大数据下批处理性能问题分析优化分享
互联网+的步伐加速了硬件资源的发展,而硬件资源的改进,促进社会的建设的快速发展,特别是这互联互通大数据时代,多用户大数据下,单核服务器无法承受处理,特别是对于一个并发量大,业务需求和数据类型多样化、数据量大的复杂系统,在架构上虽然是可以千变万化但是,需要综合考虑才能设计出合理的系统架构,这样的系统才是王道。
例如CPU硬件采购考虑,多个独立的CPU来说确保系统的运算性能。因为多个单核CPU,每个CPU都有自己独立的芯片组件来完成系统运算,也就是有自己 进行快速数据交换的CACHE和其他外设交互的控制器,但是大部分服务器默认情况下,对应用服务都是单线程使用,满足基本功能操作,但是对于大型服务,大数据高并发性,需要调整对应参数才能真正充分利用多核多线程;而oracle 自从8i开始就赶上硬件发展步伐,在技术架构山支持多CPU同时处理并行处理能力,它在每个数据库函数中都实现了并行性,包括sql访问(全表检索)、并行数据操作和并行恢复等功能实现,当然cpu使用颗粒数跟oracle对应采购版本也有关系,当然Oracle并行执行也是一种分而治之的方法。执行一个sql时,分配多个并行进程同时执行数据扫描、连接以及聚合等操作也就是多个CPU来并行处理,使用更多的资源,得到更快的sql响应时间。并行执行是充分利用硬件资源,处理大量数据时的核心技术。
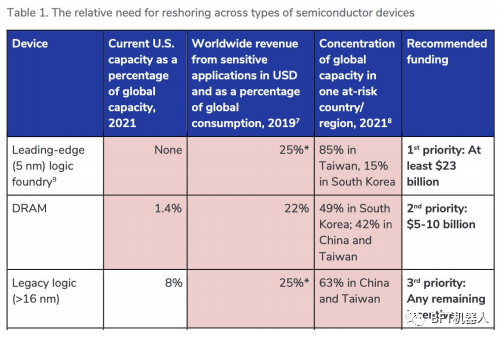
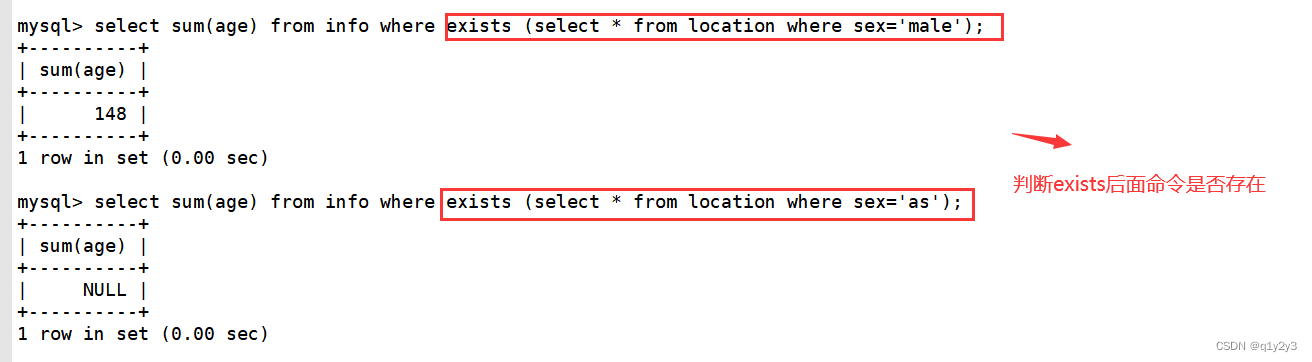
例如某个大型企业财务监管报送系统,出现日终跑批,一个进程作业几个小时都没办法正常跑批处理数据,项目技术经理打电话咨询问题如何定位和优化处理,通过经理的耐心讲解,了解了生产系统软硬件环境,应用服务tomcat8、数据库服务是oracle、linux操作系统,通过分析各服务器资源使用情况,发现就数据库服务器资源使用比较异常,环境监测对应批处理服务执行过程的资源使用情况,如下图:

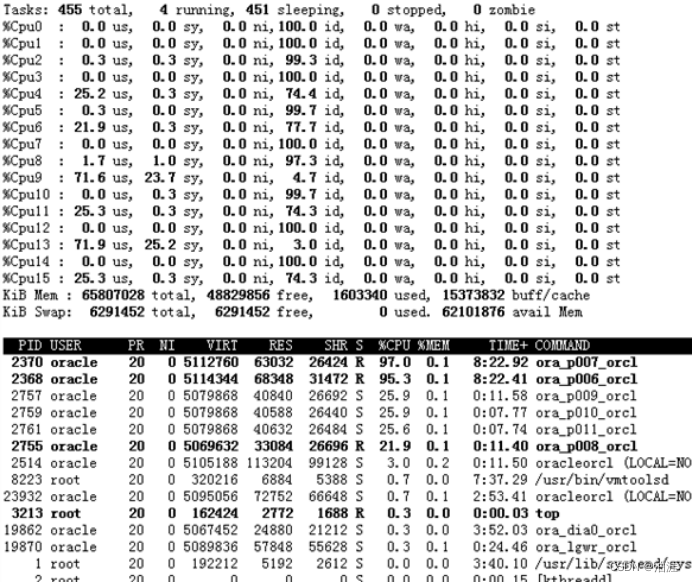
可以看到在执行该批处理作业时,oracle进程CPU使用率100%,但是总的有16个CPU线程,监控到的只有2个CPU线程在执行,通过PLSQL参数查看分析,发现oracle参数使用的都是默认最低配置,没有进行调整,如下图:
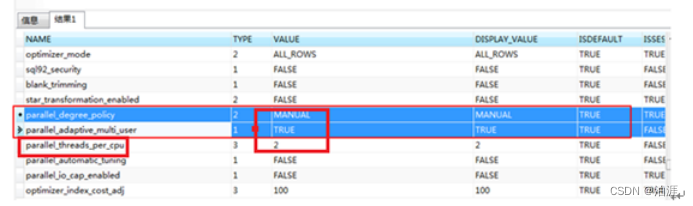
初步分析应该是oracle安装时都是启用默认参数配置,忘记根据服务器硬件资源配置情况进行动态调整参数,例如没有设置充分的把服务器对应的多核CPU配置利用上,因为默认下CPU线程最小配置,例如2个CPU线程使用;
SQL> show parameter parallel
NAME TYPE VALUE
------------------------------------ ---------------------- --------------------
fast_start_parallel_rollback string LOW
parallel_adaptive_multi_user boolean TRUE
parallel_automatic_tuning boolean FALSE
