参考资料
- https://blog.csdn.net/TZ845195485/article/details/119745735
Redis单线程和多线程问题的背景
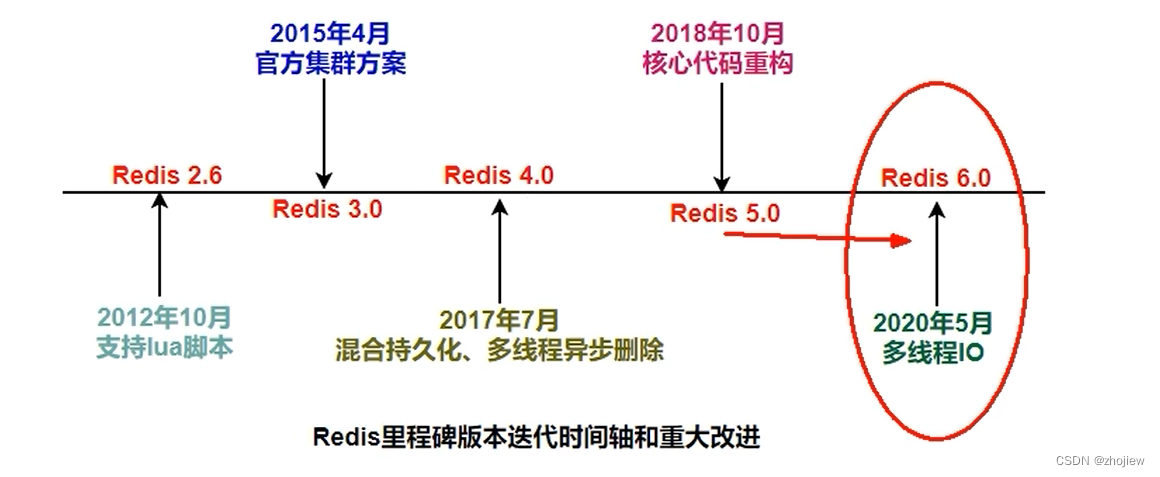
Redis里程碑版本迭代
Redis的单线程
-
主要是指Redis的网络IO和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取(socket读)、解析、执行、内容返回(socket写)等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。这也是Redis对外提供键值存储服务的主要流程。
-
但Redis的其他功能,比如持久化RDB、AOF、异步删除、集群数据同步等等,其实是由额外的线程执行的。
-
Redis命令工作线程是单线程的,但是整个Redis来说是多线程的
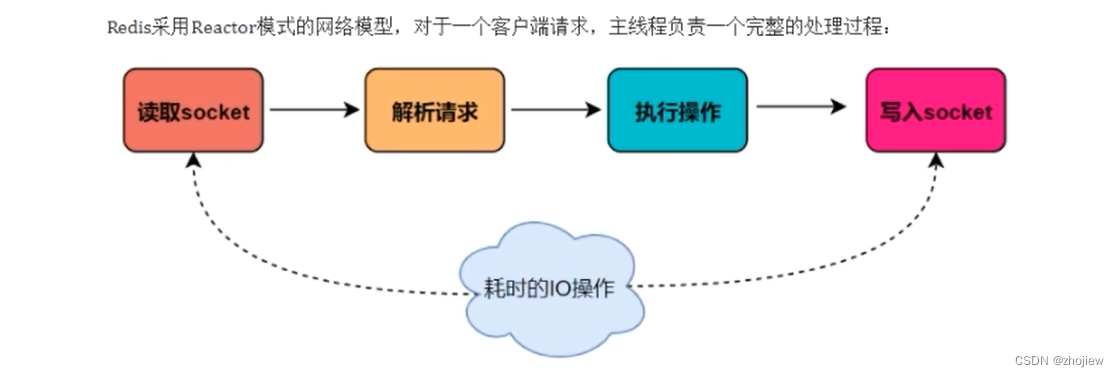
Redis为什么选择单线程?
- 基于内存操作:Redis的所有数据都存在内存中,因此所有的运算都是内存级别的,性能比较高;
- 数据结构简单:Rdis的数据结构是专门设计的,而这些简单的数据结构的查找和操作的时间大部分复杂度都是O(1),因此性能比较高
- 多路复用和非阻塞I/O:Redis使用I/O多路复用功能来监听多个socket连接客户端,这样就可以使用一个线程连接来处理多个请求,减少线程切换带来的开销,避免了IO阻塞操作
- 避免上下文功换:因为是单线程模型,因此就避免了不必要的上下文切换和多线程竞争,这就省去了多线程切换带来的时间和性能上的消耗
Redis为什么开始利用多核?
https://redis.io/docs/getting-started/faq/#how-can-redis-use-multiple-cpus-or-cores
It’s not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound.
