系列文章目录
第一章 AlexNet网络详解
第二章 VGG网络详解
第三章 GoogLeNet网络详解
第四章 ResNet网络详解
第五章 ResNeXt网络详解
第六章 MobileNetv1网络详解
第七章 MobileNetv2网络详解
第八章 MobileNetv3网络详解
第九章 ShuffleNetv1网络详解
第十章 ShuffleNetv2网络详解
第十一章 EfficientNetv1网络详解
第十二章 EfficientNetv2网络详解
第十三章 Transformer注意力机制
第十四章 Vision Transformer网络详解
第十五章 Swin-Transformer网络详解
第十六章 ConvNeXt网络详解
第十七章 RepVGG网络详解
第十八章 MobileViT网络详解
文章目录
- EfficientNetv1网络详解
- 0. 摘要
- 1. 前言
- 2. EfficientNetv1网络详解网络架构
- 1. EfficientNetv1_Model.py(pytorch实现)
- 2.
- 总结
0、摘要
1.本文介绍了EfficientNetV2,这是一种比以前的模型具有更快的训练速度和更好参数效率的卷积网络。
2.本研究的背景是为了开发一种具有更好训练速度和参数效率的卷积网络。
3.本文的主要论点是EfficientNetV2可以比以前的模型更快地训练,同时更小巧。
4.过去的研究方法主要是使用神经架构搜索和缩放来寻找更优秀的模型,但是这些方法效率低下且耗时较长。
5.本文提出了一种结合神经架构搜索和缩放的训练方法来开发EfficientNetV2.
6.研究表明,EfficientNetV2比以前的模型更快地训练,同时更小巧,而且效果显著。然而,本研究的局限在于收集的数据集方面较少,需要有更多数据来验证其有效性。
本文介绍了一种新的卷积网络EfficientNetV2,它具有比之前的模型更快的训练速度和更好的参数效率。为了开发这些模型,我们使用了一种训练感知的神经架构搜索和缩放的组合,以共同优化训练速度和参数效率。这些模型是从具有新操作(如Fused-MBConv)的搜索空间中搜索出来的。我们的实验表明,EfficientNetV2模型的训练速度比最先进的模型快得多,同时体积最大可减小6.8倍。我们可以通过逐步增加训练中的图像尺寸来进一步加速训练,但这往往会导致准确度降低。为了补偿这种准确度降低,我们提出了一种改进的逐步学习方法,它根据图像尺寸自适应地调整正则化(例如数据增强)。通过逐步学习,我们的EfficientNetV2在ImageNet和CIFAR/Cars/Flowers数据集上明显优于以前的模型。通过在相同的ImageNet21k上进行预训练,我们的EfficientNetV2在ImageNet ILSVRC2012上实现了87.3%的top-1准确率,比最近的ViT高出2.0%的准确率,同时使用相同的计算资源训练速度提高了5倍至11倍。代码可在<a href="https://github.com/google/automl/tree/master/efficientnetv2%E4%B8%8A%E6%89%BE%E5%88%B0%E3%80%82">https://github.com/google/automl/tree/master/efficientnetv2上找到。</a></p>
- 引入Fused-MBConv模块
- 引入渐进式学习策略(训练更快)
EfficientNetV1中存在的问题
- 训练图像的尺寸很大时,训练速度非常慢->降低训练图像尺寸(增加训练速度的同时可以使用更大的batch_size)
- 在网络浅层中使用Depthwise convolutions速度会很慢(引入Fused-MBConv模块[stage1-stage3])
- 同等的放大每个stage是次优的(使用非均匀的缩放策略)
亮点
- 引入新的网络(EfficientNetV2),该网络在训练速度以及参数数量上都优于以前的一些网络。
- 提出了改进的渐进学习方法,该方法会根据训练图像的尺寸动态调整正则方法(提升训练速度,准确率)
- 通过实验与先前的网络相比,训练速度提升11倍,参数数量减少为1/6.8
EfficientV2与EfficientV1的不同点:
- 除了使用MBConv模块,还是使用Fused-MBConv模块
- 会使用较小的expansion ratio
- 偏向使用更小的kernel_size(3x3)
- 移除了EfficientNetV1中最后一个步距为1的stage(V1中的Stage8)
渐进式学习策略
- 训练早期使用较小的训练尺寸以及较弱的正则化方法weak regularization,这样网络能够快速的学习到一些简单的表达能力。接着逐渐提升图像尺寸,同时增强正则化方法adding stronger regulation。这里所说的regulation包括Droupout, RandAugment以及Mixup

1、前言
训练效率对于深度学习来说非常重要,因为模型规模和训练数据规模越来越大。例如,GPT-3(Brown等人,2020)拥有更大的模型和更多的训练数据,在少量标注样本学习方面展现出了显著的能力,但需要数千个GPU数周的训练,这使得重新训练或改进变得困难。最近,训练效率引起了重要的关注。例如,NFNets(Brock等人,2021)通过删除昂贵的批量归一化来提高训练效率;最近的一些研究(Srinivas等人,2021)专注于通过在卷积网络(ConvNet)中添加注意力层来提高训练速度; Vision Transformers(Dosovitskiy等人,2021)通过使用变换器块在大规模数据集上提高训练效率。然而,这些方法通常会在大参数大小上带来昂贵的开销,如图1(b)所示。在本文中,我们使用训练感知的神经结构搜索(NAS)和缩放的组合来提高训练速度和参数效率。鉴于EfficientNets(Tan&Le,2019a)的参数效率,我们从系统地研究EfficientNets中的训练瓶颈开始。我们的研究结果显示,在EfficientNets中:(1)使用非常大的图像尺寸进行训练很慢;(2)深度卷积在前面的层中很慢;(3)均等地扩展每个阶段是次优的。基于这些观察结果,我们设计了一个增加了额外操作(如Fused-MBConv)的搜索空间,并应用训练感知的NAS和缩放来共同优化模型的准确性、训练速度和参数大小。我们发现的网络被命名为EfficientNetV2,可以比之前的模型快4倍(图3),同时参数大小可以缩小6.8倍。
我们的训练可以通过在训练过程中逐渐增加图像大小来进一步加快。许多以前的工作,如渐进式调整大小(Howard,2018)、FixRes(Touvron et al.,2019)和Mix&Match(Hoffer et al.,2019),在训练中使用较小的图像大小;然而,它们通常保持所有图像大小的相同正则化,从而导致准确性下降。我们认为,对不同的图像尺寸使用相同的正则化并不理想:对于相同的网络,较小的图像尺寸会导致较小的网络能力,因此需要较弱的正则化;反之,较大的图像尺寸需要更强的正则化以抵消过度拟合(参见第4.1节)。基于这个见解,我们提出了一个改进的渐进式学习方法:在早期的训练周期中,我们使用较小的图像大小和较弱的正则化(如dropout和数据增强)来训练网络,然后逐渐增加图像大小并添加更强的正则化。基于渐进式调整大小(Howard,2018),但通过动态调整正则化,我们的方法可以加速训练,而不会导致准确性下降。通过改进的渐进式学习,我们的EfficientNetV2在ImageNet、CIFAR-10、CIFAR-100、Cars和Flowers数据集上取得了强大的结果。在ImageNet上,我们实现了85.7%的top-1准确率,同时训练速度比以前的模型快3倍至9倍,并且比先前模型小6.8倍(图1)。我们的EfficientNetV2和渐进式学习也使得更容易在更大的数据集上训练模型。例如,ImageNet21k(Russakovsky et al.,2015)比ImageNet ILSVRC2012大约大10倍,但我们的EfficientNetV2可以在使用32个TPUv3核心的中等计算资源下两天内完成训练。通过对公共的ImageNet21k进行预训练,我们的EfficientNetV2在ImageNet ILSVRC2012上实现了87.3%的top-1准确率,在训练速度比ViT-L/16快5倍至11倍的同时,超过了近期的ViT-L/16的2.0%准确性(图1)。
(TPUv3(Third Generation Tensor Processing Unit)是由谷歌开发的一种专门用于加速深度神经网络训练和推理的ASIC(应用特定集成电路)芯片。TPUv3比第二代的性能提高了8倍,是当前世界上最快的人工智能计算芯片之一。
TPUv3的核心设计包括高速缓存、多个算术逻辑单元、计算单元等。它还使用了低精度浮点数计算来减少开销,支持大规模并行计算。与一般的CPU和GPU相比,TPUv3的特点是高效性能、低能耗和快速部署,适用于需要大规模训练和推理的深度学习任务,如自然语言处理、图像分类、语音识别等。
TPUv3的使用需要谷歌提供的云服务支持,用户可以在Google Cloud Platform上租用TPUv3进行深度学习任务。)
我们的贡献有三个方面:
• 我们引入了EfficientNetV2,这是一个新的更小更快的模型系列。通过我们的训练感知NAS和缩放发现,EfficientNetV2在训练速度和参数效率方面都优于以前的模型。
• 我们提出了一种改进的渐进式学习方法,它自适应地调整正则化和图像大小。我们证明这种方法可以加速训练,并同时提高准确性。
• 我们展示了在ImageNet、CIFAR、Cars和Flowers数据集上,比以前的技术提供了高达11倍的更快的训练速度和高达6.8倍的更好的参数效率。
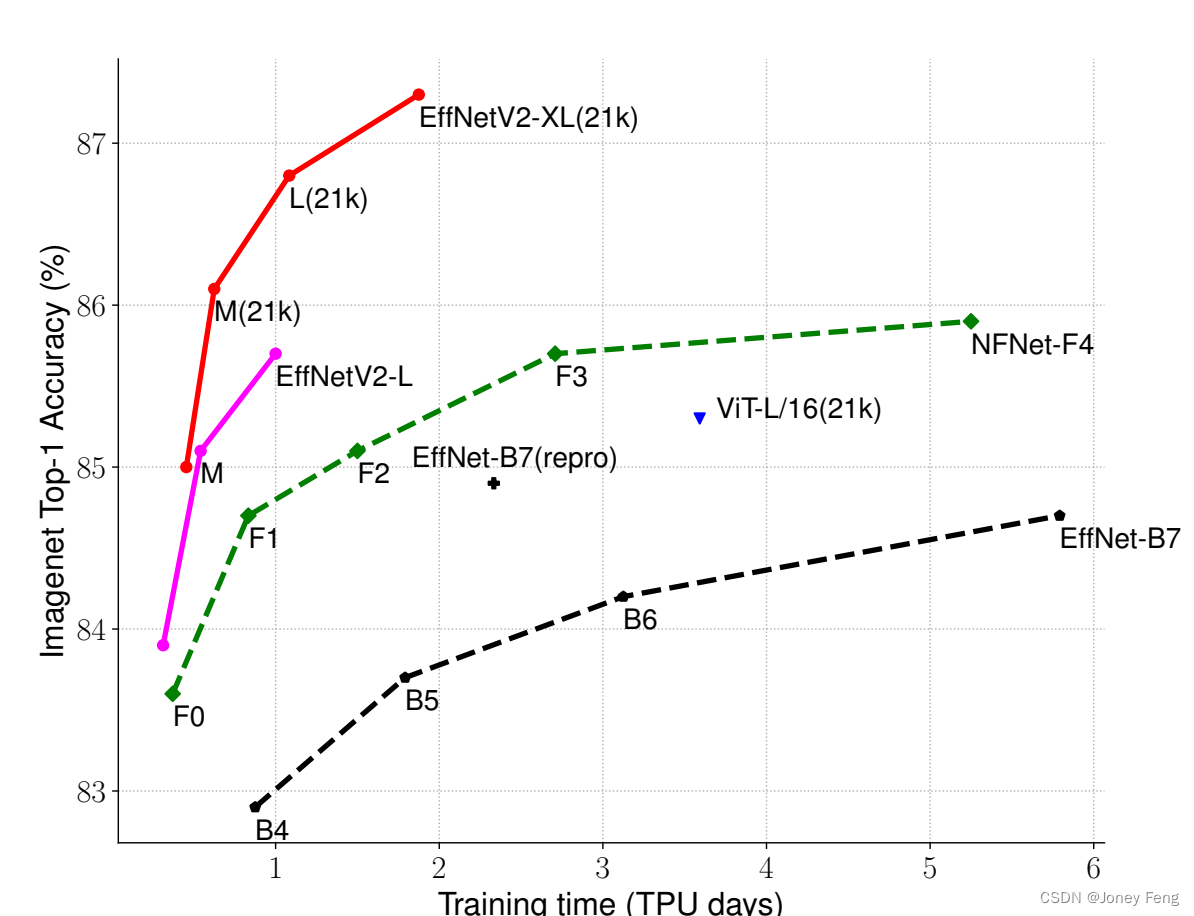
(训练效率)
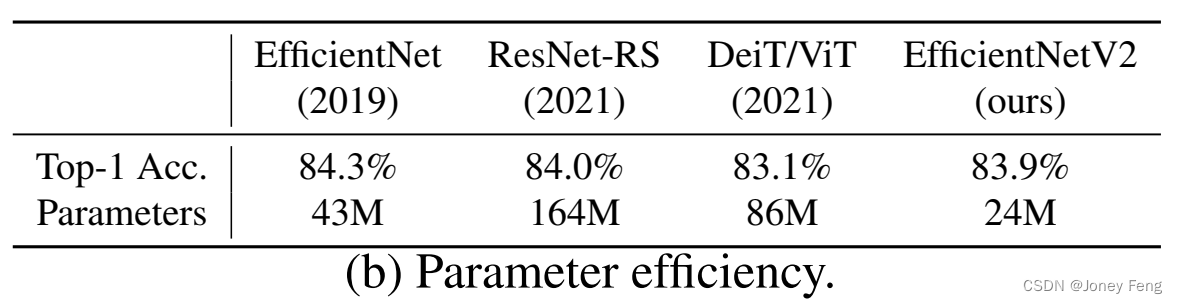
(参数效率。 参数效率是指在特定条件下,系统所能有效利用和最优化的参数设置的能力)
