一、《OVTrack: Open-Vocabulary Multiple Object Tracking》
作者:Siyuan Li* Tobias Fischer* Lei Ke Henghui Ding Martin Danelljan Fisher Yu
Computer Vision Lab, ETH Zurich
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Li_OVTrack_Open-Vocabulary_Multiple_Object_Tracking_CVPR_2023_paper.pdf
Github:https://github.com/SysCV/ovtrack
1、摘要
识别、定位和跟踪场景中的动态物体的能力是许多现实世界的应用程序的基础,如自动驾驶和机器人系统。然而,传统的多重对象跟踪(MOT)基准测试只依赖于少数对象类别,这些类别很难代表在现实世界中遇到的大量可能的对象。这使得当代的MOT方法仅限于一组预定义的对象类别。在本文中,我们通过解决一个新的任务,即开放词汇表MOT来解决这一限制,该任务旨在评估在预定义的训练类别之外的跟踪。我们进一步开发了OVTrack,这是一个能够跟踪任意对象类的开放词汇表跟踪器。它的设计基于两个关键成分:第一,利用视觉语言模型通过知识蒸馏进行分类和关联;第二,一种数据幻想策略,从去噪扩散概率模型中进行鲁棒外观特征学习。其结果是一个非常数据高效的开放词汇量跟踪器,它在静态图像上进行训练就在大规模的、大词汇量的TAO基准测试上达到SOTA。
2、方法
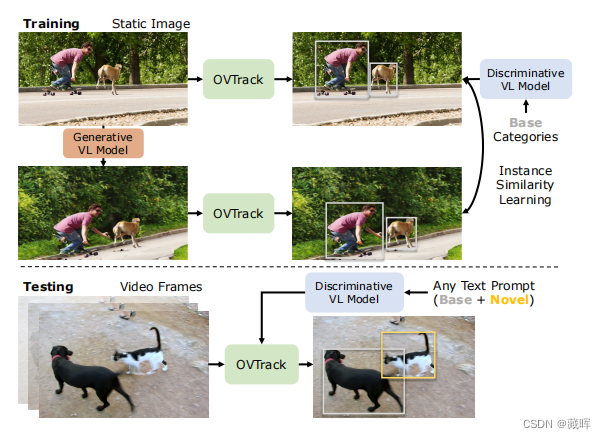
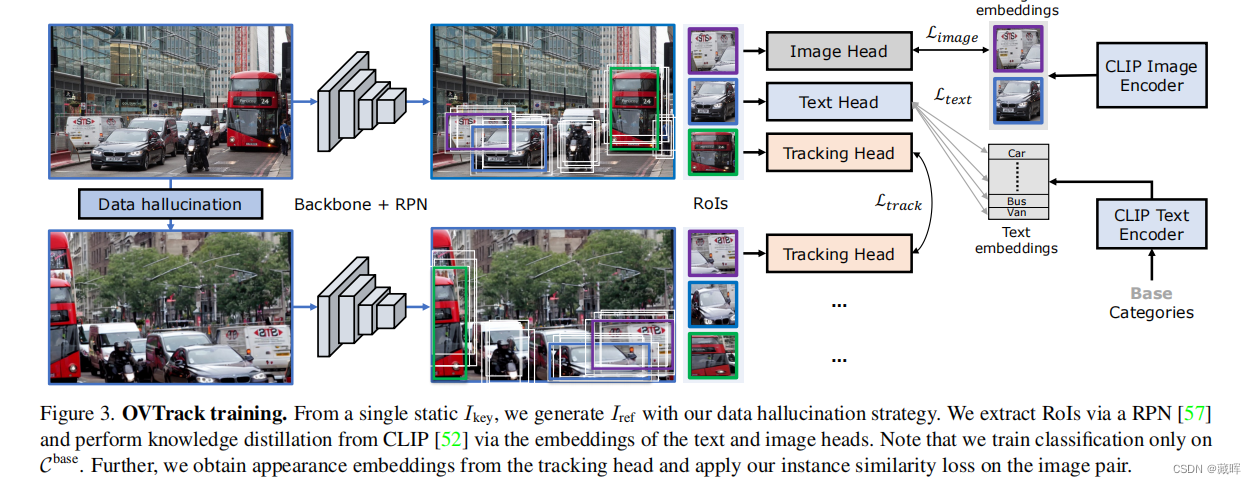
简单来说,本文通过大模型的能力来替代掉原来的Tracking不可知目标分类的能力。对于跟随未知物体,需要跟踪器可以做的事请有三件,一是定位物体的位置,文中用了Faster RCNN在类不可知的方式下进行训练(先前的方法,可见前两年的总结)。二是关联,作者用了一种数据增强方式,用一种图来促进外观embedding的学习,并用其做关联。三是分类,告诉用户现在在跟随的目标类别。这篇paper将传统的分类任务改变为Image Captioning的任务,通过蒸馏大模型CLIP来获得Image到Text的解读能力。

在Inference阶段,也用到了CLIP。OVTrack通过比较embedding的相似性获得相邻帧的匹配结果以及类别。
二、《MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking》
作者:Zheng Qin1† Sanping Zhou1† Le Wang1∗
Jinghai Duan2 Gang Hua3 Wei Tang4
1National Key Laboratory of Human-Machine Hybrid Augmented Intelligence,
National Engineering Research Center for Visual Information and Applications,
Institute of Artificial Intelligence and Robotics, Xi’an Jiaotong University
2School of Software Engineering, Xi’an Jiaotong University
3Wormpex AI Research 4University of Illinois at Chicago
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Qin_MotionTrack_Learning_Robust_Short-Term_and_Long-Term_Motions_for_Multi-Object_Tracking_CVPR_2023_paper.pdf
