创建scrapy项目
创建爬虫项目
scrapy startproject ss1_miove
创建爬虫文件()
命令格式:scrapy genspider <爬虫名称> <网站域名>
scrapy genspider ss1_scrapy ssr1.scrape.center
scrapy框架的组成
spider文件夹:里面存放爬虫文件,用来定义爬虫文件
items文件:定义框架内的数据传输格式
Pipelines文件:数据保护模块
Minddlewwares:中间件模块
settings文件:框架配置模块
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fnU1MSuW-1687664182665)(…/AppData/Roaming/Typora/typora-user-images/image-20230618090031123.png)]
scrapy框架 —爬虫文件
生成Python文件后scrapy会给你一个默认的爬虫模板
生成爬虫文件的命令:scrapy genspider <爬虫名称> <网站域名>
import scrapy
class Ss1ScrapySpider(scrapy.Spider):
name = "ss1_scrapy"
allowed_domains = ["ssr1.scrape.center"]
start_urls = ["https://ssr1.scrape.center"]
def parse(self, response):
pass
| 属性 | 说明 |
|---|---|
| pares()方法 | 默认获取start_urls的解析方法 |
| name | 爬虫的名字 |
| allowed_domains | 能抓取网站的范围 |
| start_urls | 指定开始的url网站(可以指定多个url) |
下面我们要对爬虫文件进行修改以达到对我们的采集需求
import re
import scrapy
from ssr1.ss1_miove.ss1_miove.items import Ss1MioveItem
class Ss1ScrapySpider(scrapy.Spider):
name = "ss1_scrapy"
allowed_domains = ["ssr1.scrape.center"]
start_urls = ["https://ssr1.scrape.center"]
def parse(self, response):
movie_list = response.xpath('//*[@id="index"]/div[1]/div[1]/div')
item = Ss1MioveItem()
for movie in movie_list:
# 获取电影网页中的名称
movie_name = movie.xpath('./div/div/div[2]/a/h2/text()').extract_first()
name = movie_name
# 获取上映时间
movie_dates = movie.xpath('./div/div/div[2]/div[3]/span/text()').extract_first()
if movie_dates is None:
movie_date = '0-0-0'
else:
movie_date = movie_dates[:-3]
print(movie_date)
# 获取电影时长
movie_times = movie.xpath('./div/div/div[2]/div[2]/span[3]/text()').extract_first()
# 获取电影评分
movie_scores = movie.xpath('./div/div/div[3]/p[1]/text()').extract_first()
# 上映地点
movie_adds = movie.xpath('./div/div/div[2]/div[2]/span[1]/text()').extract_first()
# # 标签
movie_bqs = movie.css('div.categories ').extract()
res = re.compile("[\u4e00-\u9fa5]+")
movie_bq = res.findall(movie_bqs[0])
scrapy框架–items文件
-
items:定义框架中数据传输的形式
-
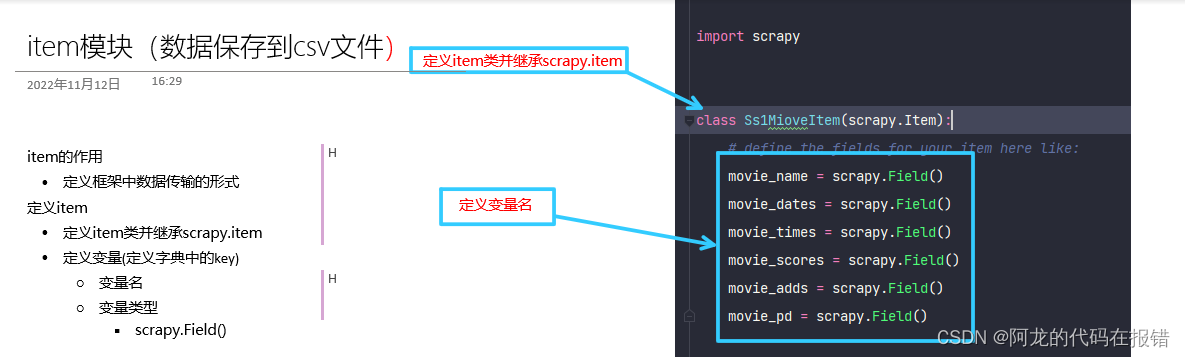
定义item:
定义item类并继承scrapy.item
定义变量(也就是给字典定义一key值)
import scrapy
class Ss1MioveItem(scrapy.Item):
# define the fields for your item here like:
movie_name = scrapy.Field()
movie_dates = scrapy.Field()
movie_times = scrapy.Field()
movie_scores = scrapy.Field()
movie_adds = scrapy.Field()
movie_pd = scrapy.Field()
代码解析:
-
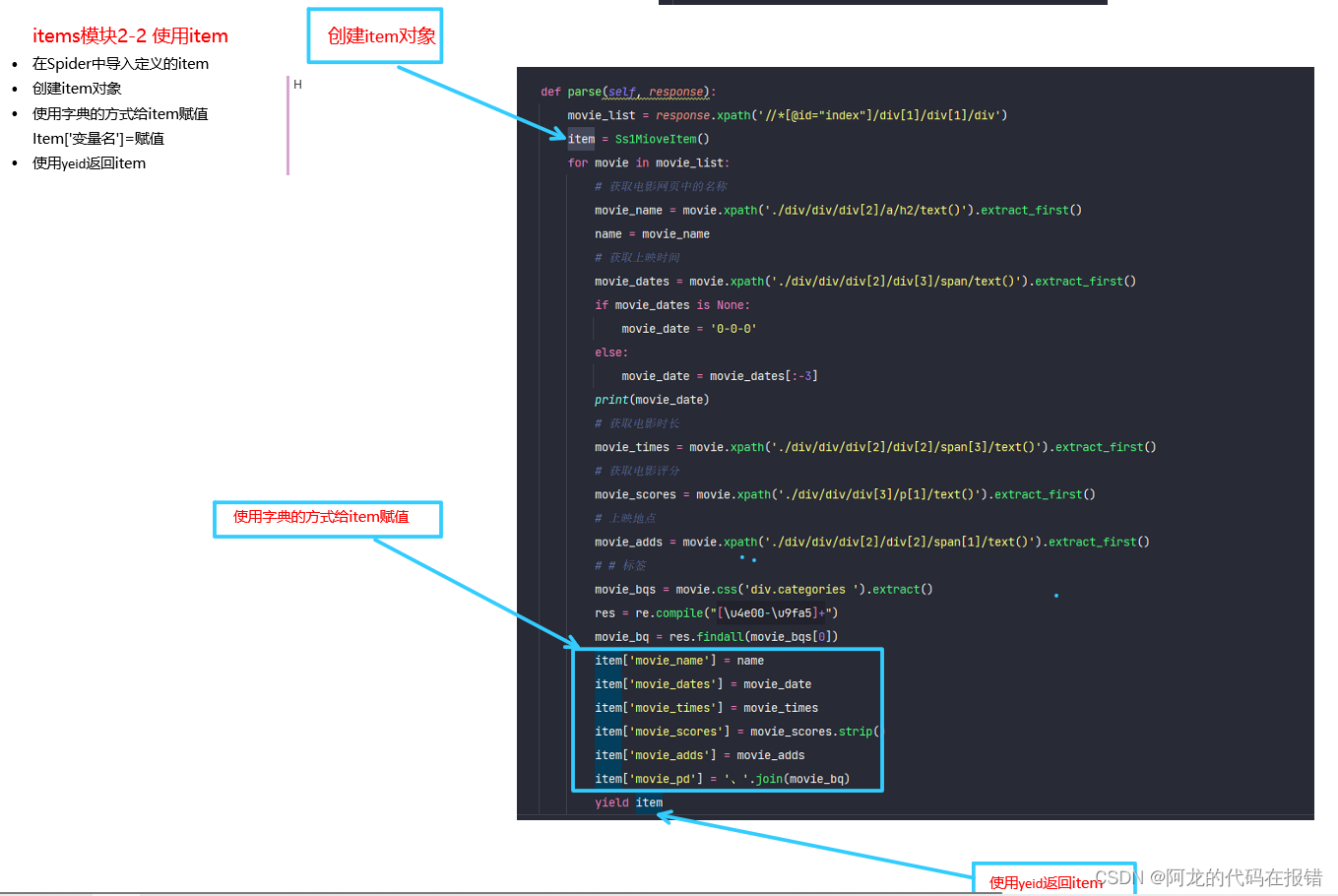
item的使用:
-
在spider中的导入定义好的item
-
创建item对象
-
使用字典的方式给item赋值
item[‘变量名’] = 赋值 (变量名可以自定义)
-
使用yield返回item
-
在spider中的导入定义好的item
from ssr1.ss1_miove.ss1_miove.items import Ss1MioveItem
创建item对象
item = Ss1MioveItem()
使用字典的方式给item赋值
item['movie_name'] = name
item['movie_dates'] = movie_date
item['movie_times'] = movie_times
item['movie_scores'] = movie_scores.strip()
item['movie_adds'] = movie_adds
item['movie_pd'] = '、'.join(movie_bq)
使用yield返回item
yield item
图片代码解析
首先我们先学习将数据存储到本地文件中(csv文件)
- 可以在终端使用命令调用Feed export进行保存
scrapy crawl ss1_scrapy -o 1.csv
-
修改setting.py文件配置Feed export进行保存
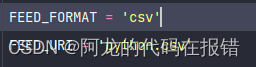
FEED_FORMAT = 'csv' FEED_URI = 'python.csv'配置输出文件的格式:
FEED_FORMAT = ‘csv’ #csv要求是小写不然无法生成文件不知道原因
输出文件的路径以及文件名:
FEED_URI = ‘python.csv’