分类目录:《深入理解深度学习》总目录
MLM训练方法是BERT拥有自然语言理解能力的核心训练方法。然而,BERT在预训练过程中挑选掩码词的概率是独立计算的,即BERT掩码词的粒度是最小的,可能是单个词,也可能是一个词的部分子词。SpanBERT的核心思想是,扩大掩码范围会让模型有更好的性能。具体而言,SpanBERT的主要改进如下:
- 提出了Span Mask方案,扩大掩码词的粒度,即不再对单个词(子词)做掩码操作,而是对局部多个连续词做掩码操作。
- 将Span Boundary Objective(SBO)作为训练方法,利用掩码词附近的词信息,预测某个掩码词的内容,加强了局部上下文的信息利用,以此增强BERT在语义理解上的性能。
- 舍弃NSP训练方法,以获得更好的长文本语义理解能力。
SpanBERT没有修改BERT的结构,也没有使用更多的语料,仅仅通过设计更合理的预训练任务和目标,使模型有更好的性能表现,思路非常独特。
算法细节
掩码词的选择
相比于BERT随机挑选15%的词做掩码操作,SpanBERT在实施多个词的掩码操作时设计得更为精细。实施多词掩码操作的关键有二:
- 连续掩码词的个数。
- 连续掩码词的起点。
SpanBERT利用几何分布来决定连续掩码词的个数,计算公式如下:
I
=
Geo
(
p
)
I=\text{Geo}(p)
I=Geo(p)
其中,
Geo
\text{Geo}
Geo为几何分布采样函数,
p
p
p为几何分布超参数,取值为0.2,
l
l
l为连续掩码词的个数,限定在
[
1
,
10
]
[1, 10]
[1,10]。几何分布采样的概率分布如下图所示。
l
l
l取值为
k
k
k的概率计算公式如下:
P
(
I
=
k
)
=
p
(
1
−
p
)
k
−
1
(
1
−
p
)
10
P(I=k)=\frac{p(1-p)^{k-1}}{(1-p)^{10}}
P(I=k)=(1−p)10p(1−p)k−1
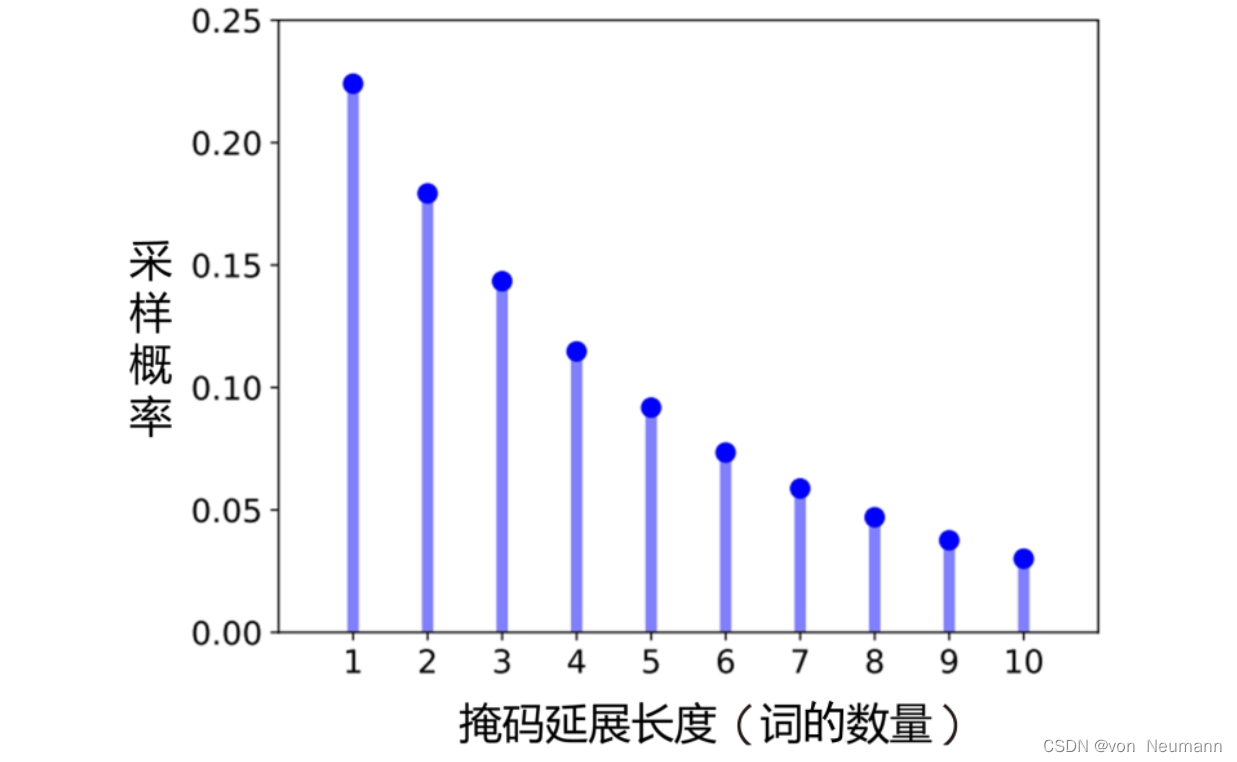
几何分布采样决定了连续掩码词的个数。值得注意的是,掩码词的个数计算的是完整词的个数,并非子词的个数(通过分词工具,一些非常见词会被分割成若干子词),而掩码词的起点是随机选取的,唯一的要求是掩码词的起点必须是一个独立的词,或者是被分为若干子词的第一个子词(即掩码必须覆盖完整的词,以确保语义连贯性)。
SBO训练目标
除了以BERT原有的预测掩码词的交叉熵作为训练目标,对连续掩码词引入掩码边界词作为辅助训练目标,可以让模型具有更好的性能。具体而言,在训练时,取掩码词前后边界的两个词,且这两个词并不在掩码范围内,通过这两个词提取得到的特征向量,与掩码词的位置编码向量联合预测最终的词,即SBO训练方法。
