前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
正文

升级 Hadoop 集群需要细致的规划,特别是 HDFS 的升级。如果文件系统的布局的版本发生变化,升级操作会自动将文件系统数据和元数据迁移到兼容新版本的格式。与其他涉及数据迁移的过程相似,升级操作暗藏数据丟失的风险,因此需要确保数据和元数据都已经备份完毕。
规划过程最好包括在一个小型测试集群上的测试过程,以评估是否能够承担(可能的)数据丢失的损失。测试过程使用户更加熟悉升级过程、了解如何配置本集群和工具集,从而为在产品集群上进行升级工作消除技术障碍。此外,一个测试集群也有助于测试客户端的升级过程。
如果文件系统的布局并未改变,升级集群就非常容易:在集群上安装新版本的 Hadoop(客户端也同步安装),关闭旧的守护进程,升级配置文件, 启动新的守护进程,令客户端使用新的库。整个过程是可逆的,换言之, 也可以方便地还原到旧版本。
成功升级版本之后,还需要执行两个清理步骤。
- 从集群中移除旧的安装和配置文件。
- 在代码和配置文件中针对“被弃用”(deprecation) 警告信息进行修复。
升级功能是Hadoop 集群管理工具如 Cloudera Manager 和 Apache Ambari 的一个亮点。它们简化了升级过程,且使得滚动升级变得容易。节点以批量方式升级(或对于主节点,一次升级一个),这样客户端不会感受到服务中断。
如果采用前述方法来升级 HDFS,且新旧 HDFS 的文件系统布局恰巧不同,则 namenode 无法正常工作,在其日志文件中产生如下信息:
File system image contains an old layout version -16.
An upgrade to version -18 is required.
Please restart NameNode with -upgrade option.
最可靠的判定文件系统升级是否必要的方法是在一个测试集群做实验。
升级 HDFS 会保留前一版本的元数据和数据的副本,但这并不意味着需要两倍的存储开销,因为 datanode 使用硬链接保存指向同一块的两个应用(分别为当前版本和前一版本),从而能够在需要时方便地回滚到前一版本。需要强调的是,系统回滚到旧版本之后,原先的升级改动都将被取消。
用户可以保留前一个版本的文件系统,但无法回滚多个版本。为了执行HDFS 数据和元数据上的另一次升级任务,需要删除前一版本,该过程被称为“定妥升级”(finalizing the upgrade)。一旦执行该操作,就无法再回滚到前一个版本。
一般来说,升级过程可以忽略中间版本。但在某些情况下还是需要先升级到中间版本,这种情况会在发布说明文件中明确指出。
仅当文件系统健康时,才可升级,因此有必要在升级之前调用 fsck 工具全面检查文件系统的状态。此外,最好保留fsck 的输出报告,该报告列举了所有文件和块信息;在升级之后,再次运行 fsck 新建一份输出报告并比较两份报告的内容。
在升级之前最好清空临时文件,包括 HDFS 的 MapReduce 系统目录和本地的临时文件等。
