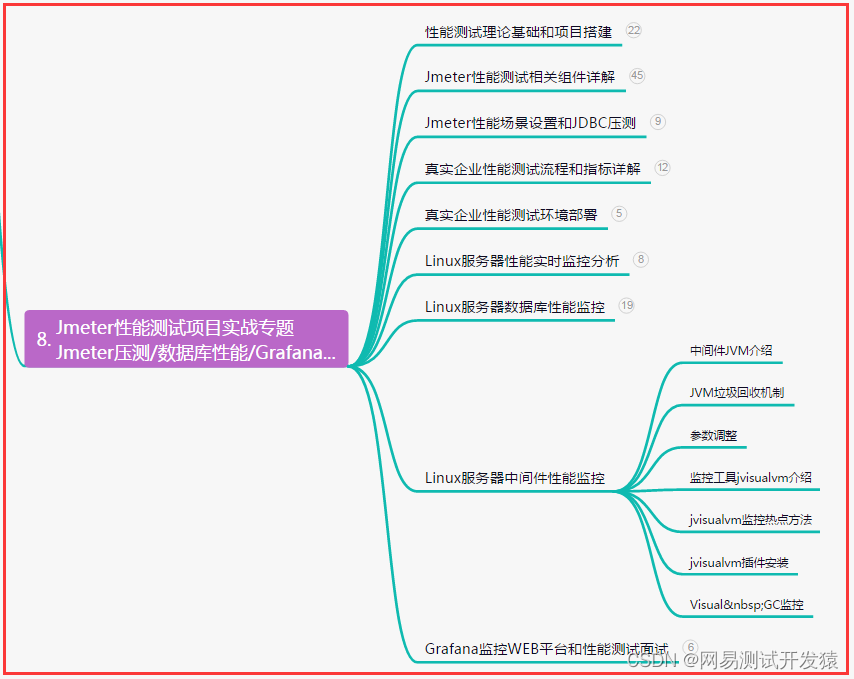
01. 背景
随着科技的发展,时序数据在我们的认知中占据越来越多的位置,小到电子元件在每个时刻的状态,大到世界每天的新冠治愈人数,一切可观测,可度量,可统计的数据只要带上了时间这个重要的因素就会成为时序数据。在运维领域,时序数据的范围则缩小到软件系统及其关联事物上面。随着数字化,物联网,人工智能等新技术的蓬勃发展,时序数据在运维领域也产生了爆发的增长,那么,究竟什么是时序数据,时序数据在智能运维(AIOps)领域又能为人们带来哪些价值呢?本文将会围绕这两点进行阐述,并拓展介绍一些具体应用时序数据的算法。
02. 时序数据

(图片来源于网络)
1)定义
简单的说,时序数据就是一串按时间维度索引的数据。具体的说,时序数据描述了某个被测量的对象在每个时间点上的测量值,时间点之间的间隔如果保持不变,比如都是1分钟,那么可以说这个时序数据的时间粒度/时间间隔/频率为1分钟。
从上述对时序数据的具体描述来看,时序数据主要由三个部分组成:对象,时间点,测量值。而我们可以说,一切带有这三个部分的组合的描述,都可以称作时序数据。只要想一想,就会发现,这类组合无处不在:人体每分钟 的 心率,cpu每秒 的 使用率,网站每小时 的 访问量,手机网络 每秒下载的数据量……,下面我们对这三个部分进行进一步解释:
① 对象:即被测量的主体是什么,一个对象可以有多个维度的属性。以cpu对象为例,可以是A集群、B物理机、C虚拟机的cpu,那么A,B,C就是cpu对象的3个维度属性。
② 时间点:即对象被测量时的时间位置,一般用时间戳表示。比如上述cpu对象在2022年6月29日上午8点12分38秒(Unix时间戳为:1656461558)被测量了一次,那么这个时间就是时间点。
③ 测量值:一个对象可能有多个测量值,每个测量值都对应一种指标。仍以上面的cpu为例,我们可以测量它在对应时间点的使用率,也可以测量它在对应时间点的使用值。
总的来说,每条时序数据都由对象、时间点、测量值三个部分组成,同一对象的时序数据记录了该对象在时间维度上的状态变化信息,对时序数据的分析就是挖掘时序数据蕴含的规律的过程。
2)特性
时序数据相较其他类型数据有一些显著特点:
- 数据一定带有时间字段/索引
- 数据按时间粒度稳定且持续的产生
- 数据基本不会有更新操作
- 一般而言数据会随着时间流逝而价值逐渐降低,具有时效性
- 数据的处理必须结合时间属性
针对时序数据的特点,业界有很多时序数据库专门用来高效的存储时序数据,如Influxdb,Prometheus等。我们在分析及使用时序数据时也应充分考虑到以上特性。
03. AIOps中的时序数据
上面对什么是时序数据以及时序数据的特性做了介绍,接下来我们看下在AIOps领域,时序数据又有怎么样的应用。
1)来源
在运维领域,为了保障整个软件系统的正常运行,需要在系统的各个层次定义要观测的时序数据,即定义要监控的指标。一般地,成熟的监控指标体系的搭建是以CMDB为骨架,以监控指标为脉络而进行的。因此,在AIOps中,时序数据的表现为监控指标。下图展示了运维领域中监控指标的体系层次,这是运维中的另一个大领域。

