深度学习(23)——YOLO系列(2)
文章目录
- 深度学习(23)——YOLO系列(2)
- 1. model
- 2. dataset
- 3. utils
- 4. test/detect
- 5. detect全过程
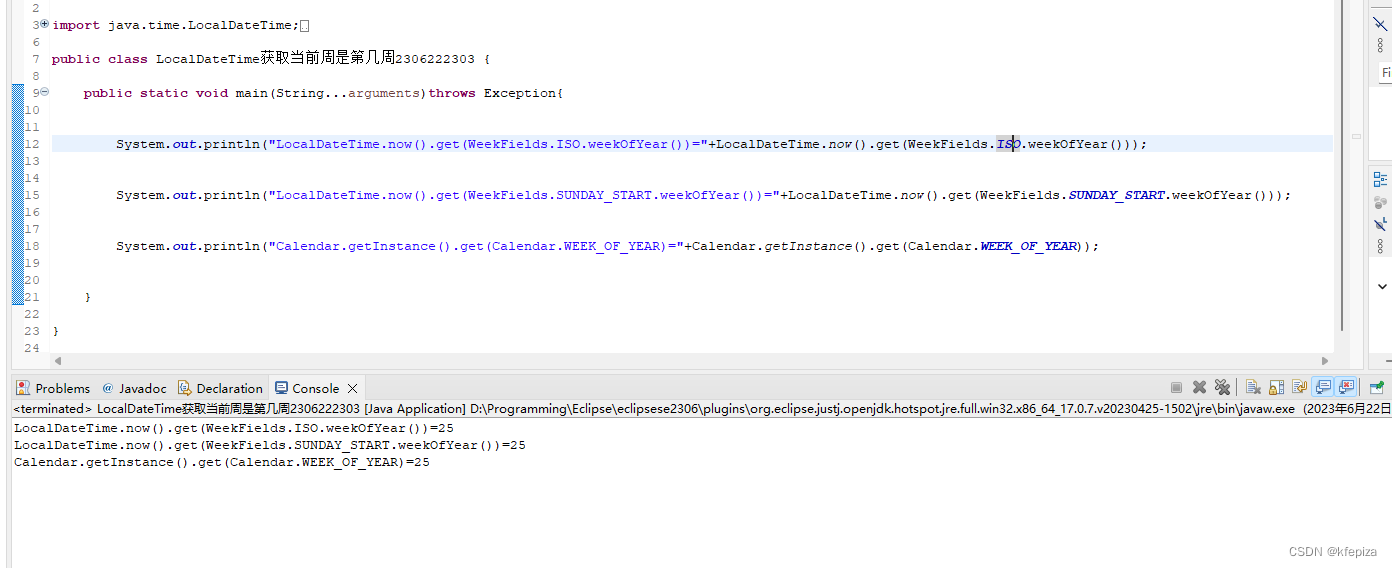
今天先写YOLO v3的代码,后面再出v5,v7。
特此说明:训练使用的COCO数据量太大了,我不想下载,我就直接用test做测试了,但是里面的代码核心还是一样的。当然我会把train的代码也放在这里大家可以用在自己的数据上训练。
1. model
model.py
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import numpy as np
from utils.parse_config import *
from utils.utils import build_targets, to_cpu, non_max_suppression
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def create_modules(module_defs):
"""
Constructs module list of layer blocks from module configuration in module_defs
"""
hyperparams = module_defs.pop(0)
output_filters = [int(hyperparams["channels"])]
module_list = nn.ModuleList()
for module_i, module_def in enumerate(module_defs):
modules = nn.Sequential()
if module_def["type"] == "convolutional":
bn = int(module_def["batch_normalize"])
filters = int(module_def["filters"])
kernel_size = int(module_def["size"])
pad = (kernel_size - 1) // 2
modules.add_module(
f"conv_{module_i}",
nn.Conv2d(
in_channels=output_filters[-1],
out_channels=filters,
kernel_size=kernel_size,
stride=int(module_def["stride"]),
padding=pad,
bias=not bn,
),
)
if bn:
modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(filters, momentum=0.9, eps=1e-5))
if module_def["activation"] == "leaky":
modules.add_module(f"leaky_{module_i}", nn.LeakyReLU(0.1))
elif module_def["type"] == "maxpool":
kernel_size = int(module_def["size"])
stride = int(module_def["stride"])
if kernel_size == 2 and stride == 1:
modules.add_module(f"_debug_padding_{module_i}", nn.ZeroPad2d((0, 1, 0, 1)))
maxpool = nn.MaxPool2d(kernel_size=kernel_size, stride=stride, padding=int((kernel_size - 1) // 2))
modules.add_module(f"maxpool_{module_i}", maxpool)
elif module_def["type"] == "upsample":
upsample = Upsample(scale_factor=int(module_def["stride"]), mode="nearest")
modules.add_module(f"upsample_{module_i}", upsample)
elif module_def["type"] == "route": # 输入1:26*26*256 输入2:26*26*128 输出:26*26*(256+128)
layers = [int(x) for x in module_def["layers"].split(",")]
filters = sum([output_filters[1:][i] for i in layers])
modules.add_module(f"route_{module_i}", EmptyLayer())
elif module_def["type"] == "shortcut":
filters = output_filters[1:][int(module_def["from"])]
modules.add_module(f"shortcut_{module_i}", EmptyLayer())
elif module_def["type"] == "yolo":
anchor_idxs = [int(x) for x in module_def["mask"].split(",")]
# Extract anchors
anchors = [int(x) for x in module_def["anchors"].split(",")]
anchors = [(anchors[i], anchors[i + 1]) for i in range(0, len(anchors), 2)]
anchors = [anchors[i] for i in anchor_idxs]
num_classes = int(module_def["classes"])
img_size = int(hyperparams["height"])
# Define detection layer
yolo_layer = YOLOLayer(anchors, num_classes, img_size)
modules.add_module(f"yolo_{module_i}", yolo_layer)
# Register module list and number of output filters
module_list.append(modules)
output_filters.append(filters)
return hyperparams, module_list
class Upsample(nn.Module):
""" nn.Upsample is deprecated """
def __init__(self, scale_factor, mode="nearest"):
super(Upsample, self).__init__()
self.scale_factor = scale_factor
self.mode = mode
def forward(self, x):
x = F.interpolate(x, scale_factor=self.scale_factor, mode=self.mode)
return x
class EmptyLayer(nn.Module):
"""Placeholder for 'route' and 'shortcut' layers"""
def __init__(self):
super(EmptyLayer, self).__init__()
class YOLOLayer(nn.Module):
"""Detection layer"""
def __init__(self, anchors, num_classes, img_dim=416):
super(YOLOLayer, self).__init__()
self.anchors = anchors
self.num_anchors = len(anchors)
self.num_classes = num_classes
self.ignore_thres = 0.5
self.mse_loss = nn.MSELoss()
self.bce_loss = nn.BCELoss()
self.obj_scale = 1
self.noobj_scale = 100
self.metrics = {}
self.img_dim = img_dim
self.grid_size = 0 # grid size