综上所述,如果升级集群会导致文件系统的布局变化,则需要采用下述步骤进行升级。
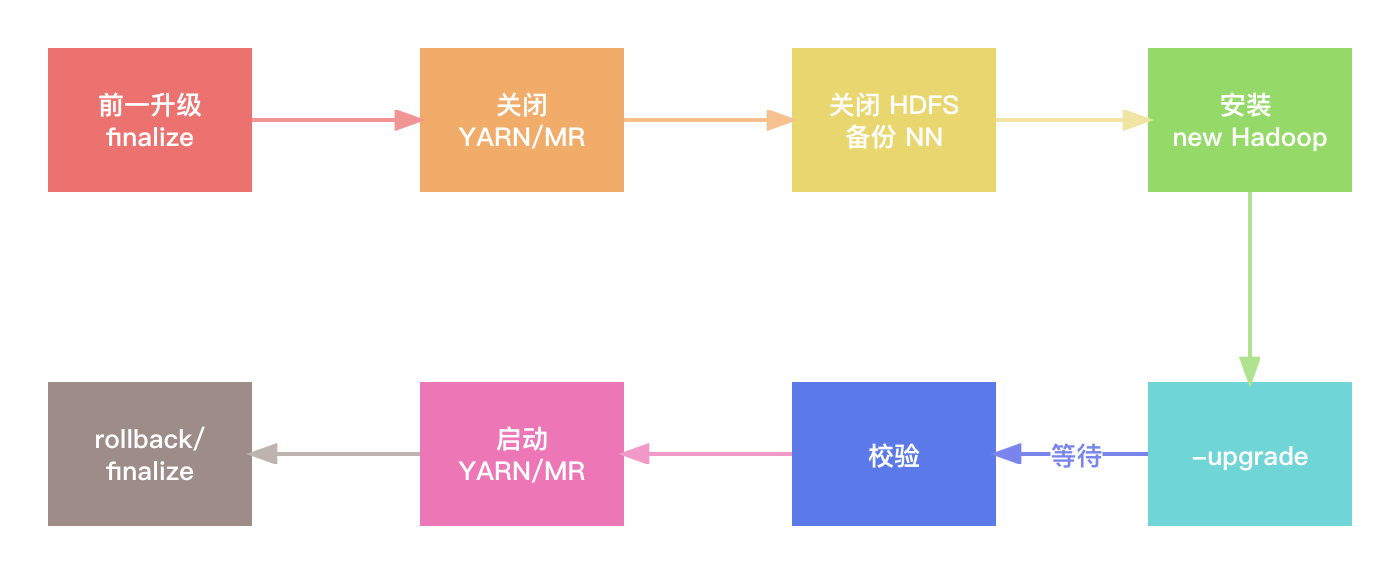
- 在执行升级任务之前,确保前一升级已经定妥。
- 关闭 YARN 和 MapReduce 守护进程。
- 关闭 HDFS,并备份 namenode 目录。
- 在集群和客户端安装新版本的 Hadoop。
- 使用 -upgrade 选项启动 HDFS
- 等待,直到升级完成。
- 检验 HDFS 是否运行正常。
- 启动 YARN 和 MapReduce 守护进程。
- 回滚或定妥升级任务(可选的)。
运行升级任务时,最好移除 PATH 环境变量下的Hadoop 脚本,这样的话,用户就不会混淆针对不同版本的脚本。通常可以为新的安装目录定义两个环境变量。在后续指令中,我们定义了 OLD_HADOOP_HOME 和NEW_HADOOP_HOME 两个环境变量。
启动升级,为了执行升级,可运行以下命令:
% $NEW_HADOOP_HOME/bin/start-dfs.sh -upgrade
该命令的结果是让namenode 升级元数据,将前一版本放在dfs.
namenode.name.dir 下的名为 previous 的新日录中。类似地,datanode 升级存储目录,保留原先的副本,将其存放在 previous 目录中。
等待,直到升级完成,升级过程并非一蹴即就,可以用 dfsadmin 查看升级进度,升级事件同时也出现在守护进程的日志文件中:
% $NEW_HADOOP_HOME/bin/hdfs dfsadmin -upgradeProgress status
Upgrade for version -18 has been completed.
Upgrade is not finalized.
显示升级完毕。在本阶段中,用户可以检查文件系统的状态,例如使用fsck(一个基本的文件操作)检验文件和块。检验系统状态时,最好让HDFS 进人安全模式(所有数据只读),以防止其他用户修改数据。如果新版本无法正确工作,可以回滚到前一版本,前提是尚未定妥更新。
首先,关闭新的守护进程:
% $NEW_HADOOP_HOME/bin/stop-dfs.sh
其次,使用 -rollback 选项启动旧版本的 HDFS:
% $OLD_HADOOP_HOME/bin/start-dfs.sh -rollback
该命令会让 namenode 和 datanode 使用升级前的副本替换当前的存储目录。文件系统返回之前的状态。
定妥升级(可选),如果用户满意于新版本的 HDFS,可以定妥升级, 以移除升级前的存储目录。
在执行新的升级任务之前,必须执行这一步:
% $NEW_HADOOP_HOME/bin/hdfs dfsadmin -finalizeUpgrade
% $NEW_HADOOP_HOME/bin/hdfs dfsadmin -upgradeProgress status
There are no upgrades in progress.