Github:https://github.com/qwomeng/MotionTrack
1、摘要
多目标跟踪(MOT)的主要挑战在于为每个目标保持一个连续的轨迹。现有的方法通常是学习可靠的运动模式,以匹配相邻帧之间的相同目标和有区别的外观特征,以在长时间后重新识别丢失的目标。然而,在跟踪过程中,密集的人群和极端的遮挡很容易受到运动预测的可靠性和外观的影响。在本文中,我们提出了一种简单而有效的多目标跟踪器,即运动跟踪器,它在一个统一的框架中学习鲁棒的短期和长期运动,从而将从短期到长期的轨迹关联起来。对于密集的人群,我们设计了一个新的交互模块,从短期轨迹中学习交互感知运动,它可以估计每个目标的复杂运动。对于极端遮挡,我们建立了一个新的重寻模块,从目标的历史轨迹中学习可靠的长期运动,它可以将中断的轨迹与相应的检测联系起来。我们的交互模块和重寻模块嵌入在众所周知的Tracking-by-detection范式中,它可以协同工作以保持优越的性能。
🔺这篇paper主要是基于ByteTrack的改进,用网络来强化其运动预测。
2、方法
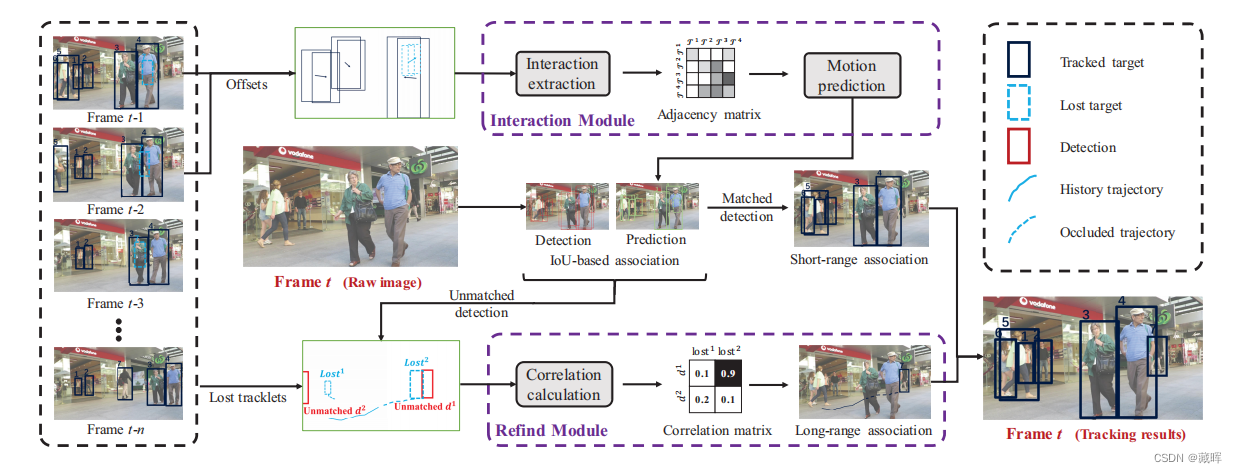
文中主要有两个模块,一个用于短时运动轨迹估计的Interaction Module,通过预测每一个目标的短时的运动轨迹,并和当前帧的detection结果做匹配。另一个是长时的Refind Moudule,通过一些方法补偿由于目标遮挡所不可见目标的运动轨迹,并找回他们。
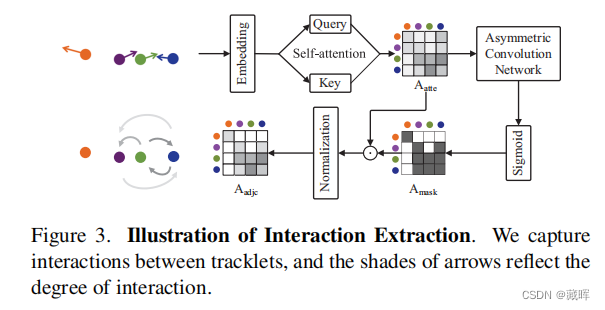
Interaction model将目标的绝对坐标和偏移量作为输入,表示为It∈R^(M×8)。将其embedding化后计算轨迹之间的相互影响,即相互作用矩阵Aadjc。这个矩阵的作用是将其他影响到的该目标轨迹的目标的偏移量,用来做加权,以提高偏移量预测的精度。跨帧的关联还是用了IOU。

Refind module将lost tracklet和当前帧未匹配的box进行编码,之后通过一个全连接层来计算其相关性,以获得找回结果。
三、《Standing Between Past and Future: Spatio-Temporal Modeling for Multi-Camera 3D Multi-Object Tracking》
作者:Ziqi Pang1*, Jie Li2, Pavel Tokmakov2, Dian Chen2, Sergey Zagoruyko3, Yu-Xiong Wang1†
University of Illinois Urbana-Champaign1, Toyota Research Institute2, Woven Planet Level-53
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Pang_Standing_Between_Past_and_Future_Spatio-Temporal_Modeling_for_Multi-Camera_3D_CVPR_2023_paper.pdf
Github:https://github.com/TRI-ML/PF-Track
1、摘要
本工作提出了一种端到端多摄像机三维多目标跟踪(MOT)框架。它强调时空连续性,并整合了过去和未来的推理。因此,我们将其命名为 “Past-and-Future reasoning for Tracking” (PF-Track)。具体来说,我们的方法采用了“注意跟踪”框架,与对象查询随时间一致地表示跟踪实例。为了明确地使用历史线索,我们的“过去推理”模块通过交叉关注来自以前的帧和其他对象的查询来学习细化轨迹和增强对象特征。“未来推理”模块消化历史信息,并预测稳健的未来轨迹。在长期遮挡的情况下,我们的方法保持物体的位置,并通过整合运动预测实现重新关联。在nuScenes数据集上,我们的方法大大提高了AMOTA的性能,并显著减少了90%的id开关,这是减少了一个数量级。
2、方法
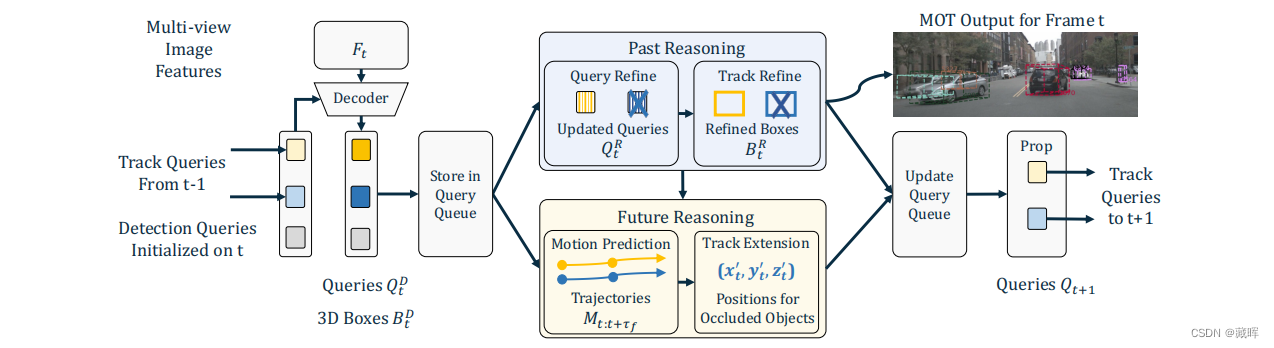
PF-Track将对象表示为查询,解码图像特征,并预测boxes。其中,“Past Reasoning”作用是利用历史信息来改进当前帧的预测。“Future Reasoning”通过估计长期的未来轨迹来改进查询跨帧的传播,即运动预测。

跨帧和跨目标的信息利用用的是Attetion机制。在“Past Reasoning”过程中是用该方式来修正当前帧的结果。在“Future Reasoning”过程中是用该方式来做轨迹预测(增加的解码工作由FC网络完成)。
🔺这篇文章的思路和第二篇比较相似,都是对目标运动做改进。
四、《Tracking through Containers and Occluders in the Wild》
作者:Basile Van Hoorick1 Pavel Tokmakov2 Simon Stent3
Jie Li2 Carl Vondrick1
1Columbia University 2Toyota Research Institute 3Woven Planet
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Van_Hoorick_Tracking_Through_Containers_and_Occluders_in_the_Wild_CVPR_2023_paper.pdf
1、摘要
在杂乱和动态的环境中跟踪具有持久性的对象仍然是计算机视觉系统面临的一个困难挑战。在本文中,我们介绍了TCOW,一个新的基准和模型,通过视觉跟踪严重遮挡的场景。我们设置了一个任务,其目标是,给定一个视频序列,分割目标对象的投影范围,以及周围的容器或遮挡器。为了研究这项任务,我们创建了一个合成和注释的真实数据集的混合物,以支持监督学习和在各种形式的任务变化下的模型性能的结构化评估,如移动或嵌套的覆盖物。我们评估了最近两个基于转换器的视频模型,发现虽然它们在某些任务变化设置下能够令人惊讶地能够跟踪目标,但在我们声称一个跟踪模型获得了对象持久性的真实概念之前,仍然存在相当大的性能差距。
🔺本工作提出的一个新的benchmark,和物体长时严重遮挡有关。

五、《Focus On Details: Online Multi-object Tracking with Diverse Fine-grained Representation》
作者:Hao Ren 1, Shoudong Han 1, ∗ , Huilin Ding, Ziwen Zhang, Hongwei Wang, Faquan Wang
National Key Laboratory of Science and Technology on Multispectral Information Processing,
School of Artificial Intelligence and Automation, Huazhong University of Science and Technology
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Ren_Focus_on_Details_Online_Multi-Object_Tracking_With_Diverse_Fine-Grained_Representation_CVPR_2023_paper.pdf
1、摘要
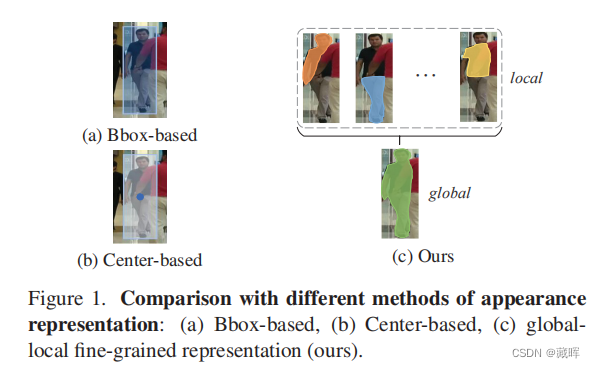
