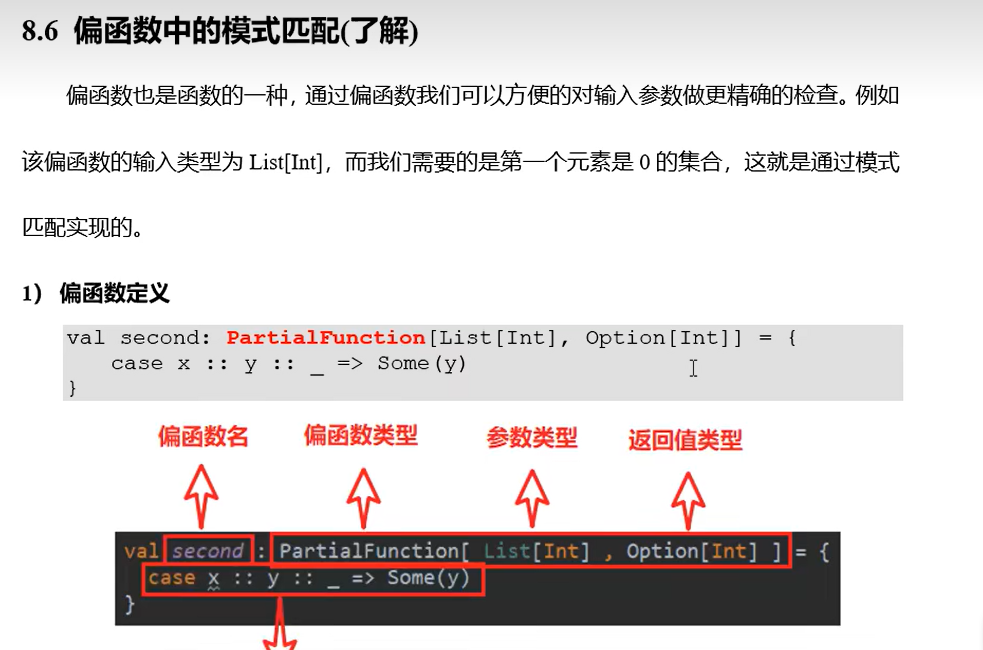
Xpath介绍
XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。 XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。 起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。
Xpath语法
祖先节点:父节点的父节点,例如html为所有标签的祖先或父节点。
父节点:为当前节点的上一层节点元素。(直接相邻)
当前节点:当前节点可以有0-n个子节点的元素。
兄弟(同胞节点):跟当前节点同一个父节点的元素。
具体如图所示。

| node_name | 选取此节点的所有子节点。例如为div或者为tr |
| / | 选取根节点。(如果字符串开始为/,即为从跟开始) |
| // | 从匹配选择的当前节点中选择文档中的节点。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
1. 根据对应的层级关系去逐层寻找或者是跨层寻找元素(假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!)
element = response_etree.xpath('//div[@xxx="xxx"]')
# 在多个层级目录下去寻找div标签,//表示多个层级目录
element = response_etree.xpath('/div[@xxx="xxx"]')
# 在当前层级目录下去寻找div标签,/表示在当前层级进行寻找2.根据属性去定位元素
element = response_etree.xpath('//div[@class="xxxx"]')
# 根据属性去获取元素
element = response_etree.xpath('//div[@id="xiaoming"]/div[7]//text()')
# 在整个html文本中去寻找id为xiaoming的div下的第7个div的所有层级的文本3.根据位置定位去定位元素,起始序号为1。
element = response_etree.xpath('//div[7]')
# 个根据属性去获取html根节点的第七个div元素4.根据运算表达式去定位元素
常用的只有|(合并节点)
element = response_etree.xpath('//div[4|6]')
# 个根据属性去获取html根节点的第4和第6个div元素5. 如果不确定属性的话可以用通配符*代替,但一般不常用,因为有可能获取的元素不为我们想要的元素
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
具体例子如图所示。
element = response_etree.xpath('//*[@id="xxx"]')
# 获取带有id="xxx"的任何标签,
element = response_etree.xpath('//div[@*="xxx"]')
# 获取带有任何"xxx"属性的div标签Xpath获取文本或属性
text = response_etree.xpath('//div//div//text()')
# text()会获取字符组成一个列表返回,
# //text()表示取当前节点及其子孙节点中的文本内容,/text为返回当前节点的文本内容
text = response_etree.xpath('//div//div//string(.)')
# string(.)会把当前节点和所有的子孙节点中的文本全部提取出来,组合成一个字符串