HDFS读写流程
这个问题是面试大数据分析师必不可少的问题,有不少面试者不能完整的说出
来,所以请务必记住。并且很多问题都是从 HDFS 读写流程中引申出来的。
一、HDFS读流程
- Client 向 NameNode 发送 RPC 请求。请求文件 block 的位置;
- NameNode 收到请求之后会检查用户权限以及是否有这个文件,如果都符
合,则会视情况返回部分或全部的 block 列表,对于每个 block,NameNode
都会返回含有该 block 副本的 DataNode 地址;这些返回的 DataNode 地址,
会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排
序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时
汇报的 DataNode 状态为 STALE,这样的排靠后; - Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是
DataNode,那么将从本地直接获取数据(短路读取特性); - 底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类
DataInputStream 的 read 方法,直到这个块上的数据读取完毕; - 当读完列表的 block 后,若文件读取还没有结束,客户端会继续向
NameNode 获取下一批的 block 列表; - 读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,
客户端会通知 NameNode,然后再从下一个拥有该 block 副本的 DataNode
继续读; - read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是
返回 Client 请求包含块的 DataNode 地址,并不是返回请求块的数据; - 最终读取来所有的 block 会合并成一个完整的最终文件;
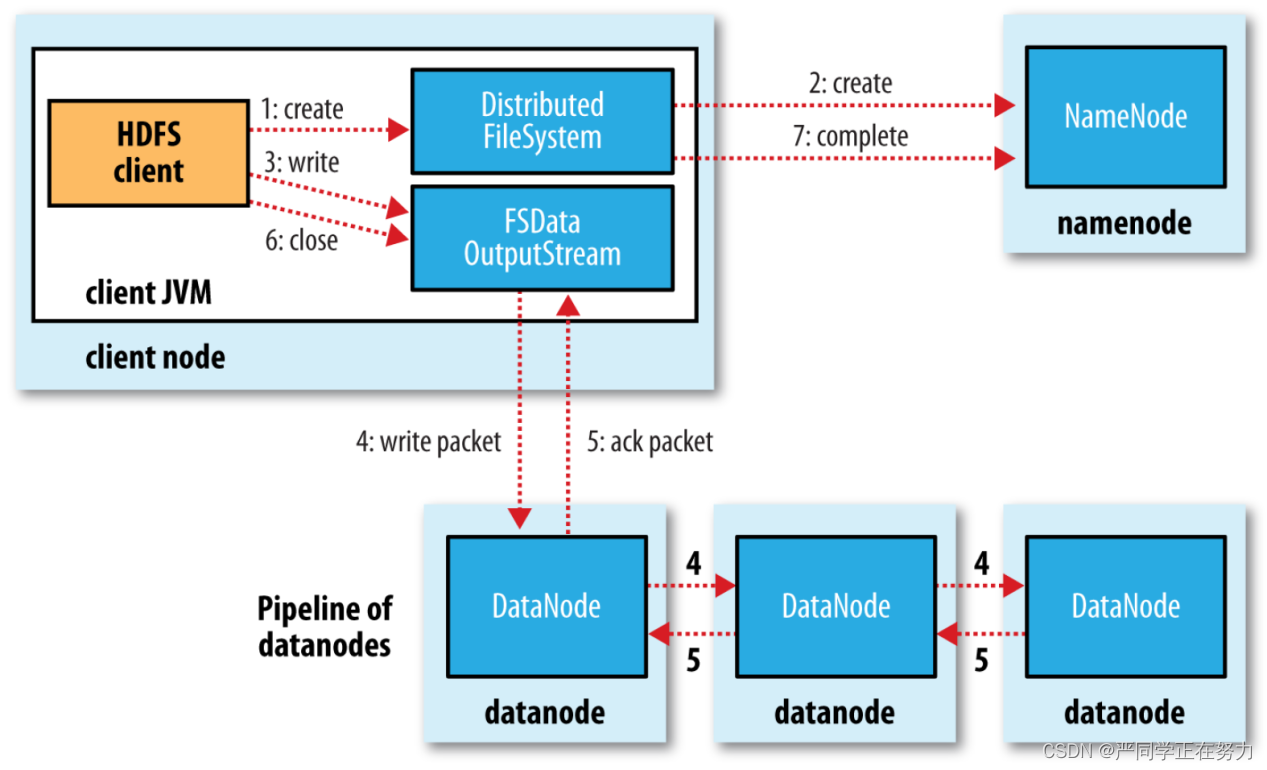
二、HDFS写流程
- Client 客户端发送上传请求,通过 RPC 与 NameNode 建立通信,NameNode
检查该用户是否有上传权限,以及上传的文件是否在 HDFS 对应的目录下
重名,如果这两者有任意一个不满足,则直接报错,如果两者都满足,则
返回给客户端一个可以上传的信息; - Client 根据文件的大小进行切分,默认 128M 一块,切分完成之后给
NameNode 发送请求第一个 block 块上传到哪些服务器上; - NameNode 收到请求之后,根据网络拓扑和机架感知以及副本机制进行文
件分配,返回可用的 DataNode 的地址; - 客户端收到地址之后与服务器地址列表中的一个节点如 A 进行通信,本
质上就是 RPC 调用,建立 pipeline,A 收到请求后会继续调用 B,B 在调
用 C,将整个 pipeline 建立完成,逐级返回 Client; - Client 开始向 A 上发送第一个 block(先从磁盘读取数据然后放到本地内存
缓存),以 packet(数据包,64kb)为单位,A 收到一个 packet 就会发送给
B,然后 B 发送给 C,A 每传完一个 packet 就会放入一个应答队列等待应答; - 数据被分割成一个个的 packet 数据包在 pipeline 上依次传输,在 pipeline
反向传输中,逐个发送 ack(命令正确应答),最终由 pipeline 中第一个
DataNode 节点 A 将 pipelineack 发送给 Client; - 当一个 block 传输完成之后, Client 再次请求 NameNode 上传第二个 block,
NameNode 重新选择三台 DataNode 给 Client。

![[python][yolov8][深度学习]将yolov8实例分割成一个类几句代码完成实例分割任务](https://i1.hdslb.com/bfs/archive/901f587718f84878626aadaab7d6fa3e7176379c.jpg@100w_100h_1c.png@57w_57h_1c.png)









![[皮尔逊相关系数corrwith]使用案例:电影推荐系统](https://img-blog.csdnimg.cn/172e8d0d7b314338b76f1e64f7b32bec.png)
