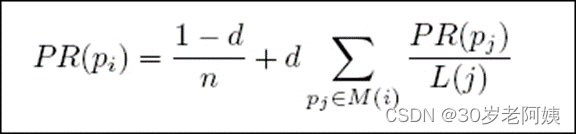个性化推荐项目
- 个性化推荐的设计和演进
- 项目概览
- 项目梳理
- 依赖管理
- 实现代码的重构和改进
- 持续演化
个性化推荐的设计和演进
CSDN 的个性化推荐系统,是从既有的推荐项目中剥离出来的一个子项目,这个项目随后移交到了我们AI组。在近一年的时间内,我们对这个项目进行了多次改进和重构。
项目概览
首先,我希望强调一点,个性化推荐系统的整体设计非常好,我交接时拿到的是一个以解释器模式驱动的spring服务:

从外部接口看, 它是个相当正统的 http json 服务,各种服务接口以 JSON API 的形式提供,大部分都是 POST 请求。从内部看,它没有使用常规的API/服务/关系型数据库的分层模式,数据持久层使用了hbase,把复杂性封装在应用层。之前构造项目的同事设计了一套非常漂亮的解释器机制,把推荐策略设计成可以通过JSON定制的形式,在运行期解释为策略图(graph of strategy)对象(这一步甚至是热更新的),任务执行器依据策略图访问对应的策略组件——它们通常是 spring service 对象——从而得到最终推送给用户的信息流。
在深入到后面的内容之前,我们先回顾一下这里出现的一些名词:
- API 这里我特指这些用 spring controller 定义的 http json 服务,它们大多是 POST,有少量是 GET 请求
- 策略图 strategy graph 是用 JSON 定义的策略,它定义一个推送信道来自哪些召回源,经由哪些过滤器和组合策略,最终成为一个线性的推荐信息流,这些图总是定义为一个有向的树图,可能有多个起源,但是最终汇聚为一个唯一的信息出口。有向图中的节点需要定义一个唯一的 id,其中大部分需要制定自己的 next id,而最后一个节点,显然没有 next。
- 任务执行器 在项目中被称为 task executor,它从配置中心读取 strategy graph 定义,调用 strategy service 执行,用于响应 http 请求或定时任务
- 策略组件 这些组件以 spring service 的形式运行在项目中,大致可以分为这样几类:
- 信道 channel 是信息流的定义单元,不同的业务方在调用时会访问不同的信道,策略执行器根据配置执行对应的策略图,返回其对应的信息流
- 召回策略 大部分是封装 hbase 查询,但是也有少量调用其他 http 服务或 redis
- 过滤策略 过滤策略通常是用于将符合条件的信息保留下来,抛弃其它,我也写了几个过滤器组件,并不直接修改信息流,而是用于记录和计算,这个后面讨论。
- 组合策略 组合策略通常是是一个策略图的最后一个节点。召回(callback)策略和过滤(filter)策略通常是无状态的。例如,多个召回策略的next都指向了同一个过滤器策略id,在实际执行时,它们也会被视作各自独立的路线,因为过滤策略是无状态的,即使调用用一个过滤器,也可以视作几次无状态的函数调用——如果我们实现了有状态的过滤器,那就要小心维护其状态在并发环境中不被破坏。而唯一会合并执行路径的,就是组合策略,执行器会将所有指向同一个组合策略的数据汇总后一次传给组合策略,获取其组合操作的结果,在这些组合策略中我们实现推送流的去重、剪裁等操作。
形象的看,一个策略可能是如下的结构:

在组合策略的后面,仍有可能存在过滤器,但是召回策略,总是在执行图的最前面,也就是树的最末端。
除此之外,我们有一些数据处理任务,用于向hbase写入推送数据,这些因为独立性较强,与服务就不做介绍了。
有了这些概念,我就可以简单回顾一下自这个个性化推荐项目交接以来,我们组所做的工作。
项目梳理
刚写了一本解释器教程的我,接手这个项目的时候,可以说非常的欣喜,从这个项目的设计中读到了很多共鸣之处。但是项目的具体实现,仍然有很多需要修正和改进的地方。
依赖管理
首先,项目的依赖库,有很多没有持续的跟进维护,这里面有不少重要的依赖项目已经因为安全和功能bug,做了升级,但是我们仍在使用陈旧的版本。与此相比,仍然在使用 java 8倒不是主要的问题了。
我跟进IDE的提示,对依赖库做了尽可能的升级,这里面确实遇到了一些兼容问题,为此我修改了一部分调用逻辑,但是总体来说,这个工作非常的值得。我遇到过很多项目,历史遗留的代码哪怕再简单,也没有人愿意下功夫去阅读和梳理,这里面固然有开发人员的惰性,但主要仍然是管理问题。不付出一定工作量去处理这些问题,久而久之,这些版本问题就成了一种迷信,即使其中有问题,也没有人原因冒着哪怕万分之一的风险去修改。我就从个性化推荐的项目依赖中删掉了一个非常古老的依赖,这个代码库在 search.maven.org 上能找到的最近一次更新是20年前。我删掉它以后,一直到现在,没有发生任何问题,也就是说,其实根本就没有用到这个库,但是没有人敢去动它。