在多目标跟踪(MOT)中,区分性表示对于为每个目标保持一个唯一的标识符是必不可少的。一些最近的MOT方法提取边界盒区域或中心点的特征作为ID embedding。然而,当目标被遮挡时,这些粗粒度的全局表示就会变得不可靠。为此,我们建议探索不同的细粒度表示,它从全局和局部的角度全面地描述外观。这种细粒度的表示需要较高的特征分辨率和精确的语义信息。为了有效地缓解任意上下文信息聚合导致的语义错位,提出了多尺度特征对齐聚合方法(FAFPN)。它在来自不同分辨率的特征映射之间生成语义流,以转换它们的像素位置。此外,我们提出了一个多头零件掩模生成器(MPMG)来提取基于对齐的特征映射的细粒度表示。MPMG的多个并行分支允许它专注于目标的不同部分,在没有标签监督的情况下生成本地mask。目标掩码中的不同细节有助于细粒度的表示。最终,受益于具有正样本和负样本平衡的洗牌组抽样(SGS)训练策略,我们在MOT17和MOT20测试集上取得了最先进的性能。即使在目标的外观非常相似的舞Dancetrack上,我们的方法在HOTA上显著超过5.0%,在IDF1上显著超过5.6%。
🔺是一篇提高外观特征表示的改进工作,通过local mask的方式学习和聚合了局部特征,提高了特征的一致性和区分度。
2、方法
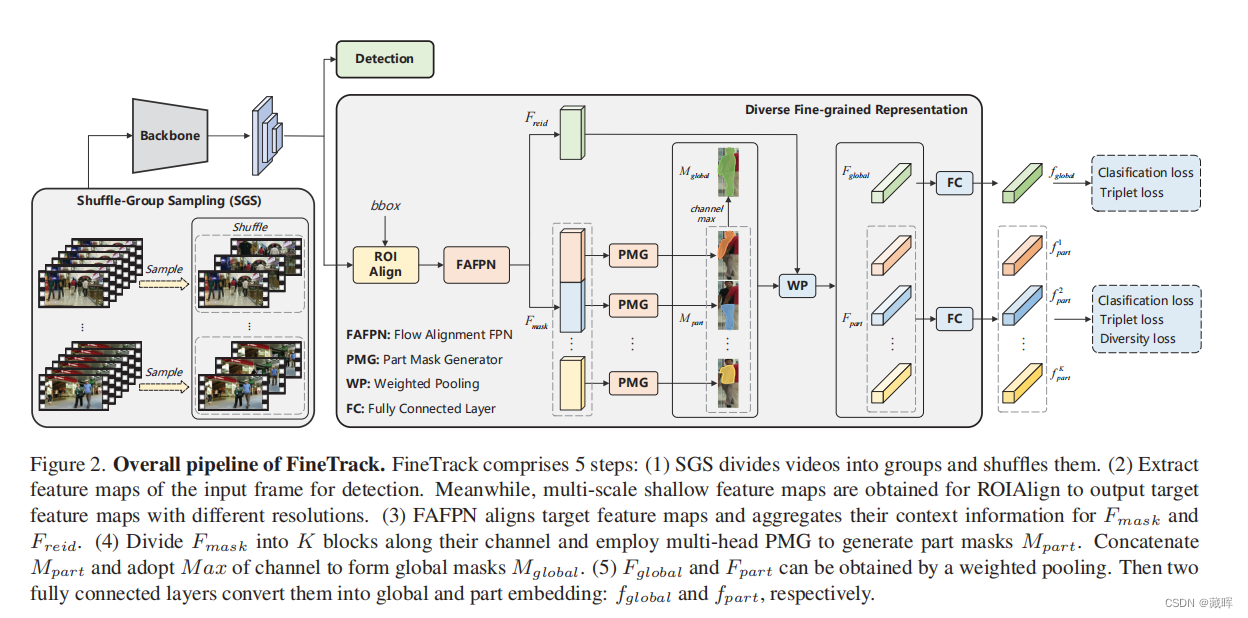
这个结构是改进了JDE,把embedding的提取方式做的更精细了。
六、《UTM: A Unified Multiple Object Tracking Model with Identity-Aware Feature Enhancement》
作者:Sisi You1 Hantao Yao2 Bing-kun Bao1 Changsheng Xu2,3*
1Nanjing University of Posts and Telecommunications
te Key Laboratory of Multimodal Artificial Intelligence Systems, Institute of Automation, Chinese Academy of Sciences (CASIA)
3University of Chinese Academy of Sciences
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/You_UTM_A_Unified_Multiple_Object_Tracking_Model_With_Identity-Aware_Feature_CVPR_2023_paper.pdf
1、摘要
近年来,多目标跟踪在目标检测、特征嵌入和身份关联等方面取得了巨大的成功。现有的方法应用三步或两步范式来生成鲁棒的轨迹,其中身份关联独立于其他组件。然而,独立的身份关联导致了在轨迹中包含的身份识别知识,并不能用于提高检测和嵌入模块。为了克服现有方法的局限性,我们引入了一种新的统一跟踪模型(UTM)来连接这三个组件,从而产生一个具有互惠互利的正反馈回路。UTM的关键见解是身份感知特征增强(IAFE),它被应用于利用身份识别知识来促进检测和嵌入,从而连接并受益于这三个组件。形式上,IAFE包含了识别意识增强注意(IABA)和身份意识消除注意(IAEA),其中IABA增强了当前框架特征和识别感知知识之间的一致区域,IAEA抑制了当前框架特征中的分心区域。通过更好的检测和嵌入,还可以生成更高质量的轨迹图。在三个基准上对公共和私人检测的大量实验证明了UTM的鲁棒性。
🔺unity 网络结构的工作,有点JDE+MPNTrack的组合。
2、方法

UTM的网络结构如上图所示。历史轨迹的embedding信息会用于当前特征的增强(Attetion),之后通过ROI-Align的方式获得box和embedding。通过图网络的构建(dist为embedding距离+iou距离),获得相邻帧的匹配关系。匹配完成之后,本文还用了一个FC网络来自特征更新。
七、《Unifying Short and Long-Term Tracking with Graph Hierarchies》
