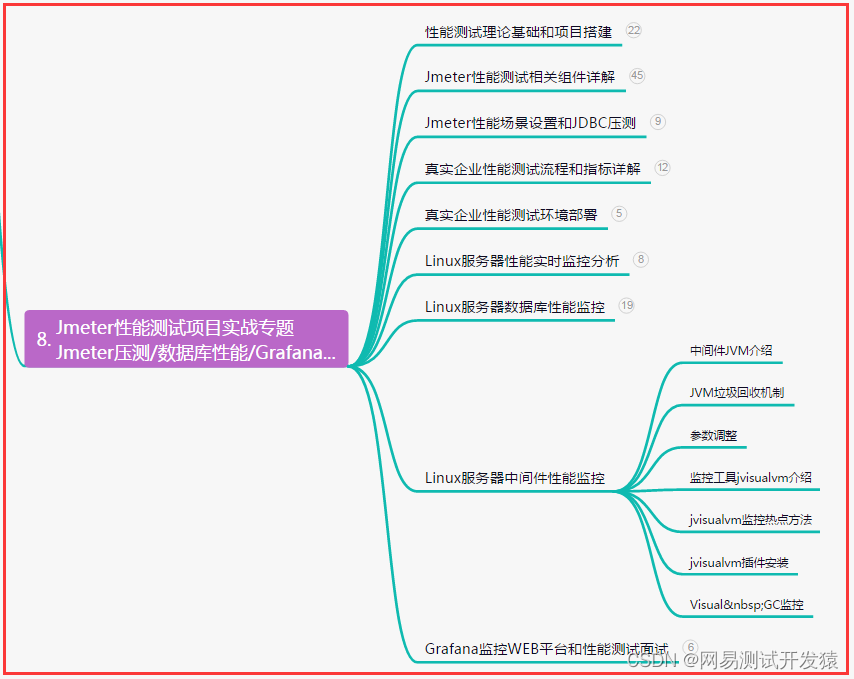
Antlr全称(ANother Tool for Language Recognition),Antlr4是一款强大的语法分析器生成工具,推特,Haddop,Oracle等各大知名公司在用到了Antlr来构建自己的语言处理类项目。
一门语言的正式描述称为语法(grammar),Antlr可以为语言生成一个词法分析器,并且自动建立语法分析树,也能自动生成树的遍历器,然后我们就可以访问树的节点,执行自定义业务逻辑代码。
本文主要是介绍Antlr4的使用,因此不过多的介绍其特性和各种使用方式,以简单的Demo来了解下它的功能。
基本概念
词法分析
词法分析也称为分词,此阶段从左向右扫描源文件,将其字符流分割成一个个的词(token) 。所谓 token ,就是源文件中不可再进一步分割的一串字符,类似于英语中单词,或汉语中的词。
- 语法中一般有多种字符组合起来的规则,有意义的字符组合一般为(Token)
- 将文本转换为Token的程序称为词法分析器(Lexier),过程称为词法分析(Lexical analysis)

语法分析
- 词法分析完成后,字符流就被转换为 token 流了,接下来根据语言的语法规则来解析这个token 流,被称为语法分析。
- 语法分析的过程就是不断的将语法规则应用于源程序,将源程序解析成一颗抽象语法树(parser tree),该树记录了语法分析器识别语句结构的过程;

入门Antlr
以上词法分析和语法分析的过程,在实际使用antlr的过程都不需要关心,只需要进行定义语法规则,以及处理最后的语法分析树即可。
环境配置
有两种方式可以快速的跑起来Demo,命令行或者IDE,不过由于命令行当前默认需要JDK 11,可能大部分人不支持这个版本,还有一些额外的配置。
antlr 在 4.10仍然支持JDK 1.8,在4.10.1之后需要JDK11。
我们直接使用Idea自带的插件来完成Demo;
安装antlr4的插件;

Idea插件使用
新建一个Expr.g4文件,记得文件名要和里面定义的语法规则名称保持一致。

grammar Expr;
prog: expr EOF ;
expr: expr ('*'|'/') expr
| expr ('+'|'-') expr
| INT
| '(' expr ')'
;
NEWLINE : [\r\n]+ -> skip;
INT : [0-9]+ ;
复制代码在文件目标规则上右键测试,Antlr4帮我们生成了最终的分析树:

Java API使用
1. 引入Pom
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4</artifactId>
<version>4.10.1</version>
</dependency>
复制代码2. 插件生成Java代码

把生成的文件拷贝到自己的包下:

其中文件的含义:
- ExprParser 包含语法分析器的定义,专门用来识别我们的语言。
- ExprLexer 词法分析器的定义,将输入字符分解为词汇符号;
- ExprLexer.tokens antlr4会将我们定义的词法符号指定一个数字类型,然后将对应的关系存储在这个文件中,一般来说我们用不到,高阶选手可能会用到。
- ExprListener antlr4在遍历语法树的时候,遍历器会触发一系列的事件,通知我们的监听器;ExprListener是监听器的接口定义 ExprBaseListener是监听器的空实现。
- ExprVisitor 如果我们想要自己显示的自定义遍历语法树,可以使用Visitor来遍历树,ExprBaseVistor是默认的空实现。
3. 使用生成代码

package me.aihe.bizim.expr;
import me.aihe.bizim.expr.ExprParser.ProgContext;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CodePointCharStream;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
public class ExprDemo {
public static void main(String[] args) {
// 构建字符流
CodePointCharStream charStream = CharStreams.fromString("1+2+3*4");
// 从字符流分析词法, 解析为token
ExprLexer lexer = new ExprLexer(charStream);
// 从token进行分析
ExprParser parser = new ExprParser(new CommonTokenStream( lexer) );
// 使用监听器,遍历语法树,根据语法定义,prog为语法树的根节点
ProgContext prog = parser.prog();
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk( new ExprBaseListener(), prog );
// 使用visitor,生成自定义的对象
Object accept = prog.accept(new ExprBaseVisitor<>());
// 打印生成的语法树
System.out.println( prog.toStringTree(parser));
}
}
复制代码4. 编写自定义的业务逻辑
通过antlr4的API,我们可以识别定义语言的语法树,但是如何做自定义的处理呢,基于上述的demo,我们实现自己的visior用于构建一个计数器的实现。
在真正实现之前,我们需要将语法重新区分一下不同的分支,方便逻辑处理:
grammar Expr;
prog: expr EOF ;
expr: expr ('*'|'/') expr #MultiOrDiv
| expr ('+'|'-') expr #AddOrSub
| INT #Lieteral
| '(' expr ')' #Single
;
NEWLINE : [\r\n]+ -> skip;
INT : [0-9]+ ;
复制代码package me.aihe.bizim.expr;
import java.util.Objects;
import me.aihe.bizim.expr.ExprParser.AddOrSubContext;
import me.aihe.bizim.expr.ExprParser.ExprContext;
import me.aihe.bizim.expr.ExprParser.LieteralContext;
import me.aihe.bizim.expr.ExprParser.MultiOrDivContext;
import me.aihe.bizim.expr.ExprParser.ProgContext;
import me.aihe.bizim.expr.ExprParser.SingleContext;
public class EvalExprVisitor extends ExprBaseVisitor<Integer>{
/**
* 入口处调用
* @param ctx the parse tree
* @return
*/
@Override
public Integer visitProg(ProgContext ctx) {
ExprContext expr = ctx.expr();
return visit(expr);
}
/**
* expr: expr ('*'|'/') expr
* | expr ('+'|'-') expr
* | INT
* | '(' expr ')'
* @param ctx the parse tree
* @return
*/
/**
* expr ('*'|'/') expr
*/
@Override
public Integer visitMultiOrDiv(MultiOrDivContext ctx) {
Integer op1 = visit(ctx.expr(0));
Integer op2 = visit(ctx.expr(1));
String operator = ctx.getChild(1).getText();
if (Objects.equals(operator, "*")){
return op1 * op2;
}
if (Objects.equals(operator, "/")){
return op1 / op2;
}
return 0;
}
/**
* expr ('+'|'-') expr
*/
@Override
public Integer visitAddOrSub(AddOrSubContext ctx) {
Integer op1 = visit(ctx.expr(0));
Integer op2 = visit(ctx.expr(1));
String operator = ctx.getChild(1).getText();
if (Objects.equals(operator, "+")){
return op1 + op2;
}
if (Objects.equals(operator, "-")){
return op1 - op2;
}
return 0;
}
/**
*
* @param ctx the parse tree
* @return
*/
@Override
public Integer visitSingle(SingleContext ctx) {
return visit(ctx);
}
/**
* INT
* @return
*/
@Override
public Integer visitLieteral(LieteralContext ctx) {
return Integer.valueOf(ctx.INT().getText());
}
}
复制代码5. 验证程序
符合预期,这样我们自定义的计数器解析程序就处理好了;
import java.util.Arrays;
import java.util.List;
import java.util.Objects;
import me.aihe.bizim.expr.ExprParser.ProgContext;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CodePointCharStream;
import org.antlr.v4.runtime.CommonTokenStream;
import org.springframework.util.Assert;
public class ExprDemo {
public static void main(String[] args) {
List<String> testSet = Arrays.asList(
