分库分表解决的问题
mysql的扩展
-
mysql并不能完全利用高性能服务器的硬件,当cpu超过24个,内存超过128G时,mysql性能处于平缓,不在上升,所以在一个性能强大的服务器上运行多个实例,才更合理
-
mysql常见的扩展方式有:垂直扩展,水平扩展和向内扩展
-
垂直扩展,也就是使用更好的机器
- 单台服务器比多台服务器更容易维护和开发,扩展也更加简单
- 但是入如果应用变得非常庞大,垂直扩展就会变得很困难
- 首先是成本问题,高配置的机器比较昂贵,而且硬件是有上限的,不可能无限扩展
- 另外如果使用了复制,主库升级配置后,一般不会配置一台和主库一样强大的从库,因为从库无法优先利用多核cpu和磁盘资源
-
水平扩展,也就是将任务分配到多台计算机,也就是分库分表
- 大概可以分为:复制、拆分和数据分片,最简单的方式就是通过复制把数据分发到多个服务器,读写分离,从库只做读操作;或者按照功能和职责对应用进行拆分,不同的节点执行不同的任务
- 数据分片是将数据分割成多块,然后存储到不同的节点,如果是想扩展写容量,就必须进行分片,只有一台主库,无论有多少从库,写容量都是无法扩展的
- 当然如果不是必要,尽量不要分片,先看能否通过调优和其他数据库来推迟分片
- 分片应用会有一个数据库访问的抽象层,用以降低应用和分片数据之间通信的复杂度
- 分片的最大问题,就是查找和获取数据,而且维护数据的一致性会很难,并且分片无法使用外键,对于重要且查询频繁的数据要减少分片,
- 选择分区键的时候,尽可能选择那些能够避免跨分片查询的,保持分片足够小更容易管理,对数据的备份和恢复也更加容易,但是太小的分片也会导致产生很多的表,从而导致跨分片的查询增加
- 跨分片的查询,需要对多个发片都执行一遍sql,最后在汇总,这类查询开销很大,最好能进行缓存
- 如果可能,尽量让每个分片大小相同,这样可以在对分片进行分组的时候很容易平衡
-
向内扩展,也就是定期对数据进行清理和归档,对冷热数据进行分离
- 可以作为争取时间的短期策略,也可以作为处理大数据量的长期计划
- 归档时需要在不影响事务处理的情况下进行,关键是要高效的找到要删除的行
分库分表
- 也就是分片,有垂直和水平两种。
- 垂直拆分比较简单,也就是本来一个数据库,因为表多所以数据多,这时候适合使用垂直切分,也就是把关系紧密(比如同一模块)的表切分出来放在一个库上
- 如果表并不多,但每张表的数据非常多,这时候适合水平切分,把单表拆分为多个表
- 垂直拆分为:垂直分库和垂直分表
- 垂直分库:对象是整个表
- 按业务对表进行分类,比如每个微服务单独使用一个数据库,如果有跨服务的关联查询,就必须通过数据冗余或程序二次加工来解决
- 垂直分表:对象是列/字段
- 基于数据库中的"列"进行,某个表字段较多,可以新建一张扩展表,将不经常用或字段长度较大的字段拆分出去到扩展表中,通过"大表拆小表",更便于开发与维护,而且一条记录如果占用空间过大会导致跨页问题,带来额外的开销
- 优点:
- 解决业务系统层面的耦合,业务清晰
- 与微服务的治理类似,也能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈
- 缺点:
- 部分表无法join,只能通过接口聚合方式解决,提升了开发的复杂度
- 分布式事务处理复杂
- 依然存在单表数据量过大的问题(需要水平切分)
- 垂直分库:对象是整个表
- 水平切分:水平分表和水平分库
- 当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,就需要水平切分了
- 水平切分分为库内分表和分库分表,根据表内某个字段的某种规则来将数据分散存储于不同的数据库或不同的表,水平切分后同一张表会出现在多个数据库/表中,每个库/表的内容不同
- 水平切分的优点:
- 不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
- 应用端改造较小,不需要拆分业务模块
- 缺点:
- 跨分片的事务一致性难以保证
- 跨库的join关联查询性能较差
- 数据多次扩展难度和维护量极大
- 分库分表能有效的缓解单机和单库带来的性能瓶颈和压力,但同时也带来了一些问题,所以随着数据库数据量增加,不要马上考虑做水平切分,首先考虑缓存处理,读写分离,使用索引等等方式,如果这些方式不能根本解决问题了,再考虑做水平分库和水平分表
Sharding JDBC 和 mycat 对比:
-
mycat
- mycat是一个开源的中间件代理层,对研发无感知,支持事务、ACID
- 可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 优点:开发无感知,增删节点程序不需要重启,可以跨语言(java 、php)
- 缺点:性能下降,不支持跨数据库
- MyCat经典实用场景
- 单纯的读写分离,主从切换
- 分表分库,对于超过1000 万的表进行分片,最大支持1000 亿的单表分片
- 多租户应用,每个应用一个库,但应用程序只连接Mycat,从而不改造程序本身,实现多租户化
- 替代Hbase,分析大数据作为海量数据实时查询的一种简单有效方案
- mycat的使用对研发是无感知的,但是运维成本较大,涉及到一些概念
-
ShardingJdbc
-
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
-
适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
-
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
-
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库
-
优点:性能很好,支持跨数据库jdbc
-
缺点:增加了开发难度,不支持跨语言(java)
-
ShardingSphere-JDBC
分库分表操作本身比较困难,操作很繁琐,有时间还是推荐多看看官网,本文基于5.1.1版本
http://shardingsphere.apache.org/index_zh.html
配置ShardingSphere-JDBC 配置,不要引入com.alibaba.druid.pool.DruidDataSource连接池,会有冲突,使用默认的com.zaxxer.hikari.HikariDataSource即可
读写分离
引入依赖:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
<scope>runtime</scope>
</dependency>
<!-- mybatis plus 代码生成器 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
