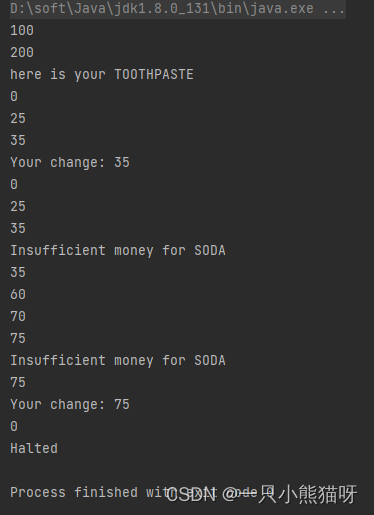
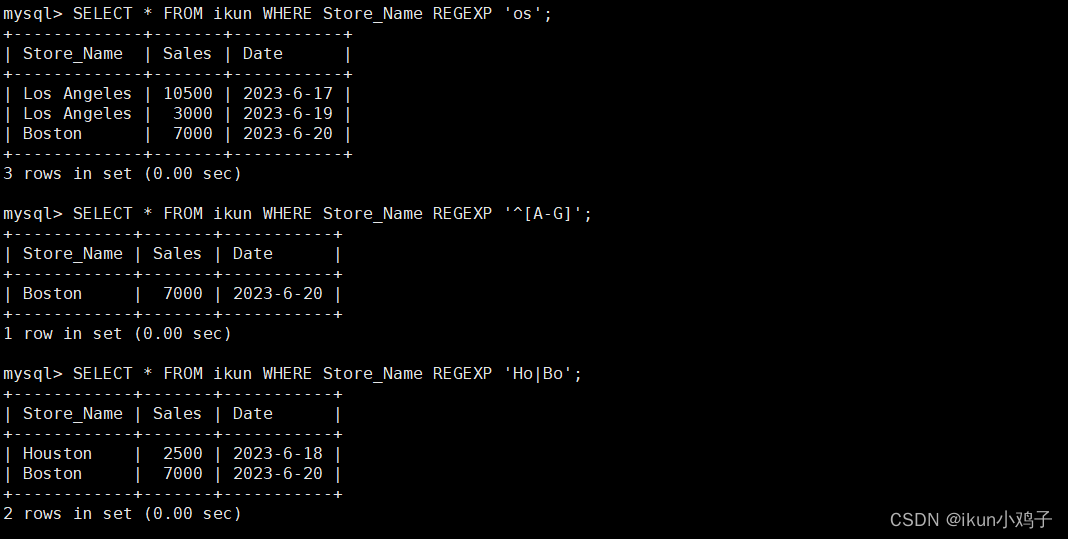
来自B站视频,API查阅,TORCH.NN
- RNN可以处理变长序列,是因为其每个时刻的参数是共享的
- RNN每算出一个时刻都可以输出,适合流式输出,但串行计算比较慢,无法获取太长的历史信息
- RNN 初始隐状态不提供默认是0,输出包括两部分:所有时刻的输出 (batch_size,seq_len,out_hidden_size*num_direction) 和 最后一个时刻的隐状态 (num_layers*num_direction,batch_size,out_hidden_size)。竖向的是第一个元素,横向的是最后一个元素。即实际上第一个输出的最后一个元素就是第二个元素(冗余的)
这里的RNN没有提供 O t = H t W h q + b q O_t=H_tW_{hq}+b_q Ot=HtWhq+bq,输出只是 H t H_t Ht