As of version 4.0, Redis has started implementing threaded actions. For now this is limited to deleting objects in the background and blocking commands implemented via Redis modules. For subsequent releases, the plan is to make Redis more and more threaded.
使用多核的必要性
-
Redis4.0引入异步删除,在删除大key时,单线程会出现阻塞(类似synchronized锁)
unlink key flushdb async flushall async -
利用惰性删除避免阻塞。因为Redis是单个主线程处理,而
lazy free的本质就是把某些cost(主要时间复制度,占用主线程cpu时间片)较高删除操作,从redis主线程剥离让bio子线程来处理,极大地减少主线阻塞时间。从而减少删除导致性能和稳定性问题。
Redis当前的性能瓶颈
-
redis主要的性能瓶颈是内存或者网络IO,而不太可能是cpu
-
虽然有些命令操作可以用后台线程或子进程执行(比如数据删除、快照生成、AOF重写)。但是从网络IO处理到实际的读写命令处理,都是由单个线程完成的。
-
单个主线程处理网络请求的速度跟不上底层网络硬件的速度,为了应对这个问题采用多个IO线程来处理网络请求,提高网络请求处理的并行度,Rdis6/7就是采用的这种方法。
但是,Redis的多IO线程只是用来处理网络请求的,对于读写操作命令Redis仍然使用单线程来处理。这是因为Redis处理请求时,网络处理经常是瓶颈,通过多个IO线程并行处理网络操作,可以提升实例的整体处理性能。而继续使用单线程执行命令操作,就不用为了保证Lua脚本、事务的原子性,额外开发多线程互斥加锁机制,这样一来Redis线程模型实现就简单了
Redis的主线程如何和IO线程协同
既然瓶颈是网络IO,Redis的主线程如何和IO线程协同?
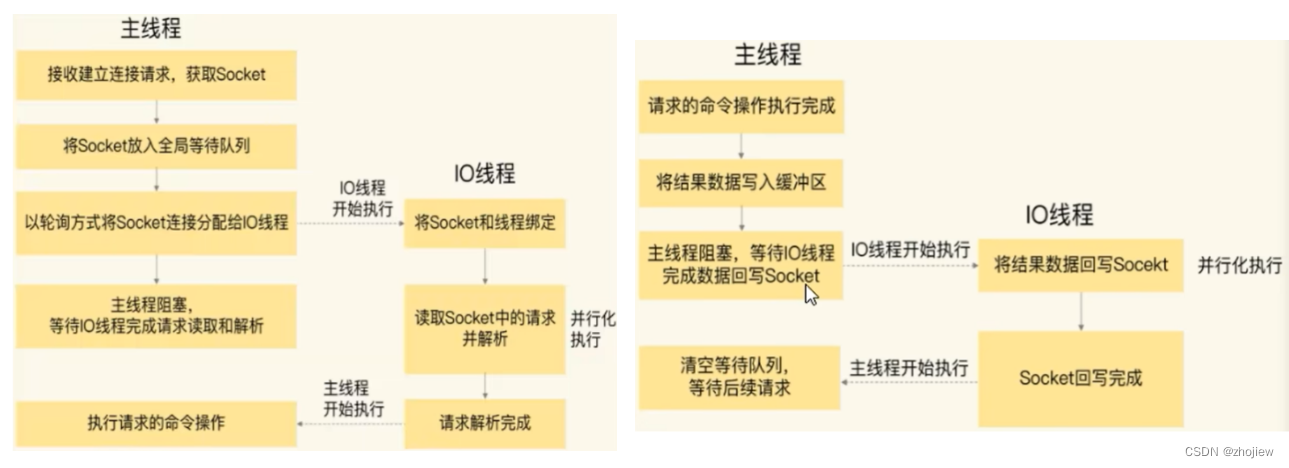
- 服务端和客户端建立Socket连接,并分配处理线程。首先,主线程负责接收建立连接请求。当有客户端请求和实例建立Socket连接时,主线程会创健和客户的连接,并把Socket放入全局等待队列中。紧接看主线程通过轮询方法把Socket连接分配给IO线程
- IO线程读取并解折请求。主线程一旦把Socket分配给IO线程,就会进入阻塞状态,等待IO线程完成客户端请求读取和解析。因为有多个IO线程在并行处理,所似这个过程很快完成
- 主线程执行请求操作。等IO线程解析完请求,主线程以单线程的方式执行这些命令操作。
