1. 缓存穿透
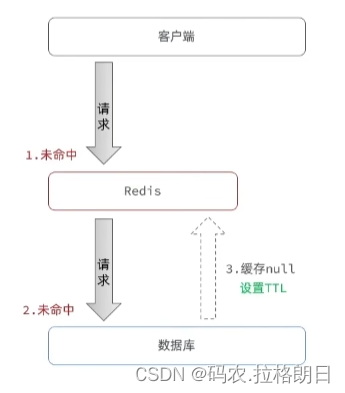
缓存穿透是指在缓存中查找一个不存在的值,由于缓存一般不会存储这种无效的数据,所以每次查询都会落到数据库上,导致数据库压力增大,严重时可能会导致数据库宕机。
解决方案:
方法一:缓存空对象
会带来内存消耗,但是可以设置TTL缓解;
而对于短期的不一致,是因为在给缓存中设置null数据时,可能此时数据库更新该id的数据,用户在TTL的时期内一直查到的是null,这就造成了短期的不一致;
对于不一致可以采取数据库更新,缓存也进行对应的删除和添加,可以进行解决;

方法二:布隆过滤
布隆过滤器判断存在时,是可能存在的并不是一定存在

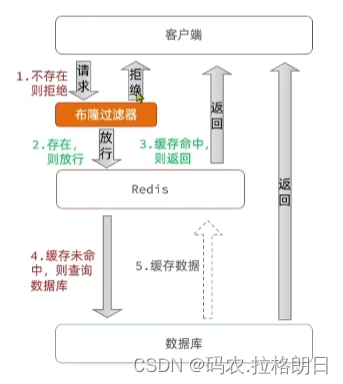
布隆过滤器简单介绍:
Redis布隆过滤器是一种基于位数组的数据结构,其原理如下:
-
由一个位数组和若干个哈希函数构成。
-
初始时,所有位数组的值均为0。当加入一个元素时,使用若干个哈希函数分别对其进行计算,并将计算结果所对应的位数组值设为1。
-
当检查一个元素是否存在于集合中时,同样使用若干个哈希函数计算该元素,如果对应的位数组值均为1,则可以认为该元素可能存在于集合中,如果其中任意一个位数组的值为0,则肯定不存在于集合中。
-
由于哈希函数可能产生哈希碰撞,即不同元素计算出的哈希值相同,因此布隆过滤器无法准确的确定集合中是否存在一个元素,但可以保证如果一个元素被判定不存在,那么它一定不存在,如果判定它存在,那么它可能存在于集合中。
-
布隆过滤器具有非常高的存储效率和查询效率,但存在误判率较高的问题,因此通常作为集合判重的辅助手段,不能作为唯一的判重手段。
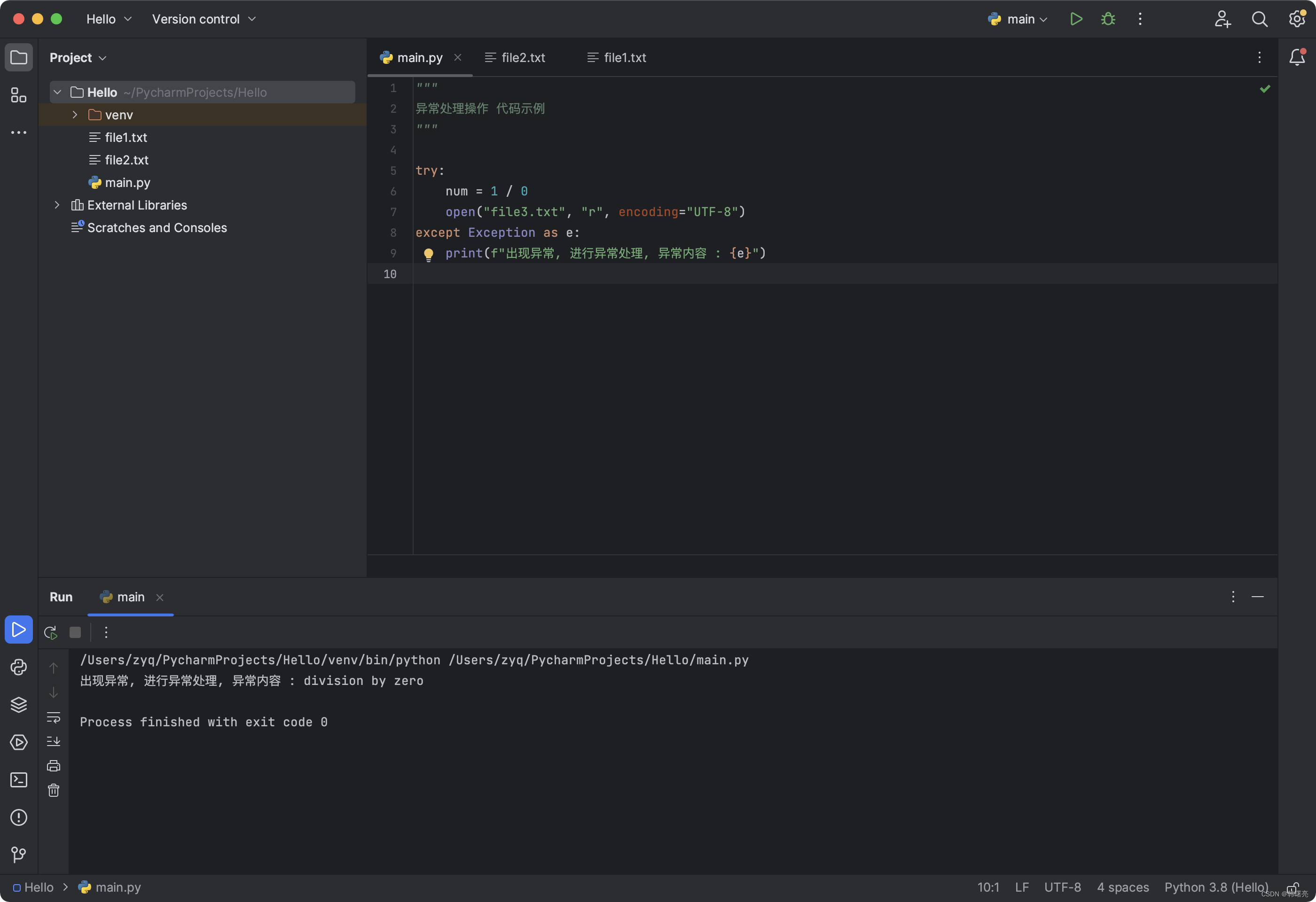
2. 解决商铺查询的缓存穿透问题
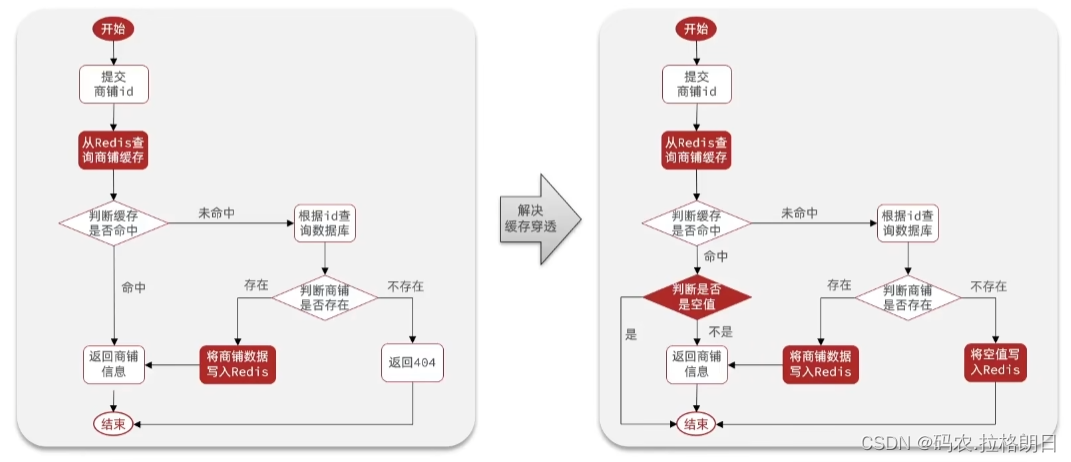
所以查询商铺的代码应该修改为;
这里要做缓存穿透处理,是有意缓存null的,所以要对null多做一次判断

@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY + id;
//1. 从Redis中查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2. 判断是否存在
if(StrUtil.isNotBlank(shopJson)){
//3. 存在,直接返回
Shop bean = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(bean);
}
// 这里要先判断命中的是否是null,因为是null的话也是被上面逻辑判断为不存在
// 这里要做缓存穿透处理,所以要对null多做一次判断,如果命中的是null则shopJson为""
if("".equals(shopJson)){
return Result.fail("店铺不存在");
}
//4. 不存在,根据id查询数据库
Shop byId = getById(id);
if(byId == null) {
//5. 不存在,将空值写入redis缓存,以便下次继续查询缓存时,如果还是查询空值可以直接返回false信息
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return Result.fail("店铺不存在");
}
//6. 存在,写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(byId), CACHE_SHOP_TTL, TimeUnit.MINUTES);
//7. 返回
return Result.ok(byId);
}
总结
缓存空对象和布隆过滤器都是被动解决方案,实际系统应该增加主动解决方法。
- 增强id的复杂度
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流