def compute_grid_offsets(self, grid_size, cuda=True):
self.grid_size = grid_size
g = self.grid_size
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
self.stride = self.img_dim / self.grid_size
# Calculate offsets for each grid
self.grid_x = torch.arange(g).repeat(g, 1).view([1, 1, g, g]).type(FloatTensor)
self.grid_y = torch.arange(g).repeat(g, 1).t().view([1, 1, g, g]).type(FloatTensor)
self.scaled_anchors = FloatTensor([(a_w / self.stride, a_h / self.stride) for a_w, a_h in self.anchors])
self.anchor_w = self.scaled_anchors[:, 0:1].view((1, self.num_anchors, 1, 1))
self.anchor_h = self.scaled_anchors[:, 1:2].view((1, self.num_anchors, 1, 1))
def forward(self, x, targets=None, img_dim=None):
# Tensors for cuda support
print (x.shape)
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
ByteTensor = torch.cuda.ByteTensor if x.is_cuda else torch.ByteTensor
self.img_dim = img_dim
num_samples = x.size(0)
grid_size = x.size(2)
prediction = (
x.view(num_samples, self.num_anchors, self.num_classes + 5, grid_size, grid_size)
.permute(0, 1, 3, 4, 2)
.contiguous()
)
print (prediction.shape)
# Get outputs
x = torch.sigmoid(prediction[..., 0]) # Center x
y = torch.sigmoid(prediction[..., 1]) # Center y
w = prediction[..., 2] # Width
h = prediction[..., 3] # Height
pred_conf = torch.sigmoid(prediction[..., 4]) # Conf
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
# If grid size does not match current we compute new offsets
if grid_size != self.grid_size:
self.compute_grid_offsets(grid_size, cuda=x.is_cuda) #相对位置得到对应的绝对位置比如之前的位置是0.5,0.5变为 11.5,11.5这样的
# Add offset and scale with anchors #特征图中的实际位置
pred_boxes = FloatTensor(prediction[..., :4].shape)
pred_boxes[..., 0] = x.data + self.grid_x
pred_boxes[..., 1] = y.data + self.grid_y
pred_boxes[..., 2] = torch.exp(w.data) * self.anchor_w
pred_boxes[..., 3] = torch.exp(h.data) * self.anchor_h
output = torch.cat(
(
pred_boxes.view(num_samples, -1, 4) * self.stride, #还原到原始图中
pred_conf.view(num_samples, -1, 1),
pred_cls.view(num_samples, -1, self.num_classes),
),
-1,
)
if targets is None:
return output, 0
else:
iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf = build_targets(
pred_boxes=pred_boxes,
pred_cls=pred_cls,
target=targets,
anchors=self.scaled_anchors,
ignore_thres=self.ignore_thres,
)
# iou_scores:真实值与最匹配的anchor的IOU得分值 class_mask:分类正确的索引 obj_mask:目标框所在位置的最好anchor置为1 noobj_mask obj_mask那里置0,还有计算的iou大于阈值的也置0,其他都为1 tx, ty, tw, th, 对应的对于该大小的特征图的xywh目标值也就是我们需要拟合的值 tconf 目标置信度
# Loss : Mask outputs to ignore non-existing objects (except with conf. loss)
loss_x = self.mse_loss(x[obj_mask], tx[obj_mask]) # 只计算有目标的
loss_y = self.mse_loss(y[obj_mask], ty[obj_mask])
loss_w = self.mse_loss(w[obj_mask], tw[obj_mask])
loss_h = self.mse_loss(h[obj_mask], th[obj_mask])
loss_conf_obj = self.bce_loss(pred_conf[obj_mask], tconf[obj_mask])
loss_conf_noobj = self.bce_loss(pred_conf[noobj_mask], tconf[noobj_mask])
loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj #有物体越接近1越好 没物体的越接近0越好
loss_cls = self.bce_loss(pred_cls[obj_mask], tcls[obj_mask]) #分类损失
total_loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls #总损失
# Metrics
cls_acc = 100 * class_mask[obj_mask].mean()
conf_obj = pred_conf[obj_mask].mean()
conf_noobj = pred_conf[noobj_mask].mean()
conf50 = (pred_conf > 0.5).float()
iou50 = (iou_scores > 0.5).float()
iou75 = (iou_scores > 0.75).float()
detected_mask = conf50 * class_mask * tconf
precision = torch.sum(iou50 * detected_mask) / (conf50.sum() + 1e-16)
recall50 = torch.sum(iou50 * detected_mask) / (obj_mask.sum() + 1e-16)
recall75 = torch.sum(iou75 * detected_mask) / (obj_mask.sum() + 1e-16)
self.metrics = {
"loss": to_cpu(total_loss).item(),
"x": to_cpu(loss_x).item(),
"y": to_cpu(loss_y).item(),
"w": to_cpu(loss_w).item(),
"h": to_cpu(loss_h).item(),
"conf": to_cpu(loss_conf).item(),
"cls": to_cpu(loss_cls).item(),