"1+2",
"1+2+3*4",
"3/3",
"10/2",
"5*5+10+5*5"
);
List<Integer> res = Arrays.asList(
3,15,1,5,60
);
for (int i = 0; i < testSet.size(); i++) {
// 构建字符流
CodePointCharStream charStream = CharStreams.fromString(testSet.get(i));
// 从字符流分析词法, 解析为token
ExprLexer lexer = new ExprLexer(charStream);
// 从token进行分析
ExprParser parser = new ExprParser(new CommonTokenStream( lexer) );
// 使用监听器,遍历语法树,根据语法定义,prog为语法树的根节点
ProgContext prog = parser.prog();
// 使用visitor,生成自定义的对象
Integer integer = prog.accept(new EvalExprVisitor());
System.out.println(integer);
Assert.isTrue(Objects.equals(integer, res.get(i)),"");
}
}
}
复制代码
6. 生成调用图
借用一个辅助工具dot语言,用来生成各种自定义图形的,基于上述的语法树监听器,我们构建自己的执行程序,然后查看真实的调用过程。
package me.aihe.bizim.expr;
import java.util.List;
import java.util.Set;
import java.util.Stack;
import me.aihe.bizim.expr.ExprParser.ProgContext;
import org.antlr.v4.runtime.ParserRuleContext;
import org.antlr.v4.runtime.misc.MultiMap;
import org.antlr.v4.runtime.misc.OrderedHashSet;
public class EvalExprListener extends ExprBaseListener {
private Graph graph = new Graph();
Stack<String> current = new Stack<>();
String prefix = "exp_";
@Override
public void enterEveryRule(ParserRuleContext ctx) {
if (ctx instanceof ProgContext){
return;
}
// 生成唯一的节点标识
String n = prefix + System.identityHashCode(ctx);
String node = n + String.format("[label=<%s>]",ctx.getText());
graph.nodes.add(node);
if (!current.empty()){
graph.edge( current.peek(), n );
}
current.push(n);
}
@Override
public void exitEveryRule(ParserRuleContext ctx) {
if (ctx instanceof ProgContext){
return;
}
current.pop();
}
public String toDot(){
return graph.toDot();
}
static class Graph {
Set<String> nodes = new OrderedHashSet<>();
MultiMap<String, String> edges = new MultiMap<>();
public void edge(String source, String target) {
if (source == null || target == null){
return;
}
edges.map(source, target);
}
public String toDot() {
StringBuffer sb = new StringBuffer();
sb.append("digraph G { \n");
sb.append("node[shape=plaintext,style=filled];graph[splines=ortho];\n");
// 声明节点
for (String node : nodes) {
sb.append(node).append(";");
sb.append("\n");
}
sb.append("\n");
for (String source : edges.keySet()) {
List<String> targets = edges.get(source);
for (String target : targets) {
sb.append(" ")
.append(source)
.append(" -> ")
.append(target).append("\n");
}
}
sb.append("}\n");
return sb.toString();
}
}
}
复制代码使用监听器:
CodePointCharStream charStream = CharStreams.fromString(testSet.get(i));
// 从字符流分析词法, 解析为token
ExprLexer lexer = new ExprLexer(charStream);
// 从token进行分析
ExprParser parser = new ExprParser(new CommonTokenStream( lexer) );
// 使用监听器,遍历语法树,根据语法定义,prog为语法树的根节点
ProgContext prog = parser.prog();
// 使用visitor,生成自定义的对象
Integer integer = prog.accept(new EvalExprVisitor());
System.out.println(integer);
Assert.isTrue(Objects.equals(integer, res.get(i)),"");
ParseTreeWalker walker = new ParseTreeWalker();
EvalExprListener listener = new EvalExprListener();
walker.walk(listener, prog );
System.out.println(listener.toDot());
复制代码5*5+10+5*5 生成结果:
digraph G {
node[shape=plaintext,style=filled];graph[splines=ortho];
exp_2085857771[label=<5*5+10+5*5>];
exp_248609774[label=<5*5+10>];
exp_708049632[label=<5*5>];
exp_1887400018[label=<5>];
exp_285377351[label=<5>];
exp_344560770[label=<10>];
exp_559450121[label=<5*5>];
exp_716083600[label=<5>];
exp_791885625[label=<5>];
exp_2085857771 -> exp_248609774
exp_2085857771 -> exp_559450121
exp_248609774 -> exp_708049632
exp_248609774 -> exp_344560770
exp_708049632 -> exp_1887400018
exp_708049632 -> exp_285377351
exp_559450121 -> exp_716083600
exp_559450121 -> exp_791885625
}
复制代码在dot语言解析网站上贴下生成的代码: dreampuf.github.io/GraphvizOnl…