图1。ImageNet ILSVRC2012的top-1准确率和训练时间与参数的比较 - 标记有21k的模型是在ImageNet21k上预训练的,其他模型是直接在ImageNet ILSVRC2012上训练的。训练时间是以32个TPU核心为单位测量的。所有EfficientNetV2模型都是通过渐进式学习来训练的。我们的EfficientNetV2训练速度比其他模型快5倍到11倍,同时使用的参数少多达6.8倍。详情请见表7和图5
2、EfficientNetv2网络详解网络架构
EfficientNetv2是谷歌在EfficientNet基础上提出的新一代神经网络架构,旨在进一步提升模型的性能和效率。其主要的改进包括:
更深的网络结构:EfficientNetv2相比EfficientNet增加了更多的层数,进一步提升了模型的表达能力。
更高效的网络结构:EfficientNetv2采用了一系列的模型优化技巧,包括更高效的卷积操作、更少的参数、更少的计算量等,从而进一步提升了模型的效率。
更灵活的网络结构:EfficientNetv2引入了基于MobileNetV3的Squeeze-and-Excitation模块,可以自适应地调整通道的权重,从而提升模型的泛化能力。
更好的跨模态迁移能力:EfficientNetv2还引入了一个新的Cross-Transform模块,可以在图像分类和目标检测等任务之间进行跨模态迁移,从而提升模型的通用性。
总的来说,EfficientNetv2是一种高效、灵活、性能强大的神经网络架构,可以应用于各种计算机视觉任务,并在各种评测数据集上取得了领先的性能。
3.正文分析
训练和参数效率:许多工作,如DenseNet (Huang et al.,2017)和EfficientNet (Tan &Le,2019a),专注于参数效率,旨在用更少的参数实现更好的准确性。一些最近的工作专注于提高训练或推断速度,而不是参数效率。例如,RegNet (Radosavovic et al.,2020),ResNeSt (Zhang et al.,2020),TResNet (Ridnik et al.,2020)和EfficientNet-X (Li et al.,2021)专注于GPU和/或TPU推断速度;NFNets (Brock et al.,2021)和BoTNets (Srinivas et al.,2021)专注于提高训练速度。然而,他们的训练或推断速度往往是以更多参数为代价。本文旨在比先前的技术显著提高训练速度和参数效率。 渐进式训练:以前的工作提出了不同类型的渐进式训练,动态地改变GANs (Karras et al.,2018),迁移学习 (Karras et al.,2018),对抗学习 (Yu et al.,2019)和语言模型 (Press et al.,2021)的训练设置或网络。逐步调整大小 (Howard,2018)与我们的方法有关,旨在提高训练速度。然而,它通常会导致准确度降低。与之密切相关的另一项工作是Mix&Match (Hoffer et al.,2019),其中随机对每个批次的不同图像尺寸进行采样。逐步调整大小和Mix&Match使用相同的正则化对所有图像大小进行处理,导致准确性下降。在本文中,我们的主要区别在于适应性地调整正则化,以便同时提高训练速度和准确性。我们的方法部分受到课程学习 (Bengio等人,2009)的启发,通过从易到难安排训练示例。我们的方法也通过添加更多的正则化逐渐增加学习难度,但我们不会有选择性地选择训练示例。
神经架构搜索(NAS):通过自动化网络设计过程,NAS已经被用于优化图像分类(Zoph等,2018)、物体检测(Chen等,2019;Tan等,2020)、分割(Liu等,2019)、超参数(Dong等,2020)和其他应用的网络架构。以前的NAS工作主要集中在提高FLOPs效率(Tan&Le,2019b;a)或推理效率(Tan等,2019;Cai等,2019;Wu等,2019;Li等,2021)的改进。与之前的研究不同,本文利用NAS优化训练和参数效率。
EfficientNetV2 架构设计 在本节中,我们研究 EfficientNet(Tan&Le,2019a)的训练瓶颈,并介绍我们的训练感知 NAS 和缩放,以及 EfficientNetV2 模型。3.1 EfficientNet 回顾 EfficientNet(Tan&Le,2019a)是一组优化 FLOPs 和参数效率的模型。它利用 NAS 搜索基线 EfficientNet-B0,该模型在精度和 FLOPs 折衷上更好。然后使用复合缩放策略将基线模型扩展到 B1-B7 的一组模型。尽管最近的一些作品声称在训练或推理速度上取得了巨大的进展,但在参数和 FLOPs 效率方面常常不如 EfficientNet(表1)。在本文中,我们的目标是改善训练速度,同时保持参数效率。
3.2.理解训练效率 我们研究EfficientNet(Tan&Le,2019a)的训练瓶颈,以下简称EfficientNetV1,并提出了一些简单的技巧来提高训练速度。使用非常大的图像大小进行训练很慢:正如之前的研究所指出的那样(Radosavovic等,2020),EfficientNet的大图像大小会导致显著的内存使用。由于GPU / TPU上的总内存是固定的,因此我们必须使用较小的批量大小来训练这些模型,这会大大减慢训练速度。一个简单的改进是应用FixRes(Touvron等人,2019),即在训练时使用比推理更小的图像大小。正如表2所示,较小的图像尺寸会导致更少的计算量,并且可以实现更大的批量大小,从而将训练速度提高了2.2倍。值得注意的是,正如(Touvron等人,2020;Brock等人,2021)所指出的那样,使用更小的图像大小进行训练还会导致略微更好的准确性。但与(Touvron等人,2019)不同的是,在培训后,我们没有细调任何层。
在第四节中,我们将探讨一种更高级的训练方法,通过在训练过程中逐渐调整图像大小和正则化。由于深度卷积在早期层次上较慢,但在后期阶段上很有效:EfficientNet的另一个训练瓶颈来自于广泛使用深度卷积(Sifre,2014)。深度卷积具有比常规卷积更少的参数和FLOPs,但通常无法充分利用现代加速器。最近,在(Gupta&Tan,2019)中提出了Fused-MBConv,后来在(Gupta&Akin,2020;Xiong et al.,2020;Li et al.,2021)中用于更好地利用移动或服务器加速器。它用Figure 2所示的单个常规conv3x3替换了MBConv(Sandler et al.,2018;Tan&Le,2019a)中的深度卷积conv3x3和扩展conv1x1。为了系统地比较这两个构建块,我们逐渐用FusedMBConv(表3)替换EfficientNet-B4中原始的MBConv。当应用于早期阶段1-3时,FusedMBConv可以提高训练速度,并在参数和FLOPs方面有小的开销,但如果我们用Fused-MBConv(阶段1-7)替换所有块,则会显著增加参数和FLOPs,同时也会减慢训练速度。找到这两个构建块MBConv和Fused-MBConv的正确组合是非常困难的,这驱使我们利用神经架构搜索自动搜索最佳组合。
3.3. 训练感知 NAS 和规模扩展 为此,我们学习了多种设计选择,以提高训练速度。为了搜索最佳组合,我们现在提出了一种训练感知 NAS。NAS 搜索:我们的训练感知 NAS 框架主要基于之前的 NAS 工作 (Tan et al., 2019; Tan & Le, 2019a),但旨在联合优化现代加速器上的准确性、参数效率和训练效率。具体来说,我们使用 EfficientNet 作为骨干网络。我们的搜索空间是一个基于阶段的分解空间,类似于 (Tan et al., 2019),由卷积操作类型 fMBConv,融合 MBConv,层数,内核大小 f3x3,5x5g,扩展比 f1、4、6g 的设计选择组成。另一方面,我们通过 (1) 删除不必要的搜索选项,如 pooling skip ops,因为它们在原始的 EfficientNets 中从未被使用; (2) 重用骨干网络中的相同通道大小,因为它们已经在 (Tan & Le, 2019a) 中被搜索过了,来减小搜索空间的大小。由于搜索空间更小,我们可以在比 EfficientNetB4 大得多的更大网络上应用强化学习 (Tan et al., 2019) 或简单的随机搜索。具体地,我们对多达 1000 个模型进行采样,并使用减小的图像大小训练每个模型约 10 个 epoch。我们的搜索奖励将模型准确性 A、归一化训练步骤时间 S 和参数大小 P 结合起来,使用简单的加权乘积 A · Sw · Pv,其中 w = -0.07,v = -0.05 对应着权衡的平衡,类似于 (Tan et al., 2019)。EfficientNetV2 架构:表 4 显示了我们搜索到的 EfficientNetV2-S 模型的架构。与 EfficientNet 骨干网络相比,我们的搜索 EfficientNetV2 有几个显著的区别:(1) 第一个区别是 EfficientNetV2 在早期层中广泛使用 MBConv (Sandler et al., 2018; Tan & Le, 2019a) 和新添加的融合 MBConv (Gupta & Tan, 2019)。(2) 其次,EfficientNetV2 更喜欢较小的 MBConv 扩展比,因为更小的扩展比可以降低内存、计算负载和训练时间。此外,EfficientNetV2 还添加了一些新的操作符,如 Squeeze-and-Excitation (SE) 和 Swish。
EfficientNetV2 Scaling:我们利用类似于(Tan&Le,2019a)的复合缩放方法,将EfficientNetV2-S放大到EfficientNetV2-M / L,并进行了一些额外的优化:(1)我们将最大推理图像尺寸限制为480,因为非常大的图像经常导致昂贵的内存和培训速度开销;(2)作为启发式方法,在后期逐渐添加更多层(例如表4中的5和6阶段)以增加网络容量,而不会添加太多运行时间开销。