"cls_acc": to_cpu(cls_acc).item(),
"recall50": to_cpu(recall50).item(),
"recall75": to_cpu(recall75).item(),
"precision": to_cpu(precision).item(),
"conf_obj": to_cpu(conf_obj).item(),
"conf_noobj": to_cpu(conf_noobj).item(),
"grid_size": grid_size,
}
return output, total_loss
class Darknet(nn.Module):
"""YOLOv3 object detection model"""
def __init__(self, config_path, img_size=416):
super(Darknet, self).__init__()
self.module_defs = parse_model_config(config_path)
self.hyperparams, self.module_list = create_modules(self.module_defs)
self.yolo_layers = [layer[0] for layer in self.module_list if hasattr(layer[0], "metrics")]
self.img_size = img_size
self.seen = 0
self.header_info = np.array([0, 0, 0, self.seen, 0], dtype=np.int32)
def forward(self, x, targets=None):
img_dim = x.shape[2]
loss = 0
layer_outputs, yolo_outputs = [], []
for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
if module_def["type"] in ["convolutional", "upsample", "maxpool"]:
x = module(x)
elif module_def["type"] == "route":
x = torch.cat([layer_outputs[int(layer_i)] for layer_i in module_def["layers"].split(",")], 1)
elif module_def["type"] == "shortcut": # 残差连接(位相加)
layer_i = int(module_def["from"])
x = layer_outputs[-1] + layer_outputs[layer_i]
elif module_def["type"] == "yolo":
x, layer_loss = module[0](x, targets, img_dim)
loss += layer_loss
yolo_outputs.append(x)
layer_outputs.append(x)
yolo_outputs = to_cpu(torch.cat(yolo_outputs, 1))
return yolo_outputs if targets is None else (loss, yolo_outputs)
def load_darknet_weights(self, weights_path):
"""Parses and loads the weights stored in 'weights_path'"""
# Open the weights file
with open(weights_path, "rb") as f:
header = np.fromfile(f, dtype=np.int32, count=5) # First five are header values
self.header_info = header # Needed to write header when saving weights
self.seen = header[3] # number of images seen during training
weights = np.fromfile(f, dtype=np.float32) # The rest are weights
# Establish cutoff for loading backbone weights
cutoff = None
if "darknet53.conv.74" in weights_path:
cutoff = 75
ptr = 0
for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
if i == cutoff:
break
if module_def["type"] == "convolutional":
conv_layer = module[0]
if module_def["batch_normalize"]:
# Load BN bias, weights, running mean and running variance
bn_layer = module[1]
num_b = bn_layer.bias.numel() # Number of biases
# Bias
bn_b = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.bias)
bn_layer.bias.data.copy_(bn_b)
ptr += num_b
# Weight
bn_w = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.weight)
bn_layer.weight.data.copy_(bn_w)
ptr += num_b
# Running Mean
bn_rm = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.running_mean)
bn_layer.running_mean.data.copy_(bn_rm)
ptr += num_b
# Running Var
bn_rv = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.running_var)
bn_layer.running_var.data.copy_(bn_rv)
ptr += num_b
else:
# Load conv. bias
num_b = conv_layer.bias.numel()
conv_b = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(conv_layer.bias)
conv_layer.bias.data.copy_(conv_b)
ptr += num_b
# Load conv. weights
num_w = conv_layer.weight.numel()
conv_w = torch.from_numpy(weights[ptr : ptr + num_w]).view_as(conv_layer.weight)
conv_layer.weight.data.copy_(conv_w)
ptr += num_w
def save_darknet_weights(self, path, cutoff=-1):
"""
@:param path - path of the new weights file
@:param cutoff - save layers between 0 and cutoff (cutoff = -1 -> all are saved)
"""
fp = open(path, "wb")
self.header_info[3] = self.seen
self.header_info.tofile(fp)
# Iterate through layers
for i, (module_def, module) in enumerate(zip(self.module_defs[:cutoff], self.module_list[:cutoff])):
if module_def["type"] == "convolutional":
conv_layer = module[0]
# If batch norm, load bn first
if module_def["batch_normalize"]:
bn_layer = module[1]
bn_layer.bias.data.cpu().numpy().tofile(fp)