<optional>true</optional>
</dependency>
application.properties
#
spring.profiles.active=dev
# 启动方式
spring.shardingsphere.mode.type=Memory
# 配置真实数据源
spring.shardingsphere.datasource.names=db1,db2,slave1
# 主库1
spring.shardingsphere.datasource.db1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db1.jdbc-url=jdbc:mysql://192.168.158.134:3306/distributed_server?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=
# 主库2
spring.shardingsphere.datasource.db2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db2.jdbc-url=jdbc:mysql://192.168.158.165:3306/distributed_server?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db2.username=root
spring.shardingsphere.datasource.db2.password=
# 主库1 的 从库192.168.158.146
spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://192.168.158.146:3306/distributed_server?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=
# 读写分离类型,如: Static,Dynamic
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.type=Static
# 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.write-data-source-name=db1
# 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.read-data-source-names=slave1,db2
# 负载均衡算法名称,如下配置了三种负载均衡算法,这里选择的是权重
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.load-balancer-name=alg_weight
# 负载均衡算法配置
# 负载均衡算法类型
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_round.type=ROUND_ROBIN
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_random.type=RANDOM
# 权重算法和比重
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.type=WEIGHT
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave1=1
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.db2=2
# 是否打印SQl
spring.shardingsphere.props.sql-show=true
server:
servlet:
context-path: /api
port: 9030
mybatis-plus:
mapper-locations: classpath:/mapper/*Mapper.xml
type-aliases-package: com.xxx.mapper
执行写入操作,就会访问写库db1

执行查询就会轮询两个读库
Transactional 问题
为了保证主从库间的事务一致性,避免跨服务的分布式事务,ShardingSphere-JDBC的主从模型中,事务中的数据读写均用主库。
- 不添加@Transactional:insert对主库操作,select对从库操作
- 添加@Transactional:则insert和select均对主库操作
读库负载均衡算法
- ROUND_ROBIN 基于轮询的读库负载均衡算法
- RANDOM 基于随机的读库负载均衡算法
- WEIGHT 基于权重的读库负载均衡算法
水平分片
在两个水平库:192.168.158.134,192.168.158.165 上分别建表
CREATE TABLE `test_server_00` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',
`i_number` varchar(2048) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '金额',
`descd` varchar(2048) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '描述',
`deleted` varchar(1) DEFAULT '0' COMMENT '删除标记',
`ctime` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`crname` varchar(32) DEFAULT NULL COMMENT '创建人',
`mtime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`chname` varchar(32) DEFAULT NULL COMMENT '更新人',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=393 DEFAULT CHARSET=utf8 COMMENT='测试表server'
CREATE TABLE `test_server_01` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',
`i_number` varchar(2048) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '金额',
`descd` varchar(2048) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '描述',
`deleted` varchar(1) DEFAULT '0' COMMENT '删除标记',
`ctime` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`crname` varchar(32) DEFAULT NULL COMMENT '创建人',
`mtime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`chname` varchar(32) DEFAULT NULL COMMENT '更新人',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=393 DEFAULT CHARSET=utf8 COMMENT='测试表server'
CREATE TABLE `test_server_02` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',
`i_number` varchar(2048) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '金额',
`descd` varchar(2048) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '描述',
`deleted` varchar(1) DEFAULT '0' COMMENT '删除标记',
`ctime` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`crname` varchar(32) DEFAULT NULL COMMENT '创建人',
`mtime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`chname` varchar(32) DEFAULT NULL COMMENT '更新人',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=393 DEFAULT CHARSET=utf8 COMMENT='测试表server'
#
spring.profiles.active=dev
# 启动方式
spring.shardingsphere.mode.type=Memory
# 配置真实数据源
spring.shardingsphere.datasource.names=db1,db0,slave1
# 主库1
spring.shardingsphere.datasource.db1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db1.jdbc-url=jdbc:mysql://192.168.158.134:3306/distributed_server?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=
# 主库2
spring.shardingsphere.datasource.db0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db0.jdbc-url=jdbc:mysql://192.168.158.165:3306/distributed_server?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db0.username=root
spring.shardingsphere.datasource.db0.password=
# 主库1 的 从库192.168.158.146
spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://192.168.158.146:3306/distributed_server?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=
# 读写分离类型,如: Static,Dynamic
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.type=Static
# 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.write-data-source-name=db1
# 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.read-data-source-names=slave1,db0
# 负载均衡算法名称,如下配置了三种负载均衡算法,这里选择的是权重
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.load-balancer-name=alg_weight
# 负载均衡算法配置
# 负载均衡算法类型
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_round.type=ROUND_ROBIN
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_random.type=RANDOM
# 权重算法和比重
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.type=WEIGHT
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave1=1
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.db2=2
#========================标准分片表配置(数据节点配置)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
# <table-name>:逻辑表名
# db$->{0..1}.test_server_0$->{0..2}
# 也可以使用枚举 db$->{[0,1]}.test_server_0$->{[1,2]}
spring.shardingsphere.rules.sharding.tables.test_server.actual-data-nodes=db$->{0..1}.test_server_0$->{0..2}
# 是否打印SQl
spring.shardingsphere.props.sql-show=true
实体类
会把 逻辑表"test_server"的操作映射到 db1.test_server_00,db1.test_server_01,db1.test_server_02,db2.test_server_00,db2.test_server_01,db2.test_server_02 这几张表上
/**
* 测试表server实体类
*
* @author psh
* @since 2023-06-23 13:42:07
*/
@Data
@ApiModel(value = "TestServer对象", description = "测试表server实体对象")
//逻辑表名
@TableName("test_server")
public class TestServer {
/**
* 主键id
*/
private Long id;
/**
* 金额
*/
@ApiModelProperty(value = "金额", name = "iNumber")
private String iNumber;
/**
* 描述
*/
@ApiModelProperty(value = "描述", name = "descd")
private String descd;
/**
* 删除标记
*/
@ApiModelProperty(value = "删除标记", name = "deleted")
@TableLogic
@TableField(value = "DELETED", fill = FieldFill.INSERT, jdbcType = JdbcType.VARCHAR)
private String deleted;
}
插入方法,为了测试方便这里使用了redis来做分布式主键id,也可以使用uuid或者雪花算法
@Resource
private RedisTemplate redisTemplate;
@Override
@Transactional
//这里只是插入测试,为了方便知道数据的去除
public BaseResultModel insert(ReqTestServerAdd req) {
TestServer entity = new TestServer();
Long increment = redisTemplate.opsForValue().increment("test_server", 1);
req.setId(increment);
switch ((int) (increment % 2)) {
case 0:
entity.setINumber("数据库0");
break;
case 1:
entity.setINumber("数据库1");
break;
}
switch ((int) (increment % 3)) {
case 0:
entity.setDescd("表0");
break;
case 1:
entity.setDescd("表1");
break;
case 2:
entity.setDescd("表2");
break;
}
entity.setDeleted("0");
if (!this.save(entity)) {
throw new BaseException(ResultStatus.INSERT_FAIL.getCode(), ResultStatus.INSERT_FAIL.getMessage());
}
return BaseResultModel.success();
}}
此时因为没有配置分片算法,sharding不知道如何分片,执行sql,会抛异常
### SQL: INSERT INTO test_server ( id, i_number, descd, DELETED ) VALUES ( ?, ?, ?, ? )
### Cause: java.lang.IllegalStateException: Insert statement does not support sharding table routing to multiple data nodes.] with root cause
分片算法
水平分库
分片算法类型
| 配置标识 | 自动分片算法 | 详细说明 |
|---|---|---|
| MOD | Y | 基于取模的分片算法 |
| HASH_MOD | Y | 基于哈希取模的分片算法 |
| BOUNDARY_RANGE | Y | 基于分片边界的范围分片算法 |
| VOLUME_RANGE | Y | 基于分片容量的范围分片算法 |
| AUTO_INTERVAL | Y | 基于可变时间范围的分片算法 |
| INTERVAL | N | 基于固定时间范围的分片算法 |
| CLASS_BASED | N | 基于自定义类的分片算法 |
| INLINE | N | 基于行表达式的分片算法 |
| COMPLEX_INLINE | N | 基于行表达式的复合分片算法 |
| HINT_INLINE | N | 基于行表达式的 Hint 分片算法 |
| COSID_MOD | N | 基于 CosId 的取模分片算法 |
| COSID_INTERVAL | N | 基于 CosId 的固定时间范围的分片算法 |
| COSID_INTERVAL_SNOWFLAKE | N | 基于 CosId 的雪花ID固定时间范围的分片算法 |
分片规则:order表中id为偶数时,数据插入db1服务器,id为奇数时,数据插入db1服务器。
#这里先指定表名
spring.shardingsphere.rules.sharding.tables.test_server.actual-data-nodes=db$->{0..1}.test_server_00
#------------------------分库策略
# 分片列名称
spring.shardingsphere.rules.sharding.tables.test_server.database-strategy.standard.sharding-column=id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.test_server.database-strategy.standard.sharding-algorithm-name=my_alg_inline_id
#------------------------分片算法配置,这里指定的是数据库
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.my_alg_inline_id.type=INLINE