训练速度比较:图3比较了我们新的EfficientNetV2的训练步骤时间,其中所有模型都是使用固定图像尺寸而没有进行渐进学习的训练。对于EfficientNet(Tan&Le,2019a),我们展示了两条曲线:一条是使用原始推理尺寸进行训练,另一条是使用约30%较小的图像尺寸进行训练,与EfficientNetV2和NFNet(Touvron等人,2019; Brock等人,2021)相同。所有模型都进行了350个周期的训练,除了NFNet使用了360个周期的训练,因此所有模型具有相似数量的训练步骤。有趣的是,我们观察到当正确训练时,EfficientNets仍然具有相当强的性能权衡。更重要的是,通过我们的训练感知NAS和放缩,我们提出的EfficientNetV2模型的训练速度比其他最新模型快得多。这些结果也与我们在表7和图5中展示的推理结果相一致。
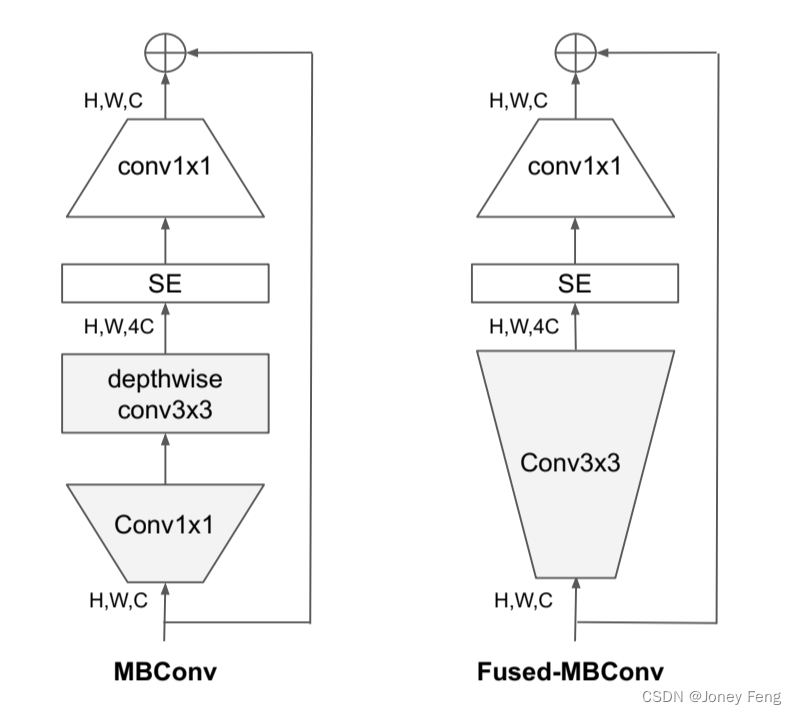
("图2.MBConv和Fused-MBConv的结构。")
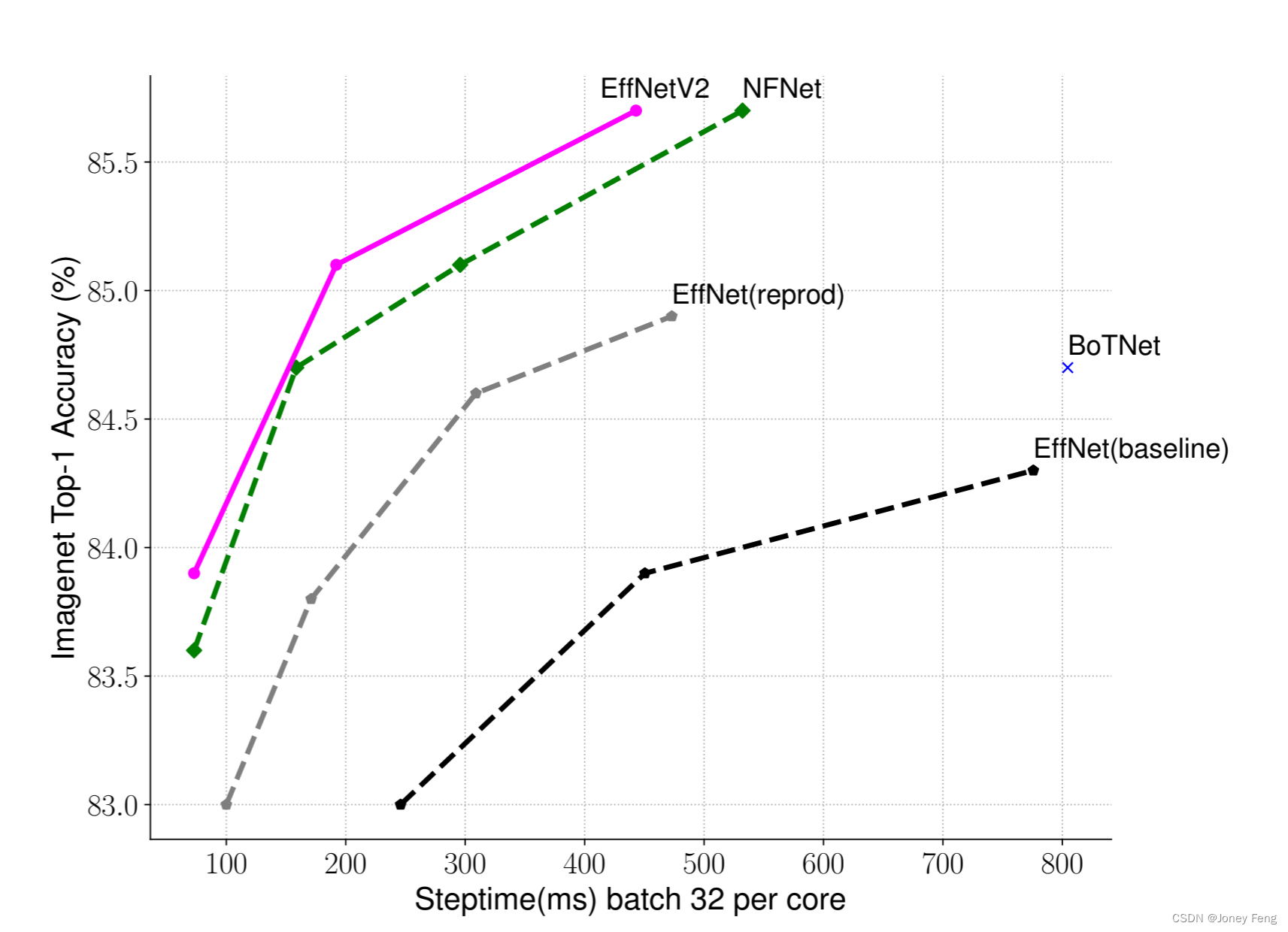
(图3.在TPUv3上的ImageNet准确率和训练步骤时间-较短的步骤时间意味着更好的表现;所有模型都使用固定图像大小进行训练,没有渐进学习。)
Table 1.EfficientNets have good parameter and FLOPs efficiency
表1。EfficientNets具有良好的参数和FLOPs效率。
| Top-1 Acc. | Params | FLOPs | |
| EfficientNet-B6(Tan & Le.2019a) | 84.6% | 43M | 19B |
| ResNet-RS-420(Bello et al.,2021) | 84.4% | 192M | 64B |
| NFNet-F1(Brock et al.,2021) | 84.7% | 133M | 36B |
表2.不同批次大小和图像尺寸下EfficientNet-B6的准确性和训练吞吐量
Table 2.EfficientNet-B6 accuracy and training throughput for dif ferent batch sizes and image size
| TPUv3 imges/sec/core | V100 imges/sec/gpu | ||||
| Top-1 Acc. | batch=32 | batch=128 | batch=12 | batch=24 | |
| train size=512 | 84.3% | 42 | OOM | 29 | OOM |
| train size=380 | 84.6 | 76 | 93 | 37 | 52 |
这个表格展示了EfficientNet-B6模型在不同批次大小和图像大小的情况下,在TPUv3和V100 GPU上的训练吞吐量以及对应的Top-1准确率。表格中列出了四组实验条件,包括批次大小(batch=32、batch=128、batch=12、batch=24)和训练图像大小(train size=512、train size=380)。TPUv3和V100 GPU分别是Google Cloud和NVIDIA公司的服务器设备,用于高性能计算和深度学习训练。
从表格中可以看出,随着批次大小的增加,训练吞吐量也会相应增加。例如,在TPUv3上使用batch=128可以实现76 imgs/sec/core的训练吞吐量,而使用batch=32时则由于OOM(out of memory)错误无法完成训练。此外,训练图像大小的变化也会影响训练吞吐量和Top-1准确率。例如,在TPUv3上使用train size=512时可以实现84.3%的Top-1准确率,而使用train size=380时可以提高到84.6%。这表明更大的训练图像可以提高模型的准确率,但也会增加训练的计算成本。
需要注意的是,表格中列举的训练吞吐量仅仅是用于衡量训练效率的指标,实际应用中还需要考虑模型的推理速度、内存占用等其他因素。此外,表格中的Top-1准确率仅仅是评价模型性能的一种指标,实际应用中还需要考虑其他因素,如模型的可解释性、鲁棒性等
表3. 用Fused-MBConv替换MBConv。未合并表示所有阶段都使用MBConv,合并阶段1-3表示在{2,3,4}阶段中将MBConv替换为Fused-MBConv。
Table 3.Replacing MBConv with Fused-MBConv.No fused denotes all stages use MBConv,Fused stage1-3 denotes re placing MBConv with Fused-MBConv in stage {2,3,4g}
| Params (M) | FLOPs (B) | Top-1 Acc. | TPU Images/sec/core | V100 Images/sec/core | |
| No fused | 19.3 | 4.5 | 82.8% | 262 | 155 |
| Fused stage1-3 | 20.0 | 7.5 | 83.1% | 362 | 216 |
| Fused stage1-5 | 43.4 | 21.3 | 83.1% | 327 | 223 |
| Fused stage1-7 | 132.0 | 34.4 | 81.7% | 254 | 206 |
这个表格展示了在EfficientNet-B6模型中,将常规MBConv(Mobile Inverted Residual Bottleneck Convolution)替换为Fused-MBConv(Fused Mobile Inverted Residual Bottleneck Convolution)后,模型的参数数量、浮点运算数(FLOPs)、Top-1准确率以及在TPU和V100 GPU上的训练吞吐量。表格中列出了四个实验条件,包括未合并使用MBConv(No fused)、在{2,3,4}阶段中使用Fused-MBConv(Fused stage1-3)、在{2,3,4,5,6}阶段中使用Fused-MBConv(Fused stage1-5)以及在{2,3,4,5,6,7,8}阶段中使用Fused-MBConv(Fused stage1-7)。
从表格中可以看出,将常规MBConv替换为Fused-MBConv会增加模型的参数数量和FLOPs。例如,在使用Fused stage1-7的情况下,模型的参数数量为132M,而在No fused的情况下仅为19.3M。此外,使用Fused-MBConv可以提高模型的Top-1准确率,例如在Fused stage1-3和Fused stage1-5的情况下,模型的Top-1准确率均为83.1%,高于No fused的82.8%。但是,在使用Fused stage1-7的情况下,模型的Top-1准确率反而下降至81.7%。
另外,表格中还列出了模型在TPU和V100 GPU上的训练吞吐量。可以看出,使用Fused-MBConv可以提高训练效率,例如在Fused stage1-3的情况下,模型在TPU上的训练吞吐量可以提高至362 imgs/sec/core,高于No fused的262 imgs/sec/core。同时,使用Fused-MBConv还可以提高在V100 GPU上的训练吞吐量。
需要注意的是,表格中列举的参数数量、FLOPs、Top-1准确率和训练吞吐量仅仅是用于比较常规MBConv和Fused-MBConv的性能差异,实际应用中还需要考虑其他因素,如模型的推理速度、内存占用等。此外,虽然Fused-MBConv可以提高模型的准确率和训练效率,但也会增加模型的计算成本,因此需要根据具体应用场景进行选择。
表格4. EfficientNetV2-S架构 - MBConv和FusedMBConv块的描述如图2所示
Table 4.EfficientNetV2-S architecture –MBConv and Fused MBConv blocks are described in Figure 2
| Stage | Operator | Stride | #Channels | #Layers |
| 0 | Conv3x3 | 2 | 24 | 1 |
| 1 | Fused-MBConv1,k3x3 | 1 | 24 | 2 |
| 2 | Fused-MBConv4,k3x3 | 2 | 48 | 4 |
| 3 | Fused-MBConv4,k3x3 | 2 | 64 | 4 |
| 4 | MBConv4,k3x3,SE0.25 | 2 | 128 | 6 |
| 5 | MBConv6,k3x3,SE0.25 | 1 | 160 | 9 |
| 6 | MBConv6,k3x3,SE0.25 | 2 | 256 | 15 |
| 7 | Conv1x1 & Pooling & FC | - | 1280 | 1 |
这个表格展示了EfficientNetV2-S模型的网络结构,包括每个阶段的操作符、步长、通道数和层数。EfficientNetV2-S是EfficientNetV2系列中的一个模型,相较于EfficientNetV2-B0模型,它具有更小的模型大小和更快的推理速度,适合于在资源受限的设备上进行部署。
表格中列出了EfficientNetV2-S模型的七个阶段,每个阶段都包含一个或多个操作符。其中,阶段0包含一个步长为2的Conv3x3操作符,用于降采样输入特征图。阶段1至3分别包含一个步长为1的Fused-MBConv1和两个步长为2的Fused-MBConv4操作符,用于提取不同层级的特征。Fused-MBConv是一种融合了多个操作的卷积块,它可以提高计算效率和模型准确率。阶段4和5分别包含一个步长为2和1的MBConv操作符,其中MBConv4和MBConv6是常规的Mobile Inverted Residual Bottleneck Convolution块,加入了SE(Squeeze-and-Excitation)注意力机制,用于进一步提升模型准确率。阶段6包含多个步长为2的MBConv6操作符,用于进一步提取高层次的语义特征。最后,阶段7包含一个Conv1x1和池化层,用于降维和全局平均池化,以及一个全连接层,输出模型的预测结果。
