Java集合之LinkedList
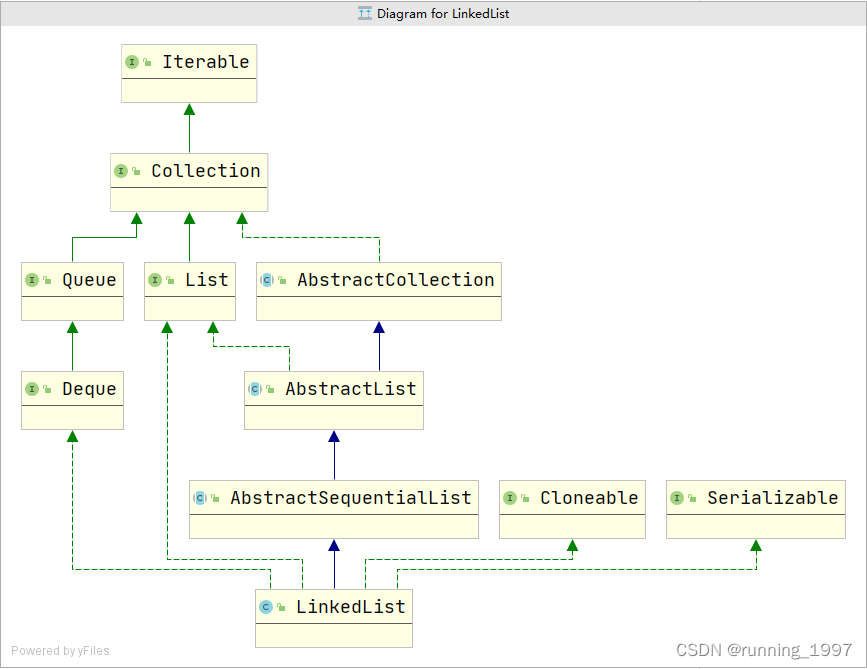
- 一、LinkedList类的继承关系
- 1. 基类功能说明
- 1.1. Iterator:提供了一种方便、安全、高效的遍历方式。
- 1.2. Collection:为了使ArrayList具有集合的基本特性和操作。
- 1.3. Queue: LinkedList是一种队列(Queue)数据结构的实现。
- 1.4. List:为了让其具有列表的特性和更多的操作。
- 1.5. AbstractCollection:提供了一些通用的集合操作。
- 1.6. Deque: 使得LinkedList可以满足更多的使用场景,例如实现双端队列、实现栈等数据结构。
- 1.7. AbstractList:为了使其具有列表的抽象特性和操作。
- 1.8. AbstractSequentialList:可以更方便地实现List接口中的方法,同时也提供了一些保护方法,供LinkedList实现自己特有的方法。
- 1.9. Cloneable:支持克隆操作。
- 10. Serializable:支持序列化。
- 二、LinkedList的优缺点
- 1. 优点:
- 1.1. 高效的插入和删除操作
- 1.2. 不需要预先分配空间
- 1.3. 可以作为双端队列使用
- 2. 缺点:
- 2.1. 随机访问性能较差
- 2.2. 占用更多的内存空间
- 2.3. 不支持随机访问
- 3. 总结
- 三、LinkedList数据结构
- 四、LinkedList源码分析
- 1. 基本属性
- 1.1 size :节点个数
- 1.2 first:头结点
- 1.3 last:尾结点
- 2. 构造方法
- 3. add方法
- 4. set方法
- 5. get方法
- 6. remove方法
- 7. clear方法
- 8. node(index)方法
- 9. unlink方法
- 10. linkBefore方法
- 助解图:
- 11. linkLast方法
- 五、常见遍历方式
- LinkedList有以下4种常见的遍历方式:
- 1、使用for循环遍历:
- 2、使用foreach循环遍历:
- 3、使用Iterator遍历:
- 4、使用ListIterator遍历:
一、LinkedList类的继承关系
1. 基类功能说明
1.1. Iterator:提供了一种方便、安全、高效的遍历方式。
-
Iterator是一个迭代器接口,它提供了一种安全的遍历集合元素的方法,可以避免在遍历过程中修改集合引起的ConcurrentModificationException异常,同时还可以避免在遍历过程中删除集合元素时出现索引越界等问题。
-
LinkedList使用Iterator遍历集合时,可以使用hasNext()方法判断是否还有元素,使用next()方法获取下一个元素,使用remove()方法安全地删除当前元素。因此,使用Iterator遍历LinkedList既方便又安全,是一种非常推荐的遍历方式。
-
另外,Iterator接口是Java集合框架中的一部分,实现Iterator接口可以使LinkedList更加符合集合框架的统一标准,方便与其他集合类一起使用。
1.2. Collection:为了使ArrayList具有集合的基本特性和操作。
- LinkedList是Java中常用的集合类之一,它实现了Collection接口,这是为了使LinkedList具有集合的基本特性和操作,例如添加、删除、遍历等。
- 实现Collection接口可以让LinkedList能够和其他Java集合类兼容,可以方便地进行集合之间的转换和使用。同时,实现Collection接口也使得LinkedList能够支持泛型,可以在编译期间进行类型检查,避免了运行时出现类型错误的问题。
- 总之,LinkedList实现Collection接口是为了使其具有更多的特性和更好的兼容性。