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.my_alg_inline_id.props.algorithm-expression=db$->{id % 2}
# 取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.my_mod.type=MOD
# 分片算法属性配置 ,这里就是对2取模,和上面的行表达式算法,都是根据配置的 分片列id 进行取模,得到的结果是一致的
spring.shardingsphere.rules.sharding.sharding-algorithms.my_mod.props.sharding-count=2
再次测试插入方法,分别插入两个不同的数据库的test_server_00表中
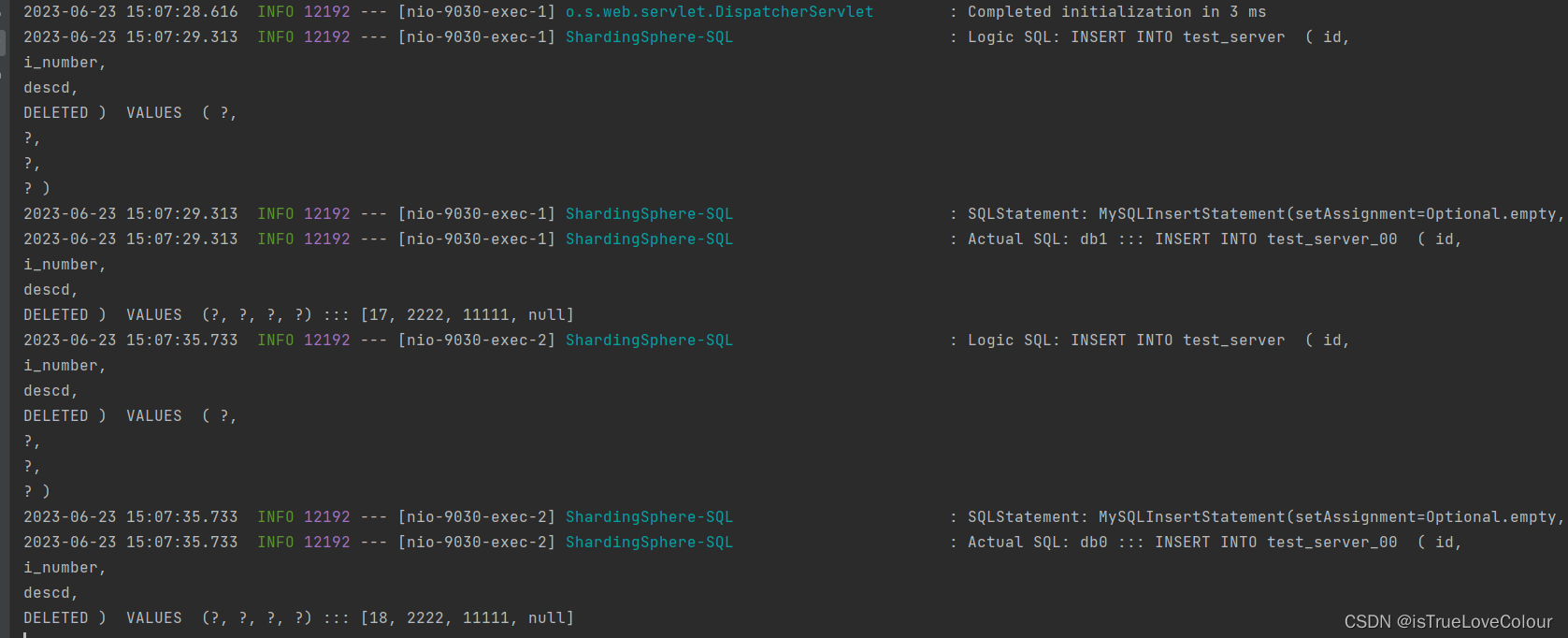
水平分表
#这里先指定表名
spring.shardingsphere.rules.sharding.tables.test_server.actual-data-nodes=db$->{0..1}.test_server_0$->{0..2}
#------------------------分库策略
# 分片列名称
spring.shardingsphere.rules.sharding.tables.test_server.database-strategy.standard.sharding-column=id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.test_server.database-strategy.standard.sharding-algorithm-name=my_alg_inline_id
#------------------------分片算法配置,这里指定的是数据库
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.my_alg_inline_id.type=INLINE
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.my_alg_inline_id.props.algorithm-expression=db$->{id % 2}
# 取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.my_mod.type=MOD
# 分片算法属性配置 ,这里就是对2取模,和上面的行表达式算法,都是根据配置的 分片列id 进行取模,得到的结果是一致的
spring.shardingsphere.rules.sharding.sharding-algorithms.my_mod.props.sharding-count=2
#------------------------分表策略,这里指定表
# 分片列名称
spring.shardingsphere.rules.sharding.tables.test_server.table-strategy.standard.sharding-column=id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.test_server.table-strategy.standard.sharding-algorithm-name=my_mod_tb
# 取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.my_mod_tb.type=MOD
# 分片算法属性配置 ,这里就是 id 对3取模
spring.shardingsphere.rules.sharding.sharding-algorithms.my_mod_tb.props.sharding-count=3
# hash分片算法 my_hash_mod
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.my_hash_mod.type=HASH_MOD
# 分片算法属性配置 ,这里就是 id计算为hash值后 对3取模
spring.shardingsphere.rules.sharding.sharding-algorithms.my_hash_mod.props.sharding-count=3
分库和分表的列可以不同,这里只是为了简便,此外取模需要列是数值类型,如果是字符串可以使用hash算法
执行6次插入操作,数据均匀的插入到对应的6张表中,查询全部结果为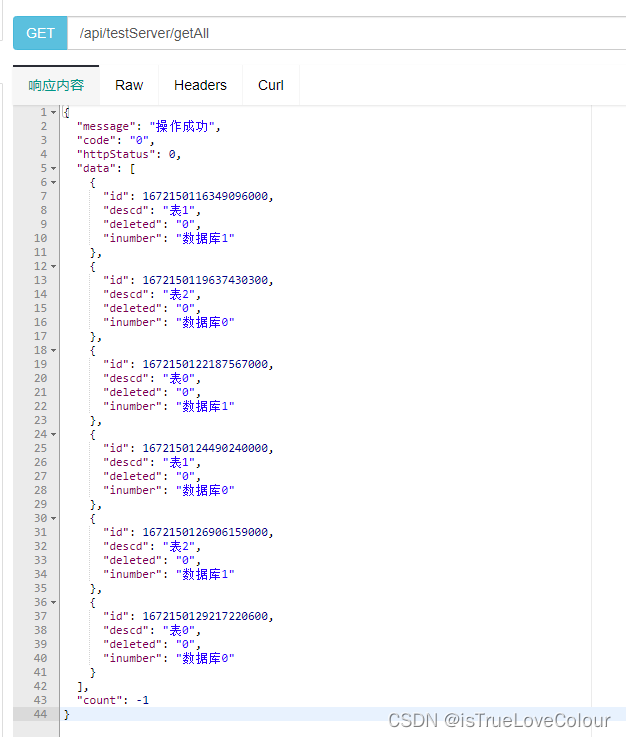
逻辑sql语句为:
SELECT id,i_number,descd,DELETED FROM test_server WHERE DELETED='0'
实际的语句是,将多个的分片表全部 UNION
Actual SQL: db0 :::
SELECT id,i_number,descd,DELETED FROM test_server_00
WHERE DELETED='0'
AND (deleted = ?) UNION ALL SELECT id,i_number,descd,DELETED FROM test_server_01
WHERE DELETED='0'
AND (deleted = ?) UNION ALL SELECT id,i_number,descd,DELETED FROM test_server_02
WHERE DELETED='0'
AND (deleted = ?) ::: [0, 0, 0]
Actual SQL: db1 :::
SELECT id,i_number,descd,DELETED FROM test_server_00
WHERE DELETED='0'
AND (deleted = ?) UNION ALL SELECT id,i_number,descd,DELETED FROM test_server_01
WHERE DELETED='0'
AND (deleted = ?) UNION ALL SELECT id,i_number,descd,DELETED FROM test_server_02
WHERE DELETED='0'
AND (deleted = ?) ::: [0, 0, 0]
如果按照id查询,也就是分片的键,能够精确定位数据所在的分片,避免很多不必要的查询,所以分片的键要谨慎选择
select * from test_server where deleted = 0 and id = ?
