要具有如下优点:
◼ Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活
◼ Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
◼ Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
Spark和Hadoop的执行流程对比

使用Hadoop进行迭代计算非常耗资源,而Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据
Spark运行架构
基本概念
◼ RDD:是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
◼ DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系
◼ Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task
◼ Application:用户编写的Spark应用程序
◼ Task:运行在Executor上的工作单元
◼ Job:一个Job包含多个RDD及作用于相应RDD上的各种操作
◼ Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集
架构设计
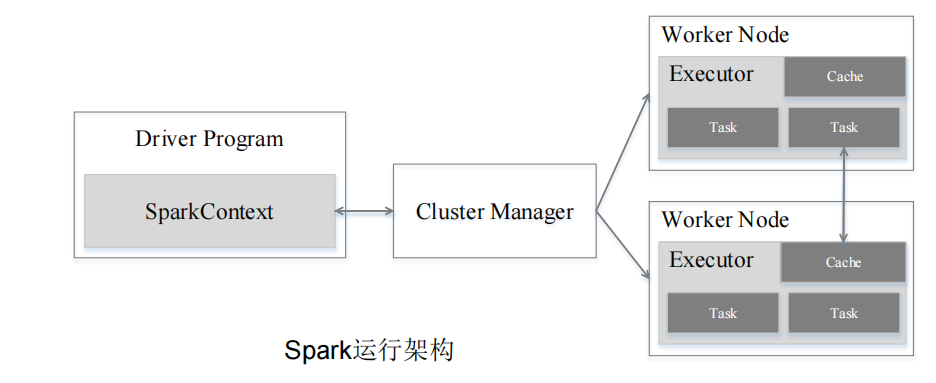
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:
◼ 一是利用多线程来执行具体的任务,减少任务的启动开销
◼ 二是Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,有效减少IO开销
Application
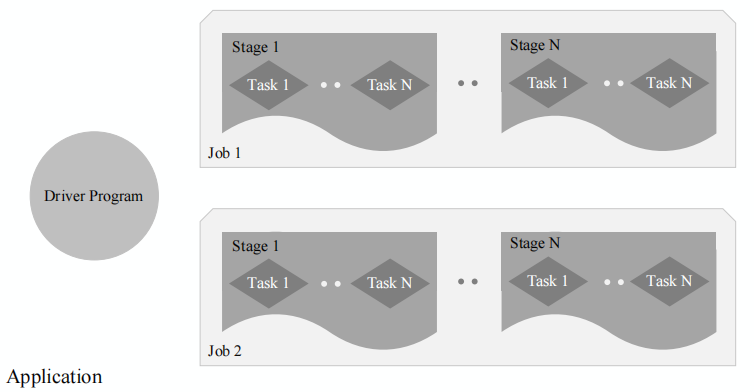
◼ 一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成
◼ 当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其他数据库中
Spark运行基本流程
(1)首先为应用构建起基本的运行环境,即由Driver创建一个SparkContext,进行资源的申请、任务的分配和监控
(2)资源管理器为Executor分配资源,并启动Executor进程
(3)SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理;Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行,并提供应用程序代码
(4)Task在Executor上运行,把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源
RDD
RDD的作用:
RDD提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储
RDD的概念:
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和group by)而创建得到新的RDD
RDD运行原理:
通过“动作”(Action)和“转换”(Transformation)算子进行运算
执行过程如下:
◼ RDD读入外部数据源进行创建
◼ RDD经过一系列的转换(Transformation)操作,每一次都会产生不同的RDD,供给下一个转换操作使用
◼ 最后一个RDD经过“动作”操作进行转换,并输出到外部数据源
RDD特性:
- 高效的容错性:血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同节点之间并行、只记录粗粒度的操作
- 中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递,避免了不必要的读写磁盘开销
- 存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化
RDD之间的依赖关系:
- 窄依赖表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区
- 宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区
Stage的划分:
◼ 在DAG中进行反向解析,遇到宽依赖就断开
◼ 遇到窄依赖就把当前的RDD加入到Stage中
◼ 将窄依赖尽量划分在同一个Stage中,可以实现流水线计算
两种不同的Stage:

RDD在Spark架构中的运行过程
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。
代码+shell
MapReduce
wordCount案例:
Mapper类:
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
Reducer类:
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}
Driver驱动类:
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 关联本Driver程序的jar
job.setJarByClass(WordCountDriver.class);
// 3 关联Mapper和Reducer的jar
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置Mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
提交到集群运行:
hadoop jar jar包路径 全类名 输入路径 输出路径
示例:
hadoop jar wc.jar com.atguigu.mapreduce.wordcount.WordCountDriver /user/atguigu/input /user/atguigu/output
HBase
启动:bin/start-hbase.sh
停止:bin/stop-hbase.sh
进入shell操作:bin/hbase shell
shell命令:
创建表:create 'student','Sname','Ssex','Sage','Sdept','course'
插入数据:
①put 'student','95001','Sname','LiYing'(为student表添加了学号为95001,名字为LiYing的一行数据,其行键为95001)
②put 'student','95001','course:math','80'(为95001行下的course列族的math列添加了一个数据)
删除数据:
①delete 'student','95001','Ssex'(删除了student表中95001行下的Ssex列的所有数据)
②deleteall 'student','95001'(删除了student表中的95001行的全部数据)
查看数据:
①get 'student','95001'(返回的是‘student’表‘95001’行的数据)
②scan 'student'(返回的是‘student’表的全部数据)
删除表
第一步:disable 'student' :让表不可用
第二步:drop 'student':删除表
查询表历史数据:
1.创建表的时候指定版本:create 'teacher',{NAME=>'username',VERSIONS=>5}
2.插入数据:
1.put 'teacher','91001','username','Mary' 2.put 'teacher','91001','username','Mary1' 3.put 'teacher','91001','username','Mary2' 4.put 'teacher','91001','username','Mary3' 5.put 'teacher','91001','username','Mary4' 6.put 'teacher','91001','username','Mary5'
3.查询时指定版本即可:
get 'teacher','91001',{COLUMN=>'username',VERSIONS=>5}
即可查询出最新的5个版本的数据:

Hive
hive-site.xml文件
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<!-- H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 远程模式部署metastore metastore地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
</configuration>