项目内容简介
爬取网站https://book.douban.com/top250上面的Top250数据,然后将数据保存到Mysql数据库中,最后这些数据记录以Web的方式进行展示,并实现对这些数据记录的CRUD(增删改查)!
项目实现简介
-
对豆瓣网站的爬虫的实现。
见项目中的
爬取豆瓣Top250脚本(beautifulSoup).py文件即可。这个Python脚本的主要功能是爬取豆瓣图书Top250的信息并将其保存到MySQL数据库中。具体实现过程如下:
- 引入需要的库:requests库用于发送http请求,BeautifulSoup库用于解析html页面,pymysql库用于将数据保存到MySQL数据库中,threading库用于实现多线程。
- 定义get_detail_urls()函数,用于获取每本书的详情页面的url链接。
- 定义parse_detail_url()函数,用于解析每本书的详情页面并将其保存到MySQL数据库中。
- 定义main()函数,用于爬取多页页面的内容,并利用多线程来解析数据。
- 在main()函数中,首先定义需要爬取的页面链接,然后遍历每个页面链接,获取每个页面中每本书的详情页面链接,再利用多线程来解析每本书的详情页面并将其保存到MySQL数据库中。
- 最后,在程序的末尾,创建多个线程来执行main()函数,以提高爬取速度。
总体来说,这段代码实现了一个简单的爬虫,并将爬取到的数据保存到了MySQL数据库中。
-
数据的WEB展示及数据的CRUD的实现。
见项目中的
web program(by flask)文件夹即可。这个文件夹是一个基于 Flask 和 MySQL 数据库的 Web 应用程序,用于展示和管理书籍信息。它实现了以下功能:
- 在首页展示所有书籍的信息,并支持数据的分页查询和展示。
- 提供查询功能,根据书名和作者名查询书籍信息。
- 提供添加、修改和删除书籍信息的功能。
具体过程如下:
- 导入所需的 Python 库和模块,包括 Flask、flask_paginate、pymysql 等。
- 初始化 Flask 应用程序和 MySQL 数据库连接。
- 定义首页路由函数 index(),根据请求方法(GET 或 POST)查询书籍信息并进行分页处理,最后将结果传递给 HTML 模板进行渲染。
- 定义添加书籍信息的路由函数 addBook(),返回一个包含表单的 HTML 模板。
- 定义修改书籍信息的路由函数 changeBook(),根据书籍 ID 查询数据库中对应的书籍信息,并将结果传递给 HTML 模板进行渲染。
- 定义更新书籍信息的路由函数 updateBook(),根据请求参数更新数据库中对应的书籍信息,并将结果重定向到首页。