bn_layer.weight.data.cpu().numpy().tofile(fp)
bn_layer.running_mean.data.cpu().numpy().tofile(fp)
bn_layer.running_var.data.cpu().numpy().tofile(fp)
# Load conv bias
else:
conv_layer.bias.data.cpu().numpy().tofile(fp)
# Load conv weights
conv_layer.weight.data.cpu().numpy().tofile(fp)
fp.close()
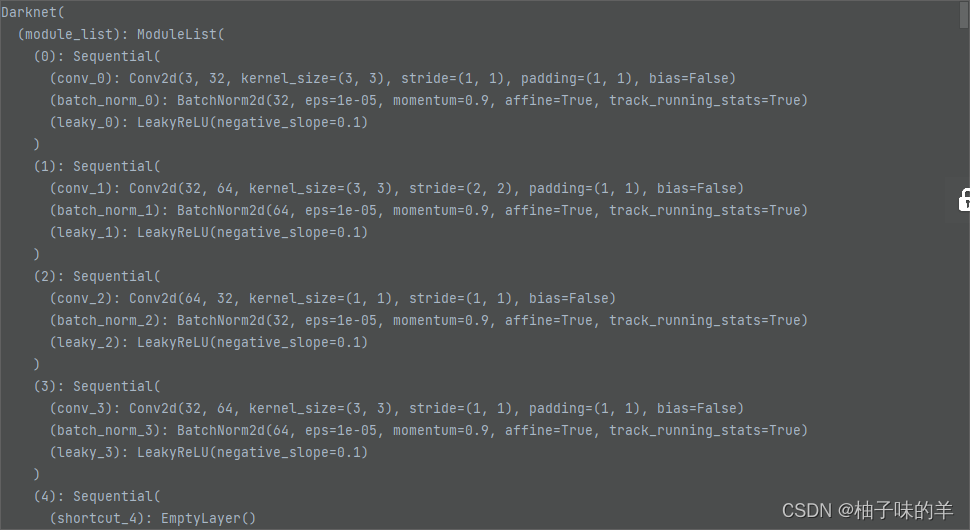
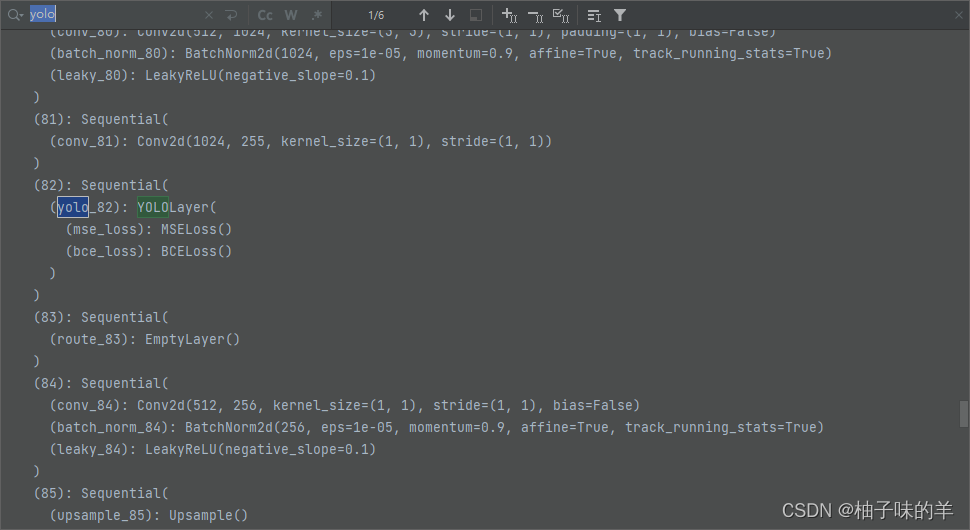
一共三个yolo层
模型定义这一块:叫做darknet,其中最重要的部分就是YOLO层。还有一个容易混淆的地方:route和shortcut层,前者是拼接,后者是残差连接的位相加。
2. dataset
dataset.py
import glob
import random
import os
import sys
import numpy as np
from PIL import Image
import torch
import torch.nn.functional as F
from utils.augmentations import horisontal_flip
from torch.utils.data import Dataset
import torchvision.transforms as transforms
def pad_to_square(img, pad_value):
c, h, w = img.shape
dim_diff = np.abs(h - w)
# (upper / left) padding and (lower / right) padding
pad1, pad2 = dim_diff // 2, dim_diff - dim_diff // 2
# Determine padding
pad = (0, 0, pad1, pad2) if h <= w else (pad1, pad2, 0, 0)
# Add padding
img = F.pad(img, pad, "constant", value=pad_value)
return img, pad
def resize(image, size):
image = F.interpolate(image.unsqueeze(0), size=size, mode="nearest").squeeze(0)
return image
def random_resize(images, min_size=288, max_size=448):
new_size = random.sample(list(range(min_size, max_size + 1, 32)), 1)[0]
images = F.interpolate(images, size=new_size, mode="nearest")
return images
class ImageFolder(Dataset):
def __init__(self, folder_path, img_size=416):
self.files = sorted(glob.glob("%s/*.*" % folder_path))
self.img_size = img_size
def __getitem__(self, index):
img_path = self.files[index % len(self.files)]
# Extract image as PyTorch tensor
img = transforms.ToTensor()(Image.open(img_path))
# Pad to square resolution
img, _ = pad_to_square(img, 0)
# Resize
img = resize(img, self.img_size)
return img_path, img
def __len__(self):
return len(self.files)
class ListDataset(Dataset):
def __init__(self, list_path, img_size=416, augment=True, multiscale=True, normalized_labels=True):
with open(list_path, "r") as file:
self.img_files = file.readlines()
self.label_files = [
path.replace("images", "labels").replace(".png", ".txt").replace(".jpg", ".txt")
for path in self.img_files
]
self.img_size = img_size
self.max_objects = 100
self.augment = augment
self.multiscale = multiscale
self.normalized_labels = normalized_labels
self.min_size = self.img_size - 3 * 32
self.max_size = self.img_size + 3 * 32
self.batch_count = 0
def __getitem__(self, index):
# ---------
# Image
# ---------
img_path = self.img_files[index % len(self.img_files)].rstrip()
img_path = r'../YOLOv3/data/coco' + img_path
#print (img_path)
# Extract image as PyTorch tensor
img = transforms.ToTensor()(Image.open(img_path).convert('RGB'))
# Handle images with less than three channels
if len(img.shape) != 3:
img = img.unsqueeze(0)
img = img.expand((3, img.shape[1:]))
_, h, w = img.shape
h_factor, w_factor = (h, w) if self.normalized_labels else (1, 1)
# Pad to square resolution
img, pad = pad_to_square(img, 0)
_, padded_h, padded_w = img.shape
# ---------
# Label
# ---------
label_path = self.label_files[index % len(self.img_files)].rstrip()
label_path = r'../YOLOv3/data/coco/labels' + label_path
#print (label_path)
targets = None
if os.path.exists(label_path):
boxes = torch.from_numpy(np.loadtxt(label_path).reshape(-1, 5))
# Extract coordinates for unpadded + unscaled image
x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2)
y1 = h_factor * (boxes[:, 2] - boxes[:, 4] / 2)
x2 = w_factor * (boxes[:, 1] + boxes[:, 3] / 2)
y2 = h_factor * (boxes[:, 2] + boxes[:, 4] / 2)
# Adjust for added padding
x1 += pad[0]
y1 += pad[2]
x2 += pad[1]
y2 += pad[3]
# Returns (x, y, w, h)
boxes[:, 1] = ((x1 + x2) / 2) / padded_w
boxes[:, 2] = ((y1 + y2) / 2) / padded_h
boxes[:, 3] *= w_factor / padded_w
boxes[:, 4] *= h_factor / padded_h
