1.研究动机
推荐系统种类繁多,user、item特征集合可以共享,特定架构特定任务使得各任务间无法迁移。
语言可以描述万物,可以作为推荐系统的中间桥梁,受到prompt学习的影响,本文提出了text-to-text框架,称为p5模型。
p5将推荐任务置身于nlp大环境中,在个性化prompt的设计下,将各类任务转化为p5 nlp语言序列。将各类推荐问题转化为Text-to-Text Encoder-Decoder架构,建模成条件文本生成问题,并使用相同的语言模型损失来预训练,而不是每个任务用特定的损失函数。
训练使用instruction-based prompts,下游可以实现零少样本的泛化,泛化到其他领域或者未见过的item,以解决冷启问题。
2、p5模型的结构
2.1、p5模型对应的任务
常见的5类推荐任务(序列推荐、评分预测、推荐理由、评论、直接推荐)如下图所示:
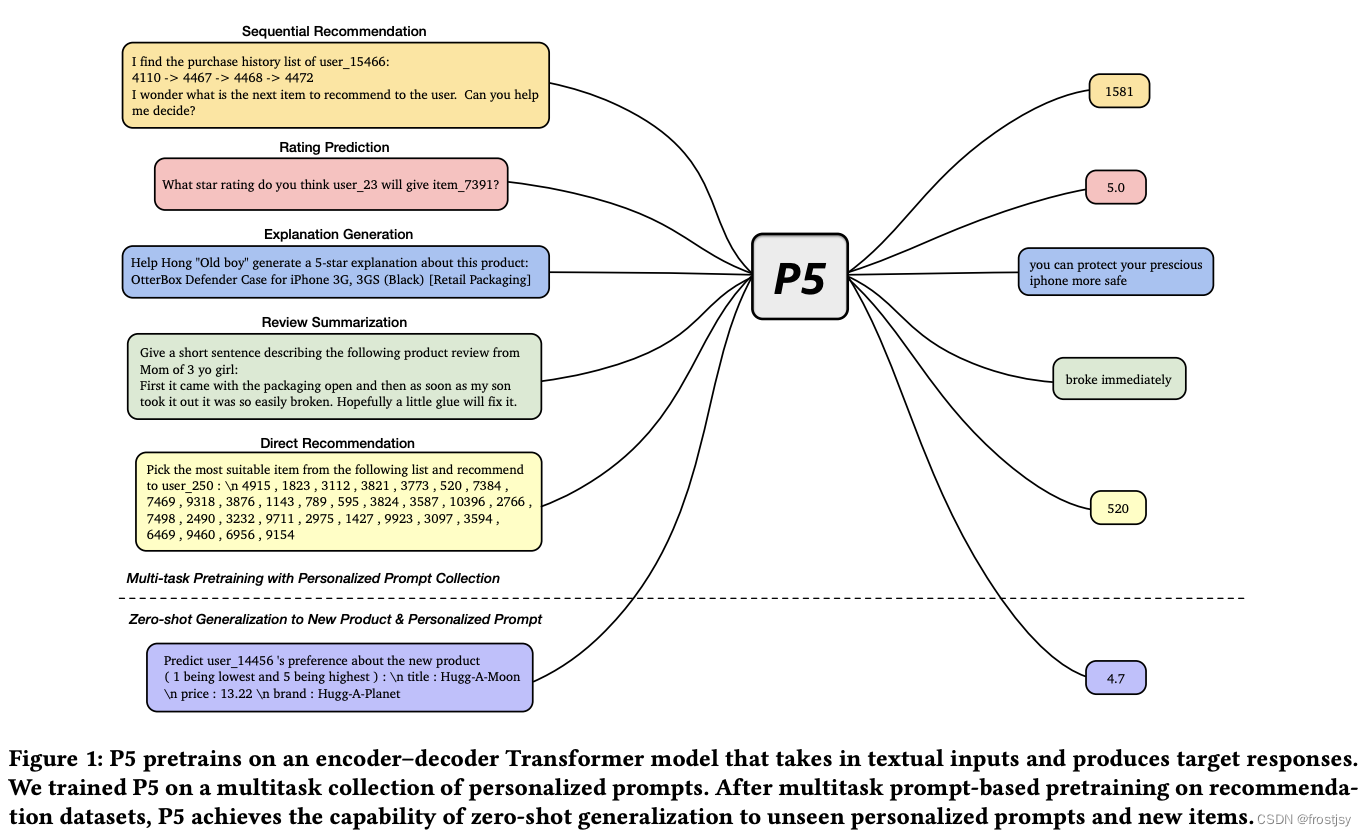 p5模型统一建模这5类任务,通过设计个性化prompt模版进行输入转换,转化为自然语言序列,作为encoder端的输入,再label进行prompt转化作为decoder的输出,通过seq2seq模型的损失函数进行预训练。下游应用时,给定目标输入,通过zero-shot的prompts模板进行输入转换,输入到encoder端进行编码,通过预训练好的decoder端进行解码,得到预测值,比如:下一次交互的item、评分、推荐理由、topK item ID等。
p5模型统一建模这5类任务,通过设计个性化prompt模版进行输入转换,转化为自然语言序列,作为encoder端的输入,再label进行prompt转化作为decoder的输出,通过seq2seq模型的损失函数进行预训练。下游应用时,给定目标输入,通过zero-shot的prompts模板进行输入转换,输入到encoder端进行编码,通过预训练好的decoder端进行解码,得到预测值,比如:下一次交互的item、评分、推荐理由、topK item ID等。
个性化prompts模板作为桥梁,沟通了推荐系统任务的原始样本(特征/label)到通用自然语言序列的转换。多任务预训练学习到了不同任务内特定的知识以及任务间的迁移知识。
2.2、p5模型模版构建
2.2.1、prompt三要素
每类任务都有对应的个性化prompts模板,每个prompt包含如下三大要素:
- 输入模板(输入样本):input template,Encoder端输入。
- 目标模板(label):target template,Decoder输出。
- 关联的元数据(user/item特征):associated metadata,Encoder端{花括号}部分需要替换的内容。
个性化prompt是指prompt模板中融入了user/item的特征,不同的user,其prompt是不一样的。
2.2.2、不同模版设计方式
5种任务的不同设计模版
- 评分预测任务:包含3类,(a)给定关于user和item的信息,直接预测评分(1~5);(b)预测user是否会对item产生评分,即:yes or no;(c)预测user对item是否喜欢(>4分喜欢,否则不喜欢)
- 序列推荐任务:包含3类,(a)直接基于交互历史,来预测下一次交互;(b)给定交互历史和候选item集合,从中选出某个item作为预测结果;(c)给定交互历史以及某个item,预测这个item用户是否下一次会进行交互。
- 推荐理由任务:包含2类,(a) 基于user和item的特征,直接生成推荐理由。(b) 将某个特征作为hint提示,生成推荐理由。
- 评论任务:包含2类,(a)对长评论进行摘要生成。(b)给定评论,预测对应的评分。
- 直接推荐:最常见的类型,类似TopK推荐。包含2类,(a) 预测是否要把某个item推荐给某个用户,yes or no。(b) 从候选集合中,选出某个item推荐给用户。
prompts任务推荐
五种任务的分类模版
评分预测任务
(a)给定关于user和item的信息,直接预测评分(1~5);