表格中的其他参数包括Stride、#Channels和#Layers。Stride表示该操作符的步长,用于控制特征图的尺寸。#Channels表示该操作符输出特征图的通道数,用于控制特征图的深度。#Layers表示该操作符内部卷积层的数量,用于控制模型的复杂度和计算量。在EfficientNetV2-S模型中,不同阶段的操作符具有不同的Stride、#Channels和#Layers,以便在不同层级提取和融合多尺度的特征,从而提高模型的准确率和泛化性能。
---------------------------------------------------------------------------------------------------------------------------------
这个算法描述了一种渐进式学习方法,其中使用自适应正则化来控制模型的复杂度。该算法的输入包括初始图像尺寸S0、正则化参数fφk0g和最终图像尺寸Se、正则化参数fφkeg,以及总的训练步数N和阶段数M。该算法的输出为在每个阶段中使用不同的图像尺寸和正则化参数训练模型,并在每个阶段结束后评估模型的性能。
算法的第一个循环用于迭代执行M个阶段的训练,其中每个阶段使用不同的图像尺寸和正则化参数。具体来说,第i个阶段使用的图像尺寸为Si,其中Si根据初始图像尺寸S0和最终图像尺寸Se以及阶段数M计算得出。同时,第i个阶段使用的正则化参数为Ri,其中Ri根据初始正则化参数φk0和最终正则化参数φke以及阶段数M计算得出。这样可以在不同的阶段中逐步加大图像尺寸和正则化参数,从而逐步提高模型的复杂度和性能。
算法的第二个循环用于在每个阶段中训练模型,并在每个阶段结束后评估模型的性能。具体来说,该循环中的每个阶段都会执行总的训练步数NM步,使用当前阶段的图像尺寸Si和正则化参数Ri进行训练。在每个阶段结束后,可以通过评估模型在验证集上的性能来确定当前阶段的最佳模型,并将其用于下一个阶段的训练。
总之,该算法的目的是通过逐步提高图像尺寸和正则化参数来渐进式地训练模型,并通过自适应正则化来控制模型的复杂度。该算法可以有效地提高模型的性能,并适用于各种计算资源和数据集规模。
表5。ImageNet 1号识别率。我们使用 RandAug(Cubuk et al.,2020),并报告3次运行的平均值和标准偏差。
Table 5.ImageNet top-1 accuracy.We use RandAug (Cubuk et al.,2020),and report mean and stdev for 3 runs.
| Size=128 | Size=192 | Size=300 | |
| RandAug magnitude=5 | 78.3±0.16 | 81.2±0.06 | 82.5±0.05 |
| RandAug magnitude=10 | 78.0±0.08 | 81.6±0.08 | 82.7±0.08 |
| RandAug magnitude=15 | 77.7±0.15 | 81.5±0.05 | 83.2±0.09 |
这个表格展示了使用RandAug数据增强方法在不同图像尺寸和不同增强强度下,EfficientNetV2模型在ImageNet数据集上的top-1准确率,包括平均值和标准差。RandAug是一种基于随机数据增强的方法,可以帮助模型学习更加鲁棒的特征,提高模型的泛化性能。
表格中的三行分别对应不同的RandAug增强强度(magnitude),包括5、10和15。每行中的三列分别对应不同的图像尺寸,包括大小为128、192和300。表格中的数值表示模型在对应参数设置下在ImageNet数据集上的top-1准确率,以及该准确率的标准差。
对于RandAug方法,其增强强度(magnitude)是一个重要的超参数,用于控制增强的强度和多样性。在本表格中,增强强度分别设置为5、10和15,可以看到随着增强强度的增加,模型的准确率有所提高。对于图像尺寸,表格中的实验结果表明,图像尺寸的增大可以进一步提高模型的准确率。同时,表格中的标准差也表明,在不同的运行中,模型的准确率存在一定的波动,但总体上模型的准确率相对稳定。
总之,这个表格的结果表明,使用RandAug数据增强方法可以提高EfficientNetV2模型在ImageNet数据集上的准确率,同时增强强度和图像尺寸的设置也可以对准确率产生影响
| 算法1 自适应正则化的渐进学习 |
| 输入:初始化图像大小S0和正则化函数{φk 0} 输入:最终图像尺寸Se和正则化函数{φk e} 输入: 总训练步数N和阶段M For i=0 to M – 1 do Image size: Si <-S0 + (Se – S0)*I / (M-1) Regularization: Ri <—{φk i =φk 0 +(φk e −φk 0)·i/(M−1)} Tranin the model for N/M steps with Si and Ri end for |
这个算法描述了一种渐进式学习方法,其中使用自适应正则化来控制模型的复杂度。该算法的输入包括初始图像尺寸S0、正则化参数fφk0g和最终图像尺寸Se、正则化参数fφkeg,以及总的训练步数N和阶段数M。该算法的输出为在每个阶段中使用不同的图像尺寸和正则化参数训练模型,并在每个阶段结束后评估模型的性能。
算法的第一个循环用于迭代执行M个阶段的训练,其中每个阶段使用不同的图像尺寸和正则化参数。具体来说,第i个阶段使用的图像尺寸为Si,其中Si根据初始图像尺寸S0和最终图像尺寸Se以及阶段数M计算得出。同时,第i个阶段使用的正则化参数为Ri,其中Ri根据初始正则化参数φk0和最终正则化参数φke以及阶段数M计算得出。这样可以在不同的阶段中逐步加大图像尺寸和正则化参数,从而逐步提高模型的复杂度和性能。
算法的第二个循环用于在每个阶段中训练模型,并在每个阶段结束后评估模型的性能。具体来说,该循环中的每个阶段都会执行总的训练步数NM步,使用当前阶段的图像尺寸Si和正则化参数Ri进行训练。在每个阶段结束后,可以通过评估模型在验证集上的性能来确定当前阶段的最佳模型,并将其用于下一个阶段的训练。
总之,该算法的目的是通过逐步提高图像尺寸和正则化参数来渐进式地训练模型,并通过自适应正则化来控制模型的复杂度。该算法可以有效地提高模型的性能,并适用于各种计算资源和数据集规模。
图4展示了我们改进的渐进式学习的训练过程:在早期的训练阶段,我们使用较小的图像和较弱的正则化来训练网络,这样网络可以轻松而快速地学习简单的表示法。然后,我们逐渐增加图像的大小,同时通过添加更强的正则化使学习更加困难。我们的方法建立在(Howard, 2018)的基础上,该方法逐渐改变图像大小,但我们在这里还要自适应地调整正则化。形式上,假设整个训练有N个步骤,目标图像大小为Se,具有正则化大小Φe= fφk eg的列表,其中k表示正则化类型,例如丢弃率或混合率值。我们将训练分为M个阶段:对于每个阶段1 ≤ i ≤ M,模型使用图像大小Si和正则化大小Φi=fφki g进行训练。最后一个阶段M将使用目标图像大小Se和正则化Φe。为简洁起见,我们启发式地选择初始图像大小S0和正则化Φ0,然后使用线性插值来确定每个阶段的值。算法1总结了这个过程。在每个阶段的开始,网络将继承前一个阶段的所有权重。与变压器不同,变压器的权重(例如位置嵌入)可能取决于输入长度,ConvNet的权重独立于图像大小,因此可以轻松地继承。

(图4.我们改进的渐进学习训练过程-从较小的图像尺寸和较弱的正则化(epoch=1)开始,然后逐渐增加学习难度,使用更大的图像尺寸和更强的正则化:更大的Dropout率、RandAugment值和Mixup比例(例如,epoch=300))
我们改进的渐进式学习通常与现有的正则化方式兼容。为了简便起见,本文主要研究以下三种正则化方式: • Dropout(Srivastava等人,2014年):一种网络层面的正则化方式,通过随机丢弃信道来减少协同作用。我们将调整丢失率γ。 • RandAugment(Cubuk等人,2020年):一种每个图像的数据增强方法,具有可调节的幅度。 • Mixup(Zhang等人,2018年):一种跨图像的数据增强方法。给定两个带标签的图像(xi,yi)和(xj,yj),它将它们与混合比例λ组合在一起:x<del>i = λxj +(1−λ)xi,y</del>i = λyj +(1−λ)yi。我们将在训练过程中调整Mixup比例λ。
5.1. ImageNet ILSVRC2012 配置:ImageNet ILSVRC2012(Russakovsky 等,2015)包含大约1.28M个训练图像和50,000个验证图像,涵盖了1000个类别。在架构搜索或超参数调整期间,我们将训练集中的25,000个图像(约2%)保留为minival,用于精度评估。我们还使用 minival 来执行早期停止。我们的 ImageNet 训练设置主要遵循 EfficientNets(Tan 和 Le,2019a):采用 RMSProp 优化器,衰减值为 0.9,动量为 0.9;批量归一化动量为 0.99;权重衰减为 1e-5。每个模型训练 350 个 epoch,总批量大小为 4096。学习率首先从 0 升温到 0.256,然后每 2.4 个 epoch 衰减 0.97。我们采用指数移动平均值,衰减速率为 0.9999,RandAugment(Cubuk 等,2020)、Mixup(张等,2018)、Dropout(Srivastava 等,2014)和随机深度(Huang 等,2016)等操作,生存概率为 0.8。
为了实现渐进式学习,我们将训练过程分为四个阶段,每个阶段大约有87个时期:早期阶段使用较小的图像尺寸和较弱的规范化,而后期阶段则使用更大的图像尺寸和更强的规范化,如算法1所述。表6显示了图像尺寸和规范化的最小值(第一阶段)和最大值(最后一阶段)。为简单起见,所有模型都使用相同的尺寸和规范化的最小值,但它们采用不同的最大值,因为更大的模型通常需要更多的规范化以防止过度拟合。根据(Touvron et al., 2020)的方法,我们的最大训练图像尺寸比推断要小约20%,但我们不会在训练后微调任何层。
表6. EfficientNetV2渐进式训练设置。
Table 6.Progressive training settings for EfficientNetV2.