targets = torch.zeros((len(boxes), 6))
targets[:, 1:] = boxes
# Apply augmentations
if self.augment:
if np.random.random() < 0.5:
img, targets = horisontal_flip(img, targets)
return img_path, img, targets
def collate_fn(self, batch):
paths, imgs, targets = list(zip(*batch))
# Remove empty placeholder targets
targets = [boxes for boxes in targets if boxes is not None]
# Add sample index to targets
for i, boxes in enumerate(targets):
boxes[:, 0] = i
targets = torch.cat(targets, 0)
# Selects new image size every tenth batch
if self.multiscale and self.batch_count % 10 == 0:
self.img_size = random.choice(range(self.min_size, self.max_size + 1, 32))
# Resize images to input shape
imgs = torch.stack([resize(img, self.img_size) for img in imgs])
self.batch_count += 1
return paths, imgs, targets
def __len__(self):
return len(self.img_files)
dataset在test部分只用到ImageFolder,pad_to_square(),list_dataset在train中使用。
- pad_to_square()用于将长方形的图片用0 值padding成正方形
3. utils
utils.py
from __future__ import division
import math
import time
import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def to_cpu(tensor):
return tensor.detach().cpu()
def load_classes(path):
"""
Loads class labels at 'path'
"""
fp = open(path, "r")
names = fp.read().split("\n")[:-1]
return names
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
def rescale_boxes(boxes, current_dim, original_shape):
""" Rescales bounding boxes to the original shape """
orig_h, orig_w = original_shape
# The amount of padding that was added
pad_x = max(orig_h - orig_w, 0) * (current_dim / max(original_shape))
pad_y = max(orig_w - orig_h, 0) * (current_dim / max(original_shape))
# Image height and width after padding is removed
unpad_h = current_dim - pad_y
unpad_w = current_dim - pad_x
# Rescale bounding boxes to dimension of original image
boxes[:, 0] = ((boxes[:, 0] - pad_x // 2) / unpad_w) * orig_w
boxes[:, 1] = ((boxes[:, 1] - pad_y // 2) / unpad_h) * orig_h
boxes[:, 2] = ((boxes[:, 2] - pad_x // 2) / unpad_w) * orig_w
boxes[:, 3] = ((boxes[:, 3] - pad_y // 2) / unpad_h) * orig_h
return boxes
def xywh2xyxy(x):# x,y是框的中心点不是左上角也不是右下角
y = x.new(x.shape)
y[..., 0] = x[..., 0] - x[..., 2] / 2
y[..., 1] = x[..., 1] - x[..., 3] / 2
y[..., 2] = x[..., 0] + x[..., 2] / 2
y[..., 3] = x[..., 1] + x[..., 3] / 2
return y
def ap_per_class(tp, conf, pred_cls, target_cls):
""" Compute the average precision, given the recall and precision curves.
Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
# Arguments
tp: True positives (list).
conf: Objectness value from 0-1 (list).
pred_cls: Predicted object classes (list).
target_cls: True object classes (list).
# Returns
The average precision as computed in py-faster-rcnn.
"""
# Sort by objectness
i = np.argsort(-conf)
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
# Find unique classes
unique_classes = np.unique(target_cls)
# Create Precision-Recall curve and compute AP for each class
ap, p, r = [], [], []
for c in tqdm.tqdm(unique_classes, desc="Computing AP"):
i = pred_cls == c
n_gt = (target_cls == c).sum() # Number of ground truth objects
n_p = i.sum() # Number of predicted objects
if n_p == 0 and n_gt == 0:
continue
elif n_p == 0 or n_gt == 0:
ap.append(0)
r.append(0)
p.append(0)
else:
# Accumulate FPs and TPs
fpc = (1 - tp[i]).cumsum()
tpc = (tp[i]).cumsum()
# Recall
recall_curve = tpc / (n_gt + 1e-16)
r.append(recall_curve[-1])
# Precision
precision_curve = tpc / (tpc + fpc)
p.append(precision_curve[-1])
# AP from recall-precision curve
ap.append(compute_ap(recall_curve, precision_curve))
# Compute F1 score (harmonic mean of precision and recall)
p, r, ap = np.array(p), np.array(r), np.array(ap)
f1 = 2 * p * r / (p + r + 1e-16)
return p, r, ap, f1, unique_classes.astype("int32")
def compute_ap(recall, precision):
""" Compute the average precision, given the recall and precision curves.
Code originally from https://github.com/rbgirshick/py-faster-rcnn.
# Arguments
recall: The recall curve (list).
precision: The precision curve (list).
# Returns
The average precision as computed in py-faster-rcnn.
"""
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.0], recall, [1.0]))
mpre = np.concatenate(([0.0], precision, [0.0]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
def get_batch_statistics(outputs, targets, iou_threshold):
""" Compute true positives, predicted scores and predicted labels per sample """
batch_metrics = []
for sample_i in range(len(outputs)):
if outputs[sample_i] is None:
continue
output = outputs[sample_i]
pred_boxes = output[:, :4]
pred_scores = output[:, 4]
pred_labels = output[:, -1]
true_positives = np.zeros(pred_boxes.shape[0])
annotations = targets[targets[:, 0] == sample_i][:, 1:]
target_labels = annotations[:, 0] if len(annotations) else []
if len(annotations):
detected_boxes = []
target_boxes = annotations[:, 1:]
for pred_i, (pred_box, pred_label) in enumerate(zip(pred_boxes, pred_labels)):
# If targets are found break
if len(detected_boxes) == len(annotations):
break
# Ignore if label is not one of the target labels
if pred_label not in target_labels:
continue
iou, box_index = bbox_iou(pred_box.unsqueeze(0), target_boxes).max(0)
if iou >= iou_threshold and box_index not in detected_boxes:
true_positives[pred_i] = 1
detected_boxes += [box_index]
batch_metrics.append([true_positives, pred_scores, pred_labels])
return batch_metrics
def bbox_wh_iou(wh1, wh2):
wh2 = wh2.t()
w1, h1 = wh1[0], wh1[1]
w2, h2 = wh2[0], wh2[1]
inter_area = torch.min(w1, w2) * torch.min(h1, h2)
union_area = (w1 * h1 + 1e-16) + w2 * h2 - inter_area
return inter_area / union_area
def bbox_iou(box1, box2, x1y1x2y2=True):
"""
Returns the IoU of two bounding boxes
"""
if not x1y1x2y2:
# Transform from center and width to exact coordinates
b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2
b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2
b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2
b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2
else:
# Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]
# get the corrdinates of the intersection rectangle
inter_rect_x1 = torch.max(b1_x1, b2_x1)
inter_rect_y1 = torch.max(b1_y1, b2_y1)
inter_rect_x2 = torch.min(b1_x2, b2_x2)
inter_rect_y2 = torch.min(b1_y2, b2_y2)
# Intersection area
inter_area = torch.clamp(inter_rect_x2 - inter_rect_x1 + 1, min=0) * torch.clamp(
inter_rect_y2 - inter_rect_y1 + 1, min=0
)
# Union Area
b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1)
b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1)
iou = inter_area / (b1_area + b2_area - inter_area + 1e-16)
return iou
def non_max_suppression(prediction, conf_thres=0.5, nms_thres=0.4):
"""
Removes detections with lower object confidence score than 'conf_thres' and performs
Non-Maximum Suppression to further filter detections.
Returns detections with shape:
(x1, y1, x2, y2, object_conf, class_score, class_pred)
"""
# From (center x, center y, width, height) to (x1, y1, x2, y2)
prediction[..., :4] = xywh2xyxy(prediction[..., :4])
output = [None for _ in range(len(prediction))]
for image_i, image_pred in enumerate(prediction):
# Filter out confidence scores below threshold
image_pred = image_pred[image_pred[:, 4] >= conf_thres]
# If none are remaining => process next image
if not image_pred.size(0):
continue
# Object confidence times class confidence
score = image_pred[:, 4] * image_pred[:, 5:].max(1)[0]
# Sort by it
image_pred = image_pred[(-score).argsort()]
class_confs, class_preds = image_pred[:, 5:].max(1, keepdim=True)
detections = torch.cat((image_pred[:, :5], class_confs.float(), class_preds.float()), 1)
# Perform non-maximum suppression 极大值抑制
keep_boxes = []
while detections.size(0):