-- 执行的sql语句为:
db0 ::: select * from test_server_00 where deleted = 0 and id = ? ::: [48]
分片主键
Apache ShardingSphere 提供了内置的分布式主键生成器
- UUID 是无须的,使用innodb存储引擎会增加插入的时间,一般不建议使用
- SNOWFLAKE
- Twitter 公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。
分布式主键生成算法
-
SNOWFLAKE 基于雪花算法的分布式主键生成算法
org.apache.shardingsphere.sharding.algorithm.keygen.SnowflakeKeyGenerateAlgorithm -
UUID 基于 UUID 的分布式主键生成算法
org.apache.shardingsphere.sharding.algorithm.keygen.UUIDKeyGenerateAlgorithm -
NANOID 基于 NanoId 的分布式主键生成算法
org.apache.shardingsphere.sharding.nanoid.algorithm.keygen.NanoIdKeyGenerateAlgorithm -
COSID 基于 CosId 的分布式主键生成算法
org.apache.shardingsphere.sharding.cosid.algorithm.keygen.CosIdKeyGenerateAlgorithm -
COSID_SNOWFLAKE 基于 CosId 的雪花算法分布式主键生成算法
org.apache.shardingsphere.sharding.cosid.algorithm.keygen.CosIdSnowflakeKeyGenerateAlgo
#------------------------分布式序列策略配置
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=my_alg_snowflake
# 分布式序列算法配置
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.my_alg_snowflake.type=SNOWFLAKE
对实体类进行更改,这里mybatis plus 也提供了内置的雪花算法,必须要加,否则就是默认使用mybatis plus 的雪花算法
/**
* 主键id
*/
@ApiModelProperty(value = "主键id", name = "id")
//当配置了shardingsphere-jdbc的分布式序列时,自动使用shardingsphere-jdbc的分布式序列
//当没有配置shardingsphere-jdbc的分布式序列时,自动依赖数据库的主键自增策略
@TableId(type = IdType.AUTO)
private Long id;
多表关联查询
在DB1主库建立用户信息表
CREATE TABLE `users` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',
`account` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '用户账号',
`username` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '用户名',
`password` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '密码',
`described` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '描述',
`cname` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '创建人',
`ctime` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`chname` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '修改人',
`mtime` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`deleted` bit(1) DEFAULT b'0' COMMENT '逻辑删除',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
在两个主库分别建立:
- 订单表
- 订单详情表
订单表:记录用户编号和订单编号
CREATE TABLE `test_order0` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',
`order_no` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '订单编号',
`account` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '用户账号',
`amount` DECIMAL(10,2) DEFAULT NULL COMMENT '订单金额',
`deleted` varchar(1) DEFAULT '0' COMMENT '删除标记',
`ctime` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`crname` varchar(32) DEFAULT NULL COMMENT '创建人',
`mtime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`chname` varchar(32) DEFAULT NULL COMMENT '更新人',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1672163673329414147 DEFAULT CHARSET=utf8 COMMENT='订单表'
CREATE TABLE `test_order1` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',
`order_no` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '订单编号',
`account` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '用户账号',
`amount` DECIMAL(10,2) DEFAULT NULL COMMENT '订单金额',
`deleted` varchar(1) DEFAULT '0' COMMENT '删除标记',
`ctime` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`crname` varchar(32) DEFAULT NULL COMMENT '创建人',