| S | M | L | ||||
| min | max | min | max | min | max | |
| Image Size | 128 | 300 | 128 | 380 | 128 | 380 |
| RandAugment | 5 | 15 | 5 | 20 | 5 | 25 |
| Mixup alpha | 0 | 0 | 0 | 0.2 | 0 | 0.4 |
| Dropout rate | 0.1 | 0.3 | 0.1 | 0.4 | 0.1 | 0.5 |
RandAugment是一种数据增强技术,它可以随机选择一些数据增强操作来对图像进行处理,从而增强模型的训练效果。这些操作包括旋转、翻转、调整亮度和对比度等,通过引入随机性来增加训练数据的多样性,从而可以提高模型的泛化能力和准确率。
这个表格展示了EfficientNetV2模型的渐进式训练设置,其中包括三个不同的模型规模,分别为S、M和L。表格中的每个参数都对应于不同模型规模下的训练设置,包括图像尺寸、RandAugment增强强度、Mixup alpha参数和Dropout rate参数。
图像尺寸是指输入模型的图像大小,表格中的每个模型规模都有不同的图像尺寸范围,包括最小值和最大值。在训练过程中,模型的图像尺寸会逐步增加,以逐步提高模型的复杂度和性能。
RandAugment是一种用于数据增强的方法,可以增强模型对各种变换的鲁棒性。表格中的每个模型规模都有不同的RandAugment增强强度范围,包括最小值和最大值。在训练过程中,RandAugment增强强度也会逐步增加,以逐步提高模型的鲁棒性。
Mixup alpha参数是一种用于数据增强的方法,可以合成不同样本之间的特征,从而提高模型的泛化性能。表格中的每个模型规模都有不同的Mixup alpha参数范围,包括最小值和最大值。在训练过程中,Mixup alpha参数也会逐步增加,以逐步提高模型的泛化性能。
Dropout rate参数是一种用于正则化的方法,可以减少模型过拟合的风险。表格中的每个模型规模都有不同的Dropout rate参数范围,包括最小值和最大值。在训练过程中,Dropout rate参数也会逐步增加,以逐步减少模型过拟合的风险。
总之,该表格的目的是提供EfficientNetV2模型的渐进式训练设置,以帮助研究人员设计和实现高性能的计算机视觉模型。在训练过程中,逐步增加图像尺寸和增强强度、Mixup alpha参数和Dropout rate参数等设置,可以有效地提高模型的性能和泛化能力。
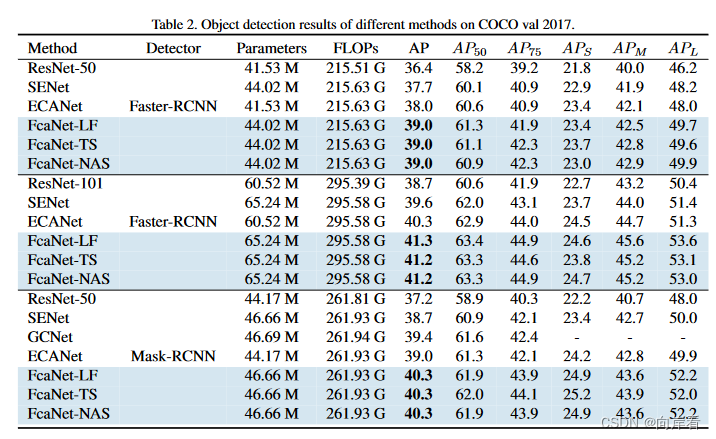
结果:如表7所示,我们的EfficientNetV2模型在ImageNet上比以前的ConvNets和Transformers具有更高的准确性和参数效率,并且速度显著更快。特别是,我们的EfficientNetV2-M在相同的计算资源下训练速度比EfficientNet-B7快11倍,准确性可比。我们的EfficientNetV2模型在准确性和推断速度方面也明显优于所有最近的RegNet和ResNeSt。图1进一步展示了训练速度和参数效率的比较。值得注意的是,这种加速是渐进训练和更好的网络的结合,我们将在我们的消融研究中研究它们的个体影响。最近,ViT在ImageNet的准确性和训练速度方面表现出色。然而,在这里,我们展示了通过改进的训练方法正确设计的ConvNets仍然可以在准确性和训练效率方面远远优于视觉Transformer。特别是,我们的EfficientNetV2-L达到了85.7%的top-1准确性,超越了在更大的ImageNet21k数据集上预训练的更大Transformer模型ViT-L/16(21k)。在这里,ViT在ImageNet ILSVRC2012上表现不佳;DeiT使用与ViT相同的架构,但通过添加更多的正则化来实现更好的结果。尽管我们的EfficientNetV2模型是为训练而优化的,但它们也表现出色的推断能力,因为训练速度通常与推断速度相关。图5基于表7可视化了模型大小、FLOPs和推断延迟。由于延迟通常取决于硬件和软件,因此我们使用相同的PyTorch Image Models代码库(Wightman,2021)以16个批次在同一台机器上运行所有模型。总的来说,我们的模型具有稍微更好的参数/FLOPs效率,但我们的推断延迟比EfficientNets快3倍。与特别优化为GPU的最近的ResNeSt相比,我们的EfficientNetV2-M在准确性方面提高了0.6%,但速度快2.8倍。
5.2. ImageNet21k设置:ImageNet21k(Russakovsky等人,2015)包含大约13M个带有21,841个类别的训练图像。原始的ImageNet21k没有训练/评估分割,因此我们将随机挑选的100,000个图像保留为验证集,并使用其余的作为训练集。我们主要复用了与ImageNet ILSVRC2012相同的训练设置,但进行了一些更改:(1)我们将训练周期更改为60或30以减少训练时间,并使用余弦学习率衰减,可以适应不同步骤而无需额外调整;(2)由于每个图像都有多个标签,因此我们在计算softmax损失之前将标签归一化为和为1。在ImageNet21k上预训练后,每个模型都使用余弦学习率衰减在ILSVRC2012上进行微调15个周期。结果:表7显示了性能比较,标记为21k的模型在ImageNet21k上进行了预训练,并在ImageNet ILSVRC2012上进行了微调。与最近的ViT-L/16(21k)相比,我们的EfficientNetV2-L(21k)使用2.5倍少的参数和3.6倍少的FLOPs,在训练和推理中运行6倍-7倍更快,并将top-1准确率提高了1.5%(85.3%对86.8%)。
我们想要强调一些有趣的观察结果:•在高准确率范围内,扩大数据规模比仅仅扩大模型规模更有效:当 top-1 准确率超过85%时,仅仅通过增加模型规模很难进一步提高准确率,原因在于过拟合非常严重。然而,额外的 ImageNet21K 预训练可以显著提高准确率。大型数据集的有效性也在之前的研究中得到观察(Mahajan等人,2018年;Xie等人,2020年;Dosovitskiy等人,2021年)。•在 ImageNet21k 上进行预训练可能非常高效。虽然 ImageNet21k 拥有 10 倍以上的数据,我们的训练方法使我们能够在两天内使用 32 个 TPU 核心完成 EfficientNetV2 的预训练(而不是像 ViT(Dosovitskiy等人,2021年)一样需要数周)。这比在 ImageNet 上训练更大的模型更有效。我们建议未来的大型模型研究将公共的 ImageNet21k 作为默认数据集。
5.3. 迁移学习数据集设置:我们在四个迁移学习数据集上评估我们的模型:CIFAR-10、CIFAR-100、Flowers 和 Cars。表 9 包括这些数据集的统计数据。对于这个实验,我们使用在 ImageNet ILSVRC2012 上训练的检查点。为了公平比较,没有使用 ImageNet21k 图像。我们的微调设置基本与 ImageNet 训练相同,在一些修改上与 (Dosovitskiy et al., 2021; Touvron et al., 2021) 相似:我们使用512 的较小批量大小,较小的初始学习率 0.001 (使用余弦衰减)。对于所有数据集,我们训练每个模型固定 10,000 步。由于每个模型微调的步骤非常少,我们禁用了权重衰减并使用了一个简单的 Cutout 数据增强。结果:表 8 比较了迁移学习性能。总的来说,我们的模型在所有这些数据集上都优于之前的 ConvNets 和 Vision Transformers,有时甚至有非常大的优势:例如,在 CIFAR-100 上,EfficientNetV2-L 的准确率比先前的 GPipe/EfficientNets 高了 0.6%,比先前的 ViT/DeiT 模型高了 1.5%。这些结果表明,我们的模型的泛化能力也超出了 ImageNet。
表7:EfficientNetV2在ImageNet上的性能结果(Russakovsky等,2015)-推理时间使用相同的代码库(Wightman,2021)在V100 GPU FP16上,批处理大小为16进行度量;训练时间是32个TPU核心规范化的总训练时间。标有21k的模型是使用1300万张图像在ImageNet21k上预训练的,而其他模型是从零开始直接在ImageNet ILSVRC2012上训练的,所有EfficientNetV2模型均使用我们改进的渐进学习方法进行训练。
Table 7.EfficientNetV2 Performance Results on ImageNet (Russakovsky et al.,2015)–Infer-time is measured on V100 GPU FP16 with batch size 16 using the same codebase (Wightman,2021);Train-time is the total training time normalized for 32 TPU cores.Models marked with 21k are pretrained on ImageNet21k with 13M images,and others are directly trained on ImageNet ILSVRC2012 with 1.28M images from scratch.All EfficientNetV2 models are trained with our improved method of progressive learning.