作者:Orcun Cetintas1* Guillem Braso´ Laura Leal-Taixe´
1Technical University of Munich 2Munich Center for Machine Learning
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Cetintas_Unifying_Short_and_Long-Term_Tracking_With_Graph_Hierarchies_CVPR_2023_paper.pdf
1、摘要
在长视频中跟踪物体有效地意味着解决一系列问题,不仅仅是从未被遮挡的物体的短期关联,还包括被遮挡的物体重新出现在场景中的物体的长期关联。处理这两个任务的方法通常是不相交的,并且是针对特定的场景精心设计的,而性能最好的方法通常是技术的混合,从而产生缺乏通用性的以工程为主的解决方案。在这项工作中,我们质疑了混合方法的必要性,并引入了SUSHI,一个统一的和可扩展的多对象跟踪器。我们的方法通过将长剪辑分割成一个子剪辑的层次结构来处理它们,从而实现了较高的可伸缩性。我们利用图神经网络来处理层次结构的所有层次,这使得我们的模型具有跨时间尺度的统一和高度的通用性。因此,我们在四个不同的数据集上获得了比最先进的显著改进。
🔺该工作是在MPNTrack上做扩展,将GNN短时跨帧的匹配也扩展到长时匹配中。
2、方法
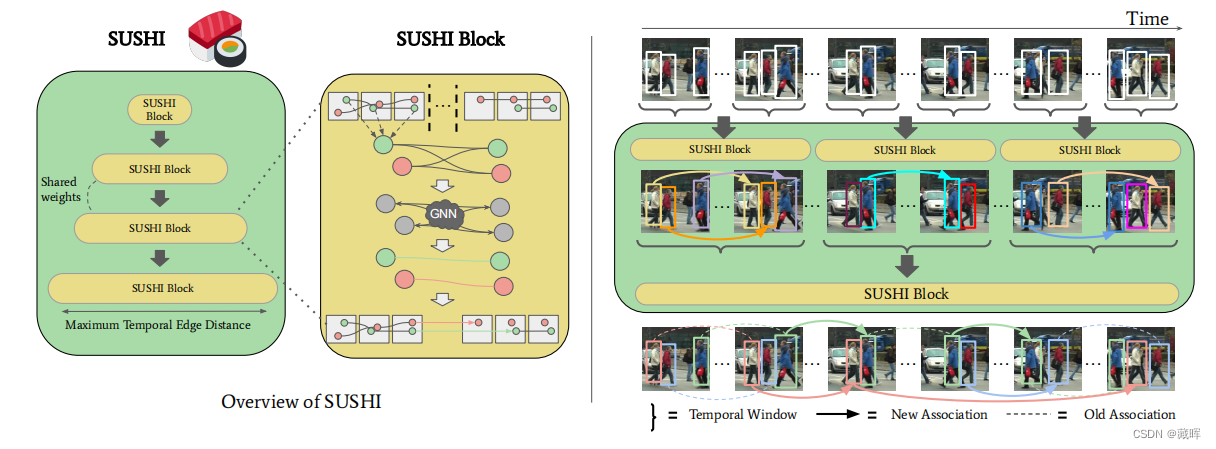
它由一系列联合训练的SUSHI Block组成,并通过一个视频剪辑进行操作。从最初的每帧对象检测开始(从现在开始称为长度为1的轨迹),每个SUSHI Block学习将前一层的轨迹合并为更长的轨迹。为了做到这一点,每个SUSHI Block构建了一个图,其中节点表示来自前一层的轨迹和边缘模型轨迹假设。节点和边具有相关的embedding编码位置、外观和运动线索,这些线索通过GNN在图中传播。经过几个消息传递步骤后,边缘embedding被分为正确的假设和不正确的假设,从而产生一组新的更长的轨迹集。通过分层堆叠几个SUSHI Block,轨迹逐渐增长到我们的最终输出:最终的轨道跨越整个输入视频剪辑。
由于考虑了直接构建一个跨越所有帧的图计算量过于庞大,本文采用了从小轨迹合成中轨迹,中轨迹合成长轨迹的方式,逐次合成来做。这说明了文中用到了global的信息,但是也意味着较难做online inference。
八、《Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking》
作者:Jinkun Cao1 Jiangmiao Pang2 Xinshuo Weng3 Rawal Khirodkar1 Kris Kitani1
1 Carnegie Mellon University 2 Shanghai AI Laboratory 3Nvidia
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Cao_Observation-Centric_SORT_Rethinking_SORT_for_Robust_Multi-Object_Tracking_CVPR_2023_paper.pdf
Github:https://github.com/noahcao/OC_SORT
1、摘要
基于卡尔曼滤波(KF)的多目标跟踪(MOT)方法假设目标呈线性移动。虽然这种假设对于非常短的闭塞时间是可以接受的,但对长时间运动的线性估计可能是非常不准确的。此外,当没有测量值可以更新卡尔曼滤波参数时,标准的约定是信任先验状态估计来进行后验更新。这导致了在一段闭塞期间错误的积累。在实际应用中,该误差导致了显著的运动方向差异。在这项工作中,我们证明了一个基本的卡尔曼滤波器仍然可以获得最先进的跟踪性能,如果采取适当的注意来修复在遮挡期间积累的噪声。我们不仅仅依赖于线性状态估计(即以估计为中心的方法),而是使用目标观测(即目标检测器的测量)来计算遮挡周期内的虚拟轨迹,以固定滤波器参数的误差积累。这允许更多的时间步长来纠正在遮挡期间积累的错误。我们将我们的方法命名为以观察为中心的SORT(OC-SORT)。它仍然是简单的、在线的和实时的,但提高了在遮挡和非线性运动时的鲁棒性。给定现成的检测作为输入,OC-SORT在单个CPU上以700+ FPS运行。它在多个数据集上实现了最先进的技术,包括MOT17、MOT20、KITTI、头部跟踪,特别是物体运动高度非线性的dancetrack。