- 定义插入书籍信息的路由函数 insertBook(),根据表单参数插入新的书籍信息到数据库中,并将结果重定向到首页。
- 定义删除书籍信息的路由函数 deleteBook(),根据书籍 ID 删除数据库中对应的书籍信息,并将结果重定向到首页。
- 启动 Flask 应用程序并监听请求,最后关闭游标对象和数据库连接。
项目的环境
- 项目需要的
软件环境如下:
安装Python环境并配置环境变量。
安装Mysql数据库环境并配置环境变量。
navicat软件,用于连接mysql数据库。
-
项目用到的
Python第三方库如下:[可用
pip包管理工具进行安装]
- requests
- bs4
- pymysql
- threading
- flask
- flask_paginate
-
项目可能需要的技术背景:
python + 爬虫 + flask + html + css + js + linux + json + mysql等。
使用指南
以下步骤基于Windows系统环境:
-
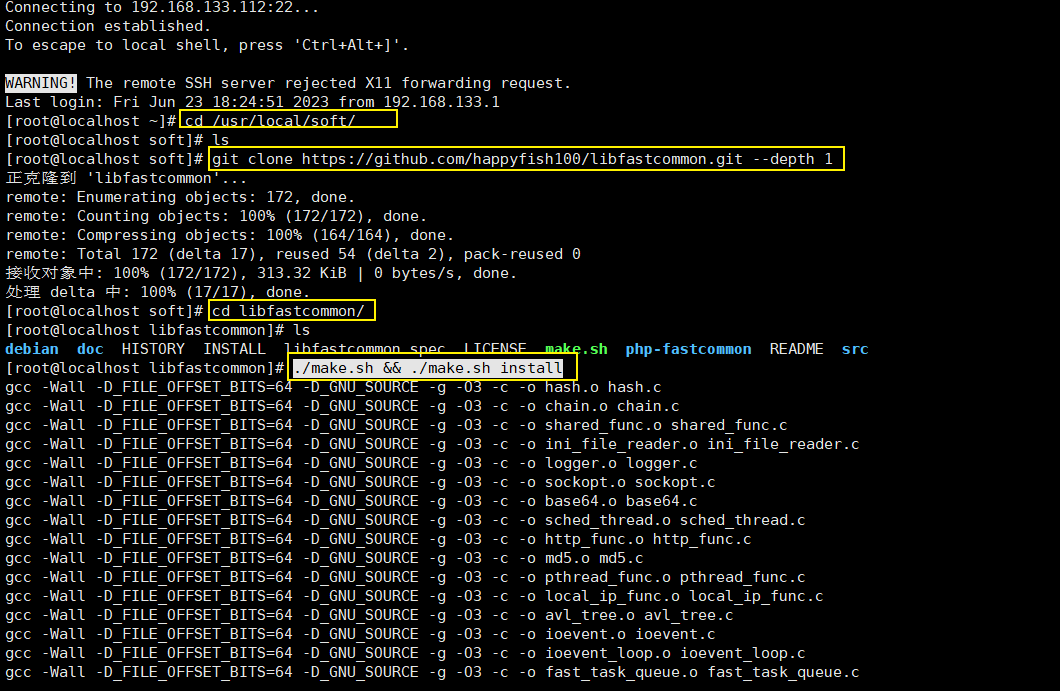
准备并安装好项目所需的环境。
-
Clone本项目的所有内容到本地。 -
打开
navicat软件,连接本地的mysql数据库,在其中先建立好一个名叫mydb数据库,再打开sql files文件夹,运行其中的1.create_douban_table.sql文件,从而在mydb数据库中建立名叫douban的数据表。 -
打开
crawler script文件夹,运行其中的爬取豆瓣Top250脚本(beautifulSoup).py爬虫程序,即可将豆瓣TOP250的书籍数据保存到本地mysql的mydb数据库的douban数据表中。【备注:如果此爬虫在运行过程中出现被封ip等情况,导致不能顺利爬取数据。此时也可以直接打开
sql files文件及,利用navicat软件运行其中的2.create_douban_data(2023-06-23爬取).sql文件,从而直接将我爬取的数据直接存储入douban数据表中,从而方便后续的步骤实现】 -
打开
web program(by flask)文件夹,运行其中的server.py服务器程序,即可启动相应的WEB可视化CRUD数据处理程序。 -
最后利用浏览器打开本地网址,即
127.0.0.1:5000即可。
示例和演示
静态展示
本项目的部分效果图如下:
爬取的数据(2023-06-23日爬取):

前端效果:
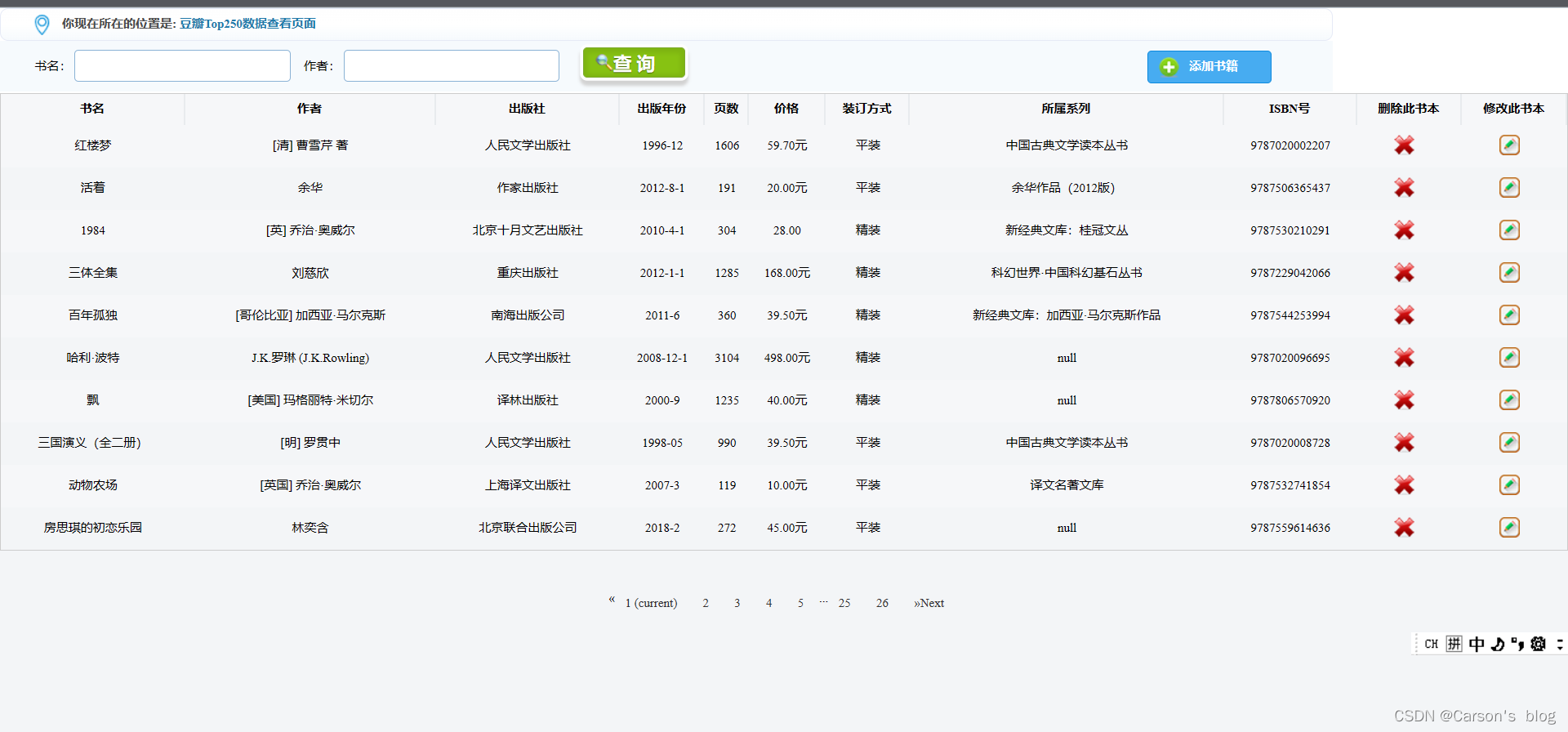
-