| Model | Top-1 Acc. | Params | FLOPs | Infer-time(ms) | train-time (hours) | |
| ConvNets & Hybird | EfficientNet-B3(Tan & Le,2019a) | 81.5% | 12M | 1.9B | 19 | 10 |
| EfficientNet-B4(Tan & Le,2019a) | 82.9% | 19M | 4.2B | 30 | 21 | |
| EfficientNet-B5(Tan & Le,2019a) | 83.7% | 30M | 10B | 60 | 43 | |
| EfficientNet-B6(Tan & Le,2019a) | 84.3% | 43M | 19B | 97 | 75 | |
| EfficientNet-B7(Tan & Le,2019a) | 84.7% | 66M | 38B | 170 | 139 | |
| RegNetY-8GF(Radosavovic et al.,2020) | 81.7% | 39M | 8B | 21 | - | |
| RegNetY-16GF(Radosavovic et al.,2020) | 82.9% | 84M | 16B | 32 | - | |
| ResNeSt-101(Zhang et al.,2020) | 83.0% | 48M | 13B | 31 | - | |
| ResNeSt-200(Zhang et al.,2020) | 83.9% | 70M | 36B | 76 | - | |
| ResNeSt-269(Zhang et al.,2020) | 84.5% | 111M | 78B | 160 | - | |
| TResNet-L(Ridnik et al.,2020) | 83.8% | 56M | - | 45 | - | |
| TResNet-XL(Ridnik et al.,2020) | 84.3% | 78M | - | 66 | - | |
| EfficientNet-X(Li et al.,2021) | 84.7% | 73M | 91B | - | - | |
| NFNet-F0(Brock et al.,2021) | 83.6% | 72M | 12B | 30 | 8.9 | |
| NFNet-F1(Brock et al.,2021) | 84.7% | 133M | 36B | 70 | 20 | |
| NFNet-F2(Brock et al.,2021) | 85.1% | 194M | 63B | 124 | 36 | |
| NFNet-F3(Brock et al.,2021) | 85.7% | 255M | 115B | 203 | 65 | |
| NFNet-F4(Brock et al.,2021) | 85.9% | 316M | 215B | 309 | 126 | |
| LambdaResNet-420-hybird(Bello,2021) | 84.9% | 125M | - | - | 67 | |
| BotNet-T7-hybrid(Srinivas et al.,2020) | 84.7% | 75M | 46B | - | 95 | |
| BiT-M-R152x2(21k)(Kolesnikov et al.2020) | 85.2% | 236M | 135B | 500 | - | |
| Vision Trandformers | ViT-B/32(Dosovitskiy et al.,2021) | 73.4% | 88M | 13B | 13 | - |
| ViT-B/16(Dosovitskiy et al.,2021) | 74.9% | 87M | 56B | 68 | - | |
| DeiT-B(ViT+reg)(Touvron et al.,2021) | 81.8% | 86M | 18B | 19 | - | |
| DeiT-B384(ViT+reg)(Touvron et al.,2021) | 83.1% | 86M | 56B | 68 | - | |
| T2T-ViT-19(Yuan et al.,2021) | 81.4% | 39M | 8.4B | - | - | |
| T2T-ViT-24(Yuan et al.,2021) | 82.2% | 64M | 13B | - | - | |
| ViT-B/16(21k)(Dosovitskiy et al.,2021) | 84.6% | 87M | 56B | 68 | - | |
| ViT-L/16(21k)(Dosovitskiy et al.,2021) | 85.3% | 304M | 192B | 195 | 172 | |
| ConvNets (ours) | EfficientNetV2-S | 83.9% | 22M | 8.8B | 24 | 7.1 |
| EfficientNetV2-M | 85.1% | 54M | 24B | 57 | 13 | |
| EfficientNetV2-L | 85.7% | 120M | 53B | 98 | 24 | |
| EfficientNetV2-S(21k) | 84.9% | 22M | 8.8B | 24 | 9.0 | |
| EfficientNetV2-M(21k) | 86.2% | 54M | 24B | 57 | 15 | |
| EfficientNetV2-L(21k) | 86.8% | 120M | 53B | 98 | 26 | |
| EfficientNetV2-XL(21k) | 87.3% | 208M | 94B | - | 45 |
(我们不包括预训练于非公开Instagram/JFT图像上的模型,或者拥有额外蒸馏或合奏的模型)
这个表格是展示了不同深度的 EfficientNetV2 模型在 ImageNet 数据集上的表现。其中,Top-1 Acc 表示模型的 Top-1 精度,Params 表示模型参数数量,FLOPs 表示模型的计算复杂度,Infer-time 表示模型预测一张图片的平均时间,Train-time 表示模型的训练时间。此外,还包括了其他模型的表现,如 RegNet、ResNeSt、TResNet、NFNet、LambdaResNet、BotNet 和 Vision Transformers 等。
通过观察表格可以发现,模型的 Top-1 精度随着模型深度的增加而提高,但同时模型参数数量和计算复杂度也会增加,导致模型训练和预测时间增加。例如,EfficientNetV2-S 模型的 Top-1 精度为 83.9%,参数数量为 22M,计算复杂度为 8.8B,预测一张图片的平均时间为 24 毫秒,训练时间为 7.1 小时;而 EfficientNetV2-L 模型的 Top-1 精度为 85.7%,参数数量为 120M,计算复杂度为 53B,预测一张图片的平均时间为 98 毫秒,训练时间为 24 小时。
此外,表格还展示了一些其他模型的表现,这些模型也在不同的指标上有不错的表现。例如,NFNet 系列模型在参数数量和计算复杂度相对较小的情况下,表现不错;Vision Transformers(ViT)模型在参数数量相对较小的情况下,表现也较好。
总的来说,这个表格展示了不同模型在 ImageNet 数据集上的表现,旨在帮助研究者选择适合自己任务的模型,并能够对比不同模型之间在不同指标上的优劣。
---------------------------------------------------------------------------------------------------------------
EfficientNet-B3/B4/B5/B6/B7: 这是一系列EfficientNet模型中的不同版本,它们的深度和宽度不同,可以根据不同的计算资源和准确性需求进行选择。
RegNetY-8GF/16GF: 这是一种高效的神经网络结构,通过调整网络的宽度和深度来提高模型的性能,同时保持计算和参数的效率。
ResNeSt-101/200/269: 这是一种具有新颖的Split-Attention机制的ResNet结构,它在ImageNet上的表现优于其他的ResNet模型。
TResNet-L/XL: 这是一种使用了自适应2D/3D卷积的高效网络结构,它可以在计算资源有限的情况下实现较高的准确性。
EfficientNet-X: 这是一种基于EfficientNet结构的改进版本,通过增加一种新的卷积核形状来提升性能。
NFNet-F0/F1/F2/F3/F4: 这是一种基于注意力机制的高效网络结构,它在ImageNet上的表现优于其他的高效模型。
LambdaResNet-420-hybrid: 这是一种结合了Lambda层和ResNet结构的混合模型,可以在小尺寸图像数据集上实现较高的准确性。
BotNet-T7-hybrid: 这是一种基于Bottleneck结构的高效网络结构,它在ImageNet上的表现优于其他的高效模型。
BiT-M-R152x2(21k): 这是一种使用了大规模无监督预训练的高效网络结构,它在大规模视觉任务上表现优秀。
ViT-B/32, ViT-B/16, ViT-L/16, ViT-B/16(21k): 这是一种基于Transformer结构的视觉注意力网络,它在大规模视觉任务上表现优秀。
DeiT-B, DeiT-B384: 这是一种结合了ViT和正则化机制的混合模型,它在小尺寸图像数据集上实现较高的准确性。
T2T-ViT-19, T2T-ViT-24: 这是一种结合了Transformer结构和自适应计算机制的混合模型,它在大规模视觉任务上表现优秀。
EfficientNetV2-S/M/L/S(21k)/M(21k)/L(21k)/XL(21k): 这是一种基于EfficientNet结构的改进版本,它在多个视觉任务上表现优秀。其中,“S/M/L”表示不同的模型深度和宽度,“(21k)”表示这些模型是在更大的数据集上进行训练的。
表8.转移学习性能比较 - 所有模型均在ImageNet ILSVRC2012上预训练,并在下游数据集上进行微调。转移学习准确性平均在五次运行中计算。
Table 8.Transfer Learning Performance Comparison –All models are pretrained on ImageNet ILSVRC2012 and finetuned on downstream datasets.Transfer learning accuracy is averaged over five runs.