2、方法
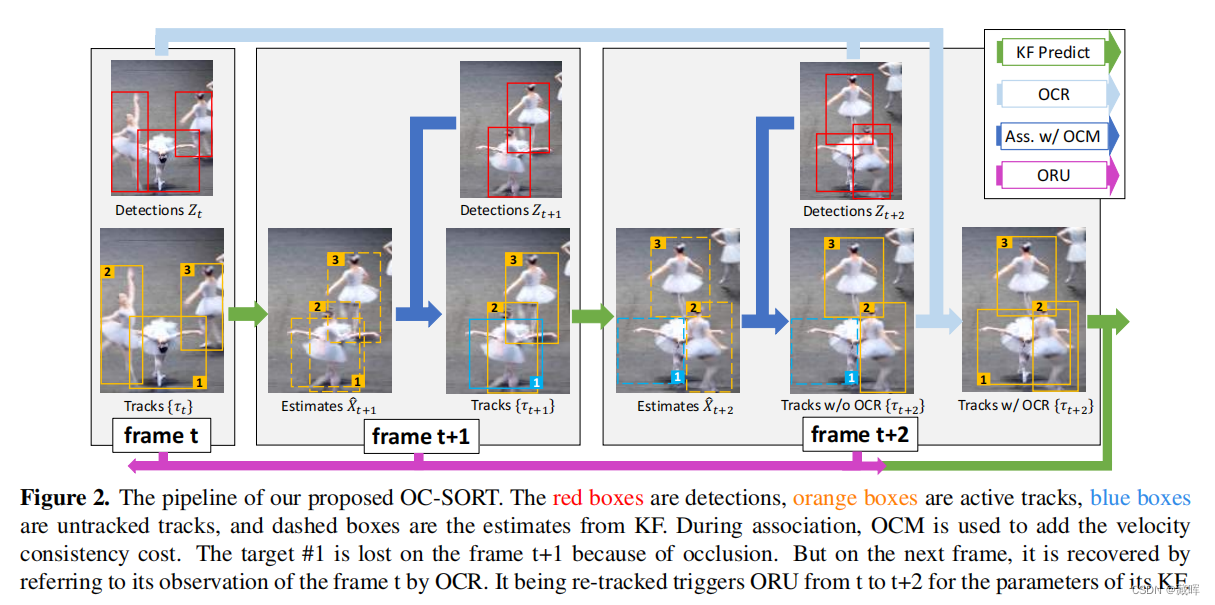
文中所提到的Sort的三项缺陷:
1)使用高帧率视频不利于抑制运动噪声: 在高帧率视频的连续帧之间,物体的位移噪声可以与实际的物体位移的幅度相同,导致KF估计的物体速度存在较大的方差;
2)观测不足造成的轨迹偏移: 由于遮挡或非线性运动,当没有新的物体观测(检测结果)与现有的轨迹相匹配时,物体状态噪声可以进一步累积。
3)依赖KF的状态估计: SORT是以估计为中心的,这意味着它严重依赖于KF状态估计,并且只使用观测值作为辅助信息。然而,作者认为当前检测器比以往的可靠,可以更多关注当前的检测。
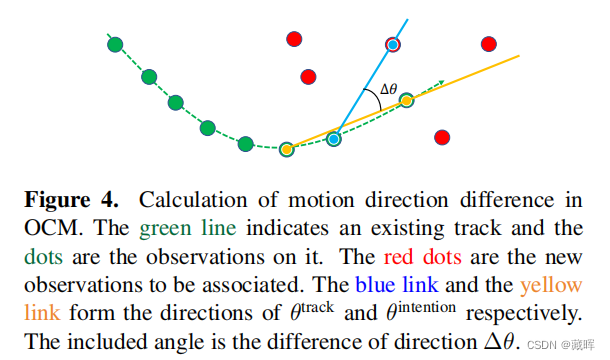
文中所提到两项改进:
1) Observation-centric Re-Update (ORU): 即增加虚拟观测来调整KF的参数,减少累积的误差。一旦轨迹在一段时间不跟踪(“重新激活”)后再次与观察相关联,ORU就反向检查它丢失的周期,并重新更新KF的参数。这次重新更新是基于对虚拟轨迹的“观测”。虚拟轨迹是根据对开始和结束未跟踪周期的步骤的观察结果生成的。
2) Observation-Centric Momentum (OCM): 在匹配矩阵中增加轨迹的方向一致性的影响,以更好地实现轨迹和观测值之间的匹配。
九、《Simple Cues Lead to a Strong Multi-Object Tracker》
作者:Jenny Seidenschwarz1* Guillem Brasó 12 Victor Castro Serrano1
Ismail Elezi1 Laura Leal-Taixé1†
1Technical University of Munich 2Munich Center for Machine Learning
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Seidenschwarz_Simple_Cues_Lead_to_a_Strong_Multi-Object_Tracker_CVPR_2023_paper.pdf
Github:https://github.com/dvl-tum/GHOST
1、摘要
在很长一段时间里,多对象跟踪中最常见的范式是逐检测跟踪(TbD),即对象首先被检测到,然后通过视频帧进行关联。对于关联,大多数模型都将资源分配到运动和外观线索上,例如,重新识别网络。最近基于注意力的方法提出了以数据驱动的方式学习线索,显示出了令人印象深刻的结果。在本文中,我们问自己,简单的好的旧的TbD方法是否也能够实现端到端模型的性能。为此,我们提出了两个关键成分,允许一个标准的重新识别网络在基于外观的跟踪方面表现卓越。我们广泛地分析了它的失败情况,并表明,将我们的外观特征与一个简单的运动模型相结合,可以得到强大的跟踪结果。我们的跟踪器推广到四个公共数据集,即MOT17、MOT20、BDD100k和dancetrack,实现了SOTA的性能。
2、方法
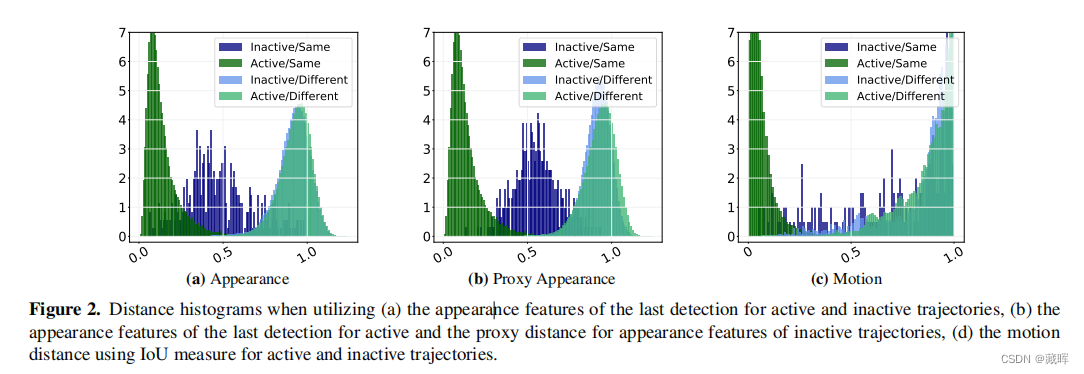
文中要解的问题是在目标丢失之后,appearance特征的区分性并不强,影响跟踪性能。
