读发布!设计与部署稳定的分布式系统(第2版)笔记09_一窝蜂和容量
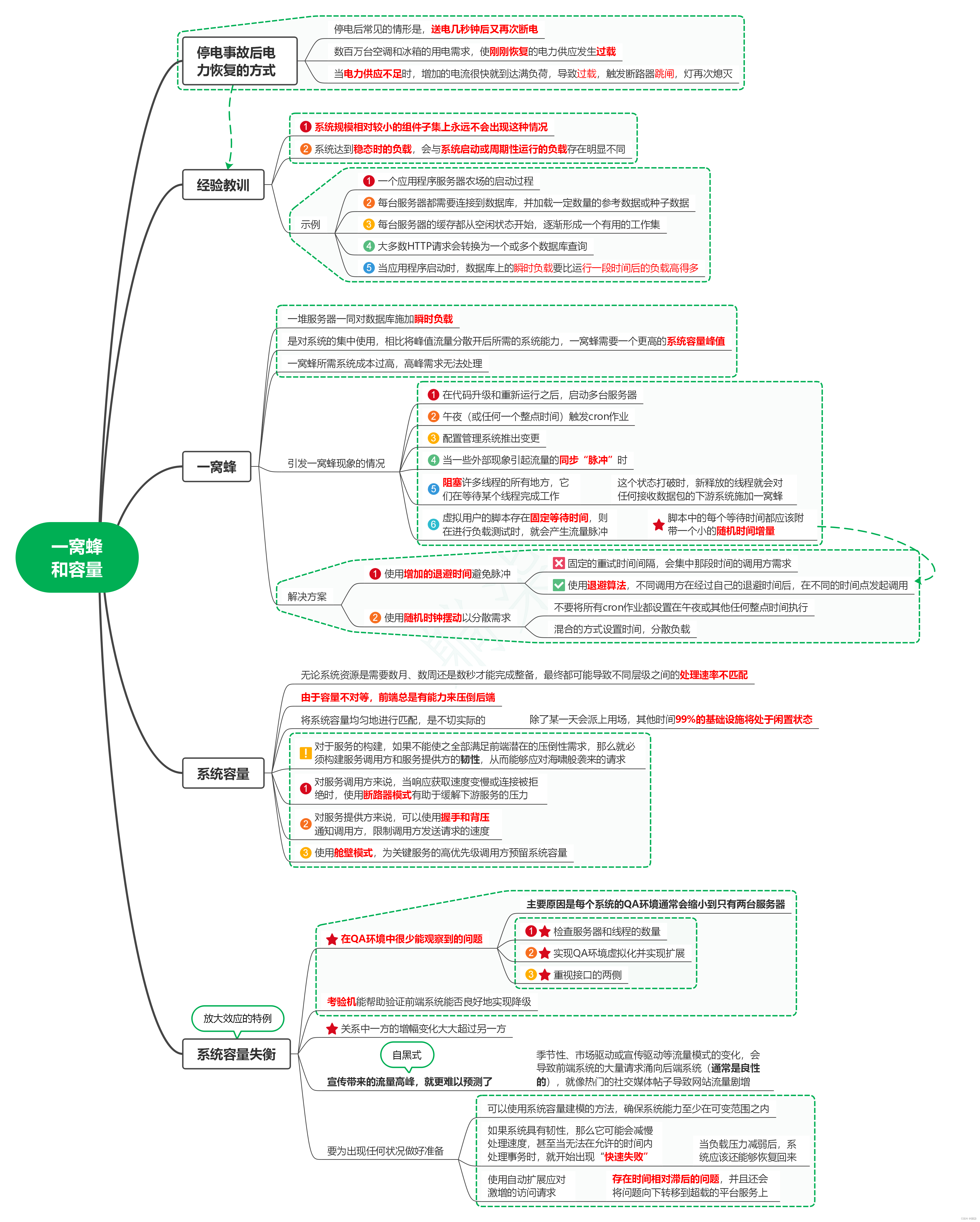
1. 停电事故后电力恢复的方式
1.1. 停电后常见的情形是,送电几秒钟后又再次断电
1.2. 数百万台空调和冰箱的用电需求,使刚刚恢复的电力供应发生过载
1.3. 当电力供应不足时,增加的电流很快就到达满负荷,导致过载,触发断路器跳闸,灯再次熄灭
2. 经验教训
2.1. 系统规模相对较小的组件子集上永远不会出现这种情况
2.2. 系统达到稳态时的负载,会与系统启动或周期性运行的负载存在明显不同
2.3. 示例
2.3.1. 一个应用程序服务器农场的启动过程
2.3.2. 每台服务器都需要连接到数据库,并加载一定数量的参考数据或种子数据
2.3.3. 每台服务器的缓存都从空闲状态开始,逐渐形成一个有用的工作集
2.3.4. 大多数HTTP请求会转换为一个或多个数据库查询
2.3.5. 当应用程序启动时,数据库上的瞬时负载要比运行一段时间后的负载高得多
3. 一窝蜂
3.1. 一堆服务器一同对数据库施加瞬时负载
3.2. 是对系统的集中使用,相比将峰值流量分散开后所需的系统能力,一窝蜂需要一个更高的系统容量峰值
3.3. 一窝蜂所需系统成本过高,高峰需求无法处理
3.4. 引发一窝蜂现象的情况
3.4.1. 在代码升级和重新运行之后,启动多台服务器
3.4.2. 午夜(或任何一个整点时间)触发cron作业
3.4.3. 配置管理系统推出变更
3.4.4. 当一些外部现象引起流量的同步“脉冲”时
3.4.5. 阻塞许多线程的所有地方,它们在等待某个线程完成工作
3.4.5.1. 这个状态打破时,新释放的线程就会对任何接收数据包的下游系统施加一窝蜂
3.4.6. 虚拟用户的脚本存在固定等待时间,则在进行负载测试时,就会产生流量脉冲
3.4.6.1. 脚本中的每个等待时间都应该附带一个小的随机时间增量
3.5. 解决方案
3.5.1. 使用增加的退避时间避免脉冲
3.5.1.1. 固定的重试时间间隔,会集中那段时间的调用方需求
3.5.1.2. 使用退避算法,不同调用方在经过自己的退避时间后,在不同的时间点发起调用
3.5.2. 使用随机时钟摆动以分散需求
3.5.2.1. 不要将所有cron作业都设置在午夜或其他任何整点时间执行