2)在AIOps中的应用方向
指标(Metric),日志(Log),调用链(Trace)是运维领域中产生的较为普遍的三种数据类型,因此基于运维数据之上的AIOps对于指标数据的利用也非常广泛,下面对应用成熟度比较高的两个方向进行探讨:
- 指标异常检测
- 指标预测
① 指标异常检测

(图片来源于网络)
指标异常检测,即判断监控指标体系中的对象指标是否发生了异常情况的过程。如果把软件系统比作人体,那么运维对象指标就对应人体的心率,血压,血糖,视力,激素水平等生理指标(类似上图),运维监控工具则对应各类用于检测的医疗设备。
需要保证软件系统的正常运行,首先就需要将表征/反映其是否健康的指标监控起来,然后再用异常检测算法进行实时或准实时的判断,当出现异常情况时能通过告警工具及时通知运维人员进行进一步检查,以决定是否采取相关措施。就像电视剧里一样,病人生病了,各类仪器在实时监控着病人的情况,当发现监控指标出现异常,就需要及时通知医生查看情况。而在运维领域,为了保证软件系统的高可用性,在软件系统的全生命周期都需要配备监控,并设定异常检测算法(不管是简单的静态阈值还是复杂的算法策略)。
1. 异常的种类
指标的异常,一般指监控对象的指标出现了不符合预期或者不符合正常情况下的变化。比如页面访问成功率突然的下跌,cpu使用率的飙升,内存使用率的缓慢增长(内存泄漏),周末业务量相较过往下跌等等,这里需要明确的是大部分指标的异常并不代表软件系统发生了故障。
另一方面,异常的判断通常需要结合具体的业务情况进行,因为数学统计上的异常不代表实际业务上发生了异常,二者的判断标准是不一样的,在实际的异常检测落地时不能忘记考虑这一点,否则算法就成自嗨的玩具了。
下面对常见的一些指标异常情况进行梳理:
离群点异常:
即当前的指标值与附近时间点的指标值差距较大,或者当前指标值与整个时间窗口内的指标值差距都较大。比如意外的下降或者上升,或者出现整个窗口内的峰值。

变点(change point)异常:
即该指标的出现不但不符合之前的趋势,并且还改变了之后指标的趋势,相当于在这个时间点的前后,指标的表现是两个模式。比如旅游人数,每年10月1日前后会持续10天左右高峰,与平时的情况大为不同,这里的变点可能就是9月30日(放假开始前夕)。

周期性异常:
在周期性指标数据内,某个时间点的指标表现不符合它以往的指标值。比如每晚10点都是英雄联盟游戏的在线人数高峰,但是某天晚10点进行了部分大区的版本更新,导致在线人数不符合之前同时间点的表现。