因此,本文提出了两种设计选择,以使外观模型更强: (i)以不同的方式处理active和inactive的轨迹,简单来说就是对active轨迹计算了前后两帧之间的距离,对于inactive轨迹计算了当前帧与轨迹消失前所有帧的距离,并求了平均;(ii)我们添加了动态的域自适应,即一种归一化方式让ReID特征可以更自适应不同的场景,如遮挡等(与ECCV2022一篇paper思路相似)。
十、《Tracking Multiple Deformable Objects in Egocentric Videos》
作者:Mingzhen Huang1,2†, Xiaoxing Li2, Jun Hu2, Honghong Peng2, Siwei Lyu1
1State University of New York at Buffalo, 2Meta Reality Labs
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Huang_Tracking_Multiple_Deformable_Objects_in_Egocentric_Videos_CVPR_2023_paper.pdf
1、摘要
大多数现有的多物体跟踪(MOT)方法在跟踪高度可变形的物体方面存在困难。其他使用运动线索跨帧关联身份的MOT方法很难有效地处理以自我为中心的视频。在这项工作中,我们提出了DogThruGlasses,一个大规模的可变形多目标跟踪数据集,有150个视频和73K注释帧,由智能眼镜独家收集。我们还提出了DETracker,一种新的MOT方法,可以联合检测和跟踪自我中心视频中的可变形对象。DETracker使用三个新的模块,即运动解纠缠网络(MDN),补丁关联网络(PAN)和补丁记忆网络(PMN),来明确地解决严重的自我运动和跟踪快速变化的目标对象。DETracker是可端到端可训练的,并实现接近实时的速度,这优于现有的在 DogThruGlasses和YouTube-Hand上的最先进的方法。
2、方法
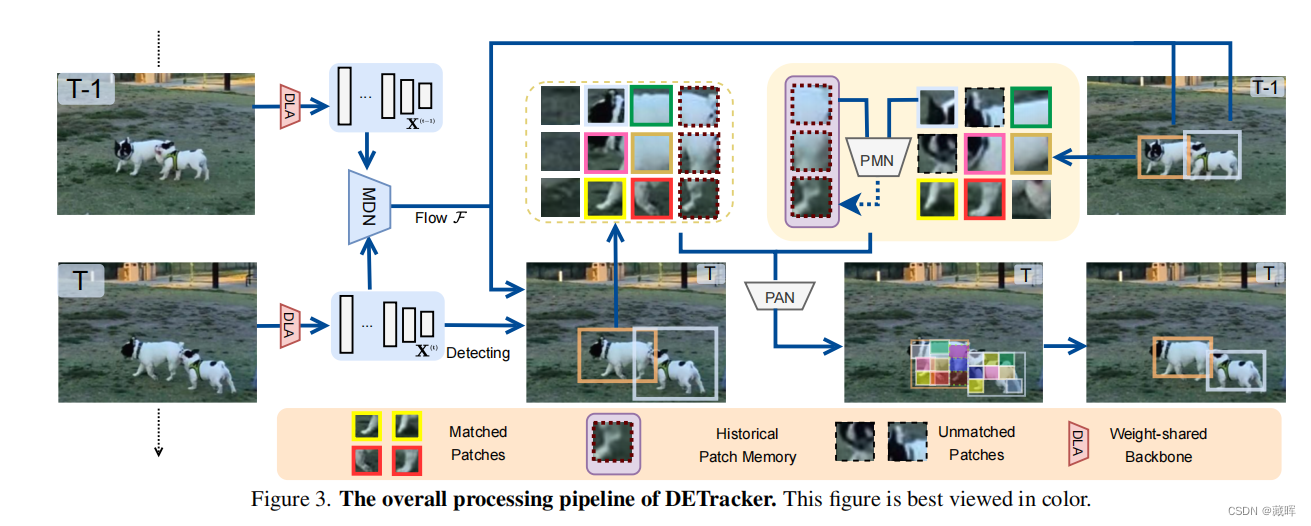
DETraccer的整体体系结构如图所示。首先相邻帧图片从一个DLA-34处理获得多个金字塔特征。之后通过MDN模块来预测跨帧的光流信息(类似RAFT)。通过光流的传播,上一帧的框可以被传递到当前帧,同时当前帧的结果也可以通过detection的方式获得,两个结果融合可以获得当前帧粗粒度的识别结果。之后是补丁网络PAN,通过匹配两个帧之间的细分补丁来检测和关联对象。最后,补丁存储网络PMN在固定长度的环补丁存储缓冲区Pmem中保留PAN输出中不匹配的补丁,以帮助跟踪可变形和被遮挡的对象。
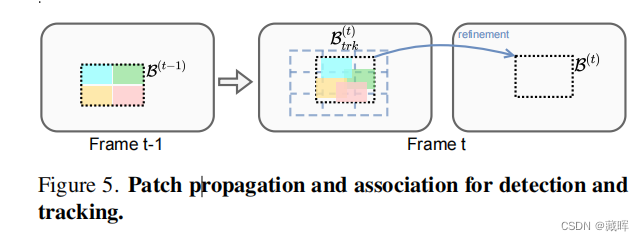
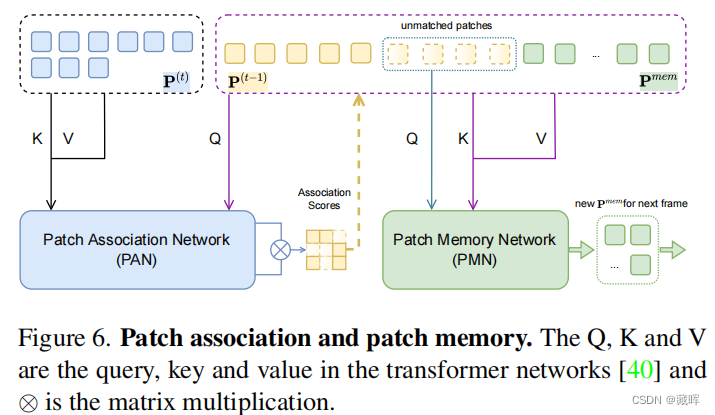
PAN和PMN网络实际上是一个transformer网络。PAN通过对每一个patch进行编码,找到当前帧与上一帧相关联的patch,实现了细化框的回归和关联。PMN用于生成历史轨迹用于匹配的patch embedding,并做状态更新,提高长时跟随稳定性。
十一、《Referring Multi-Object Tracking》
作者:Dongming Wu1∗‡, Wencheng Han2∗, Tiancai Wang3, Xingping Dong4, Xiangyu Zhang3,5, Jianbing Shen2†
1 Beijing Institute of Technology, 2 SKL-IOTSC, CIS, University of Macau, 3 MEGVII Technology,
4 School of Computer Science, Wuhan University, 5 Beijing Academy of Artificial Intelligence