| Model | Params | ImageNet Acc. | CIFAR-10 | CIFAR-100 | Flowers | Cars | |
| ConvNets | Gpipe(Huang et al.,2019) | 556M | 84.4 | 99.0 | 91.3 | 98.8 | 94.7 |
| EfficientNet-B7(Tan & Le,2019a) | 66M | 84.7 | 98.9 | 91.7 | 98.8 | 94.7 | |
| Vision Transformers | ViT-B/32(Dosovitskiy et al.,2021) | 88M | 73.4 | 97.8 | 86.3 | 85.4 | - |
| ViT-B/16osovitskiy et al.,2021) | 87M | 74.9 | 98.1 | 87.1 | 89.5 | - | |
| ViT-L/32(Dosovitskiy et al.,2021) | 306M | 71.2 | 97.9 | 87.1 | 86.4 | - | |
| ViT-L/16(Dosovitskiy et al.,2021) | 306M | 76.5 | 97.9 | 86.4 | 89.7 | - | |
| DeiT-B(Vit+regularization)(Touvron et al.2021) | 86M | 81.8 | 99.1 | 90.8 | 98.4 | 92.1 | |
| DeiT-B-384(Vit+regularization)(Touvron et al.2021) | 86M | 83.1 | 99.1 | 90.8 | 98.5 | 93.3 | |
| ConvNets (ours) | EfficientNetV2-S | 24M | 83.2 | 98.7±0.04 | 91.5±0.11 | 97.9±0.13 | 93.8±0.11 |
| EfficientNetV2-M | 55M | 85.1 | 99.0±0.08 | 92.2±0.08 | 98.5±0.08 | 94.6±0.10 | |
| EfficientNetV2-L | 121M | 85.7 | 99.1±0.03 | 92.3±0.13 | 98.8±0.05 | 95.1±0.10 | |
这个表格是用来比较不同深度学习模型在ImageNet预训练数据集上的性能,以及在下游任务(CIFAR-10、CIFAR-100、Flowers、Cars)上微调后的性能。其中,模型的参数表示模型的大小,ImageNet Acc.表示在ImageNet数据集上的准确率,CIFAR-10、CIFAR-100、Flowers、Cars分别表示在对应数据集上微调后的准确率。表格中的模型都是使用了迁移学习的方法,即在ImageNet上进行预训练,然后在下游任务上进行微调。
从表格中可以看出,不同深度学习模型在ImageNet上的表现存在一定的差异,其中EfficientNetV2-L参数最多,但在ImageNet上的准确率最高。同时,不同模型在不同任务上的表现也存在一定的差异。例如,在CIFAR-10上,ConvNets和EfficientNetV2-L两种模型的性能比其他模型要好。
总体来说,这个表格可以帮助人们选择适合自己研究任务的深度学习模型,并且可以提供参考性能指标
第9表. 转移学习数据集。
Table 9.Transfer learning datasets
| Train images | Eval images | Classes | |
| CIFAR-10(Krizhevsky & Hinton,2009) | 50,000 | 10,000 | 10 |
| CIFAR-100(Krizhevsky & Hinton,2009) | 50,000 | 10,000 | 100 |
| Flowers(Nilsback & Zisserman,2008) | 2,040 | 6,149 | 102 |
| Cars(Krause et al.,2013) | 8,144 | 8,041 | 196 |
表格10.与相同的训练设置比较—我们的新EfficientNetV2-M在更少的参数下运行速度更快。
Table 10.Comparison with the same training settings –Our new EfficientNetV2-M runs faster with less parameters.
| Acc.(%) | Params(M) | FLOPs(B) | TrainTime(h) | InferTime(ms) | |
| V1-B7 | 85.0 | 66 | 38 | 54 | 170 |
| V2-M | 85.1 | 55(-17%) | 24(-37%) | 13(-76%) | 57(-66%) |
表格11. 缩小模型大小 - 我们在批处理大小为128的V100 FP16 GPU上,测量推理吞吐量(图像/秒)
Table 11.Scaling down model size –We measure the inference throughput (images/sec)on V100 FP16 GPU with batch size 128.
| Top-1 Acc. | Parameters | FLOPs | Throughput | |
| V1-B1 | 79.0 | 7.8 | 0.7 | 2675 |
| V2-B0 | 78.7 | 7.4 | 0.7 | (2.1x)5739 |
| V1-B2 | 79.8 | 9.1 | 1.0 | 2003 |
| V2-B1 | 79.8 | 8.1 | 1.2 | (2.0x)3983 |
| V1-B4 | 82.9 | 19 | 4.2 | 628 |
| V2-B3 | 82.1 | 14 | 3.0 | (2.7x)1693 |
| V1-B5 | 83.7 | 30 | 9.9 | 291 |
| V2-S | 83.6 | 24 | 8.8 | (3.1x)901 |
这个表格主要是用来比较不同版本的EfficientNetV2模型在不同参数和计算量下的推理效率和性能指标。其中,模型的版本(V1和V2)表示模型的不同设计版本,B1、B2、B4和B5表示模型的不同深度,S表示模型的较小版本。Top-1 Acc.表示模型在ImageNet测试集上的Top-1准确率,Parameters表示模型的参数数量,FLOPs表示模型的浮点运算次数,Throughput表示模型的推理吞吐量(images/sec)。
从表格中可以看出,EfficientNetV2的不同版本和深度在参数数量和计算量上存在一定的差异,同时也会影响到模型的推理效率和性能表现。例如,EfficientNetV2-S是最小的版本,参数数量和计算量都比较小,但是推理吞吐量比较高,可以达到901 images/sec;而EfficientNetV2-B4和V2-B5是较大的版本,参数数量和计算量都比较大,但是推理吞吐量比较低,分别为628和291 images/sec。同时,通过对比V1和V2版本的模型,可以发现V2版本相比V1版本在相同参数数量和计算量下,能够获得更高的Top-1准确率和推理吞吐量,这说明V2版本的模型设计更加优秀。
综上所述,这个表格可以帮助人们选择适合自己需求的EfficientNetV2模型,并且提供了模型参数、计算量、推理吞吐量和准确率等方面的参考指标。
表12. ResNets和EfficientNets的渐进式学习–(224)和(380)表示推理图像尺寸。我们的渐进式训练改善了所有网络的准确性和训练时间。
Table 12.Progressive learning for ResNets and EfficientNets –(224)and (380)denote inference image size.Our progressive train ing improves both accuracy and training time for all networks.
| Baseline | Progressive | |||
| Acc.(%) | TrainTime | Acc.(%) | TrainTime | |
| ResNet50(224) | 78.1 | 4.9h | 78.4 | 3.5h(-29%) |
| ResNet50(380) | 80.0 | 14.3h | 80.3 | 5.8h(-59%) |
| ResNet50(380) | 82.4 | 15.5h | 82.9 | 7.2h(-54%) |
| EfficientNet-B4 | 82.9 | 20.8h | 83.1 | 9.4h(-55%) |
| EfficientNet-B5 | 83.7 | 42.9h | 84.0 | 15.2h(-65%) |
这个表格主要是用来比较不同深度学习模型在不同训练方式下的训练时间和准确率表现。其中,ResNet50和ResNet152是不同深度的ResNet模型,EfficientNet-B4和EfficientNet-B5是不同深度的EfficientNet模型。Baseline表示基准模型,Progressive表示采用渐进式学习的模型训练方式。Acc.表示模型在ImageNet测试集上的Top-1准确率,TrainTime表示模型的训练时间。
从表格中可以看出,采用渐进式学习的模型训练方式可以在更短的时间内达到更高的准确率。例如,ResNet50在224大小的图片上,采用渐进式学习的训练方式可以将准确率提高到78.4%,比基准模型提高了0.3个百分点,同时训练时间也缩短了29%。同样的,对于ResNet50和ResNet152在380大小的图片上的训练,采用渐进式学习的训练方式可以将准确率分别提高了0.3%和0.5%,同时训练时间也缩短了59%和54%。对于EfficientNet-B4和EfficientNet-B5,采用渐进式学习的训练方式也可以将准确率分别提高了0.2%和0.3%,同时训练时间也缩短了55%和65%。
综上所述,这个表格表明采用渐进式学习的模型训练方式可以在更短的时间内提高深度学习模型的准确率,同时也可以减少训练时间。这对于需要在短时间内训练高准确率模型的任务是非常有帮助的。
表13。自适应正则化 - 我们基于三次运行的平均值比较ImageNet的top-1准确率。
Table 13.Adaptive regularization –We compare ImageNet top-1 accuracy based on the average of three runs
| Vanilla | +our adaptive reg | |
| Progressive resize(Howard,2018) | 84.3±0.14 | 85.1±0.07(+0.8) |
| Random resize(Hoffer et al.,2019) | 83.5±0.11 | 84.2±0.10(+0.7) |
这个表格主要是用来比较不同正则化方法对网络准确率的影响。其中,Vanilla表示基准模型,Random resize表示采用随机缩放的正则化方法,Progressive resize表示采用渐进式缩放的正则化方法,+our adaptive reg表示结合自适应正则化方法和渐进式缩放方法的模型表现。Acc.表示模型在ImageNet测试集上的Top-1准确率,±0.14和±0.07表示准确率的标准差。
从表格中可以看出,采用自适应正则化方法和渐进式缩放方法结合的模型表现最佳,准确率为85.1%,比基准模型提高了0.8%。同时,采用随机缩放的正则化方法也可以提高模型准确率,但是提高幅度较小,仅为0.7%。这说明在训练深度学习模型时,采用适当的正则化方法可以提高模型的准确率和稳定性。
综上所述,这个表格表明自适应正则化方法和渐进式缩放方法结合可以提高深度学习模型的准确率,随机缩放的正则化方法也可以提高模型准确率,但是提高幅度较小。这对于提高深度学习模型的准确率和稳定性是非常有帮助的。
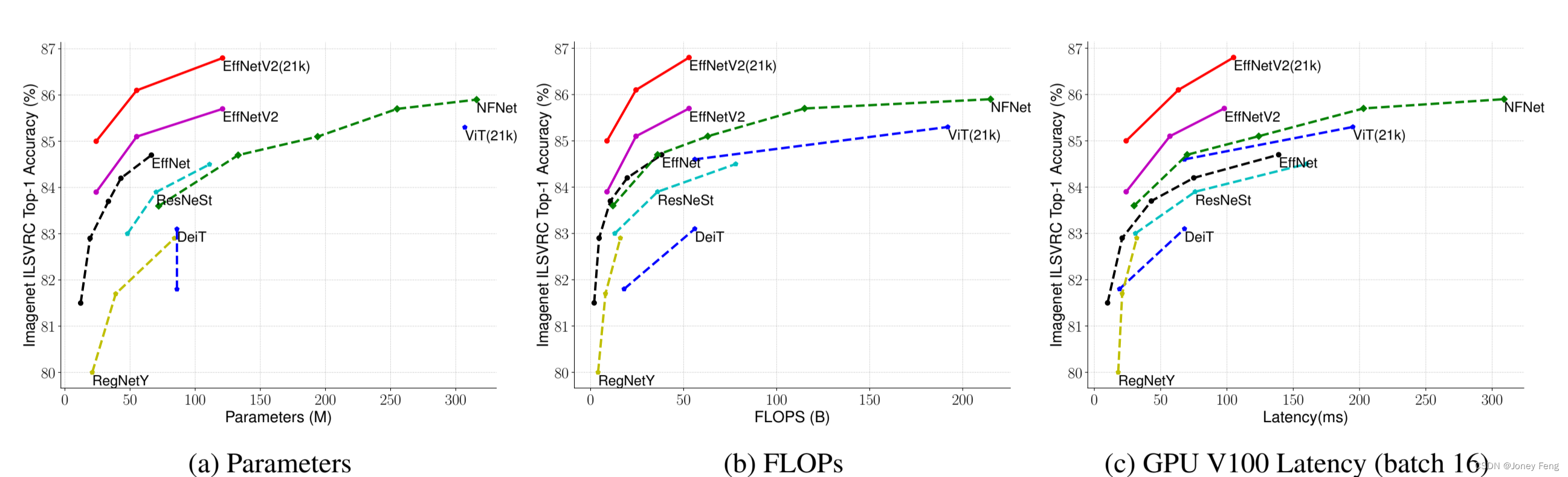