其他类异常:
比如上面谈到的内存泄露,对于很多指标下图的表现都不能算异常,但是对于内存指标而言却可以肯定的说出现了内存泄露的异常。

② 指标预测
指标预测,即通过对指标历史数据的分析,挖掘其存在的内部规律(比如趋势性,周期性等),根据这些规律对未来一段时间内的指标值进行预测。比如对业务量进行预测,判断未来半年需要投入多少成本来达到最优成本配置。甚至还可以对股市进行预测,当然,因为股市影响因素极多,很难只从时序数据本身挖掘到规律,自然预测的结果也就毫不可信了。
在AIOps领域,指标预测的应用方向一般有两个:
指标异常检测:
一般使用单步预测即可满足,通过对比预测值和实际值的差异大小来判断指标的异常程度。常用的如移动平均(MA),1阶,2阶,3阶指数平滑等统计类算法。
较长期资源量的预测:
比如存储资源、计算资源、网络资源、资源池等未来使用量的预测。对于业务上公有云的公司来说,资源即成本,能在满足业务使用及一定冗余的情况下尽可能的减少资源的购买量,能够显著提升效益。资源预测如果再配合上自动化工具,即可完成自动扩缩容的场景。对于另一些采购资源周期比较长的公司来说,能根据过去资源的使用情况预测下半年或者下一整年的资源配置是非常重要的,这能尽量使得资源利用率得到提高。
下图是一个时序预测的样例图:

2)方法汇列
这里对上面提到的两个应用方向介绍些具体的方法。对于异常检测算法,目前来看大致可以分为以下几种:
统计类算法:
复杂度低,计算速度快,泛化能力强,不需要大量的带标签数据做训练。但是某些算法的适用需要先验的了解指标的统计分布特性,并且无法“进化”,因为本质上还是属于某种规则。
机器学习算法:
鲁棒性较好,准确率较高。有的需要进行特征工程,训练模型,泛化能力一般。
深度学习算法:
计算复杂度高,需要进行特征工程,并且需要大量的数据进行训练,对于新标签可以重新训练,“进化”的越来越准。整体来看准确度最高。
但是在运维领域,机器学习和深度学习模型的落地经常会有“水土不服”的现象,主要体现为:
- 异常点的判定标准不统一,如上所说,异常的判定是需要结合业务情况的,而业务情况通常千奇百怪,难以有统一的异常判断标准对所有业务数据进行打标签工作。异常判断标准不同会导致模型的复用性变差,不能覆盖所有指标。
- 标签工具与工作量,很多公司的运维人员可能会面对数以万计乃至百万千万计的监控指标,打标签工具如何与大量的指标结合呢,打标签这么枯燥而繁杂的工作量消耗的人员成本也是巨大的,需要懂各类业务指标,并且能准确的标记,这是很难做到的,而一旦标签数据不准确,就会导致模型的准确率下降。
- 正负标签的样本量差距极大,在目前可用性极高的软件系统中,异常的指标一般占比不足1%,如何平衡正负样本的数量来进行模型训练也是需要解决的问题。
- 模型管理与部署,随着业务变更,资源扩缩,指标的形态是会发生变化的,当模型的准确率下降,是需要重新训练和部署模型的,这其中涉及到MLOps的持续训练了(CT,Continuous Training),需要工程化的流程来支撑,复杂度进一步加大。
- 特征工程,对于时序数据,通常会生成各类时序特征后再输入模型,特征工程的计算量及耗时对于实时性要求比较高的指标异常检测可能是个需要考虑的问题。
考虑到指标异常检测的费效比,是否要上机器学习乃至深度学习模型值得三思。
目前,统计类/无监督学习的算法在异常检测场景中因为“更接地气”,因此也更多的被运维工具/平台所采用。下面列举了一些常用的统计类和无监督机器学习算法,在后面算法介绍的部分会有进一步的说明。
统计类算法:Nsigma(含一阶差分与不差分两类),箱线图,EWMA,KDE
无监督机器学习算法:DBSCAN,孤立森林,LOF局部异常因子,OneClassSVM
对于指标预测算法,从不同的角度看有不同的分类:
- 从实现原理的角度,可以分为传统统计学,机器学习(又分非深度学习和深度学习)。
- 按预测步长区分,可以分为单步预测和多步预测,简单来说就是一次预测未来一个时间单元还是一次预测未来多个时间单元的区别。
- 按输入变量区分,可以分为自回归预测和使用协变量进行预测,区别在于维度中是否含有协变量,例如预测未来销售量时,如果只接受时间和历史销售量数据,则是自回归预测,如果可以接受天气、经济指数、政策事件分类等其他相关变量(称为协变量),则称为使用协变量进行预测。
- 按输出结果区分,可以分为点预测和概率预测,很多模型只提供了点预测而不提供概率预测,点预测模型后再加蒙特卡洛模拟(或其他转化为概率预测的方式)往往不能准确反映模型输出的预测概念,而在大多数场景下,概率预测更贴近事实情况,对于未来的预测本身就应该是一种概率分布。
- 按目标个数区分,可以分为一元、多元、多重时间序列预测。举例理解,使用历史的销售量预测未来1天的销售量为一元时间序列预测,使用历史的进店人数、销售量、退货量预测未来1天的进店人数、销售量、退货量(预测目标有三个)为多元时间序列预测,使用历史的红烧牛肉面、酸菜牛肉面、海鲜面的销售量预测未来1天的红烧牛肉面、酸菜牛肉面、海鲜面的销售量(预测目标有三种)为多重时间序列预测。[1]
注[1]:参考资料来源于亚马逊官方博客:
https://aws.amazon.com/cn/blogs/china/time-series-prediction-with-deep/
预测类的算法非常多,有的原理及使用非常复杂,这里只列出几种比较常用的且在AIOps实践中落地过的算法,同样,在后面的算法介绍部分对涉及到的算法会有进一步的说明。
统计类算法:prophet,holt-winters,SARIMA
机器学习类算法(非深度学习):回归类算法(包括LR及正则化LR,XGBoost回归等)
3)适用性分类
在AIOps落地应用上述算法时,经常会碰到使用者提出的一个问题:这么多算法,我到底该用哪一个。别急,在明确回答这个问题之前,我们需要再掌握一些时序数据相关的知识,才能更好的给出这个问题的答案。
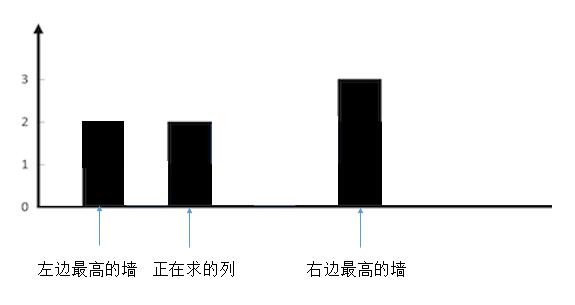
时序数据的平稳性:如果某条时序数据不会随着时间的推移而改变其统计特性,那么我们可以说这条时序数据是平稳的。这里的统计特性指的是这条时序数据的均值、方差以及其第t项与第(t+m)项数值的协方差。
这里用非正式的语言解释下这些统计特性的含义,可能不够严谨:均值不变代表整个时序数据是否是围绕某条线(均值线)上下波动的,比如下图左侧三条曲线都是围绕y=5波动的;方差不变代表整个时序数据的波动幅度是否是不变的,同理下图左侧的波动幅度是不变的(测量值最大是10,最小是0,围绕均值5最大波动幅度为5);第t项与第(t+m)项数值的协方差不变,代表着固定数据间隔下数据的走势是相同的,可以简单的理解为数据的周期是不变的。
下面给出示例图辅以说明:

为什么平稳性如此重要?因为对平稳序列进行分析很容易,因为可以假设未来的统计特性与目前观测到的统计特性是一致的,这使得大多数时间序列算法都以这样或那样的方式去利用这些属性(例如均值或方差)。如果原始序列不是平稳的,未来的预测将可能是错误的。很不幸,在实际应用中大多数的时间序列都是非平稳的。但好消息是消除时间序列非平稳性的方法有很多,常用的有:多阶差分、移除趋势和季节性去除、平滑,以及 Box-Cox 或对数等转换。
因此,对于异常检测算法的选择有如下建议:
- 如果时序数据是围绕某个数值上下波动的,满足正态分布或者近似正态分布的,Nsigma或者箱线图都是不错的选择,Nsigma在工业领域使用的极其广泛。
- 如果时序数据存在多个集中值,比如说出行量在早晚是高峰,其他时间是低峰,则可以使用kde去估计出时序数据的概率密度分布,通过概率密度进行异常检测。
- 如果时序数据的变化是缓慢的,很少有突变,那么可以使用1阶差分+Nsigma的方式捕捉离群点和变点。
- 如果时序数据的变化理应是上下波动的,而不是一直上升(比如内存泄露导致的内存使用率稳定增长)或者一直下降,则可以使用Cusum累积和算法去捕捉这种情况下的异常。
- EWMA基于平滑预测去判断异常,对于离群点和变点的检测都能很好的捕捉到。
- 基于机器学习的算法,通常对峰值离群点,多集中值数据的离群点有很好的检测。
对于预测算法则有如下建议:
- 对于无法转化成平稳序列的时序数据(即毫无规律或者受影响因素极多的数据),无法进行预测,无法进行预测,无法进行预测,或者说预测的结果没有任何可信度。(为什么要强调这一点,因为有些同学会认为预测算法什么数据都能准确预测,我想说那大家早就靠预测炒股发财了。)
- 如果对预测长度没有很高的要求,但对出预测速度有要求,比如历史数据有1000个点,只需要快速预测未来20个点,那么回归类机器学习算法可能是你首先可以尝试的选择。
- prophet算法在绝大部分预测场景里一般都能取得不错的效果,如果对于要预测的曲线非常了解,那么还可以配置很多prophet的参数让预测变得更准,唯一美中不足的是prophet的py包安装有些难度,且对于大数据量的预测计算速度没有回归类算法快速。
- holt-winters,SARIMA是较为传统且使用较为普遍的两类算法,对于使用者而言需要先确认要预测的时序数据是否含有季节性(不变的周期性)成分,并明确这个间隔(比如每个周六游戏在线人数都会固定的变多等)。两类算法的使用要求对时序数据的理解要多一些,比如是否有初始的趋势,比如对于自相关和偏自相关图阶数的选择等。目前借助auto-arima实现的SARIMA可以使用网格搜索最优参数,速度上可能会慢些。
以上的算法选择只是一些经验之谈,有条件的话最好拿数据都试一遍,看看效果再做选择,毕竟实践才是检验真理的唯一标准。
04. AIOps中时序数据算法介绍
这一小节会对上面提到的算法做一个简单的介绍,为了避免数学公式对阅读造成的精神折磨,下面不会列出各类复杂的公式和数学定义,这里的介绍仅仅是为了让大家对这些算法有一个初步的感性认识。
1)异常检测
所谓异常点,就是在给定数据集内,有的数据表现与其他数据显著不同的点。异常检测就是在数据集中寻找异常点的过程。
① Nsigma
在自然界、人类社会及其他各个领域,许多测量值的分布都会存在一种现象:中间密集,两边稀疏。比如正常人群的身高、体重、考试成绩、家庭收入等等,太突出的很少,太贫乏的也很少,大部分都在中间的水平波动。这种测量值的分布现象我们叫做正态分布,原因在于我们研究的对象群体总体来看具有类似的特征(比如都是正常人),这就是一个基准,但群体内部的个体存在差异,导致大家的特征并不会完全一致,所以测量值会在这个基准(均值)的上下波动,因此造成中间密集,两边稀疏的现象。