parallel_degree_limit string CPU
parallel_degree_policy string MANUAL
parallel_execution_message_size integer 16384
parallel_force_local boolean FALSE
parallel_instance_group string
parallel_io_cap_enabled boolean FALSE
parallel_max_servers integer 135
parallel_min_percent integer 0
NAME TYPE VALUE
------------------------------------ ---------------------- --------------------
parallel_min_servers integer 0
parallel_min_time_threshold string AUTO
parallel_server boolean FALSE
parallel_server_instances integer 1
parallel_servers_target integer 64
parallel_threads_per_cpu integer 2
解决方法:
对于一个大的任务,一般的做法是利用一个进程,串行的执行,如果系统资源足够,可以采用parallel技术,把一个大的任务分成若干个小的任务,同时启用n个进程/线程,并行的处理这些小的任务,这些并发的进程称为并行执行服务器(parallel executeion server),这些并发进程由一个称为并发协调进程的进程来管理。
例如本次发现的问题,在调整操作系统参数配置后,主要是通过调整Oracle其中核心参数parallel_threads_per_cpu,参数使用描述如下:
parallel_threads_per_cpu
- 参数类型:整型
- 默认值:2
- 修改:修改不需要重启数据库
- 取值范围: 任何非0值
- 基本参数:否
取值意义
该参数指定Orale的默认并行度,描述了一个CPU可处理并行查询进程或线程的数量
默认值在大多数情况下都是可行的,可根据实际负责调整,默认并行度使用如下计算公式;
parallel_threads_per_cpu integer 2
说明: 说明一个 CPU 在并行执行过程中可处理的进程或线程的数量,
并优化并行自适应算法和负载均衡算法。如果计算机在执行一个典型查询时有超负荷的迹象, 应减小该数值。
值范围: 任何非零值。
默认值: 根据操作系统而定 (通常为 2)
通过调整改为8后,在调整PARALLEL_DEGREE_POLICY 为auto,如下截图:

重新执行发现可以充分利用服务器CPU资源,而且整个批处理作业20分钟就执行完成;
总结说明:
对于一个应用来说,为了让应用达到最好的性能和可扩展性,我们不仅仅要充分利用 CPU 周期内可用的部分,而且要让这部分 CPU 的使用更有价值,而不是浪费。能够让 CPU 的周期利用的更充分对于多线程应用运行在多处理器和多核系统上至很有挑战性的。另外,当 CPU 达到饱和状态的时候并不能说明 CPU 的性能和伸缩性已经达到了最佳的状态。