large_overlap = bbox_iou(detections[0, :4].unsqueeze(0), detections[:, :4]) > nms_thres
label_match = detections[0, -1] == detections[:, -1]
# Indices of boxes with lower confidence scores, large IOUs and matching labels
invalid = large_overlap & label_match
weights = detections[invalid, 4:5]
# Merge overlapping bboxes by order of confidence
detections[0, :4] = (weights * detections[invalid, :4]).sum(0) / weights.sum()
keep_boxes += [detections[0]]
detections = detections[~invalid]
if keep_boxes:
output[image_i] = torch.stack(keep_boxes)
return output
def build_targets(pred_boxes, pred_cls, target, anchors, ignore_thres):
ByteTensor = torch.cuda.ByteTensor if pred_boxes.is_cuda else torch.ByteTensor
FloatTensor = torch.cuda.FloatTensor if pred_boxes.is_cuda else torch.FloatTensor
nB = pred_boxes.size(0) # batchsieze 4
nA = pred_boxes.size(1) # 每个格子对应了多少个anchor
nC = pred_cls.size(-1) # 类别的数量
nG = pred_boxes.size(2) # gridsize
# Output tensors
obj_mask = ByteTensor(nB, nA, nG, nG).fill_(0) # obj,anchor包含物体, 即为1,默认为0 考虑前景
noobj_mask = ByteTensor(nB, nA, nG, nG).fill_(1) # noobj, anchor不包含物体, 则为1,默认为1 考虑背景
class_mask = FloatTensor(nB, nA, nG, nG).fill_(0) # 类别掩膜,类别预测正确即为1,默认全为0
iou_scores = FloatTensor(nB, nA, nG, nG).fill_(0) # 预测框与真实框的iou得分
tx = FloatTensor(nB, nA, nG, nG).fill_(0) # 真实框相对于网格的位置
ty = FloatTensor(nB, nA, nG, nG).fill_(0)
tw = FloatTensor(nB, nA, nG, nG).fill_(0)
th = FloatTensor(nB, nA, nG, nG).fill_(0)
tcls = FloatTensor(nB, nA, nG, nG, nC).fill_(0)
# Convert to position relative to box
target_boxes = target[:, 2:6] * nG #target中的xywh都是0-1的,可以得到其在当前gridsize上的xywh
gxy = target_boxes[:, :2]
gwh = target_boxes[:, 2:]
# Get anchors with best iou
ious = torch.stack([bbox_wh_iou(anchor, gwh) for anchor in anchors]) #每一种规格的anchor跟每个标签上的框的IOU得分
print (ious.shape)
best_ious, best_n = ious.max(0) # 得到其最高分以及哪种规格框和当前目标最相似
# Separate target values
b, target_labels = target[:, :2].long().t() # 真实框所对应的batch,以及每个框所代表的实际类别
gx, gy = gxy.t()
gw, gh = gwh.t()
gi, gj = gxy.long().t() #位置信息,向下取整了
# Set masks
obj_mask[b, best_n, gj, gi] = 1 # 实际包含物体的设置成1
noobj_mask[b, best_n, gj, gi] = 0 # 相反
# Set noobj mask to zero where iou exceeds ignore threshold
for i, anchor_ious in enumerate(ious.t()): # IOU超过了指定的阈值就相当于有物体了
noobj_mask[b[i], anchor_ious > ignore_thres, gj[i], gi[i]] = 0
# Coordinates
tx[b, best_n, gj, gi] = gx - gx.floor() # 根据真实框所在位置,得到其相当于网络的位置
ty[b, best_n, gj, gi] = gy - gy.floor()
# Width and height
tw[b, best_n, gj, gi] = torch.log(gw / anchors[best_n][:, 0] + 1e-16)
th[b, best_n, gj, gi] = torch.log(gh / anchors[best_n][:, 1] + 1e-16)
# One-hot encoding of label
tcls[b, best_n, gj, gi, target_labels] = 1 #将真实框的标签转换为one-hot编码形式
# Compute label correctness and iou at best anchor 计算预测的和真实一样的索引
class_mask[b, best_n, gj, gi] = (pred_cls[b, best_n, gj, gi].argmax(-1) == target_labels).float()
iou_scores[b, best_n, gj, gi] = bbox_iou(pred_boxes[b, best_n, gj, gi], target_boxes, x1y1x2y2=False) #与真实框想匹配的预测框之间的iou值
tconf = obj_mask.float() # 真实框的置信度,也就是1
return iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf
4. test/detect
detect.py
from __future__ import division
from models import *
from utils.utils import *
from utils.datasets import *
import os
import sys
import time
import datetime
import argparse
from PIL import Image
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.ticker import NullLocator
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--image_folder", type=str, default=r"..\data\samples", help="path to dataset")
parser.add_argument("--model_def", type=str, default=r"..\config\yolov3.cfg",
help="path to model definition file")# 网络结构定义
parser.add_argument("--weights_path", type=str, default=r"..\weights\yolov3.weights",
help="path to weights file") # 网络权重加载
parser.add_argument("--class_path", type=str, default=r"..\data\coco.names",