- LSTM 中 指定 proj_size 后是 LSTM 的一个变体,hidden_size 会经过 W h r W_{hr} Whr 压缩成 proj_size,减少了模型参数添加链接描述
- LSTM 的输入比 RNN 多了 C,如果不提供默认C 和 H 都是全0,输入的时候如果是多层或者双向,h的第一个维度不是1,需要1的话可以h.unsqueeze(0)
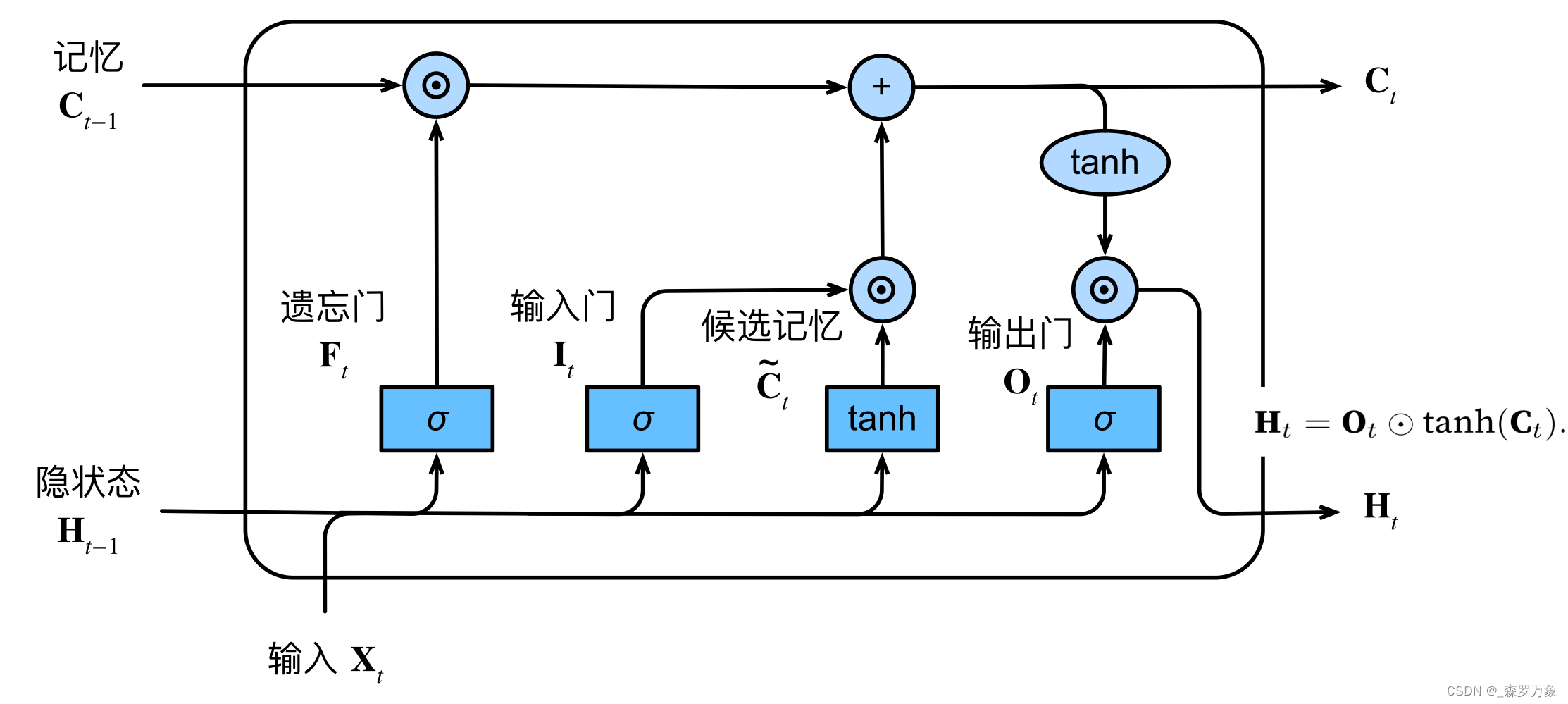
- F t , I t , O t F_t,I_t,O_t Ft,It,Ot都是直接通过 X t , H t − 1 X_t,H_{t-1} Xt,Ht−1得到,激活函数是 σ \sigma σ, C ~ t \tilde C_t C~t 也是 X t , H t − 1 X_t,H_{t-1} Xt,Ht−1得到,激活函数是 t a n h tanh tanh,计算的时候可以四个 W concat 起来做矩阵乘法然后需要的时候用切片截取,计算并行性好
- C t = F t ⊙ C t − 1 + I ⊙ C ~ t C_t=F_t\odot C_{t-1}+I\odot \tilde C_t Ct=Ft⊙Ct−1+I⊙C~t, H t = O t ⊙ t a n h ( C t ) H_t=O_t\odot tanh(C_t) Ht=Ot⊙tanh(Ct)