- IO线程回写Socket和主当主线程清空全局队列。主线程执行完请求操作后,会把需要返回的结果写入缓冲区,然后主线程会阻塞等待IO线程,把这些结果回写到Socket中(多个线程在并发执行),并返回给客户端。等到lO线程回写Socket完毕,主线程会清空全局队列,等待客户端的后续请求。
IO多路复用的理解
linux的5种IO模型的理解
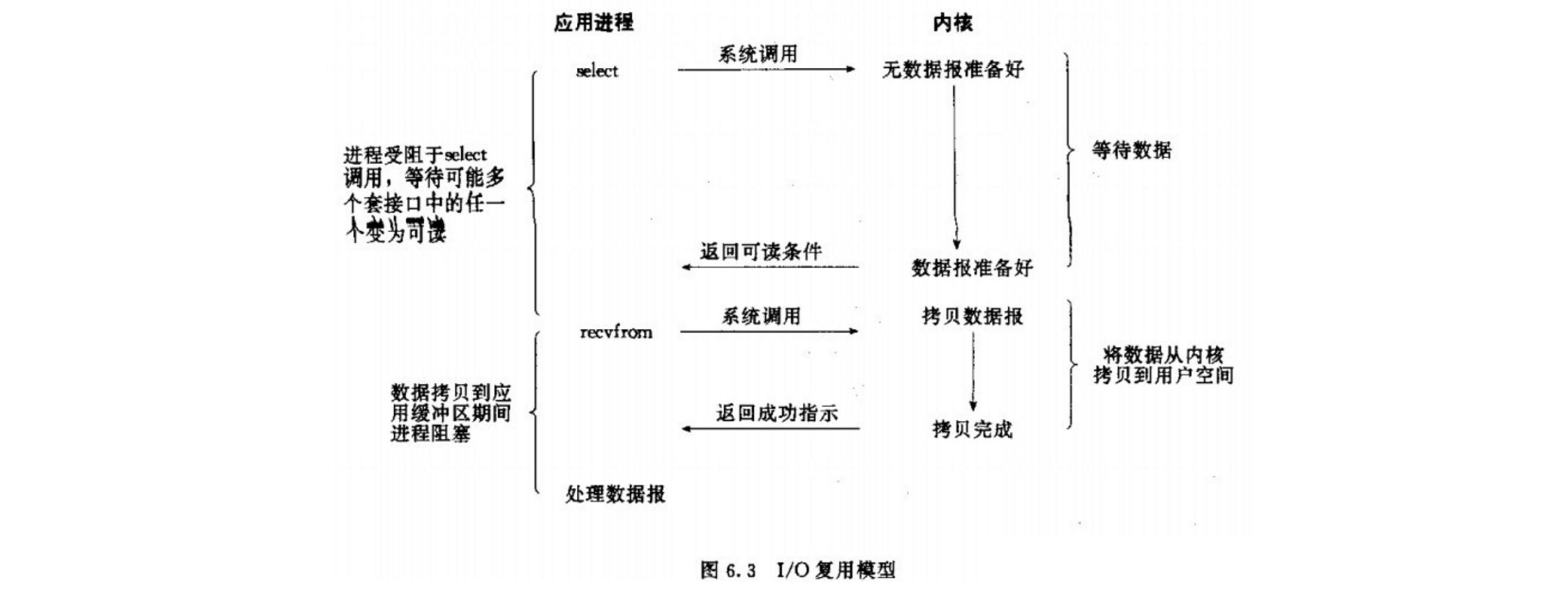
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
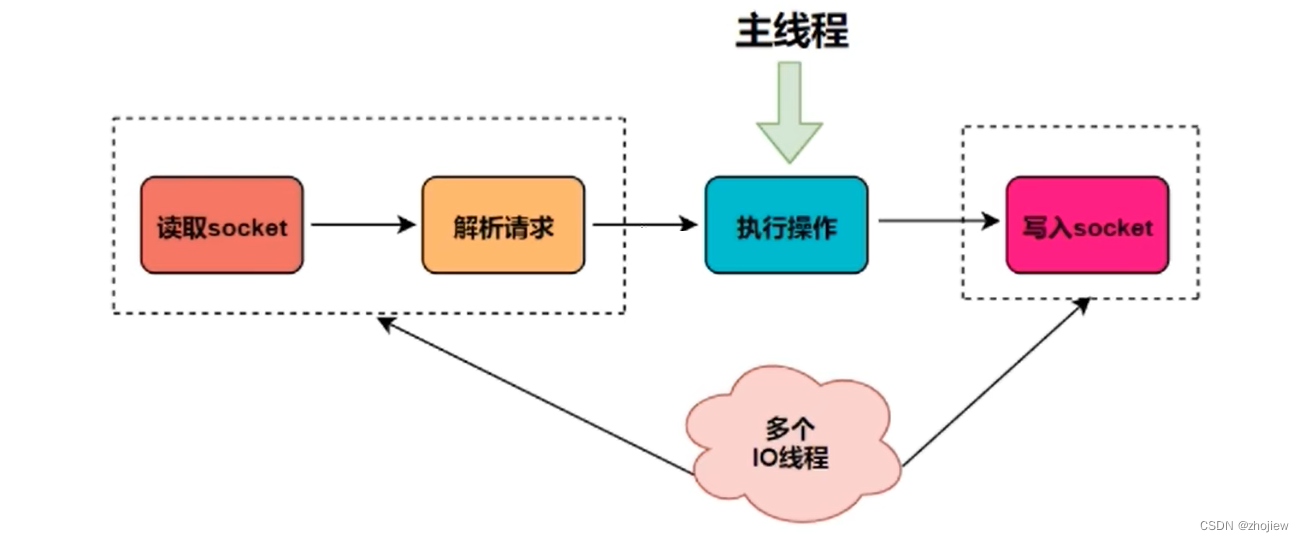
IO多路复用的解释,即使用一个或一组线程处理多个tcp连接
- IO,指代网络IO,需要进行模态转换的读写操作
- 多路,多个客户端连接(socket)
- 复用,复用一个或多个线程、
一个服务端进程可以同时处理多个socket,IO多路复用模型包括select,poll,epoll
在单个线程通过记录跟踪每一个Sockek(I/O流)的状态来同时管理多个I/O流。一个服务端进程可以同时处理多个套接字描述符。目的是尽量多的提高服务器的吞吐能力。
将用户socket对应的文件描述符(FileDescriptor)注册进epoll,然后epoll监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻塞模式。这样整个过程只在调用select.、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor模式。
因此IO多路复用+epoll也是Redis速度快的根本保证。redis的多线程即
- 单个工作线程保证线程安全和高性能
- 多个IO线程解决网络IO的问题
在redis6/7中,IO多路复用默认是关闭的,有2个相关的配置
################################ THREADED I/O #################################
# Redis is mostly single threaded, however there are certain threaded
# operations such as UNLINK, slow I/O accesses and other things that are
# performed on side threads.
#
# Now it is also possible to handle Redis clients socket reads and writes
# in different I/O threads. Since especially writing is so slow, normally
# Redis users use pipelining in order to speed up the Redis performances per
# core, and spawn multiple instances in order to scale more. Using I/O
# threads it is possible to easily speedup two times Redis without resorting
# to pipelining nor sharding of the instance.
#
# By default threading is disabled, we suggest enabling it only in machines
# that have at least 4 or more cores, leaving at least one spare core.
# Using more than 8 threads is unlikely to help much. We also recommend using
# threaded I/O only if you actually have performance problems, with Redis
# instances being able to use a quite big percentage of CPU time, otherwise
# there is no point in using this feature.
#
# So for instance if you have a four cores boxes, try to use 2 or 3 I/O
# threads, if you have a 8 cores, try to use 6 threads. In order to
# enable I/O threads use the following configuration directive:
#
# io-threads 4
#
# Setting io-threads to 1 will just use the main thread as usual.
# When I/O threads are enabled, we only use threads for writes, that is
# to thread the write(2) syscall and transfer the client buffers to the
# socket. However it is also possible to enable threading of reads and
# protocol parsing using the following configuration directive, by setting
# it to yes:
#
# io-threads-do-reads no
#
# Usually threading reads doesn't help much.
#
# NOTE 1: This configuration directive cannot be changed at runtime via
# CONFIG SET. Also, this feature currently does not work when SSL is
# enabled.
#
# NOTE 2: If you want to test the Redis speedup using redis-benchmark, make
# sure you also run the benchmark itself in threaded mode, using the
# --threads option to match the number of Redis threads, otherwise you'll not
# be able to notice the improvements.
线程数不要超过机器的核心数
深入理解Redis的IO多路复用
Redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
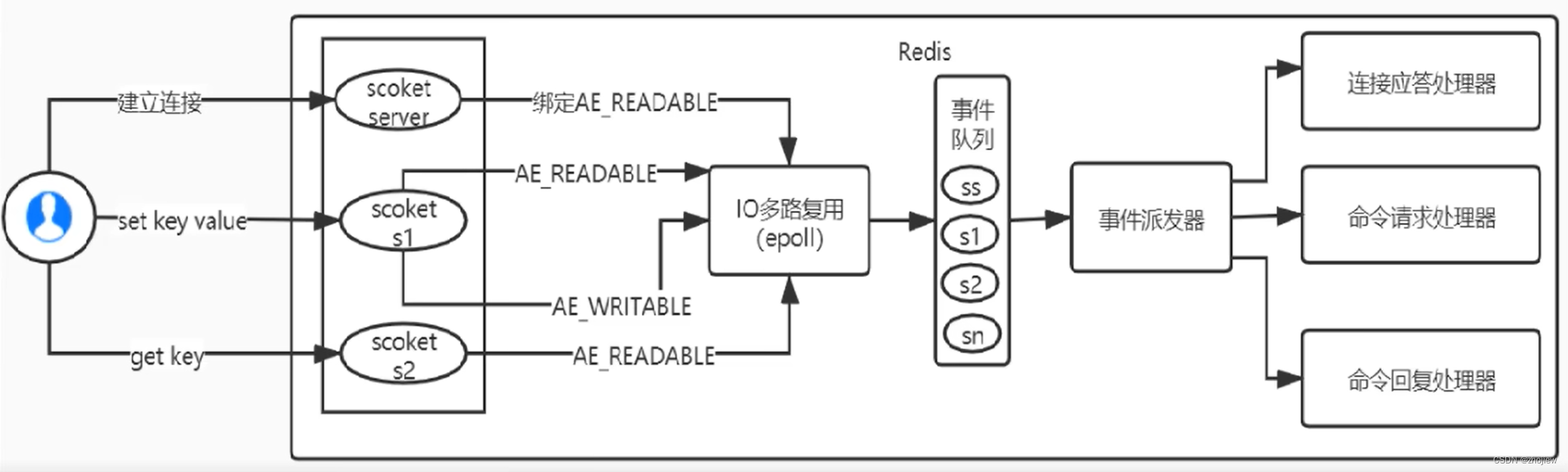
Rdis是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以I/O操作在一般情况下往往不能直接返回,这会导致某一文件的I/O阻塞导致整个进程无法对其它客户提供服务,而I/O多路复用就是为了解决这个问题而出现
所谓I/O多路复用机制,就是说通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作。这种机制的使用需要select、pol川、epol来配合。多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
Redis服务采用Reactor的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。它的组成结构为4部分:
- 多个套接字
- IO多路复用程序
- 文件事件分派器
- 事件处理器。
因为文件事件分派器队列的消费是单线程的,所汉Reds才叫单线程模型
解释为什么从bio,nio到io多路复用
在bio场景下,当client1请求并和server建立连接后,server在accept和read处发生阻塞,此时新的client2建立连接的请求无法被server处理(处于阻塞中)
注意:这里的应用程序指代的是server端
如何解决服务器主线程阻塞的问题?
考虑使用子线程来处理新的客户端连接和请求。在连接socket后创建线程来处理read操作
client代码
Socket socket = new Scoket("127.0.0.1",6379);
OutputStream outputStream == socket.getOUtputStream();
// 获取标准输入到msg
outputStream.write(msg.getBytes());
server代码
ServerSocket serverSocket = new ServerSocket(6379);
while(true){
Socket socket = serverSocket.accept(); // 阻塞等待连接
new Thread(() -> {
try{
InputStream inputStream = socket.getInputStream();
// 从input中获取输入,阻塞在读请求
socket.close();
}
},Thread.currentThread().getName()).start();
}
如何解决多线程资源浪费的问题
多线程模型要求每到来一个请求,就切换到内核态创建对应的的进程。新的进程和上下文切换都会产生性能的损耗
- 池化技术,但是实际的线程数量未知
- NIO,使read方法不阻塞
NIO的特点是使用轮询替代阻塞
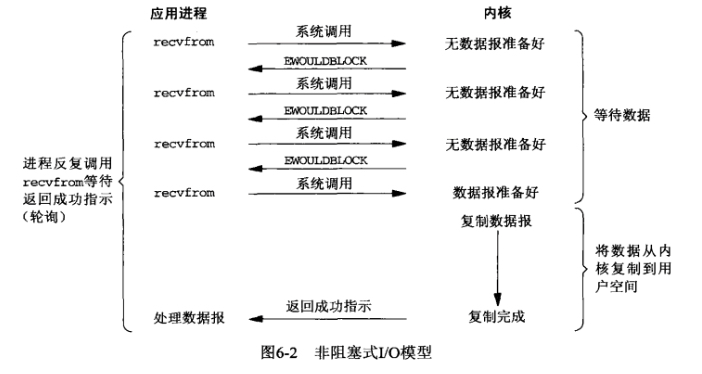
在客户端,如果kernal中的数据没有准备好,则会返回error
在NIO中一切都是非阻塞的
- accept方法非阻塞,如果没有客户端连接则返回无连接标识
- read方法非阻塞,如果read读不到数据返回空间中标识,有数据则只阻塞read读取数据的时间
- nio中服务端只有一个线程,对socker数组进行遍历
客户端代码和bio下相同
Socket socket = new Scoket("127.0.0.1",6379);
OutputStream outputStream == socket.getOUtputStream();
// 获取标准输入到msg
outputStream.write(msg.getBytes());
服务端代码
- 通过ServerSocketChannel的configureBlocking(false)方法将获得连接设置为非阻塞的。此时若没有连接,accept会返回null
- 通过SocketChannel的configureBlocking(false)方法将从通道中读取数据设置为非阻塞的。若此时通道中没有数据可读,read会返回-1
static ArrayList<SocketChannel> socketList = new ArrayList<>(); // 容纳socket数组
static ByteBuffer byteBuffer = ByteBuffer.allocate(1024); // 输入缓冲
ServerSocketChannel serverSocket = new ServerSocketChannel.open();
serverSocket.bind(new InetSocketAddress(127.0.0.1,6379));
serverSocket.configureBlocking(false); // jdk1.4开始兼容阻塞模式,此处设置为非阻塞
while(true){
for (SocketChannel element : socketList){
int read = element.read(byteBuffer); //不会阻塞
if(read > 0){
byteBuffer.flip();
byte[] bytes = new byte[read];
byteBuffer.get(byte);
byteBuffer.clear();
}
}
SocketChannel socketChannel = serverSocket.accpet(); // 不会阻塞
if(socketChannel != null){
sockerChannel.configureBlocking(false);
socketList.add(socketChannel) // 连接成功
}
}
NIO模型存在的问题
- socketlist遍历存在性能瓶颈(空socket仍旧会轮询),cpu不友好
- 对socket状态的判断仍旧需要切换模态(查询socket仍旧是通过read syscall),开销较大、
- 轮询会不断询问内核,占用了大量cpu时间,系统资源利用率较低
如何解决NIO模型cpu不友好的问题?
如果通过linux内核完成上述工作(遍历socket),不需要模态切换,内核本身是非阻塞的。
多路复用就是使用一个信道传输多个信号,多个网络连接使用一个线程,多个socket使用一个通道是在内核和驱动层实现的
IO多路复用模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aRXsM3LX-1687616915979)(null)]
基于I/O复用模型:多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
Reactor模式,是指通过一个或多个输入同时传递给服务处理器的服务请求的事件驱动处理模式。服务端程序处理传入多路请求,并将它们同步分派给请求对应的处理线程,Reactor模式也叫Dispatcher模式。即I/O多了复用统一监听事件,收到事件后分发(Dispatch给某进程),是编写高性能网络服务器的必备技术。Reactor模式中有2个关键组成:
- Reactor,Reactor在一个单独的线程中运行,负贵监听和分发事件,分发给适当的处理程序来对IO事件做出反应。它就像公司的电话接线员,它接听来自客户的电话并将线路转移到适当的联系人
- Handlers,处理程序执行I/O事件要完成的实际事件,类似于客户想要与之交谈的公司中的实际办理人。Reactor通过调度适当的处理程序来响应I/O事件,处理程序执行非阻塞操作
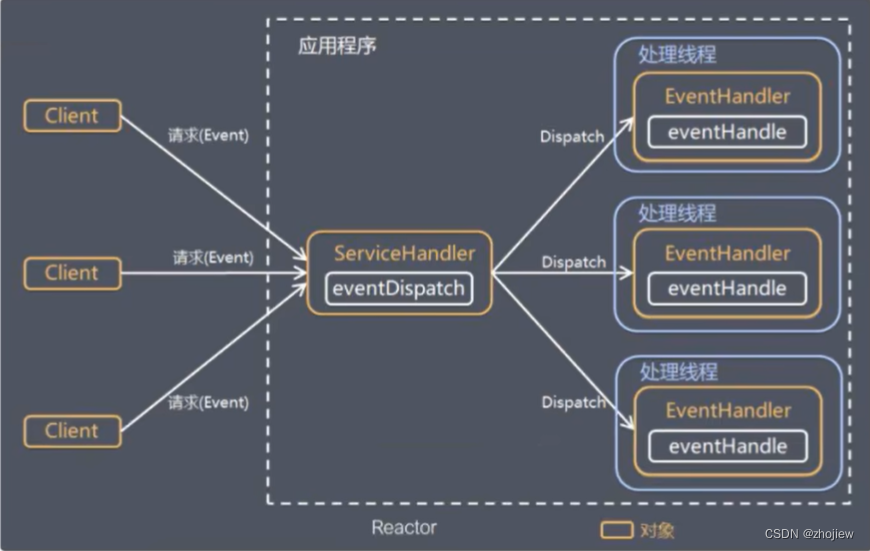
IO多路复用的具体实现
select方法

select函数监视的文件描述符分3类,分别是readfds、writefds和exceptfds,将用户传入的数组拷贝到内核空间
-
调用后select函数会阻塞,直到有描述符就绪(有数据可读、可写、或者有except)或超时(timeout指定等待时间,如果立即返回设为null即可),函数返回
-
当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
分析select函数的执行流程:
- select是一个阻塞函数,当没有数据时,会一直阻塞在select调用
- 当有数据时会将rset中对应的位置为1
- selecti函数返回,不再阻塞
- 遍历文件描述符数组,判断哪个fd被置位
- 读取数据,然后处理
下面的示例代码
-
实际是将之前java示例的代码从用户态搬到内核态运行
-
将
fd拷贝到内核态,避免模态切换
sockfd = socket(AF_INET,SOCK_STREAM,0);
memse(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(2000);
addr.sin_addr.s_addr = INADDR_ANY;
bind(sockfd,(struct sockaddr*)&addr, sizeof(addr));
listen (sockfd, 5);
for(i=0;i<5;i+){
// 模拟5个客户端连接
memset(&client,0,sizeof (client));
addrlen = sizeof(client);
fds[i] = accept(sockfd, (struct sockaddr*)&client, &addrlen);
if(fds[i]>max)
max = fds[i]; //找到一个最大的文件描述符,在下面select中限制范围
}
while(1){
FD_ZERO(&rset); // 重置rset为0
for(i=0;i<5;i++){
FD_SET(fds[i],&rset); // &rset是个bitmap.如果5个文件描述符分别是1,2,4,5,7,那么这个bitmap为01101101
}
puts("round again");
select(max+1,&rset,NULL,NULL,NULL); // select是一个系统调用,它会堵塞直到有数据发送到socket,select会把&rset相应的位置置位,但并不会返回哪个socket有数据
for(i=0;i<5;i++){
// 用户态只要遍历&rst,看哪一位被置位了,不需要每次调用系统调用来判断了,效率有很大提升,遍历到被置位的文件描述符就进行读取
if (FD_ISSET(fds[i],&rset)){
memset(buffer, 0, MAXBUF);
read(fds[i], buffer, MAXBUF);
puts(buffer);
}
}
select函数的缺点
- bitmap默认大小为1024(代码实现较早1983年),虽然可以调整但还是有限度的
- rset每次循环都必须重新置位为0,不可重复使用
- 尽管将rset从用户态拷贝到内核态由内核态判断是否有数据,但是还是有拷贝的开销
- 当有数据时select就会返回,但是selecti函数并不知道哪个文件描述符有数据了(仅仅置位)。后面还需要再次对文件描述符数组进行遍历,效率比较低
poll方法
函数原型
int poll(struct pollfd *fds,nfds_t nfds,int timeout);
struct pollfd
int fd; //file descriptor
short events; // 读或者写事件
short revents; // 文件描述符有事件则置1
};
poll的执行流程:
- 将五个fd从用户态拷贝到内核态
- poll为阻塞方法,执行poll方法,如果有数据会将fd对应的revents置为POLLIN
- poll方法返回
- 循环遍历,查找哪个fd被置位为POLLIN了
- 将revents重置为0便于复用
- 对置位的fd进行读取和处理
解决的问题
- 不在使用bitmap,消除了client的大小限制(1024)
- rset不可复用的问题(每次置0)
代码实现
for(1=0;1<5;1++) //模拟5个客户端连接
{
memset(&client,0,sizeof (client));
addrlen = sizeof(client);
pollfds[i].fd = accept(sockfd,(struct sockaddr)&client,&addr);
pollfds[i].events = POLLIN; //这5个socket只读事件
}c
sleep(1);
while(1){
puts("round again");
poll(po11fds,5,50000); // poll中传入pollfds数组,交给内核判断是否有事件发生,如果哪个发生事件则revents置1
for(1=0; 1<5; 1++){ //遍历数组,找到哪个pollfd有事件发生
if (pollfds[i].revents & POLLIN){
pollfds[i].revents=O; // 找到后revents置0
memset(buffer,0,MAXBUF);
read(pollfds[i].fd,buffer,MAXBUF); //读取数据
puts(buffer);
}
}
缺点
- 本质上还是select方法
- 拷贝fd到内核态仍旧存在开销
- 仍旧需要遍历socket(O(n)复杂度)
epoll方法
函数原型
// 创建一个epoll的句柄,size表示内核监听的数目。并非最大限制,而是内核初始分配数据结构的建议值
int epoll_create(int size);
// 向内核添加,修改或删除要监控的fd
int epoll_ctl(
int epfd, // epfd是epoll_create的返回值
1nt op, // 表示op操作,用三个宏来表示:添加EPOLL.CTL_ADD,除EPOLL.CTL_DEL,修改EPOLL.CTL_MOD
int fd, //fd:是需要监听的fd(文件描述符)
struct epoll_event *event // 告诉内核要监听什么事
);
struct epoll_event
// events可以是以下几个宏的熊合:
// EPOLLIN:表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
// EPOLLOUT:表示对应的文件描述符可以写;
__uint32_t events;
epoll_data_t data; // User data variable
}
// 类似select调用
int epoll_wait(int epfd,
struct epoll event *events,
int maxevents, // 最多返回的事件数
int timeout
);
具体实现
- socket生命周期只会从用户态到内核态拷贝一次
- 使用event通知级值,每次socket有数据会主动通知内核加入就绪列表,不需要遍历所有socket
struct epoll_event events[5];
int epfd epoll_create(10); // epoll_create在内核开辟一块内存空间,用来存放epolle中fd的数据结构
for(i=0;i<5;i+) { //模拟S个客户端连接
static struct epoll_event ev; // epoll中fd的数据结构和polI中的差不多,只是没有了revents
memset(&client,0,sizeof (client));
addrlen sizeof(client);
ev.data.fd = accept(sockfd,(struct sockaddr&client,&addrlen);
ev.events = EPOLLIN;
epoll_ctl(epfd,EPOLL_CTL_ADD,ev.data.fd,&ev); // epoll ctl把每-个socket的fd数据结构放到epoll_create创建的内存空间中
}
while(1){
puts("round again");
nfds = epoll_wait(epfd,events,5,1O0O0); // epoll_wait阻塞,只有当epoll_create中创建的内存空间中的fd有事件发生,才会把这些fd放入就绪链表中,返回就绪fd的个数
for(i=0;i<nfds;i++){ //遍历就绪链表,读取数据
memset(buffer,0,MAXBUF);
read(events[i].data.fd, buffer, MAXBUF);
puts(buffer);
}
}
三个方法的对比
- 不同操作系统选择的方式不同,windows没有epoll默认为select
| select | poll | epoll | |
|---|---|---|---|
| 操作方式 | 遍历 | 遍历 | 回调 |
| 数据结构 | bitmap | 数组 | 红黑树 |
| 最大连接数 | 1024或2048(x64) | 无限 | 无限 |
| 最大支持fd数 | 无限 | 65535 | 65535 |
| fd跨态拷贝 | 每次select调用都需要拷贝 | 每次poll调用都需要拷贝 | 首次调用epoll_ctl拷贝 |
| 工作效率 | 线性遍历,O(n) | 线性遍历,O(n) | 事件通知,O(1) |
elasticache7的增强IO
Amazon ElastiCache for Redis 7 新增功能:通过增强型 I/O 多路复用将吞吐量提升高达 72%
使用 ElastiCache for Redis 7 时,将会免费自动提供增强型 I/O 多路复用功能

采用增强型 I/O 后,引擎将专注于处理命令的运行,而非处理网络连接。不再为每个客户端打开一个通道,而是如下图所示,由每个增强型 I/O 线程使用 ElastiCache for Redis 引擎将命令组合在单个通道中