1.3. Queue: LinkedList是一种队列(Queue)数据结构的实现。
- Queue接口定义了一些基本的队列操作,例如添加元素、删除元素、查看队首元素等,LinkedList实现了这些操作,因此可以被视为一种队列数据结构。
1.4. List:为了让其具有列表的特性和更多的操作。
- ArrayList实现了List接口,是为了使其具有列表的特性和操作,例如按索引访问元素、插入、删除、替换等。List是Collection接口的子接口,提供了更多针对列表的操作。
- 例如按索引操作、排序、子列表等。因此,实现List接口可以让ArrayList具有更多的操作和更好的兼容性,可以和其他实现List接口的Java集合类进行交互和转换。
1.5. AbstractCollection:提供了一些通用的集合操作。
- 例如containsAll、removeAll、retainAll等方法,这些方法可以被ArrayList直接继承和使用,从而避免了重复实现这些操作。
- 同时,AbstractCollection也提供了一些抽象方法,例如size、iterator、toArray等方法,这些方法需要由具体的集合类去实现,LinkedList也需要实现这些方法以完成自身的功能。
1.6. Deque: 使得LinkedList可以满足更多的使用场景,例如实现双端队列、实现栈等数据结构。
- 这使得LinkedList可以满足更多的使用场景,例如实现双端队列、实现栈等数据结构。同时,LinkedList还可以在队首和队尾进行高效的插入和删除操作,因为它的底层实现是双向链表,而双向链表可以在常数时间内进行插入和删除操作。
- 因此,LinkedList继承Deque接口的作用在于让LinkedList具备了双端队列的功能,同时也提高了LinkedList的灵活性和可用性。
1.7. AbstractList:为了使其具有列表的抽象特性和操作。
-
AbstractList是List接口的一个抽象实现,实现了List接口的大部分方法,包括添加、删除、获取元素、遍历等。
-
LinkedList作为List接口的一个具体实现,需要实现List接口中定义的所有方法。
-
通过继承AbstractList抽象类,LinkedList可以重用AbstractList中已经实现的方法,减少重复代码,提高代码的复用性和可维护性。
-
另外,AbstractList还提供了一些抽象方法,例如get()、set()、add()、remove()等,这些抽象方法需要LinkedList子类实现,从而使得LinkedList具备列表的基本操作。
-
AbstractList还提供了一些模板方法,例如addAll()、removeAll()等,这些方法可以通过调用抽象方法实现具体的操作。通过继承AbstractList抽象类,LinkedList可以利用这些模板方法快速实现各种列表操作,提高了开发效率。
-
综上所述,LinkedList实现了AbstractList抽象类是为了重用AbstractList中已经实现的方法,提高代码的复用性和可维护性,同时也能够利用AbstractList中提供的模板方法快速实现各种列表操作。
1.8. AbstractSequentialList:可以更方便地实现List接口中的方法,同时也提供了一些保护方法,供LinkedList实现自己特有的方法。
-
AbstractSequentialList是一个抽象类,它实现了List接口中大部分方法,例如add、remove、get、set等。而这些方法的实现都是基于迭代器(Iterator)进行的,迭代器是用于遍历集合中元素的一个对象。因此,继承AbstractSequentialList可以让LinkedList更容易地实现List接口中的这些方法,只需要实现迭代器即可。
-
另外,AbstractSequentialList还提供了一些保护方法(protected method),例如getIterator、getListIterator等,可以供子类使用。LinkedList继承了AbstractSequentialList后,可以使用这些保护方法来实现自己特有的方法。