(b)预测user是否会对item产生评分,即:yes or no;

(c)预测user对item是否喜欢(>4分喜欢,否则不喜欢)

序列推荐任务
(a)直接基于交互历史,来预测下一次交互;

(b)给定交互历史和候选item集合,从中选出某个item作为预测结果;

(c)给定交互历史以及某个item,预测这个item用户是否下一次会进行交互。

推荐理由任务:
(a) 基于user和item的特征,直接生成推荐理由。
可能由于直接为生成任务,故而没有相应的模版
(b) 将某个特征作为hint提示,生成推荐理由。

直接推荐:
(a) 预测是否要把某个item推荐给某个用户,yes or no。

(b) 从候选集合中,选出某个item推荐给用户。

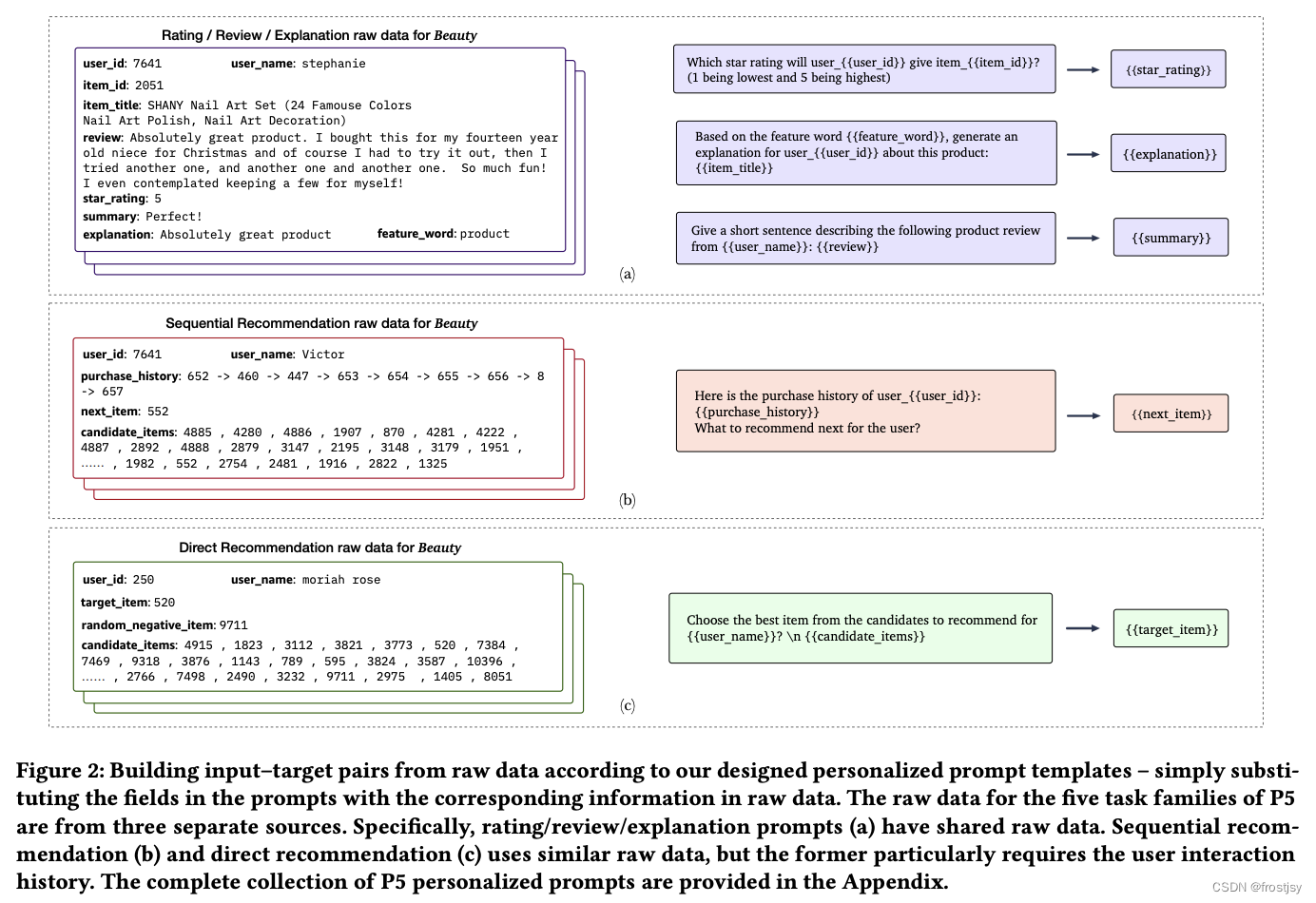
给定上述的prompts,很容易将推荐系统的原始输入数据转成input-target pairs,举几个从原始数据生成输入样本的例子。
如下图所示,最左侧是原始输入数据,包含user、item特征和推荐任务的label。中间是prompt模板,可以将花括号{}用具体的输入样本特征来替代,生成训练input-target pairs。右侧是target,用输入数据中的label来替换花括号。这样就能生成NLP任务encoder-decoder架构的输入-输出数据对。
3、模型结构
由于prompts的存在,所有任务的输入都巧妙地转换成了通用的自然语言序列,将各类任务之间的界限打破了,映射到统一的输入空间。在预训练的时候,将上述5种任务构造得到的input-target pairs全部混合起来喂给模型进行预训练。实际实现时,对每个raw data,会随机抽部分prompt模板进行输入样本的生成,保证泛化能力。在序列推荐和topK推荐的candidate items中,负样本会随机抽取。在这种多任务样本的预训练中,能够充分利用各类任务中蕴含的通用知识。下游应用时,即使是一些新颖、未见过的prompts或items,模型也能够很好地进行泛化和迁移。
3.1、模型整体架构
模型架构上采用了家喻户晓的Encoder-Decoder结构,核心组成是Transformers。
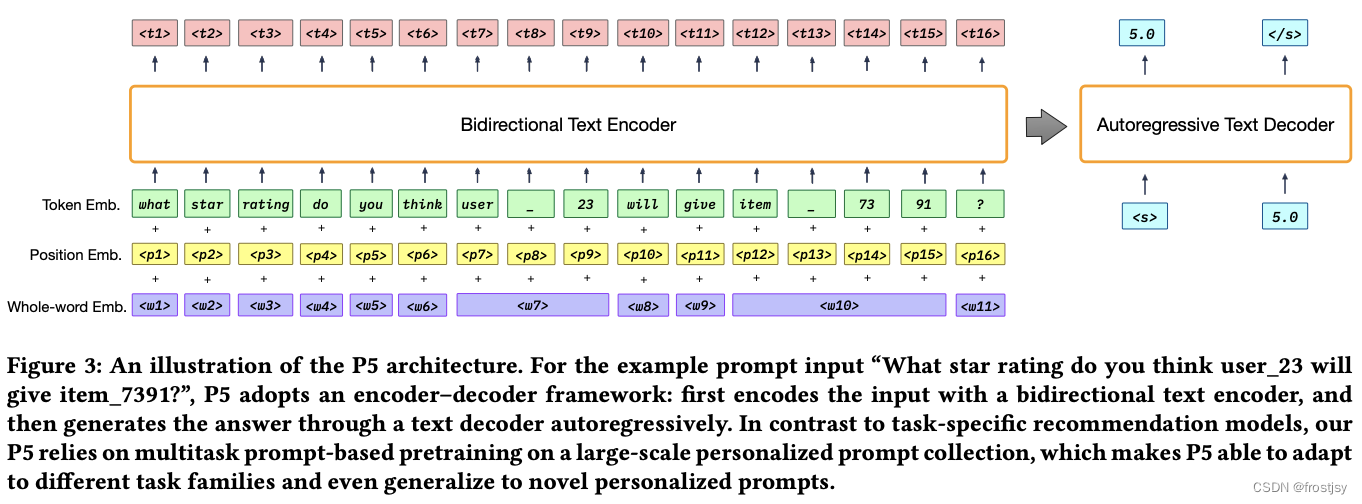 实际使用时,采用了T5预训练模型[5]。