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Wu_Referring_Multi-Object_Tracking_CVPR_2023_paper.pdf
1、摘要
现有的引用理解任务往往涉及到检测单个文本引用对象。在本文中,我们提出了一个新的和通用的参考理解任务,称为参考多目标跟踪(RMOT)。其核心思想是利用语言表达式作为语义线索来指导多目标跟踪的预测。据我们所知,这是第一个在视频中实现任意数量的参考对象预测的工作。为了推进RMOT,我们构建了一个基于KITTI的可伸缩表达式的基准,名为Refer-KITTI。具体来说,它提供了18个视频和818个表达式,并且在一个视频中的每个表达式平均注释了10.7个对象。此外,我们开发了一个基于转换器的架构TransRMOT,以在线方式处理新任务,它实现了令人印象深刻的检测性能,并优于其他同类任务。

2、方法
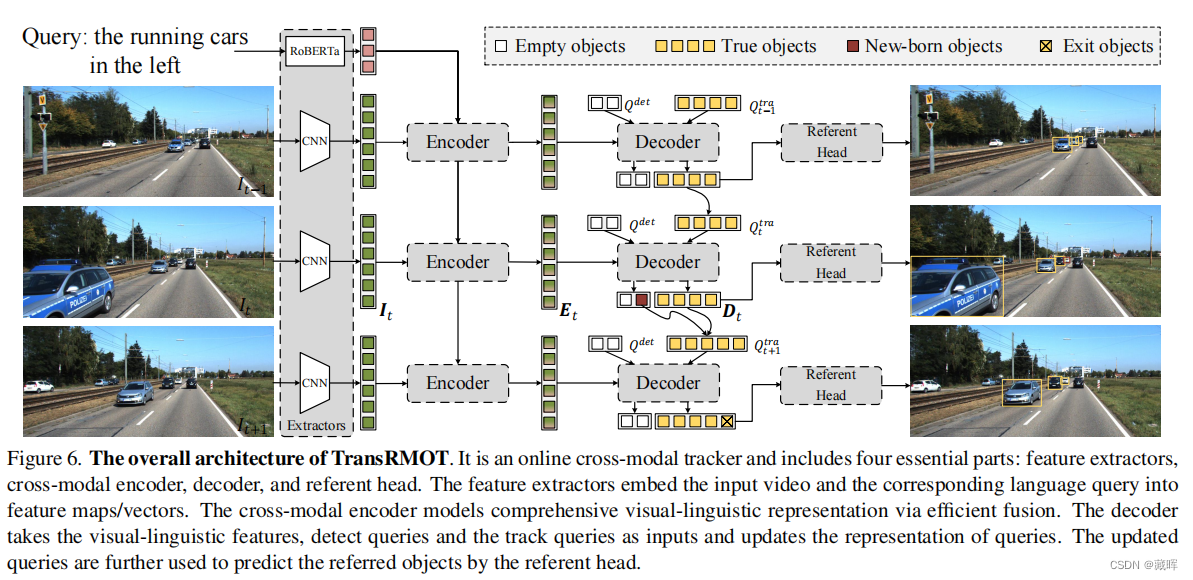
它是一个在线的跨模态跟踪器,包括四个基本部分:特征提取器、跨模态编码器、解码器和参考头网络。特征提取器将输入的视频和相应的语言查询嵌入到特征映射/向量中。跨模态编码器通过有效的融合建立了全面的视觉-语言表示模型。解码器将视觉语言特征、检测查询和跟踪查询作为输入,并更新查询的表示。更新后的查询进一步用于预测引用头的引用对象。
十二、《MOTRv2: Bootstrapping End-to-End Multi-Object Tracking by Pretrained
Object Detectors》
作者:Yuang Zhang1*, Tiancai Wang2, Xiangyu Zhang2,3
1Shanghai Jiao Tong University 2MEGVII Technology 3Beijing Academy of Artificial Intelligence
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Zhang_MOTRv2_Bootstrapping_End-to-End_Multi-Object_Tracking_by_Pretrained_Object_Detectors_CVPR_2023_paper.pdf
1、摘要
在本文中,我们提出了MOTRv2,一个简单而有效的方法,与预先训练的目标检测器引导端到端多目标跟踪。现有的端到端方法,如MOTR [43]和Track前[20]不如其检测跟踪方法,主要是因为它们的检测性能较差。我们的目标是通过优雅地合并一个额外的目标探测器来改进MOTR。我们首先采用查询的锚定公式,然后使用一个额外的对象检测器来生成建议作为锚定,在MOTR之前提供检测。这个简单的修改极大地缓解了MOTR中联合学习检测和关联任务之间的冲突。MOTRv2保持了查询扩展特性,并在大规模基准测试上很好地扩展。MOTRv2在第一届dancetrack challenge中排名第一(73.4%的HOTA)。
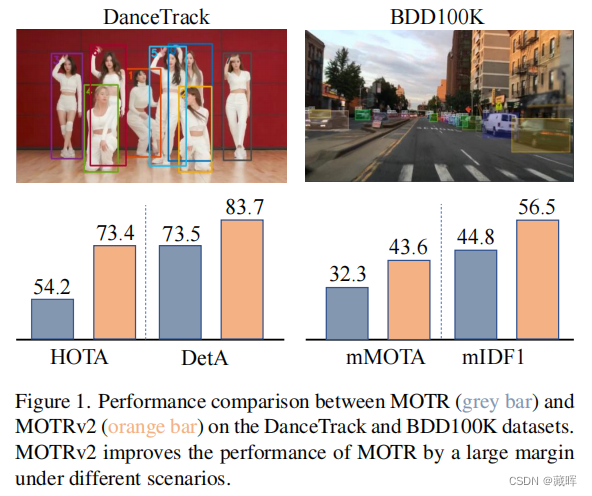
🔺Transformer方法在时序匹配上具有天然的优势,但是在识别上较弱,还是由SOTA的detection网络来完成。
2、方法
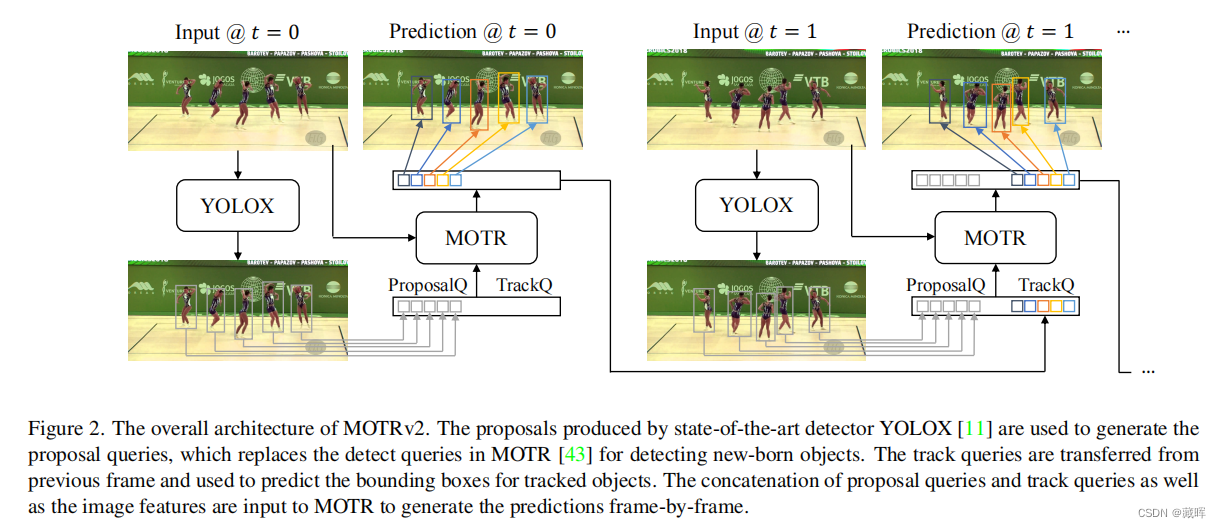
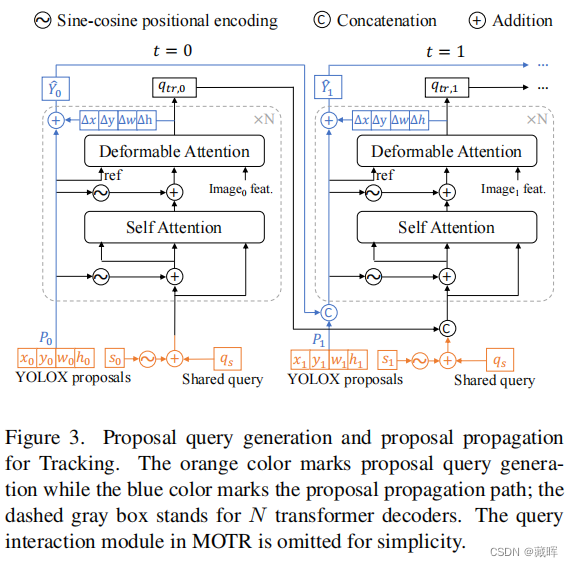
MOTRv2的整体架构。由最先进的检测器YOLOX [11]生成的提案被用于生成提案查询,它取代了MOTR [43]中用于检测新生对象的检测查询。跟踪查询从上一帧传输出来,用于预测被跟踪对象的边界框。将建议查询和跟踪查询以及图像特征的连接输入到MOTR,以逐帧生成预测。
![[Selenium] 通过Java+Selenium查询某个博主的Top40文章质量分](https://img-blog.csdnimg.cn/0ebb1caa66704cbf964cafc95bf2ef6d.png)