作者:Emily McAlister

组织越来越依赖数据来做出有效的、基于证据的决策来推动业务成果。 无论是评估市场状况和改善客户体验、确保应用程序正常运行时间还是保护组织安全,来自多个来源(包括消费者和内部系统)的数据对于日常运营都至关重要。
这种数据驱动的方法要求组织快速收集、存储和分析大量数据,以便及时做出决策。 通常,这意味着大规模地跨多个来源和不同复杂程度的格式进行关联和分析。
Elasticsearch® 提供了摄取、存储和搜索这些数据集的可扩展性和灵活性,以便从业务、可观察性和安全角度找到相关且可操作的见解。 然而,随着越来越多的数据被摄取,如果不考虑利用 Elasticsearch 平台实现的数据架构和结构,它可能会变得笨重且昂贵。
使用 Elastic 解决常见数据挑战
作为一名 Elastic 顾问,我帮助许多客户加入多个数据源,这些数据源经过转换和关联,为业务决策、平台可用性和安全性提供支持。 以下是我帮助组织解决的一些挑战,特别是那些拥有多种数据源的挑战:
- 按数据源对摄取量进行归因:如果没有适当的标签/标记策略和执行,这可能会很棘手。
- 跨多个数据源的分析和关联:由于每个数据集中存在冲突的字段名称(例如,host_name、host.name、name),这通常很困难。
- 存储成本:有时我会发现由于索引设计和对所摄取数据源的理解不周,导致无法利用存储分层。 有时我还发现客户不知道新的、节省成本的功能。
数据架构的开发和文档化通过组织内数据源的规划和设计来解决上述挑战。 数据架构详细介绍了如何收集、处理和存储数据以供组织内的系统和人员使用的策略和标准。 一旦定义完毕,以下四种工具可用于使用 Elastic Stack 在技术层解决这些挑战。
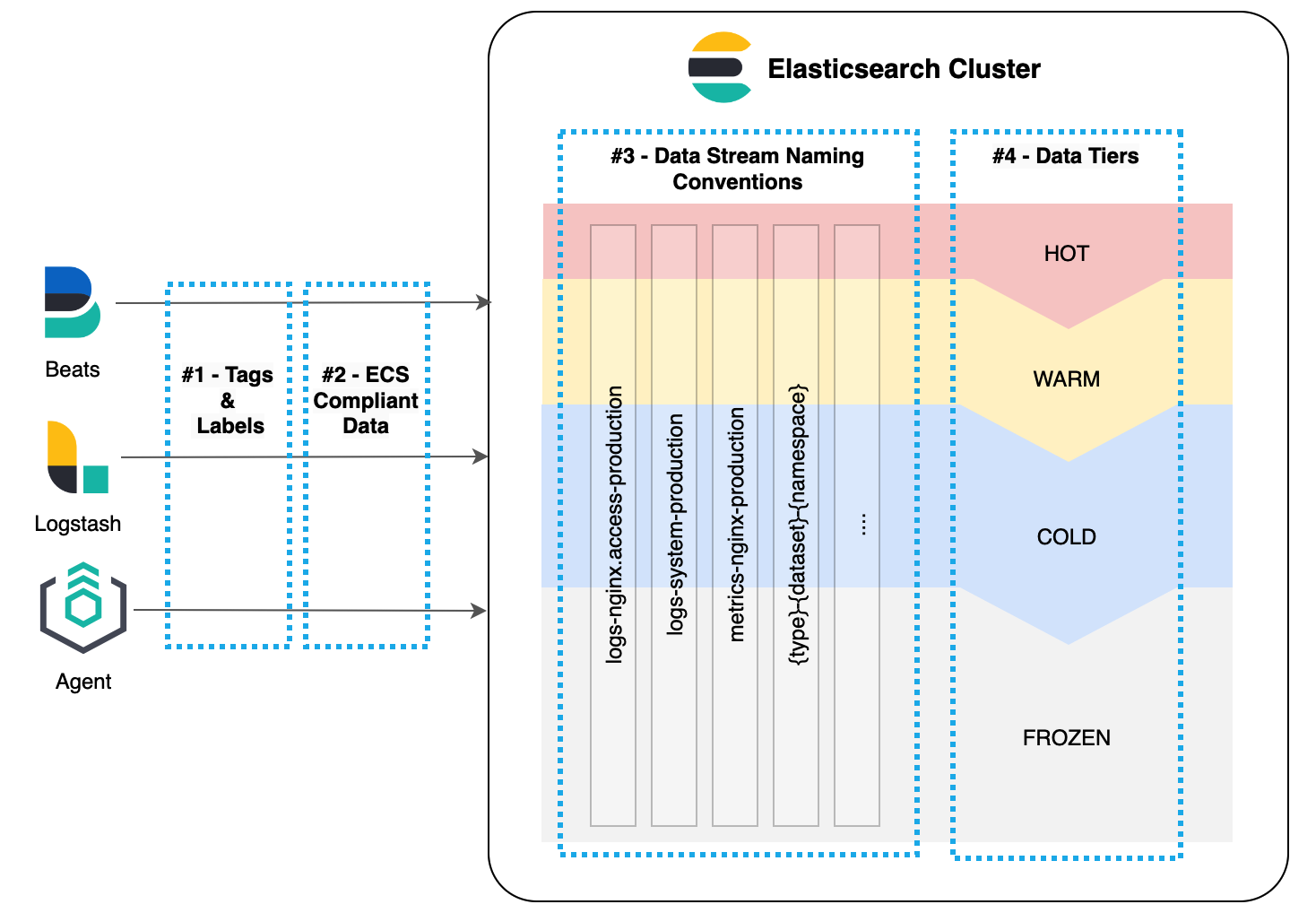
1. 标记和标签
Agent、Beats 和 Logstash® 等 Elastic Stack 摄取工具都提供添加自定义标记和标签的功能,使每个文档在存储在 Elasticsearch 中后可以轻松识别。 与组织的数据架构保持一致的标记或标签标准可以清晰地说明如何处理数据源。
通过过滤特定标签来快速分离数据源,可以准确、快速地识别数据源。 这减少了重要数据管理所需的时间,例如容量规划、分析摄取量或在索引之间迁移数据源。
对于在多个团队之间共享 Elastic 部署的某些客户,可以使用符合特定消费者群体的标准轻松报告退款/许可证消耗数据的归属。 在高级情况下,标记和标签还可用于支持基于角色的访问控制的文档级安全性。
使用标记和标签标准还可以减少为跨多个数据源的应用程序或系统开发可视化和执行调查活动的时间。
2. Elastic 通用模式
如果跨数据源的字段命名不一致,则跨数据集的关联会变得更加复杂。 这种不一致可能会导致跨多个字段的复杂查询,这些字段都表示相同的信息(例如,host.name: "serverA" 或 host_name: "serverA" 或 name: "serverA")。