-
总之,LinkedList继承AbstractSequentialList的作用在于可以更方便地实现List接口中的方法,同时也提供了一些保护方法,供LinkedList实现自己特有的方法。
1.9. Cloneable:支持克隆操作。
-
Cloneable接口是一个标记接口,用于表示实现该接口的对象可以进行克隆操作。
-
在LinkedList中,克隆操作可以用于创建一个与原列表相同的新列表,这个新列表与原列表相互独立,对新列表的修改不会影响到原列表。这在某些场景下非常有用,例如需要对一个列表进行操作,但是又需要保留原列表不变的情况下,可以先克隆出一个新列表进行操作。
-
需要注意的是,LinkedList实现Cloneable接口只是表示它支持克隆操作,并不代表它的克隆操作一定是完全正确和安全的。在进行克隆操作时,需要注意可能存在的浅拷贝和深拷贝问题,以及可能会影响到对象的不变性和线程安全性问题等。
-
因此,在使用LinkedList的克隆操作时,需要仔细考虑其对程序的影响,并进行必要的安全性和正确性检查。
10. Serializable:支持序列化。
- 序列化是将对象转换为字节流的过程,可以用于持久化对象、网络传输等操作。实现Serializable接口可以让LinkedList的实例对象被序列化,以便于在需要的时候进行序列化操作。
二、LinkedList的优缺点
1. 优点:
1.1. 高效的插入和删除操作
- 由于LinkedList底层实现是双向链表,因此在插入和删除操作方面具有高效性。在链表的任意位置插入或删除一个元素的时间复杂度是O(1),而在数组中插入或删除元素的时间复杂度是O(n)。
1.2. 不需要预先分配空间
- 由于LinkedList是动态的数据结构,因此在使用时不需要预先分配空间,可以根据需要动态地添加或删除元素,使得空间利用率更高。
1.3. 可以作为双端队列使用
- 由于LinkedList实现了Deque接口,因此可以在队首和队尾进行高效的插入和删除操作,使得LinkedList可以作为双端队列使用。
2. 缺点:
2.1. 随机访问性能较差
- 由于LinkedList底层实现是链表,因此在访问某个元素时需要从头开始遍历整个链表,时间复杂度为O(n)。而在数组中,访问某个元素的时间复杂度为O(1)。
2.2. 占用更多的内存空间
- 由于LinkedList需要存储指向下一个元素和上一个元素的指针,因此占用的内存空间相对于数组要更多。
2.3. 不支持随机访问
- 由于LinkedList是基于链表实现的,因此不支持随机访问,只能通过遍历整个链表来访问元素。这也使得LinkedList在某些场景下性能较差,例如在对元素进行排序、查找等操作时。
3. 总结
- 总之,LinkedList的优点在于高效的插入和删除操作、不需要预先分配空间、可以作为双端队列使用;缺点在于随机访问性能较差、占用更多的内存空间、不支持随机访问。因此,在使用LinkedList时需要根据具体的场景进行选择。
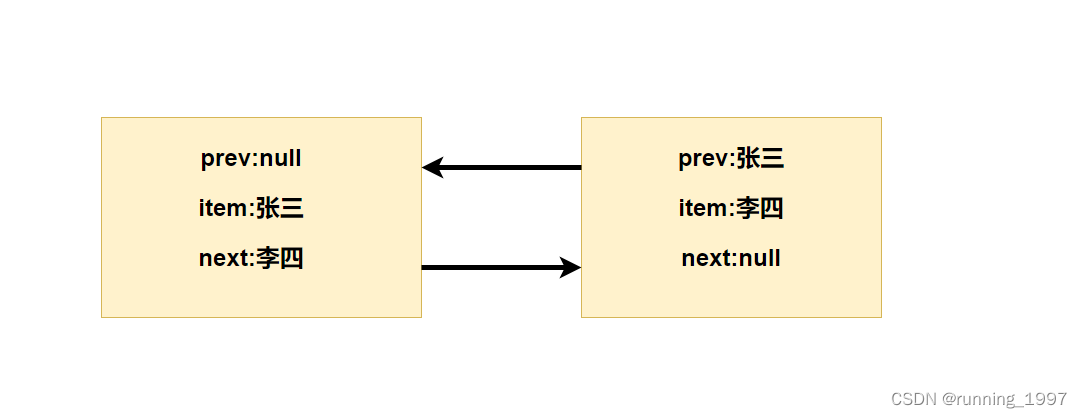
三、LinkedList数据结构
四、LinkedList源码分析
1. 基本属性
1.1 size :节点个数
transient int size = 0;
1.2 first:头结点
transient Node<E> last;
1.3 last:尾结点
transient Node<E> last;
2. 构造方法
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
- 无参构造方法:因为底层是双向链表,所以无需指定初始长度。
- 有参构造方法:创建一个包含指定Collection中所有元素的LinkedList对象。
- 这两个构造方法的使用场景如下:
3.1 无参构造方法可以用于创建一个空的LinkedList对象,然后通过add()方法逐个添加元素。
3.2 带有Collection参数的构造方法可以用于创建一个包含指定元素的LinkedList对象,例如:
List<Integer> list = Arrays.asList(1, 2, 3);
LinkedList<Integer> linkedList = new LinkedList<>(list);
- 总之,LinkedList的两个构造方法分别用于创建一个空的LinkedList对象和创建一个包含指定元素的LinkedList对象。通过这两个构造方法,我们可以实现LinkedList的快速创建和初始化。
3. add方法
public boolean add(E e) {
linkLast(e);
return true;
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
add(E e) :调用linkLast方法将当前元素添加到链表尾部。(linkLast见下文)
add(int index, E element):
- 调用checkPositionIndex校验下标是否越界(index >= 0 && index <= size)。
- 如果要添加的元素下标位于链表的最后一个,则调用linkLast方法追加到链表尾部。
- 否则不是最后一个,调用linkBefore方法将元素插入指定位置。(linkBefore见下文)。
4. set方法
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
- 调用checkPositionIndex校验下标是否越界(index >= 0 && index <= size)
- 调用node(index) (见下文)
- 获取要插入结点的原值oldVal
- 将当前元素设置找到的结点位置
- 返回结点的原值(oldVal )
5. get方法
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
get(int index):
- 调用checkPositionIndex校验下标是否越界(index >= 0 && index <= size)
- 调用node(index) (该方法见下文)
getFirst(): - 返回链表的头结点
6. remove方法
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
remove(int index):
- 调用checkPositionIndex校验下标是否越界(index >= 0 && index <= size)
- 调用node(index) (见下文)
- 调用unlink方法,移除index位置的节点(unlink方见下文)
remove(Object o) :
- 如果 o == null 从链表的第一个结点first开始遍历,寻找结点item属性为null的结点,调用unlink()方法将该节点移除。
- 如果 o 不等于 null 从链表的第一个结点first开始遍历,寻找item属性与之相同的为null的结点,调用unlink()方法将该节点移除。
7. clear方法
public void clear() {
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
- 从头结点first开始遍历,将所有属性item、next、prev置为null。
- 将头尾结点置为null。
- 将size属性设置为0。
- 将modCount++,在这个过程中,LinkedList的结构发生了变化,因此modCount需要+1。
8. node(index)方法
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
- 根据下标调用node(index)找到目标结点
- 判断当前下标位于链表的左侧还是右侧(size >> 1)