这个过程中,一个很大的改动是,我用 Jackson 代替了 fastjson。Fastjson有很多优点,但是和很多 Java 项目一样,个性化推荐中对 fastjson 的使用处于失序状态 ,无论最初定义的版本出于何等动机,后续在也没有人面对那些 cve ,去做过任何升级维护。而 fastjson 社区本身 ,也早就推荐用户改用 fastjson2 了。
所谓“稳定”作为不升级的借口,在我看来是非常难以忍受的。我改用 jackson 也无非是因为这样几点:
- 我对 Jackson 有足够的了解,如果用 fastjson2,那么jackson用户(实际上就是我)和fastjson(公司既有的java开发人员)都不了解它,而 jackson 至少我可以驾驭
- Jackson 不是最快的 JSON库,也并非没有缺陷,但是它足够活跃,综合各方面表现,也足够使用,Spring、lombok等常规工具与之也配合良好。
- Jackson 的使用过程并不是最简洁的,但是足够灵活,我可以针对不同的使用场景,定义不同的ObjectMapper——其实我看到fastjson也有类似的功能,但是这样用的人似乎不多,使用 fastjson,主要还是因为它有足够方便的快捷调用风格,并且这个风格经过了深度的性能优化。
实现代码的重构和改进
除了这种基础工具的改动,最大的问题是,之前最常用的几个组合策略其实始终没有达到设计目标,从上游信息流中抽取信息项的逻辑,实现的非常粗糙。为了最终构造出足够好的用户体验,不得不将策略图配置的非常复杂,几个最主要的信息流都是多层组合策略,通过将组合策略再次作为召回源使用,来实现信息流的随机行为。
因此,我重写了组合策略,包括所有组合策略的公共基类和所有的实现子类。引入了非平均随机概率。使得信息流的构造可以兼顾随机性和排名。并且完整的重写了整个业务逻辑和配置, 去掉了那些不必要的多层组合。
在这个过程中,我遇到了很多细节问题,比如过去代码中对信息项的score值,是按升序排列,分数越小越优先。这个问题其实不影响项目的正常运行,但是对开发人员非常的不友好, 可以说这是我二十三年的开发工作中,第一次遇到推荐系统的 score 居然不是降序,于是我在重写组合策略时,预留了排序方向的设定能力,终于最近一段时间,负责数据分析任务的同事修改了上游的任务,个性化推荐也就迅速切换到了常规的降序排列。
这里面还有一个重要的改动是,因为过滤器逻辑在过去的实现中,存在一些不稳定的因素,导致负反馈等过滤器经常失效。具体来说,最初所有的过滤器都是用可删除的迭代器去遍历信息流。而我经过debug,发现有时候这个迭代器会失效,这是因为在信息传递的过程中,有时会经历几次序列化和反序列化,一些反序列化代码(它们来自第三方代码库)会将list还原为某些不能删除的类型。
我将发现的这些迭代器操作, 都改写成了常规的 stream api 风格,总是通过 filter 生成一个新的 list 传递给下游节点。
相信我,在一个复杂项目中,使用可删除迭代器做 in place 的写操作,并不能带来多少性能优势,相反可能会发生这种极难发现的bug。
对于推荐系统,“不重复推荐”是很常规的能力,过去向某个用户推荐过的内容,会写在hbase里,在推荐过程中再通过过滤器查询和筛选。这里面不仅仅是多了一个hbase写入,为了不阻塞hbase,还经过了一个消息队列和几个异步任务,带来了非常多的不确定性。于是我将其简化为一个可以去重的组合策略,将历史内容缓存到redis中。这样可以有效缩短响应时间,也大大简化了项目结构。
当然,在改动过程中,我们也遇到了很多问题,比如一开始对redis key的有效期设置有问题——redis的 spring库有些很细节的东西,会导致代码中的操作顺序未必会与实际操作执行的顺序一致——这些问题也导致我们经历了一段手忙脚乱的时间。感谢同事们的支持和帮助,最终我们解决了这些问题,现在这些功能运转良好,并且比过去更加容易维护和管理。
持续演化
在这些改动的过程中,实际影响最大的是首页推荐流,在终于解决了负反馈失效的问题后,我们简化了负反馈的流程,将其从过去的异步任务访问日志->填充数据->加载过滤的过程,简化为通过个性化推荐的内部API直接记录负反馈。这里面使用 hbase 做了些 OLTP 的工作,虽然 hbase 并不擅长做这样的工作,但是至少我们不必再基于一个漫长的链路来实现负反馈业务,回报是丰厚的。现在负反馈切实的起作用了!
三四月份,我用了一些时间,实现了一些内部的调试器功能,这些功能并不服务于最终用户,但是在我们的开发过程中,这些代码起了重要的作用。我们可以通过这些接口实时查看redis、hbase和服务进程的工作状态,数据的细节。调试器极大的优化了日常的开发工作。
目前,我们正在落实实时正反馈的功能开发,力求将用户的使用体验,更快更有效的体现于内容推荐服务,使个性化推荐系统更智能、精准和友善。