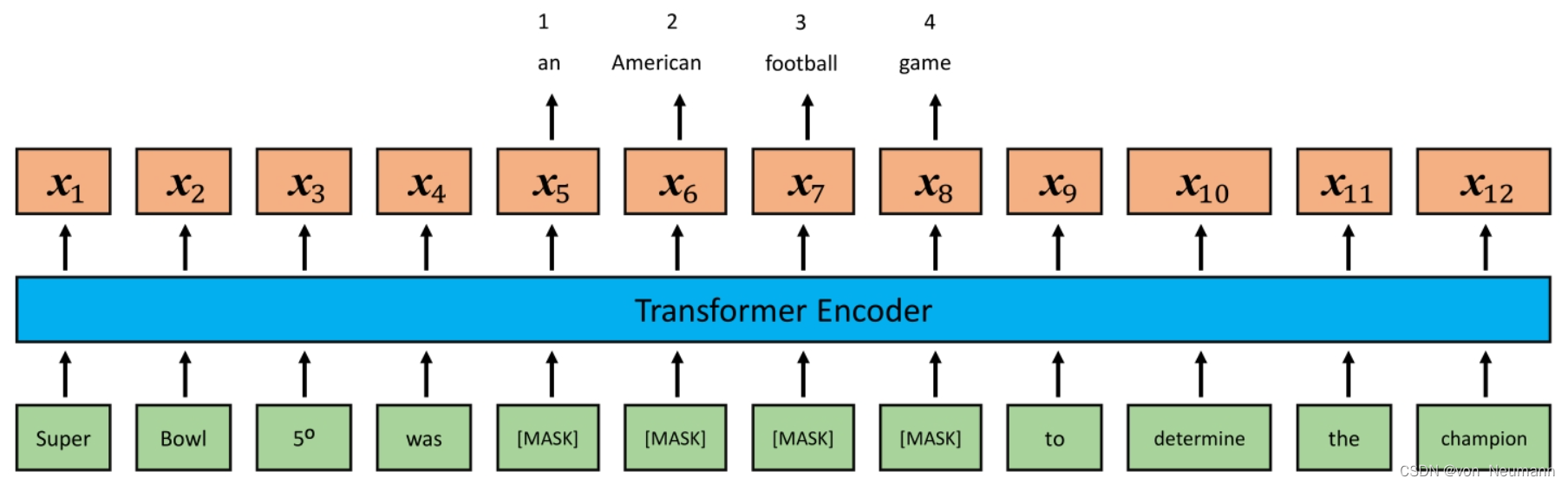
如下图所示,
x
5
,
x
6
,
x
7
,
x
8
x_5, x_6, x_7, x_8
x5,x6,x7,x8是掩码词对应的特征向量,以预测向量
x
7
x_7
x7对应的词为例,该词被正确预测为“football”的概率为:
L
(
football
)
=
L
MLM
(
football
)
+
L
SBO
(
football
)
=
−
log
P
(
football
∣
x
7
)
−
log
P
(
football
∣
x
5
,
x
9
,
p
3
)
\begin{aligned} L(\text{football}) &= L_\text{MLM}(\text{football})+L_\text{SBO}(\text{football}) \\ &= -\log P(\text{football}|x_7) - \log P(\text{football}|x_5, x_9, p_3) \end{aligned}
L(football)=LMLM(football)+LSBO(football)=−logP(football∣x7)−logP(football∣x5,x9,p3)
其中,
L
MLM
L_\text{MLM}
LMLM的计算方法与BERT的MLM计算方法一致,
L
SBO
L_\text{SBO}
LSBO则是通过两层全连接网络计算得到的,
p
3
p_3
p3表示待预测词在掩码词中的位置编码。
综上所述,SpanBERT的主要改进点在于优化了掩码策略,引入SBO训练方法。在绝大部分下游任务中,SpanBERT的表现均优于BERT。它在抽取式问答任务上的表现尤其优异,证明改进后的掩码策略和训练模式与此类任务强相关。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.

![[python][yolov8][深度学习]将yolov8实例分割成一个类几句代码完成实例分割任务](https://i1.hdslb.com/bfs/archive/901f587718f84878626aadaab7d6fa3e7176379c.jpg@100w_100h_1c.png@57w_57h_1c.png)









![[皮尔逊相关系数corrwith]使用案例:电影推荐系统](https://img-blog.csdnimg.cn/172e8d0d7b314338b76f1e64f7b32bec.png)