(图片来源于网络)
在运维领域,某业务稳定的情况下,机器的资源使用率可能稳定在60%,偶尔会上下波动,这也属于正态分布。但是如果出现服务器故障,资源使用率可能就会飙升或者陡降,这种波动都会超过原有的正常范围,在数学上会通过标准差来刻画这种波动的幅度,当波动的幅度超过N倍的标准差时,我们就可以认为发生了故障,完全正态分布的数据,超过3倍标准差的波动的概率为0.27%,工业界一般会使用是否超过3倍作为异常检测的判断。而实际的运维数据很多都只是贴近正态分布,因此,N的选择需要根据实际需要来定。
另一方面,在很多时候,我们不仅想知道整个窗口的离群点,还想捕捉到在趋势中变化的点,这时可以使用1阶差分的方法,一阶差分是将时序数据的后一个值减去前一个值得到的差值,这种方法会关心相邻点之间的变化,不关心整体的变化,通过这样的处理,我们再对差分的值进行Nsigma异常检测,就可以捕捉到与临近点离群的异常值了。
② 箱线图
给出一组数据,比如公司所有成员的年龄,我们如何准确把握年龄的分布情况呢,可以通过最大值最小值得到年龄的跨度,可以通过中位数得到区间的中心的范围(为什么不用平均数呢?有个笑话,说我和某富豪的平均资产是几千亿,但我显然只和几千有关系,跟亿是万万沾不上边的),最好能用年龄数轴加年龄点的来表示每个成员的年龄,这样就可以一目了然了。
箱线图即是结合了以上想法的做法,它刻画了整体的数据分布,并通过三个分位数描绘了内部的差距情况(如下图)。

正常的状态下,运维数据呈现稳定/规律的分布,当异常发生时,比如峰值,超过了之前刻画指标的箱线图标准,那么我们也可以认为发生了异常。上图的延伸线的长度类似于Nsigma的N,可以根据实际情况调整,以贴合业务的实际情况。
③ EWMA
EWMA(Exponential Weighted Moving Average),中文名叫做指数加权移动平均,是基于移动平均上的一种算法,本身是一种预测算法,它根据时序数据过去的趋势,使用指数加权平均的方式(距离预测点越近的点权重越大,这也符合人们的通常看法:越远的数据对现在的影响越小,越近的数据影响越大)对现有的值进行预测,如果预测值与实际值差异过大,则认为发生了异常。
④ KDE
KDE(Kernel Density Estimation),中文名叫核密度估计,它采用平滑的峰值函数(“核”)来拟合观察到的时序数据点,从而对真实的概率分布曲线进行模拟。下图是使用不同核函数进行拟合的结果。在很多情况下我们是不知道指标的分布情况的,比如直播访问量,可能在固定的几个时间段是比较高的(因为有不同的大主播在线),在其他时刻则相对较低。针对这种情况我们可以通过KDE去拟合真实的访问量在时段上的概率分布。当测量值在KDE图里是小概率的时候,我们就认为可能发生了异常。

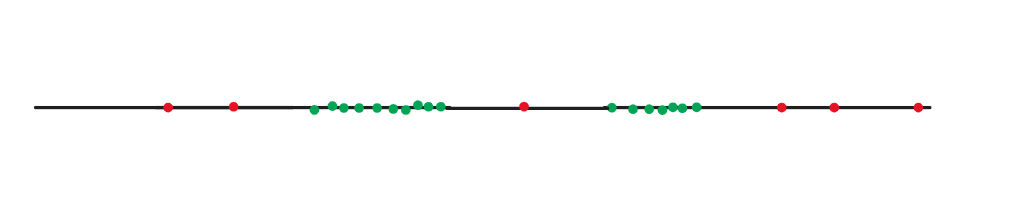
⑤ DBSCAN
DBSCAN,是机器学习聚类算法的一种,通过给定的半径,它会搜索每个点半径范围内的其他点,如果半径内没有其他的点,则认为此点距离其他的点过远,即为离群点。如下图所示,N点的半径内查找不到任何其他点,因此是离群点。红点半径内的其他点的数量较多,被认为是核心点,黄点半径内点数较少,被认为是边界点。
因为是基于密度计算范围,因此此算法可以接收高维数据,即也可以做多指标的异常检测。