现在,HDFS 已经完全升级到新版本了
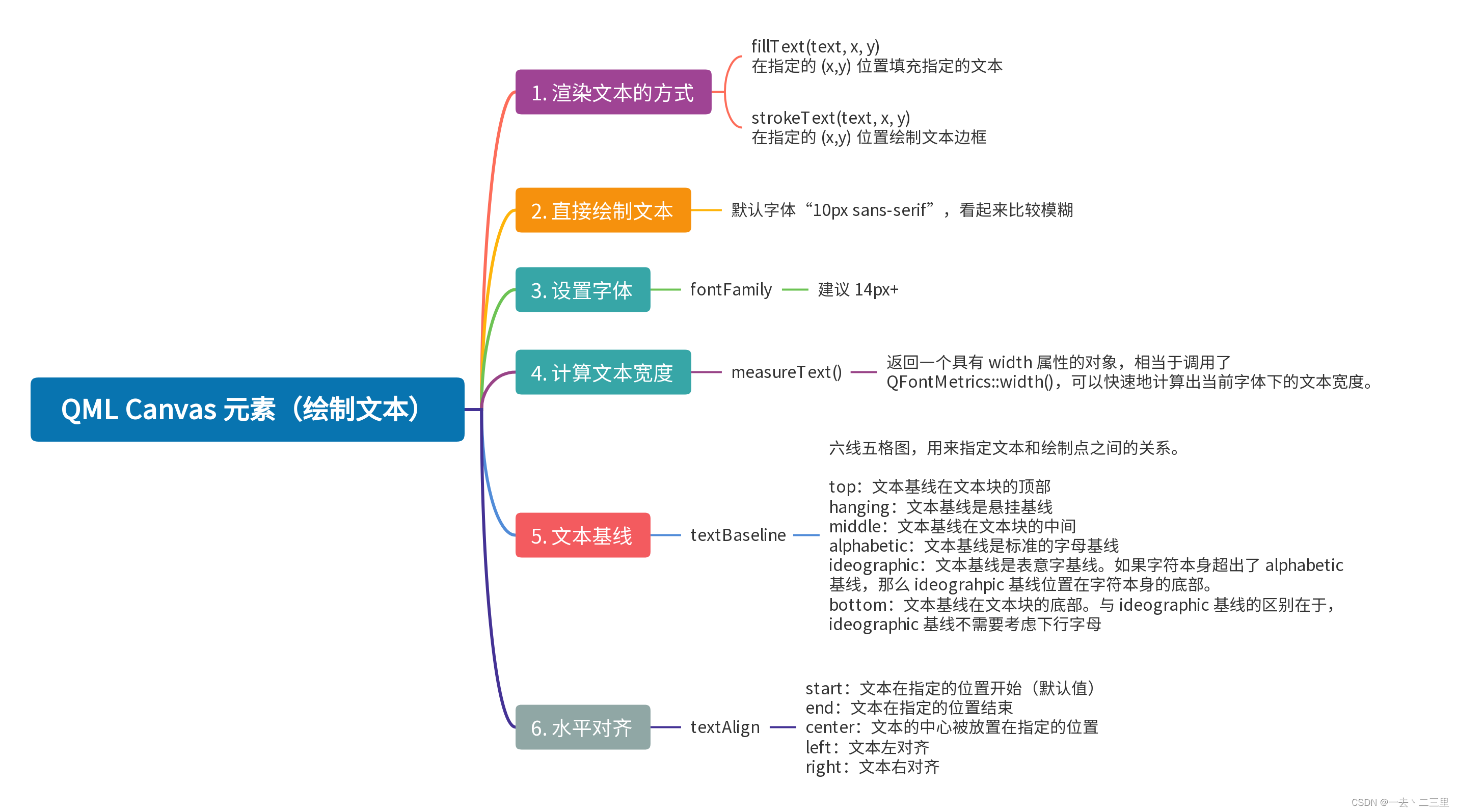
思维导图

总结
本文介绍了升级Hadoop集群的步骤和注意事项,特别是HDFS的升级。
- 升级Hadoop集群需要进行规划,特别是对HDFS的升级需谨慎。升级操作可能导致数据丢失风险,因此在开始升级之前,务必备份数据和元数据。
- 建议在小型测试集群上进行升级测试,以评估可能的数据丢失风险。测试过程可以帮助用户熟悉升级过程和配置,消除技术障碍,并测试客户端的升级过程。
- 如果文件系统的布局没有改变,升级集群相对容易。步骤包括安装新版本的Hadoop、关闭旧的守护进程、升级配置文件、启动新的守护进程,以及让客户端使用新的库。
- 升级成功后,需要执行清理步骤,包括移除旧的安装和配置文件,并修复"被弃用"警告信息。
- Hadoop集群管理工具(Cloudera Manager和Apache Ambari)简化了升级过程,使得滚动升级成为可能。它们支持批量升级节点,以减少对客户端的服务中断。
- 如果HDFS文件系统布局发生变化,需要进行额外的升级步骤。在升级之前,需要确保之前一次升级已经完成,关闭相关守护进程,备份namenode目录,安装新版本的Hadoop,并使用-upgrade选项启动HDFS等。
- 在升级之前,建议使用fsck工具检查文件系统的状态,并保留和比较输出报告。另外,清空临时文件也是一个好的实践。
- 定妥升级是指在满意于新版本的HDFS后,移除升级前的存储目录。在执行新的升级任务之前,需要执行该步骤。
综上所述,本文提供了详细的升级步骤和注意事项,帮助用户顺利升级Hadoop集群,并保护数据的安全性。