7. Java代码生成Dot图
或者直接用Java代码生成对应的SVG图也是可以的:仍然使用上述监听器。
下载plantuml:plantuml.com/zh/download graphviz配置:plantuml.com/zh/graphviz…
- 首先在机器上安装graphviz;
- 验证plantuml支持点图,java -jar plantuml.jar -testdot
- 集成点图的pom,然后输出图片。
Java引入依赖:
<dependency>
<groupId>net.sourceforge.plantuml</groupId>
<artifactId>plantuml</artifactId>
<version>1.2022.13</version>
</dependency>
复制代码使用Java生成对应的点图:
public class Demo {
public static void main(String[] args) throws IOException {
FileFormat gif = FileFormat.valueOf("SVG");
StringBuffer sb = new StringBuffer();
// 注意 digraph g {的后面不要有空格
sb.append("@startuml\n"
+ "digraph g {\n"
+ "node[shape=plaintext,style=filled];graph[splines=ortho];\n"
+ "exp_2085857771[label=<5*5+10+5*5>];\n"
+ "exp_248609774[label=<5*5+10>];\n"
+ "exp_708049632[label=<5*5>];\n"
+ "exp_1887400018[label=<5>];\n"
+ "exp_285377351[label=<5>];\n"
+ "exp_344560770[label=<10>];\n"
+ "exp_559450121[label=<5*5>];\n"
+ "exp_716083600[label=<5>];\n"
+ "exp_791885625[label=<5>];\n"
+ "\n"
+ " exp_2085857771 -> exp_248609774\n"
+ " exp_2085857771 -> exp_559450121\n"
+ " exp_248609774 -> exp_708049632\n"
+ " exp_248609774 -> exp_344560770\n"
+ " exp_708049632 -> exp_1887400018\n"
+ " exp_708049632 -> exp_285377351\n"
+ " exp_559450121 -> exp_716083600\n"
+ " exp_559450121 -> exp_791885625\n"
+ "}\n"
+ "@enduml");
String str = sb.toString();
System.out.println(str);
SourceStringReader dot = new SourceStringReader(str);
FileOutputStream os = new FileOutputStream(new File("result.svg"));
dot.outputImage(os, new FileFormatOption(gif));
os.flush();
}
}
复制代码
8. 添加错误监听器
// 可以在识别到错误的时候,抛出异常终止进行
parser.addErrorListener( new BaseErrorListener());
复制代码自定义语法
如果说想要自定义一些语言类应用,可以参考antlr4的lab网站,内置了当前主流的语言语法结构。
lab.antlr.org/
比如URL语法,以及JSON,CSV,DOT、SQL等语言的解析器;


总结
1、Antlr4是一种语法分析器的 生成器,帮我们屏蔽了词法分析和语法分析的过程,直接生成出对应的语法分析树。 基于语法分析树,我们可以构建自己的语言类应用;
2、Idea工具可以直接安装Antlr4的插件,可以帮我们检验自定义的语法特性,并且可以生成对应的Java基础类。
3、通过生成的Java基础类,配合Antlr4的API,可以快速完成一个语言类的应用。
参考: