最近在使用SPI的时候,遇到了一些数据传输效率问题,在此记录自己学习过程。SPI的基础知识这里就不在讲述了,直接分析SPI查询方式和DMA方式的效率问题。这里使用的芯片是GD32F303CC。
SPI以查询方式进行全双工通信
1.查询手册,SPI0挂载在APB2总线下,最高频率120MHZ。
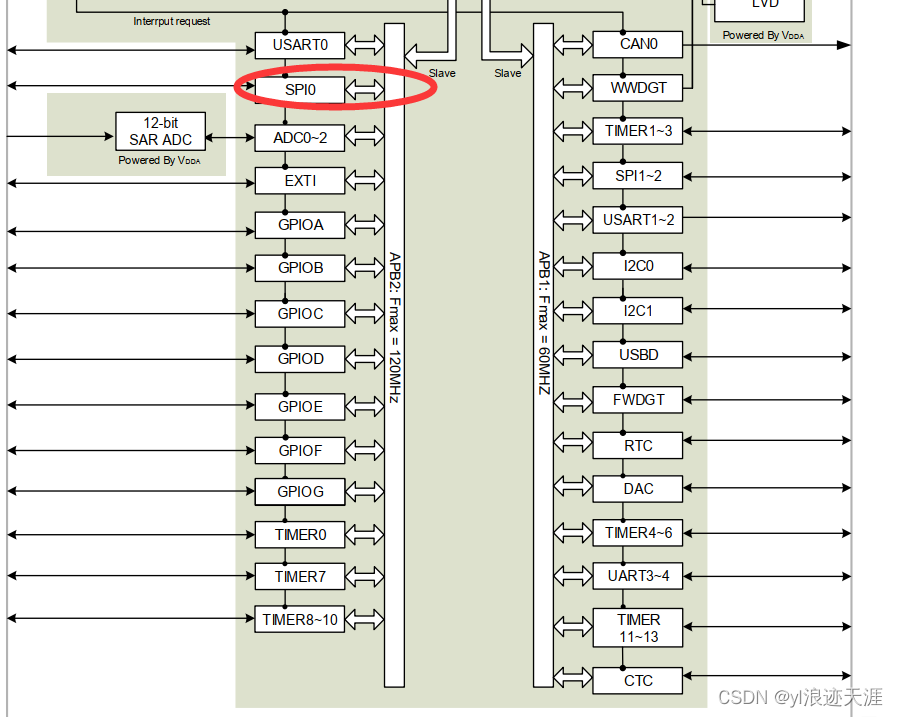
2.接下来对SPI0进行配置
以下只是简化的配置内容,可以看出SPI0的CLK速率是3.75MHZ,还有一个注意的点MISO配置的是输入模式,而不是输出。
// SPI0 主机模式 使用软件SPI片选信号
/* SPI0 GPIO config:NSS/PA3, SCK/PA5, MISO/PA6, MOSI/PA7 */
gpio_init(GPIOA, GPIO_MODE_AF_PP, GPIO_OSPEED_50MHZ, GPIO_PIN_5 | GPIO_PIN_7);
gpio_init(GPIOA, GPIO_MODE_IN_FLOATING, GPIO_OSPEED_50MHZ, GPIO_PIN_6); // MOSI 浮空输入
/* PA3 as NSS */
gpio_init(GPIOA, GPIO_MODE_OUT_PP, GPIO_OSPEED_50MHZ, GPIO_PIN_3);
/* SPI0 parameter config */
spi_init_struct.trans_mode = SPI_TRANSMODE_FULLDUPLEX;
spi_init_struct.device_mode = SPI_MASTER;
spi_init_struct.frame_size = SPI_FRAMESIZE_8BIT;
spi_init_struct.clock_polarity_phase = SPI_CK_PL_LOW_PH_1EDGE;
spi_init_struct.nss = SPI_NSS_SOFT; //软件片选
spi_init_struct.prescale = SPI_PSC_32; //120M/32 = 3.75M
spi_init_struct.endian = SPI_ENDIAN_MSB;
spi_init(SPI0, &spi_init_struct);
3.使用API函数进行数据的发送和接收,最后通过逻辑分析仪抓取时序图

发现SPI传输数据的过程中,SCK的时钟频率为3.703M符合我们设置的CLK频率,但是我们发现两个SPI的字节之间有一段SCK是空闲的,从逻辑分析仪上看时间高达1.95us,比SPI传输一个自字节的时间还长,在极大的影响了SPI的传输速率。其实这个空闲时间正是MCU在搬运SPI的数据。
到底是不是这么回事呢,我们提升SPI的SCK速率,来继续观察。
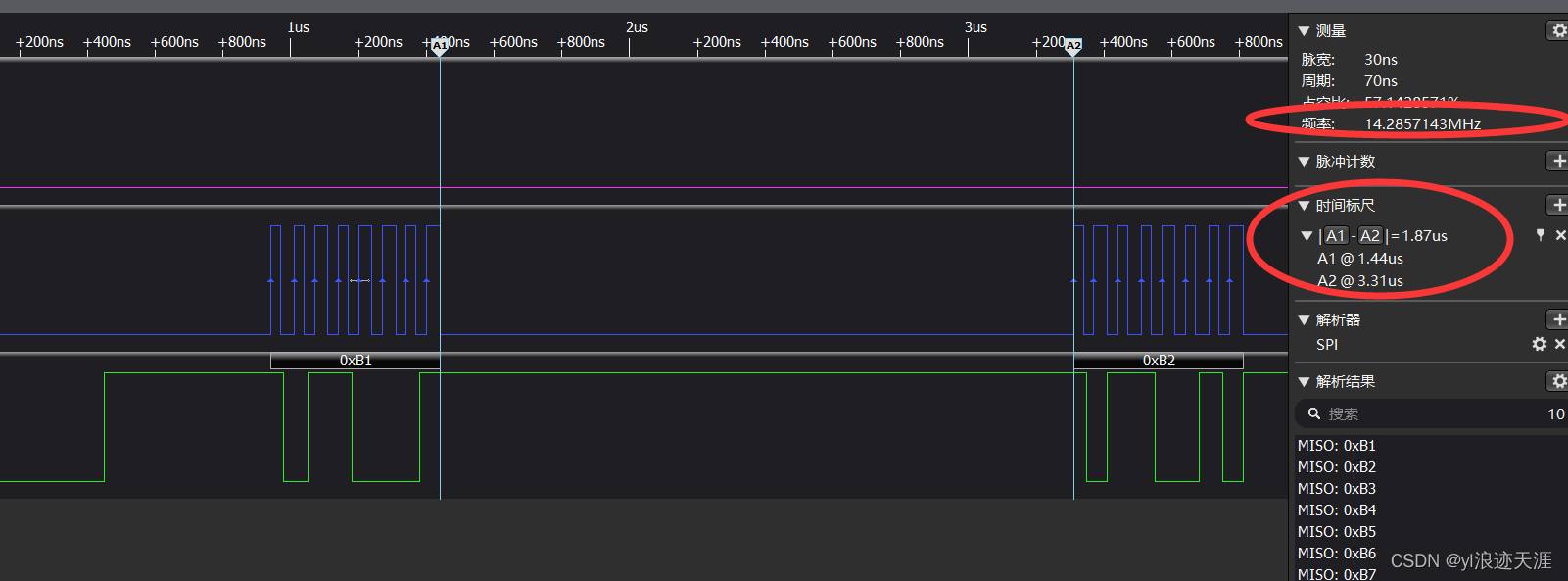
这里我们把SPI的CLK速率提升到15Mhz,发现空闲状态的时间已经是传输数据的时间的好几倍了,且空闲状态的时间为1.87us(逻辑分析仪采样率不足导致),与1.95us接近。如果传输大量数据的话,使用查询的方式效率还是太低。
SPI以DMA进行全双工通信
1.查询SPI0的DMA相关信息
DMA 功能在传输过程中将应用程序从数据读写过程中释放出来, 从而提高了系统效率。根据查询手册我们知道,SPI0的RX和TX分别挂载在DMA0的通道1和通道2下面。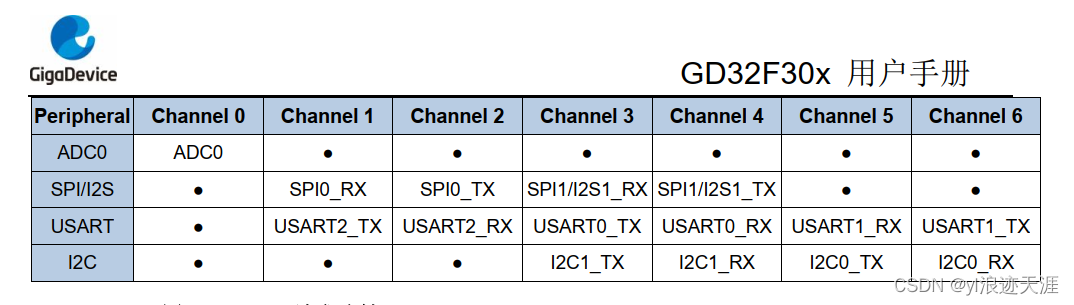
2.接下来对SPI0进行配置
其他SPI的配置都和前面一致,只是新增了SPI DMA相关的配置。这里简短的贴上一部分代码:
void spi_dma_config(void)
{
dma_parameter_struct dma_init_struct;
/* SPI0 transmit dma config:DMA0-DMA_CH2 */
dma_deinit(DMA0, DMA_CH2);
dma_init_struct.periph_addr = (uint32_t)&SPI_DATA(SPI0);
dma_init_struct.memory_addr = (uint32_t)spi0_send_array;
dma_init_struct.direction = DMA_MEMORY_TO_PERIPHERAL;
dma_init_struct.memory_width = DMA_MEMORY_WIDTH_8BIT;
dma_init_struct.periph_width = DMA_PERIPHERAL_WIDTH_8BIT;
dma_init_struct.priority = DMA_PRIORITY_LOW;
dma_init_struct.number = arraysize;
dma_init_struct.periph_inc = DMA_PERIPH_INCREASE_DISABLE;
dma_init_struct.memory_inc = DMA_MEMORY_INCREASE_ENABLE;
dma_init(DMA0, DMA_CH2, &dma_init_struct);
/* configure DMA mode */
dma_circulation_disable(DMA0, DMA_CH2);
dma_memory_to_memory_disable(DMA0, DMA_CH2);
/* SPI0 receive dma config:DMA0-DMA_CH1 */
dma_deinit(DMA0, DMA_CH1);
dma_init_struct.periph_addr = (uint32_t)&SPI_DATA(SPI0);
dma_init_struct.memory_addr = (uint32_t)spi0_receive_array;
dma_init_struct.direction = DMA_PERIPHERAL_TO_MEMORY;
dma_init_struct.priority = DMA_PRIORITY_HIGH;
dma_init(DMA0, DMA_CH1, &dma_init_struct);
/* configure DMA mode */
dma_circulation_disable(DMA0, DMA_CH1);
dma_memory_to_memory_disable(DMA0, DMA_CH1);
/* SPI1 transmit dma config:DMA0,DMA_CH4 */
dma_deinit(DMA0, DMA_CH4);
dma_init_struct.periph_addr = (uint32_t)&SPI_DATA(SPI1);
dma_init_struct.memory_addr = (uint32_t)spi1_send_array;
dma_init_struct.direction = DMA_MEMORY_TO_PERIPHERAL;
dma_init_struct.priority = DMA_PRIORITY_MEDIUM;
dma_init(DMA0, DMA_CH4, &dma_init_struct);
/* configure DMA mode */
dma_circulation_disable(DMA0, DMA_CH4);
dma_memory_to_memory_disable(DMA0, DMA_CH4);
/* SPI1 receive dma config:DMA0,DMA_CH3 */
dma_deinit(DMA0, DMA_CH3);
dma_init_struct.periph_addr = (uint32_t)&SPI_DATA(SPI1);
dma_init_struct.memory_addr = (uint32_t)spi1_receive_array;
dma_init_struct.direction = DMA_PERIPHERAL_TO_MEMORY;
dma_init_struct.priority = DMA_PRIORITY_ULTRA_HIGH;
dma_init(DMA0, DMA_CH3, &dma_init_struct);
/* configure DMA mode */
dma_circulation_disable(DMA0, DMA_CH3);
dma_memory_to_memory_disable(DMA0, DMA_CH3);
}3.使用API函数进行数据的发送和接收,最后通过逻辑分析仪抓取时序图
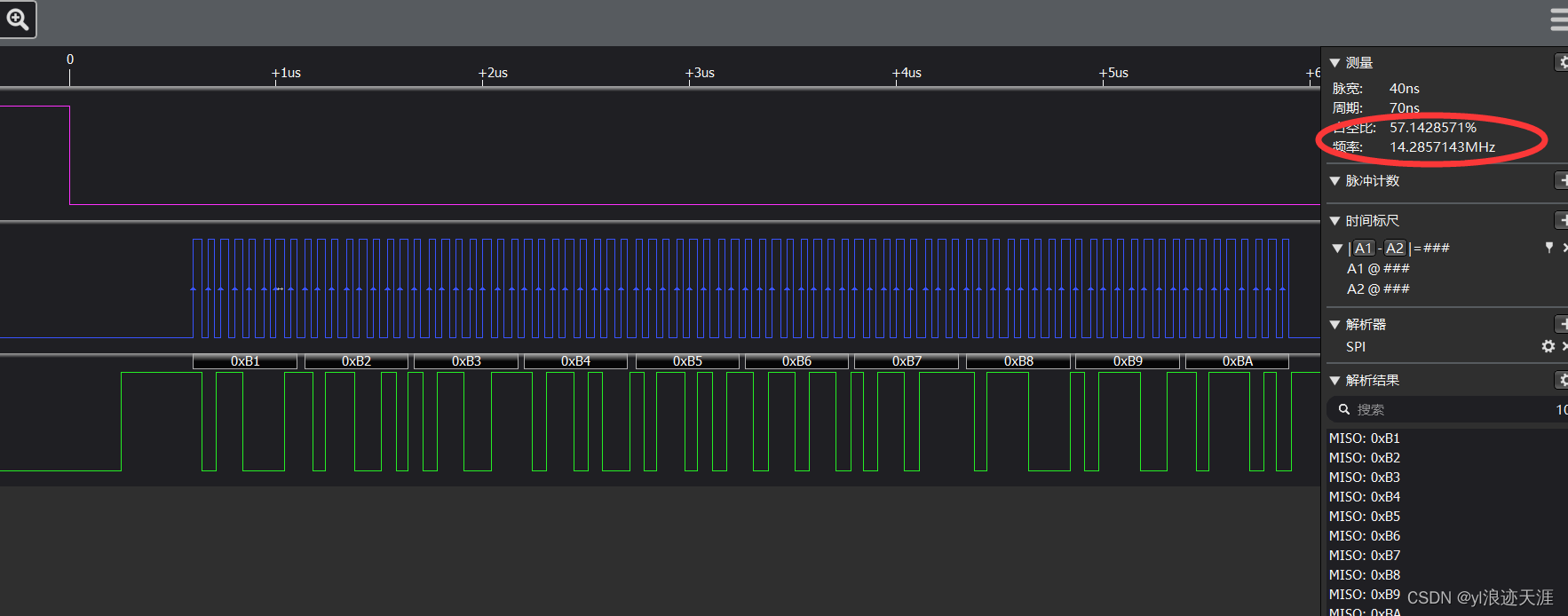
从逻辑分析仪上可以看出,SPI使用DMA发送不会再出现两个字节之间CLK空余时间,极大的提升了SPI的传输速率。
防伪记录:文章原创于yl浪迹天涯。
总结
对于一般数据几个字节的传输,还是建议使用查询式(阻塞式)SPI,因为传输更加容易,DMA方式适合于高频次大容量数据传输的场景。比如在使用SPI 读取W25Q128芯片ID或者一般的操作指令的时候,就没有必要使用DMA方式了,但是在一次读取几个页的数据的时候,建议还是使用DMA方式。
附带源码
参考源码来源于GD32官网的GD32F30x_Firmware_Library_Vx.x.x库里面的Examples,具体代码直接去GD32官网下载即可。