数据查找效果:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QxTMAmfJ-1687626928578)(README.assets/%E6%95%B0%E6%8D%AE%E6%9F%A5%E6%89%BE%E6%95%88%E6%9E%9C.png)]](https://img-blog.csdnimg.cn/ca15c20822a646c18b68ef62a07cb70e.png)
-
数据分页效果:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vF2hTbbX-1687626928579)(README.assets/%E6%95%B0%E6%8D%AE%E5%88%86%E9%A1%B5%E6%95%88%E6%9E%9C.png)]](https://img-blog.csdnimg.cn/da2ca49625c64c90bab726530c1aebc9.png)
-
数据删除效果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qCpX9CVX-1687626928580)(README.assets/%E6%95%B0%E6%8D%AE%E5%88%A0%E9%99%A4%E6%95%88%E6%9E%9C.png)]](https://img-blog.csdnimg.cn/3657c0fcaf734edebe62097e2fe56e0f.png)
数据添加效果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7QGT2apq-1687626928581)(README.assets/%E6%95%B0%E6%8D%AE%E6%B7%BB%E5%8A%A0%E6%95%88%E6%9E%9C.png)]](https://img-blog.csdnimg.cn/c8e888fbf822496d8f535f53d7a97f48.png)
数据修改效果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vl2Qjyh5-1687626928582)(README.assets/%E6%95%B0%E6%8D%AE%E4%BF%AE%E6%94%B9%E6%95%88%E6%9E%9C.png)]](https://img-blog.csdnimg.cn/234d876df1cd4866b059ed3de56a1aaf.png)
创作不易!!欢迎关注个人公众号!!获取更多知识内容!!
发送关键词: douban到公众号即可获取项目源码!











![[元带你学: eMMC协议详解 20] emmc的命令(cmd)、响应(resp)详解](https://img-blog.csdnimg.cn/img_convert/262abfa94e2b5642120b21810384ce4b.png)