(图5. 模型大小、FLOP 和推理延迟-延迟是在 V100 GPU 上使用批量大小为16来测量的。21k 表示预训练 ImageNet21k 图像,其他仅在 ImageNet ILSVRC2012 上训练。我们的 EfficientNetV2 在参数效率方面略优于 EfficientNet,但推理速度快 3 倍)
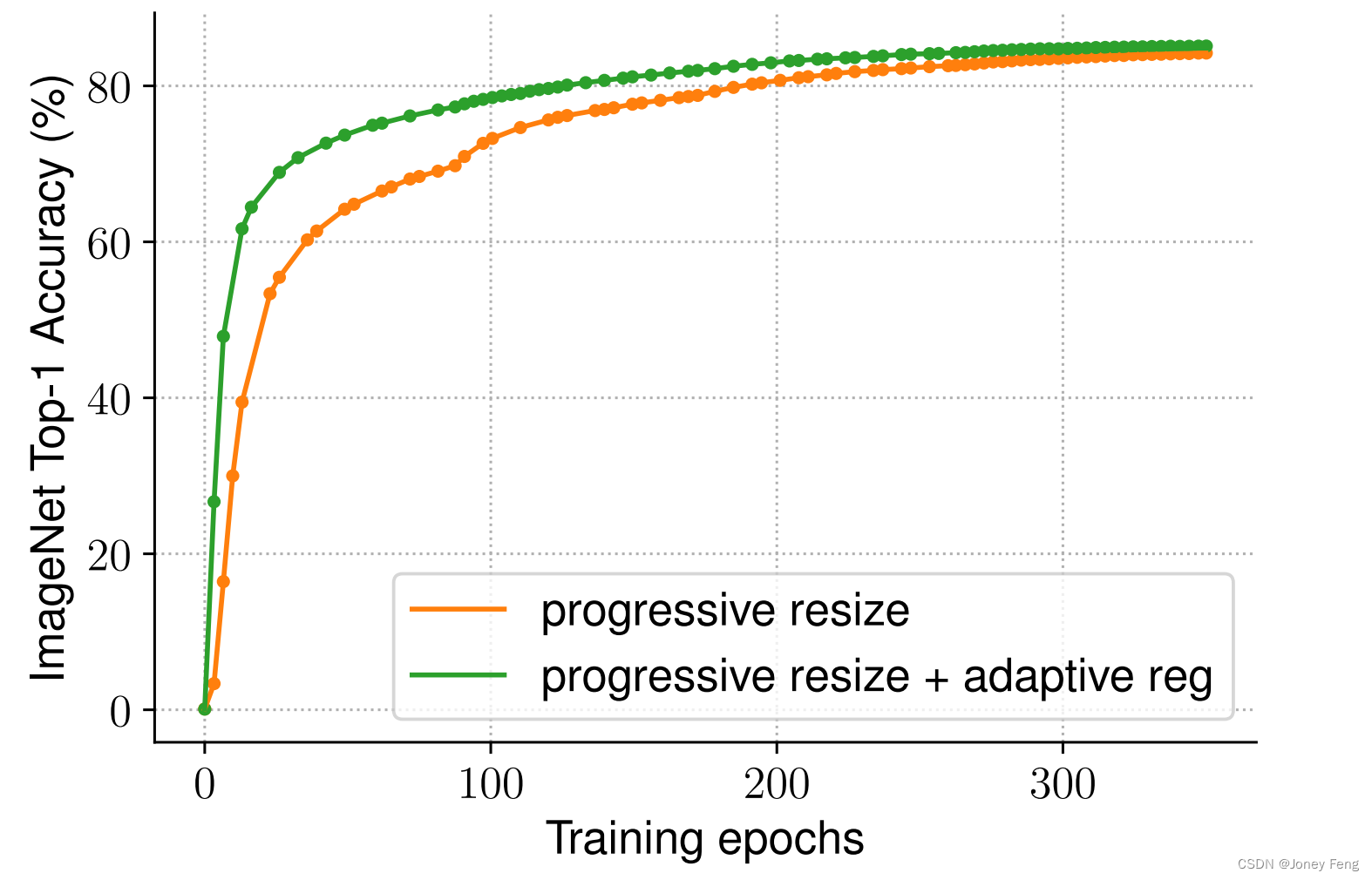 (图6.训练曲线比较-我们的自适应正则化收敛更快,并实现了更好的最终准确性)
(图6.训练曲线比较-我们的自适应正则化收敛更快,并实现了更好的最终准确性)
6.消融研究
6.1.与EfficientNet的比较 在本节中,我们将在相同的训练和推理设置下比较我们的EfficientNetV2(简称V2)与EfficientNets(Tan&Le,2019a)(简称V1)。相同训练的性能:表10显示了使用相同渐进学习设置的性能比较。当我们将相同的渐进学习应用于EfficientNet时,其训练速度(从139小时缩短至54小时)和准确性(从84.7%提高至85.0%)均优于原论文(Tan&Le,2019a)。然而,如表10所示,我们的EfficientNetV2模型仍然比EfficientNets表现更好:EfficientNetV2-M将参数减少了17%,FLOPs减少了37%,同时在训练中运行速度比EfficientNet-B7快4.1倍,在推理中快3.1倍。由于我们在这里使用相同的训练设置,我们将收益归因于EfficientNetV2架构。
缩小规模:之前的部分大多聚焦于大规模模型。通过使用EfficientNet复合缩放,我们将EfficientNetV2-S缩小规模,与较小的EfficientNets(V1)进行比较。为了方便比较,所有模型均在不进行渐进学习的情况下进行训练。与小型EfficientNets(V1)相比,我们的新EfficientNetV2(V2)模型一般而言更快,同时保持了可比的参数效率。
6.2.不同网络的渐进式学习:我们在不同网络上对渐进学习的性能进行了验证。表12展示了我们渐进式训练和基准训练(使用相同的ResNet和EfficientNet模型)的性能比较。基准ResNet模型的准确度比原论文(He et al., 2016)还要高,因为它们采用了我们改进的训练设置(参见第5节),使用更多的训练轮数和更好的优化器。我们还将ResNet的图像大小从224增加到380,以进一步增加网络容量和准确度。
如表12所示,我们的渐进式学习通常可以减少训练时间,同时提高所有不同网络的准确性。毫不奇怪,当默认图像大小非常小,例如224x224大小的ResNet50(224)时,训练加速有限(1.4倍速度加快);然而,当默认图像大小更大且模型更复杂时,我们的方法在准确性和训练效率方面获得更大的提高:对于ResNet152(380),我们的方法通过略微更好的准确性提高了训练速度2.1倍;对于EfficientNet-B4,我们的方法使训练加速2.2倍。
6.3. 自适应正则化的重要性 我们训练方法的一个关键洞察是自适应正规化,它根据图像大小动态调整正规化。本文选择了简单的逐步方法,但它也是一种通用方法,可以与其他方法结合使用。表13研究了我们的自适应正则化在两个训练设置上的表现:一个是逐渐增加图像大小从小到大的方法(Howard,2018),另一个是为每个批次随机采样不同的图像大小(Hoffer等人,2019)。因为TPU需要为每个新的大小重新编译图形,所以我们每隔八个epoch随机采样一个图像大小,而不是每个批次。与使用相同正则化的普通逐步或随机调整大小方法相比,我们的自适应正则化可以将准确性提高0.7%。图6进一步比较了逐步方法的训练曲线。我们的自适应正则化在早期训练epoch为小型图像使用更小的正则化,使得模型收敛更快并取得更好的最终准确性。
1.EfficientNetv2.py(pytorch实现)
from typing import List, Callable
import torch
from torch import Tensor
import torch.nn as nn
def channel_shuffle(x:Tensor, groups:int) -> Tensor:
batch_size, num_channels, height, width = x.size()
channel_per_group = num_channels // groups
x = x.view(batch_size, groups, channel_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(batch_size, -1, height, width)
return x
class InvertedResidual(nn.Module):
def __init__(self, input_c: int, output_c:int, stride:int):
super(InvertedResidual, self).__init__()
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.stride = stride
assert output_c % 2 == 0
branch_features = output_c // 2
assert (self.stride != 1) or (input_c == branch_features << 1)
if self.stride == 2:
self.branch1 = nn.Sequential(
self.depthwise_conv(input_c, input_c, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
@staticmethod
def depthwise_conv(input_c: int,
output_c:int,
kernel_s:int,
stride:int=1,
padding:int=0,
bias:bool=False) -> nn.Conv2d:
return nn.Conv2d(in_channels=input_c, out_channels=output_c, kernel_size=kernel_s,
stride=stride, padding=padding, bias=bias, groups=input_c)
def forward(self, x: Tensor) -> Tensor:
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch1(x), self.branch2(x)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
class ShuffleNetV2(nn.Module):
def __int__(self,
stages_repeats: List[int],
stages_out_channels: List[int],
num_classes:int=1000,
inverted_residual: Callable[..., nn.Module] = InvertedResidual):
super(ShuffleNetV2, self).__init__()
if len(stages_repeats) != 3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5:
raise ValueError("expected stage_out_channels as list of 5 positive ints")
self._stage_out_channels = stages_out_channels
input_channels=3,
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels = output_channels
self.maxpoool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.stage2:nn.Sequential
self.stage3:nn.Sequential
self.stage4:nn.Sequential
stages_names = ["stage{}".format(i) for i in [2, 3, 4]]
for name, repeats, output_channels in zip(stages_names, stages_repeats, stages_out_channels[1:]):
seq = [inverted_residual(input_channels, output_channels, 2)]
for i in range(repeats - 1):
seq.append(inverted_residual(output_channels, output_channels, 1))
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(output_channels, num_classes)
def _forward_impl(self, x:Tensor) -> Tensor:
x = self.conv1(x)
x = self.maxpoool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2, 3])
x = self.fc(x)
return x
def forward(self, x:Tensor) -> Tensor:
return self._forward_impl(x)
def shufflenet_v2_x0_5(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 48, 96, 192, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_0(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 116, 232, 464, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_5(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 176, 352, 704, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x2_0(num_classes=1000):
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 244, 488, 976, 2048],
num_classes=num_classes)
return model总结
结论 本文介绍了 EfficientNetV2,一种新的用于图像识别的更小、更快速的神经网络系列。通过经过训练感知的 NAS 和模型缩放的优化,我们的 EfficientNetV2 在显著优于以前的模型的同时,参数更加高效。为了进一步加速训练,我们提出了一种改进的渐进学习方法,它在训练过程中同时增加图像大小和规则化。广泛的实验表明,我们的 EfficientNetV2 在 ImageNet、CIFAR/Flowers/Cars 上取得了强大的成果。与 EfficientNet 和最近的工作相比,我们的 EfficientNetV2 在更快的训练速度和更小的规模上提升了 11 倍和 6.8 倍。致谢特别感谢 Lucas Sloan 在开源方面的帮助。我们感谢 Ruoming Pang、Sheng Li、Andrew Li、Hanxiao Liu、Zihang Dai、Neil Houlsby、Ross Wightman、Jeremy Howard、Thang Luong、Daiyi Peng、Yifeng Lu、Da Huang、Chen Liang、Aravind Srinivas、Irwan Bello、Max Moroz、Futang Peng 给我们反馈。