`mtime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`chname` varchar(32) DEFAULT NULL COMMENT '更新人',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1672163673329414147 DEFAULT CHARSET=utf8 COMMENT='订单表'
订单详情表,也加入 account 字段,是希望同一个用户的订单表和订单详情表中的数据都在同一个数据源中,避免跨库关联,因此这两张表我们使用相同的分片策略。
CREATE TABLE `test_order_item0` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',
`order_no` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '订单编号',
`account` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '用户编号',
`commodity_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '商品id',
`price` DECIMAL(10,2) DEFAULT NULL COMMENT '商品单价',
`count` bigint COMMENT '商品数量',
`descd` varchar(512) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '备注',
`deleted` varchar(1) DEFAULT '0' COMMENT '删除标记',
`ctime` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`crname` varchar(32) DEFAULT NULL COMMENT '创建人',
`mtime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`chname` varchar(32) DEFAULT NULL COMMENT '更新人',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1672163673329414147 DEFAULT CHARSET=utf8 COMMENT='订单详情表'
CREATE TABLE `test_order_item1` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',
`order_no` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '订单编号',
`account` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '用户编号',
`commodity_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '商品id',
`price` DECIMAL(10,2) DEFAULT NULL COMMENT '商品单价',
`count` bigint COMMENT '商品数量',
`descd` varchar(512) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '备注',
`deleted` varchar(1) DEFAULT '0' COMMENT '删除标记',
`ctime` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`crname` varchar(32) DEFAULT NULL COMMENT '创建人',
`mtime` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`chname` varchar(32) DEFAULT NULL COMMENT '更新人',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1672163673329414147 DEFAULT CHARSET=utf8 COMMENT='订单详情表'
分库分表配置:
# 订单表和订单详情表分片
spring.shardingsphere.rules.sharding.tables.test_order.actual-data-nodes=db$->{0..1}.test_order$->{0..1}
spring.shardingsphere.rules.sharding.tables.test_order_item.actual-data-nodes=db$->{0..1}.test_order_item$->{0..1}
# test_order ,test_order_item 使用相同的分库策略,根据id取模 ,这里指定的是数据库
spring.shardingsphere.rules.sharding.tables.test_order.database-strategy.standard.sharding-column=account
spring.shardingsphere.rules.sharding.tables.test_order.database-strategy.standard.sharding-algorithm-name=inline_account
spring.shardingsphere.rules.sharding.tables.test_order_item.database-strategy.standard.sharding-column=account
spring.shardingsphere.rules.sharding.tables.test_order_item.database-strategy.standard.sharding-algorithm-name=inline_account
spring.shardingsphere.rules.sharding.sharding-algorithms.inline_account.type=HASH_MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.inline_account.props.sharding-count=2
# test_order ,test_order_item 使用形同的分表策略,用hash对 order_no 进行取模,这里指定表
spring.shardingsphere.rules.sharding.tables.test_order.table-strategy.standard.sharding-column=order_no