Elastic Common Schema (ECS) 提供了在 Elasticsearch 中存储基于事件的数据的标准蓝图。 默认情况下,Elastic 的集成和摄取工具(Agent、Beats 和 Logstash)遵循此标准,以跨多个数据源提供一致的字段名称和数据类型。 这使得你可以轻松查询所有数据,从而使组织能够利用预构建的开箱即用仪表板和我们的一站式解决方案,例如 Elastic Observability 和 Elastic Security。
ECS 补充了组织的数据架构,并且可以作为基础层来协助捕获每个数据源的一组通用标准字段,从而回答 “这个源为我提供了哪些数据?” 的问题。
事实上,ECS 已被 OpenTelemetry 项目接受,使用户在日志记录、分布式跟踪、指标和安全事件方面受益。
了解有关 Elastic Common Schema 优势的更多信息。
3. 数据流约定
Elastic 在 7.9 版本中引入了数据流,作为管理可观测性和安全性用例的时间序列数据的改进方法。 作为此功能的一部分,引入了命名方案,通过引入以下内容来更好地管理索引层的数据集:
- type:描述数据的通用类型
- dataset:描述摄取的数据及其结构
- namespace:用户可配置的任意分组
这三个部分通过 “-” 组合在一起,产生像 logs-nginx.access-Production 这样的数据流。 这意味着所有数据流都按以下方式命名:
{type}-{dataset}-{namespace}特别是,命名空间选项的使用为组织提供了一种灵活的方法,可以根据数据架构所需的方式组织和存储数据。
阅读有关数据流的更多信息。
4. 数据层
Elasticsearch 提供了跨不同硬件配置文件传播数据的能力,以平衡数据存储的保留和基础设施成本。 随着数据老化,可以使用更便宜且性能较低的层来降低存储成本,同时保留对数据的访问。 这是通过使用数据流和索引生命周期管理策略以及在不同数据层之间自动移动数据的工具来完成的。
数据架构提供了正在摄取的数据源以及如何将它们存储在 Elasticsearch 中的清晰总体图景。 这是一个关键输入,可用于在 Elasticsearch 集群中设计可扩展的分层存储结构,以满足组织内的各种数据源和用例。
例如,某些安全用例需要长期存储日志,在这种情况下,冷层或冻结层应被视为一种具有成本效益的解决方案,它不仅可以保留数据,而且可以在出现以下情况时轻松搜索数据: 一项调查。 然而,对于可观察性用例,许多代理和 APM 数据源需要快速的热层来进行立即调查,以快速解决或通知任何性能问题。
阅读有关使用数据层管理数据的更多信息。
总之
上述注意事项将帮助您避免一些常见陷阱并从 Elastic 部署中实现更多价值:
- 标签和标记以及数据流命名约定使组织能够轻松地按数据源保护、聚合和过滤数据,以进行分析和管理。
- Elastic Common Schema 合规性使组织能够利用统包解决方案,使跨多个源的数据关联变得简单、无缝。
- 可扩展的数据层提供了可扩展的解决方案,可优化存储成本以增加数据量,使组织能够在不牺牲速度的情况下存储所需的数据。
开始免费试用 Elastic Cloud 14 天,了解如何应用这些工具。