- GRU 的参数和计算量只是 LSTM 的 3/4
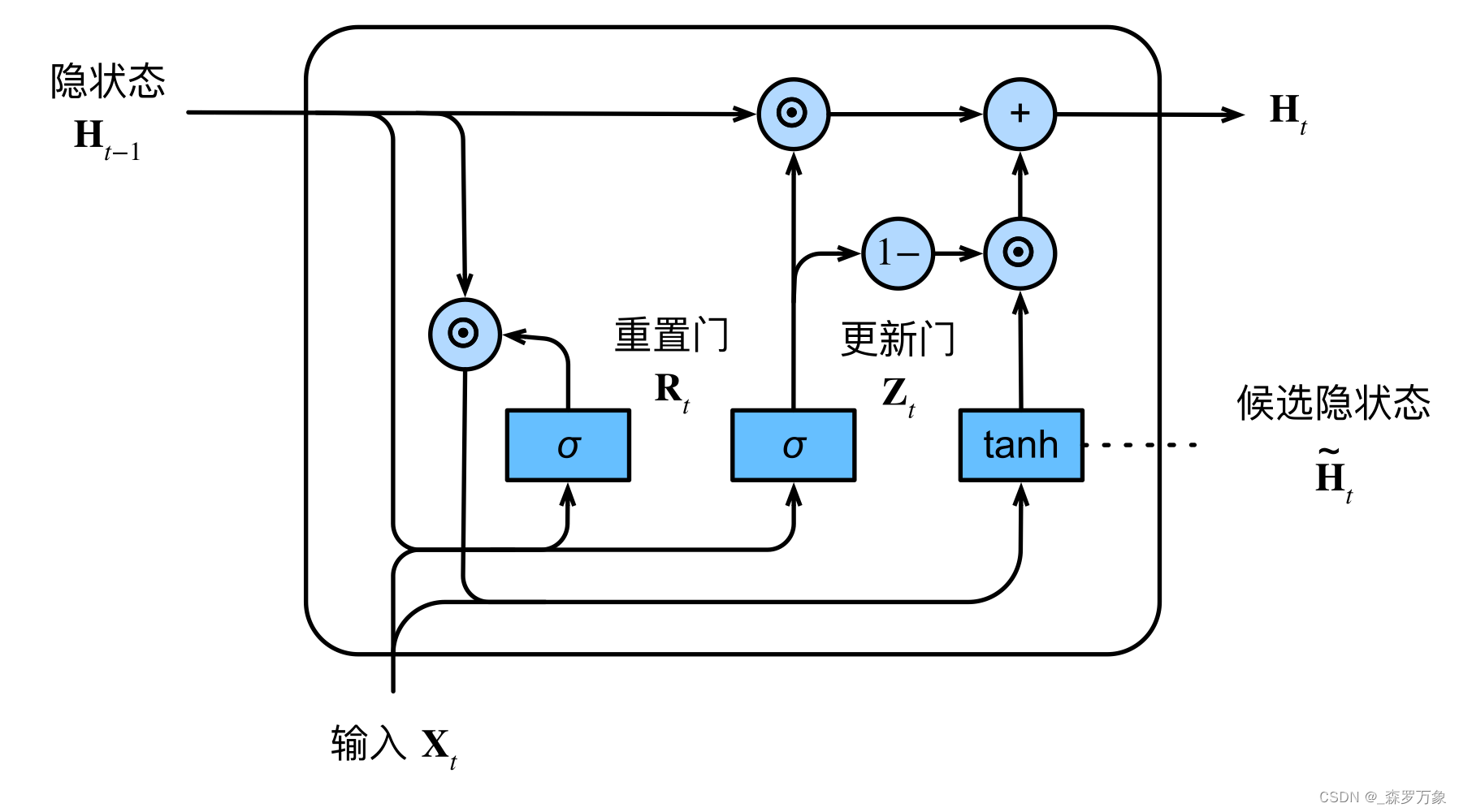
- R t , Z t R_t,Z_t Rt,Zt都是直接通过 X t , H t − 1 X_t,H_{t-1} Xt,Ht−1得到
- H ~ t = t a n h ( X t W x h + ( R t ⊙ H t − 1 ) W h h + b h ) \tilde H_t=tanh(X_tW_{xh}+(R_t\odot H_{t-1})W_{hh}+b_h) H~t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)
- H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t H_t=Z_t\odot H_{t-1}+(1-Z_t)\odot \tilde H_t Ht=Zt⊙Ht−1+(1−Zt)⊙H~t