⑥ 孤立森林
孤立森林算法是由周志华老师在2008年提出的异常检测算法,原理可以这么来比喻:下面是一条公路,路边种了不少的树,每个点都是一棵树,下面需要随机的进行隔断,最终保证每棵树都被单独隔离出来。显而易见,红点标识的树因为距离其他树更远,所以更容易被孤立出来。通过这种划分的难度来判断哪些点更孤立,因为异常的点总是距离正常点更远,因此就更容易被划分出来,正经的说法就是:异常样本相较普通样本可以通过较少次数的随机特征分割被孤立出来。单次的随机隔断可能存在误差,但是综合通过多次的随机隔断结果,就能有比较高的可信度了。单次的隔断可以理解为一颗孤立所有点的树,多次的隔断结果就是“孤立森林”了。
⑦ LOF
LOF(Local Outlier Factor),中文叫局部异常因子,类似DBSCAN,也是一种基于密度的算法,但是DBSCAN通常只能给出 0/1 的判断(即:是不是异常点),不能量化每个数据点的异常程度。相比较而言,LOF算法是可以量化每个数据点的异常程度的,可以在某种程度理解为异常概率。
⑧ OneClassSVM
OneClassSVM,一类SVM算法,属于支持向量机大家族的一种,它默认异常点的个数只占数据集的极少部分,因此它的目的就是找到一个超平面尽可能的将正常的点囊括进去,超平面以外的点认为是异常点。
2)时序预测
在进行数据分析和决策支撑时,总会希望能通过算法的时序预测结果作为数据支持。但可惜的是,现实中很多数据都无法做长期的预测,短期的预测有时效果也会不尽如人意,好用准确的预测是好的数据(可以转化为平稳性、长期大量的数据)加好的算法加好的分析人员共同作用的结果。
① Prophet
FaceBook 开源的 Prophet最初是为了创建高质量的商业预测而开发的,这个库试图去解决目前许多业务时间序列常见的困难:人类行为的季节性因素;新产品和市场趋势的变动;特殊情况下的点等。Prophet 官方声称,即使仅使用默认的参数设置,在许多情况下,Prophet 生成的预测与经验丰富的分析师提供的预测一样准确。在实际使用中prophet的表现也确实不俗,最重要的优点就是使用者友好,参数友好,使用简单。
prophet的原理本质上是基于时序分解的加性回归模型,首先按照趋势、周期、波动将时序数据分解,再分别通过对趋势性、周期性、假期和特殊事件、残差的预测的结果求和来进行时序预测。
② SARIMA
SARIMA( Seasonal Autoregressive Integrated Moving Average ) 季节性差分自回归滑动平均模型。是常用的时间序列预测分析方法之一。该方法可以对任何周期的时间序列进行建模。因为 SARIMA 的部分参数需要根据自相关图和偏自相关图来进行选取。所以存在一定的使用成本,对使用者的能力提出了一定的要求。
它首先通过一系列方法将原始时序数据进行转换为平稳性数据,再通过自回归和移动平均进行预测,最后将结果加上非平稳的因素作为最终的预测值。
③ 回归算法
通常,在我们的工作中,一般以快、准、好作为唯一的指导原则来构建模型。因此很多时候我们并不想花费大量的时间进行数据准备和数据变换,只想快速的进行预测,并期望得到不错的效果。这里,回归模型(包括普通的线性回归,也包括基于树的XGBoost回归)就提供了这样的解决方案。这种方法没有理论支持,但在实践中仍然非常有用,而且经常用于机器学习竞赛。接地气的说,就是我也不知道为什么它可以预测,并且预测的还算不错,但它就是可以做到。
当然,它通过移动时差的方式进行预测,所以他的预测步长在数据不多的时候非常有限,建议在数据充足的条件下使用它。
④ Holt-Winters
Holt-Winters 模型,得名于发明人的姓氏 Charles Holt 和他的学生 Peter Winters,它的另一个名字叫做三次指数平滑法,本质上仍是移动平均的变种,不过增加了非常多的因素,包括序列、趋势、季节等。
如果要预测的时序数据没有季节性,那么是不太建议使用这种方法的。
05. 总结
目前,智能运维仍是运维领域发展的方向和目标,而时序数据的异常检测和预测作为多数AIOps场景的落地基石仍在其中占据着重要地位。千淘万漉虽辛苦,吹尽狂沙始到金。只有一步一步的思考和实践, 才能将AIOps的落地做得更好。