help="path to class label file") # classes name
parser.add_argument("--conf_thres", type=float, default=0.8, help="object confidence threshold") # 置信度阈值
parser.add_argument("--nms_thres", type=float, default=0.4, help="iou threshold for non-maximum suppression")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--n_cpu", type=int, default=0, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_size", type=int, default=416, help="size of each image dimension")
parser.add_argument("--checkpoint_model", type=str, help="path to checkpoint model")
opt = parser.parse_args()
print(opt)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
os.makedirs("output", exist_ok=True)
# Set up model
model = Darknet(opt.model_def, img_size=opt.img_size).to(device)
if opt.weights_path.endswith(".weights"):
# Load darknet weights
model.load_darknet_weights(opt.weights_path)
else:
# Load checkpoint weights
model.load_state_dict(torch.load(opt.weights_path))
model.eval() # Set in evaluation mode
dataloader = DataLoader(
ImageFolder(opt.image_folder, img_size=opt.img_size),
batch_size=opt.batch_size,
shuffle=False,
num_workers=opt.n_cpu,
)
classes = load_classes(opt.class_path) # Extracts class labels from file
Tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.FloatTensor
imgs = [] # Stores image paths
img_detections = [] # Stores detections for each image index
print("\nPerforming object detection:")
prev_time = time.time()
for batch_i, (img_paths, input_imgs) in enumerate(dataloader):
# Configure input
input_imgs = Variable(input_imgs.type(Tensor))
# Get detections
with torch.no_grad():
detections = model(input_imgs)
detections = non_max_suppression(detections, opt.conf_thres, opt.nms_thres)
# Log progress
current_time = time.time()
inference_time = datetime.timedelta(seconds=current_time - prev_time)
prev_time = current_time
print("\t+ Batch %d, Inference Time: %s" % (batch_i, inference_time))
# Save image and detections
imgs.extend(img_paths)
img_detections.extend(detections)
# Bounding-box colors
cmap = plt.get_cmap("tab20b")
colors = [cmap(i) for i in np.linspace(0, 1, 20)]
print("\nSaving images:")
# Iterate through images and save plot of detections
for img_i, (path, detections) in enumerate(zip(imgs, img_detections)):
print("(%d) Image: '%s'" % (img_i, path))
# Create plot
img = np.array(Image.open(path))
plt.figure()
fig, ax = plt.subplots(1)
ax.imshow(img)
# Draw bounding boxes and labels of detections
if detections is not None:
# Rescale boxes to original image
detections = rescale_boxes(detections, opt.img_size, img.shape[:2])
unique_labels = detections[:, -1].cpu().unique()
n_cls_preds = len(unique_labels)
bbox_colors = random.sample(colors, n_cls_preds)
for x1, y1, x2, y2, conf, cls_conf, cls_pred in detections:
print("\t+ Label: %s, Conf: %.5f" % (classes[int(cls_pred)], cls_conf.item()))
box_w = x2 - x1
box_h = y2 - y1
color = bbox_colors[int(np.where(unique_labels == int(cls_pred))[0])]
# Create a Rectangle patch
bbox = patches.Rectangle((x1, y1), box_w, box_h, linewidth=2, edgecolor=color, facecolor="none")
# Add the bbox to the plot
ax.add_patch(bbox)
# Add label
plt.text(
x1,
y1,
s=classes[int(cls_pred)],
color="white",
verticalalignment="top",
bbox={"color": color, "pad": 0},
)
# Save generated image with detections
plt.axis("off")
plt.gca().xaxis.set_major_locator(NullLocator())
plt.gca().yaxis.set_major_locator(NullLocator())
filename = path.split("\\")[-1].split(".")[0]
plt.savefig(rf"..\output\samples\{filename}.png", bbox_inches="tight", pad_inches=0.0)
plt.close()
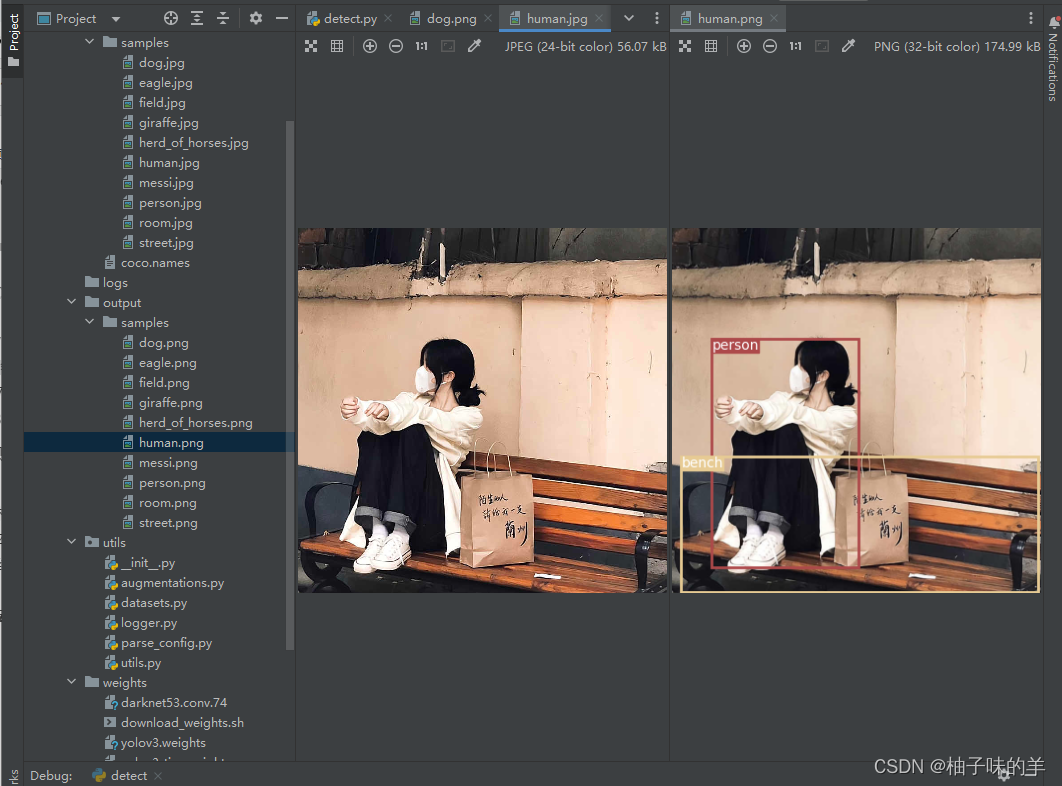
5. detect全过程
- 加载图片,将图片padding成正方形后作为模型的input
- 由浅及深将三个yolo层得到的特征cat到一起【(1,507,85)+(1,2028,85)+ (1,8112,85)】 = 【(1,10647,85)】
- model预测得到的10647个框进入非极大值抑制去除小于阈值的框
- 把最终的框框保存,现在的框坐标是相对于正方形的,要将其还原成原本的图片尺寸下的坐标进行可视化
我的测试结果:
今天先这些,去学新的啦,886