实际使用时,采用了T5预训练模型[5]。
3.2、embedding输入层
Encoder的输入包括3个部分,token emb, position emb, whole-word emb,遵从类似BERT的输入范式。
- token emb,输入token序列表示为:,经过embedding。
- position emb,位置嵌入,建模位置和次序信息。
- whole-word emb,这个是文中提出的,主要为了解决可能把user/item侧的个性化特征切碎的问题,加入了整体的word表征。比如:item_7391是ID为7391的item,加个整体的embedding。实现上类似position emb,按顺序预留一个word idx embedding矩阵,根据输入中的需要进行查表。
三者加起来后作为Encoder的输入。这个部分实际上通过transformer来建模中蕴含的user特征、item特征、user/item交互特征。
3.2、encoder
采用的是transformers,可以对输入序列做双向attention。得到表征后的embedding序列,
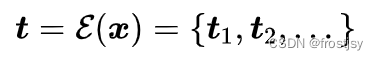
3.3、Decoder
自回归decoder,允许对输入序列、已经解码的输出端序列做attention,并预测下一步的token。即:
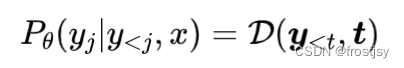
3.4、loss损失函数
预训练的学习目标是label tokens的负对数似然损失,训练样本是所有5种推荐任务混合起来的样本。
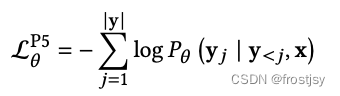
模型层面非常简洁,用one data format, one model, one loss来建模multi-task。
4、下游任务预测
对于序列任务
预训练完后,可以直接应用在下游任务中,做zero-shot和few-shot。对于评分预测/推荐理由/评论任务,采用贪心算法进行解码即可。序列推荐和topk推荐通常需要输出一个item list,采用beam search来产生潜在topk结果。BeamSearch形式化如下:
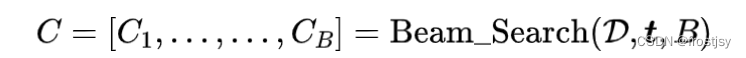
BeamSearch输入为Decoder,Encoder的输出序列t和搜索的窗口大小B,输出预测的topk序列C。
预测方式
两种预测方式,一种是使用和预训练一致的prompt模版,另一种是使用一种新的prompt模版,体现预训练模型的泛化能力
后者实际上就对应着模型的强大泛化能力,比如给一个新的item和描述元信息,让模型来预测,实现item的冷启动;或者给定一个其它domain的测试样本做映射,让模型来预测,实现了跨域迁移学习。非常巧妙。
5、实验对比
5.1、数据集
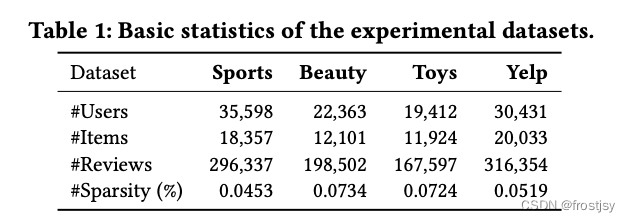
对四个真实世界的数据集进行了广泛的实验。 Amazon数据集是从 Amazon.com 平台收集的,其中包含用户对 29 类产品的评分和评论。在本文中,我们采用其中三个来评估我们的方法,即运动和户外、美容以及玩具和游戏
5.2、实验对比
比如评分预测的MF、序列推荐的GRU4REC、BERT4REC等。预训练模型采用的是T5,包括base和small两个checkpoint,分别对应P5-B和P5-S。比如实验中的P5-S(1-6)代表用small T5版本的预训练模型做参数初始化,用第1~6种prompts做样本生成。各类任务对比实验指标如下:
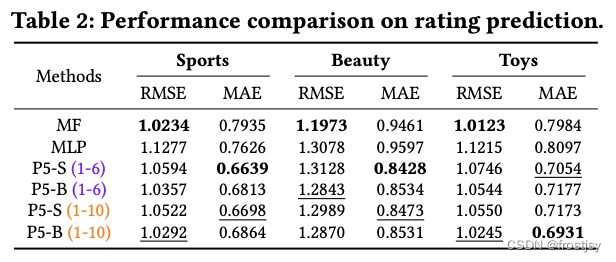
5.2.1、评分任务的对比
rmse(Root Mean Squard Error):均方根误差
MAE :MAE(平均绝对误差)
5.2.2、序列推荐任务的对比
Caser(卡瑟):将顺序推荐视为马尔可夫链并采用 卷积神经网络来模拟用户兴趣。
HGN:采用分层门控网络来学习用户行为 长期和短期的信息
GRU4Rec :利用 GRU 对用户点击历史序列进行建模
BERT4Rec :模仿 BERT风格的掩码语言建模并学习用于序列推荐的双向表示
FDSA:通过self-attention 模块focus on序列转化
SASRec:在序列推荐模型中采用自注意力机制,该模型调和马尔可夫链和基于 RNN 的方法的属性。
S3-Rec: 利用self-supervised(自监督)目标来帮助 顺序推荐模型更好地发现不同item及其属性之间的相关性。

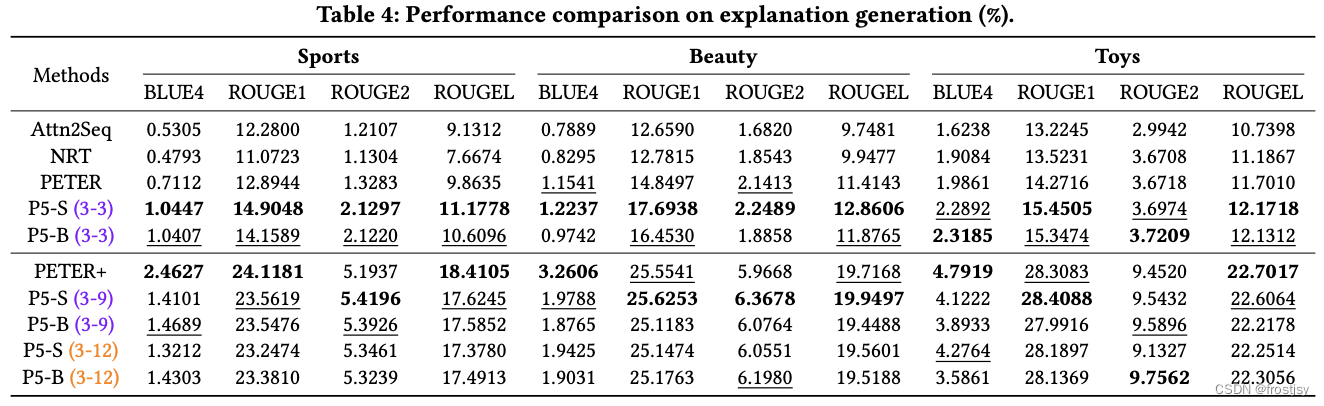
5.2.3、推荐理由任务的对比
5.2.4、评论任务
评论预测
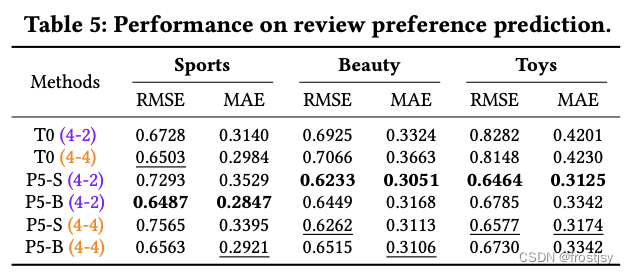
评论总结

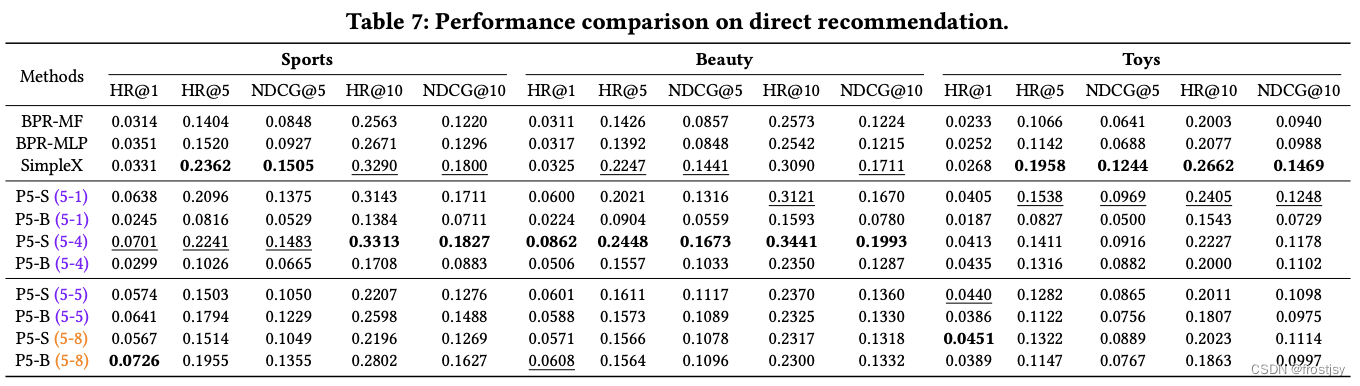
5.2.5、直接推荐
参考文献
P5 | NLP模型一统推荐系统? 谈新型推荐系统建模范式 (P5 | NLP模型一统推荐系统? 谈新型推荐系统建模范式)
https://arxiv.org/pdf/2203.13366.pdf 论文地址