- 如果是左侧从first结点开始遍历
- 否则从链表的尾部last结点往前遍历,根据prev指针遍历
9. unlink方法
E unlink(Node<E> x) {//移除链表上的x结点
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
- 分别获取当前结点的ele元素、前驱结点prev、后继结点next
- 如果prev等于null,则头结点first指向next,否则将prev的下一个结点指向当前结点的下一个结点。
- 如果next等于null,将last指向当前要删除结点的前一个结点,也即prev。否则将next的前驱结点指向要删除的前驱结点prev,同时将当前要删除的结点的next指向为null
- 将当前结点的item元素置为null
- size元素数量个数-1
- modCount+1,因为链表结构发生改变了
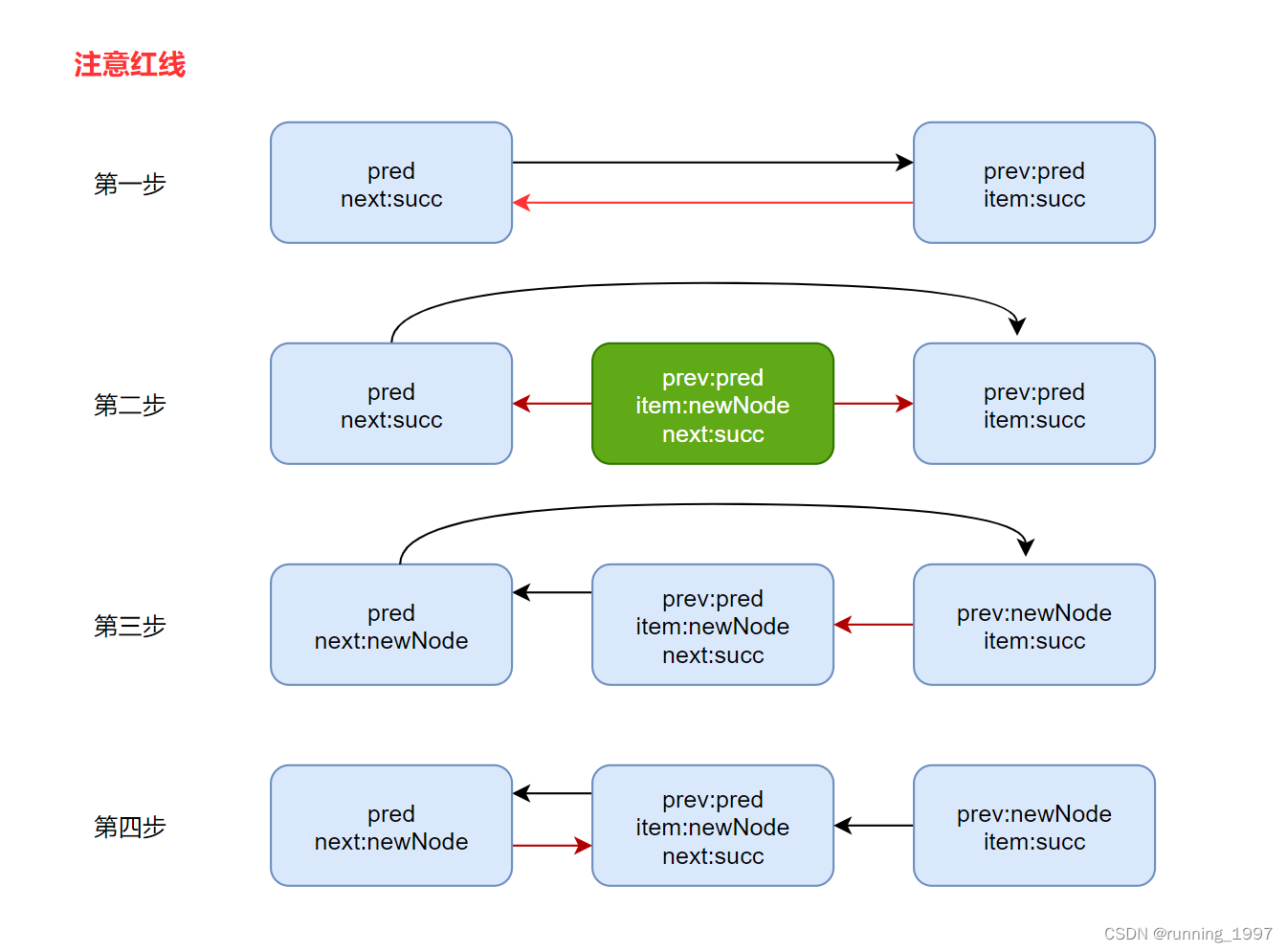
10. linkBefore方法
//将元素e插入succ结点的前面
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
- 定义succ的前驱结点pred
- 构造一个新的结点newNode pred就是前驱结点、e当前元素、succ做为当前newNode 的下一个结点。
- 修改succ结点的前驱结点为newNode
- 如果pred == null 说明链表中只有一个结点succ,则将newNode 作为头结点,将first指向newNode
- 否则pred 不等于null,修改pred的后续结点指向,将pred.next 指向刚刚构造出来的新结点newNode
- 将size+1
- 修改modCount
助解图:
11. linkLast方法
void linkLast(E e) { //将当前元素插入链表的尾部
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
- 将变量 l 指向链表的最后一个结点last(暂存)。
- 把传进来的元素e,构造一个新的结点newNode。
- 将last引用指向newNode。
- 如果l == null,说明链表中没有元素,将first指向newNode,做为头结点。
- 否则l 不等于null,将 newNode 追加为链表的最后一个元素。
- 将链表的size元素数量+1,modCount+1,用来实现快速失败机制。
五、常见遍历方式
LinkedList有以下4种常见的遍历方式:
1、使用for循环遍历:
可以使用for循环和get方法,从头到尾遍历LinkedList中的元素。
for (int i = 0; i < linkedList.size(); i++) {
E element = linkedList.get(i);
// 处理当前元素
}
2、使用foreach循环遍历:
可以使用foreach循环,从头到尾遍历LinkedList中的元素。
for (E element : linkedList) {
// 处理当前元素
}
3、使用Iterator遍历:
可以使用Iterator,从头到尾遍历LinkedList中的元素。
Iterator<E> iterator = linkedList.iterator();
while (iterator.hasNext()) {
E element = iterator.next();
// 处理当前元素
}
4、使用ListIterator遍历:
可以使用ListIterator,从头到尾遍历LinkedList中的元素,还可以在遍历时进行添加、删除、修改等操作。
ListIterator<E> listIterator = linkedList.listIterator();
while (listIterator.hasNext()) {
E element = listIterator.next();
// 处理当前元素
}