3.5.2.2. 混合的方式设置时间,分散负载
4. 系统容量
4.1. 无论系统资源是需要数月、数周还是数秒才能完成整备,最终都可能导致不同层级之间的处理速率不匹配
4.2. 由于容量不对等,前端总是有能力来压倒后端
4.3. 将系统容量均匀地进行匹配,是不切实际的
4.3.1. 除了某一天会派上用场,其他时间99%的基础设施将处于闲置状态
4.4. 对于服务的构建,如果不能使之全部满足前端潜在的压倒性需求,那么就必须构建服务调用方和服务提供方的韧性,从而能够应对海啸般袭来的请求
4.5. 对服务调用方来说,当响应获取速度变慢或连接被拒绝时,使用断路器模式有助于缓解下游服务的压力
4.6. 对服务提供方来说,可以使用握手和背压通知调用方,限制调用方发送请求的速度
4.7. 使用舱壁模式,为关键服务的高优先级调用方预留系统容量
5. 系统容量失衡
5.1. 放大效应的特例
5.2. 在QA环境中很少能观察到的问题
5.2.1. 主要原因是每个系统的QA环境通常会缩小到只有两台服务器
5.2.2. 检查服务器和线程的数量
5.2.3. 实现QA环境虚拟化并实现扩展
5.2.4. 重视接口的两侧
5.3. 考验机能帮助验证前端系统能否良好地实现降级
5.4. 关系中一方的增幅变化大大超过另一方
5.5. 宣传带来的流量高峰,就更难以预测了
5.5.1. 自黑式
5.5.2. 季节性、市场驱动或宣传驱动等流量模式的变化,会导致前端系统的大量请求涌向后端系统(通常是良性的),就像热门的社交媒体帖子导致网站流量剧增
5.6. 要为出现任何状况做好准备
5.6.1. 可以使用系统容量建模的方法,确保系统能力至少在可变范围之内
5.6.2. 如果系统具有韧性,那么它可能会减慢处理速度,甚至当无法在允许的时间内处理事务时,就开始出现“快速失败”
5.6.2.1. 当负载压力减弱后,系统应该还能够恢复回来
5.6.3. 使用自动扩展应对激增的访问请求
5.6.3.1. 存在时间相对滞后的问题,并且还会将问题向下转移到超载的平台服务上
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/675630.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!