spring.shardingsphere.rules.sharding.tables.test_order.table-strategy.standard.sharding-algorithm-name=hash_mod
spring.shardingsphere.rules.sharding.tables.test_order_item.table-strategy.standard.sharding-column=order_no
spring.shardingsphere.rules.sharding.tables.test_order_item.table-strategy.standard.sharding-algorithm-name=hash_mod
# hash分片算法 hash_mod
spring.shardingsphere.rules.sharding.sharding-algorithms.hash_mod.type=HASH_MOD
# 分片算法属性配置 ,这里就是 id计算为hash值后 对2取模
spring.shardingsphere.rules.sharding.sharding-algorithms.hash_mod.props.sharding-count=2
# 复用之前配置的雪花算法,生成分布式序列id
spring.shardingsphere.rules.sharding.tables.test_order.key-generate-strategy.column=id
spring.shardingsphere.rules.sharding.tables.test_order.key-generate-strategy.key-generator-name=my_alg_snowflake
spring.shardingsphere.rules.sharding.tables.test_order_item.key-generate-strategy.column=id
spring.shardingsphere.rules.sharding.tables.test_order_item.key-generate-strategy.key-generator-name=my_alg_snowflake
# 分布式序列算法配置
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.my_alg_snowflake.type=SNOWFLAKE
订单表和订单详情表,使用相同的分库分表策略,保证相关的数据在一个库中,避免跨库的关联查询
插入方法:
@Resource
private TestOrderItemMapper testOrderItemMapper;
/**
* 新增订单表时要把订单详情表一起插入
*
* @param req
* @return
*/
public BaseResultModel insert(ReqTestOrderAdd req) {
//订单编号用uuid生成
String orderNo = UUID.randomUUID().toString().replace("-", "");
TestOrder entity = new TestOrder();
entity.setOrderNo(orderNo);
entity.setAmount(req.getCount() * req.getPrice());
entity.setAccount(req.getAccount());
entity.setDeleted("0");
//订单详情
TestOrderItem testOrderItem = new TestOrderItem();
testOrderItem.setOrderNo(orderNo);
testOrderItem.setAccount(req.getAccount());
testOrderItem.setCommodityId(req.getCommodityId());
testOrderItem.setAccount(req.getAccount());
testOrderItem.setPrice(req.getPrice());
testOrderItem.setDescd(req.getDescd());
testOrderItem.setDeleted("0");
testOrderItemMapper.insert(testOrderItem);
if (!this.save(entity)) {
throw new BaseException(ResultStatus.INSERT_FAIL.getCode(), ResultStatus.INSERT_FAIL.getMessage());
}
return BaseResultModel.success();
}
插入订单时,同步插入订单详情,相同的客户编号,数据插入一个库中
查询语句
@Select("SELECT o.account, SUM(i.price * i.count) AS amount " +
"FROM test_order o JOIN test_order_item i ON o.order_no = i.order_no GROUP BY account")
List<OrderItemVo> selectGroupByAccount();
实际上是在各自的库上做笛卡尔积的关联,会有很多不必要的查询,可以通过绑定表俩解决这个问题
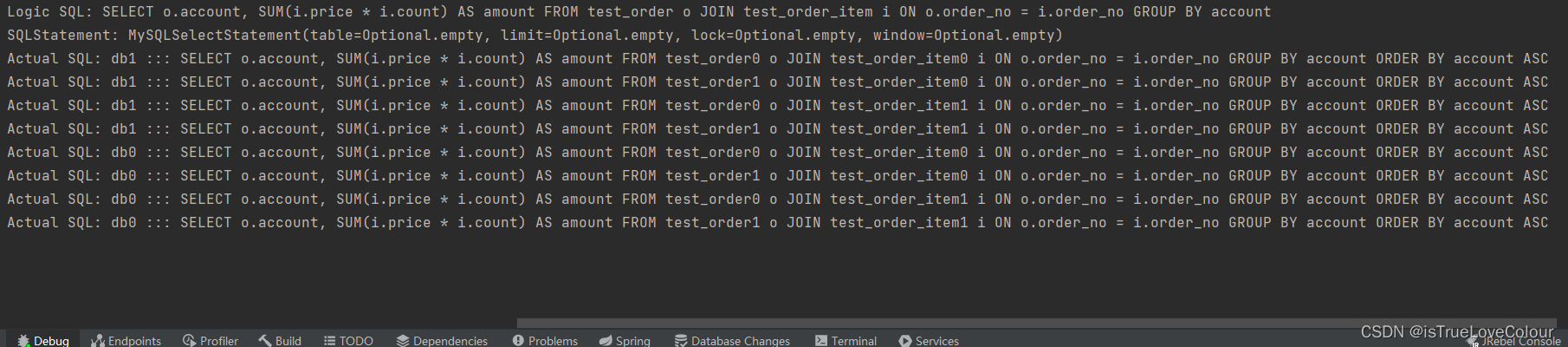
分片规则一致的一组分片表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。
绑定表配置如下:
spring.shardingsphere.rules.sharding.binding-tables[0]=test_order,test_order_item
绑定表后,通过分片规则列去查询,会减少很多不必要的查询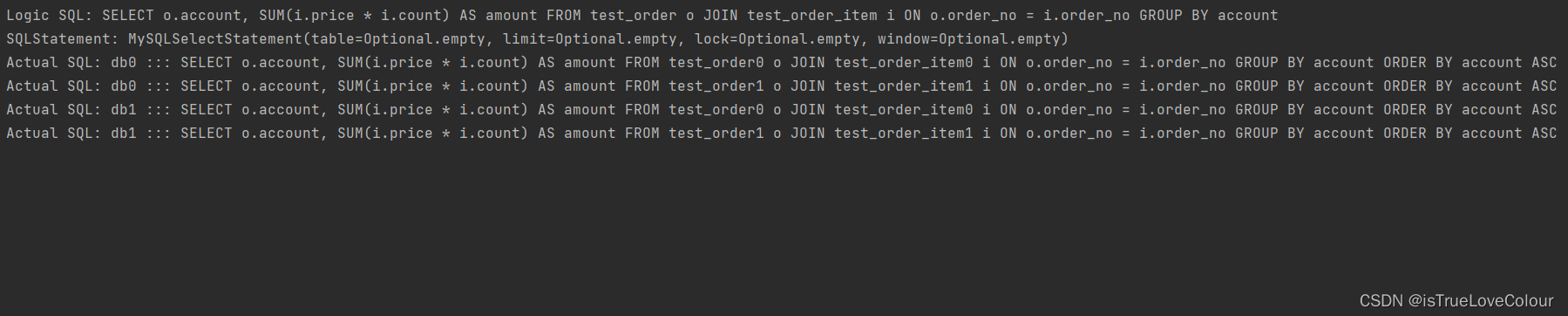
广播表
比如一些字典表,需要经常和其他分片表进行关联,那么就需要所有的分片数据源中都存在这个表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景
广播具有以下特性:
(1)插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
(2)查询操作,只从一个节点获取,因为每个节点的数据都是一致的
(3)可以跟任何一个表进行 JOIN 操作
在db0、db01 数据库中分别创建t_dict表
CREATE TABLE t_dict(
id BIGINT,
dict_type VARCHAR(200),
PRIMARY KEY(id)
);
配置广播表
#数据节点可不配置,默认情况下,向所有数据源广播
spring.shardingsphere.rules.sharding.tables.t_dict.actual-data-nodes=db0.t_dict,db1.t_dict
# 广播表
spring.shardingsphere.rules.sharding.broadcast-tables[0]=t_dic