Iceberg从入门到精通系列之一:Iceberg核心概念理解
- 一、Iceberg核心概念
- 二、Iceberg表结构
- 三、数据文件
- 四、表快照Snapshot
- 五、清单列表Manifest list
- 六、表快照、数据文件和清单列表之间的关系
- 七、Catalog
- 八、Hive Catalog
- 九、Hadoop Catalog
- 十、Hive Catalog和Hadoop Catalog之间的关系
- 十一、创建数据库和iceberg表
- 十二、插入数据
- 十三、查询表的信息
一、Iceberg核心概念
Iceberg是一个分布式列式存储库,它基于Hadoop HDFS和Apache Spark。核心概念包括:
-
表(Table):存储数据的逻辑单元。Table由物理上相互独立且互不影响的Tablet组成。
-
Tablet(分片):Table的逻辑单元,Table可由一个或多个Table构成。Tablet使用数据分片技术存储数据,每个数据分片只能由一个Tablet存储,因而满足不可变性。
-
Snapshot(快照):代表一个Table在某个时间点的数据状态,由一份或多份Tablet组成。
-
Manifest(清单):描述Table状态的元数据,包括Table的Schema(模式)、Partition Spec(分区规范)和Current Snapshot ID(当前快照ID)等信息。
-
Partition(分区):将数据按照指定规则分隔成的逻辑单元,Partition由一个或多个数据块(Block)组成。
-
Block(块):其中存储的是Partition的数据,每个块都有一个唯一的ID,块的大小可以在表级别进行配置。
二、Iceberg表结构

- Iceberg 有文件级别的元数据管理。它基于 snapshot 来做多版本的控制。
- 每一个 snapshot 对应一组 manifest,每一个 manifest 再对应具体的数据文件。
- Iceberg 开放的存储格式,有着比较好的 API 和存储规范的定义,方便在后续对它做一些功能上的扩展。
三、数据文件
Iceberg数据文件是指实际存储表格数据的文件,通常以Parquet格式存储。每个数据文件包含了表格的一部分数据,通常是一个分区中的数据。数据文件通常情况下不会被修改,而是通过追加新的数据文件来增加新数据。Iceberg数据文件具有以下特点:
- 数据文件是不可变的,一旦创建就不能被修改。
- 数据文件以Parquet格式存储,可以很好地支持列式存储和查询。
- 数据文件通常会被分配到不同的存储系统或节点上,以实现分布式的数据存储和查询。
- 数据文件可以通过添加新文件、删除旧文件等方式实现数据的管理和调优。
- 数据文件通常会被组织成目录树的形式,以便快速定位和访问数据。
Iceberg数据文件是Iceberg表格的最基本的组成单元,也是Iceberg表格的核心。数据文件的设计可以使得Iceberg表格具备高效的查询和分析性能,同时具有良好的容错性和扩展性。
- 数据文件是Apache Iceberg表真实存储数据的文件,一般是在表的数据存储目录的data目录下,如果文件格式选择的是parquet,那么文件是以".parquet"结尾。
- Iceberg每次更新会产生多个数据文件
四、表快照Snapshot
Iceberg表快照是指表格在某个特定时间点的快照。Iceberg中的表格不允许修改,所有的修改会生成一个新的表快照。每个表快照包含了表格的元数据信息,如架构、分区规则、数据文件等等。因此,表格的每个新的快照都代表了表格的新的状态。
Iceberg表快照是Iceberg表格的重要组成部分,它可以帮助Iceberg表格实现版本控制和数据管理。通过使用表快照,可以轻松地恢复表格到先前的状态,也可以通过比较不同的快照,了解表格的历史变化和数据趋势。此外,表快照还可以实现数据的版本控制和权限管理等功能。
在Iceberg中,生成新的表快照是一件非常高效和简单的事情。当表格状态发生变化时,会自动产生一个新的表快照,并记录下新的元数据信息。因此,在使用Iceberg时,可以放心地对数据进行修改和操作,同时保证数据的正确性和可追溯性。
- 快照代表一张表在某个时刻的状态。每个快照里面会列出表在某个时刻的所有data-files列表。
- data files是存储在不同的manifest files里面,manifest files是存储在一个Manifest list文件里面,而一个Manifest list文件代表一个快照。
五、清单列表Manifest list
Iceberg清单列表是指Iceberg表格中所有数据文件的列表。每个数据文件都包含了表格的一部分数据,通常是一个分区中的数据。清单列表包含了数据文件的元数据信息,如文件大小、数据量、创建时间、分区信息等等。在Iceberg中,清单列表是非常重要的元数据信息,它可以帮助我们进行数据查询、管理和优化等操作。
在Iceberg表格中,清单列表是动态的,随着表格数据的变化而变化。当新的数据文件添加到表格中时,清单列表会自动更新,并记录下新的数据文件的元数据信息。同时,清单列表还可以帮助我们进行数据查询和优化。通过查询清单列表的元数据信息,我们可以轻松地了解表格的数据分布、数据量、可用的分区等信息,从而为我们的查询和优化操作提供帮助。
- manifest list是一个元数据文件,它列出构建表快照Snapshot的清单(Manifest file)。
- 这个元数据文件中存储的是Manifest file列表,每个Manifest file占据一行。
- 每行中存储了Manifest file的路径、其存储的数据文件(data files)的分区范围,增加了几个数据文件、删除了i个数据文件等信息,这些信息可以用来在查询时提供过滤,加快速度。
- Manifest file是以avro格式进行存储的,以".avro"后缀结尾。
总之,清单列表是Iceberg表格中重要的元数据信息之一,它可以帮助我们进行数据管理、查询和优化等操作,同时也是实现Iceberg表格高效和可靠的关键之一。
六、表快照、数据文件和清单列表之间的关系
在Iceberg表格中,表快照、数据文件和清单列表是密切相关的。表快照记录了表格在某个特定时间点的状态和元数据信息,包括架构、分区规则、数据文件等等。数据文件是实际存储表格数据的文件,通常以Parquet格式存储。每个数据文件包含了表格的一部分数据,通常是一个分区中的数据。清单列表是Iceberg表格的所有数据文件的列表,包括数据文件的元数据信息,如大小、数据量、创建时间、分区信息等等。
表格的每个新的快照都代表了表格的新的状态,包括新的元数据信息和数据文件列表。因此,快照与数据文件和清单列表是相互关联的。表快照记录了数据文件和清单列表的版本信息,以及它们的所有元数据信息。同时,清单列表可以帮助我们查询表格的数据文件和元数据信息,从而帮助我们了解表格的状态和数据趋势。数据文件是快照的实际组成部分,代表了表格的数据信息。
在Iceberg表格中,快照、数据文件和清单列表三者之间的关系是密切相关的,它们共同组成了Iceberg表格的基本结构。通过这个结构,我们可以实现数据版本控制、数据管理和查询优化等多种操作,从而提高我们的数据分析和应用效率。
七、Catalog
- 在Iceberg中,Catalog是管理表和数据的入口。Catalog负责存储表的元数据信息,包括Schema、Partition Spec、Current Snapshot ID等信息。它允许用户通过编程方式或CLI(命令行界面)来创建、删除、修改、查询表等操作。同时,Catalog还提供了对表的版本控制功能,允许用户在不同的快照之间切换,以及查询不同快照中数据的历史版本。
- Catalog将数据存储在下层的存储介质中,可以支持多种存储介质,目前已经支持了Hadoop HDFS、AWS S3等存储介质。 这种架构能够保证数据的持久性和可靠性,并且能够对接不同的计算引擎,可以提供更好的数据管理和查询能力。
八、Hive Catalog
- Hive Catalog是在Iceberg中使用Hive元数据存储的一种Catalog实现。
- 它通过使用Hive的元数据模型、和Iceberg的数据结构相结合的方式,实现了对Iceberg表的管理。
- 具体来说,Hive Catalog会通过Hive Metastore来存储Iceberg表的元数据,包括表的Schema、Partition信息、快照等内容。同时,它还实现了Iceberg的API(Application Programming Interface),使得用户可以通过使用相同的方法来管理和查询Iceberg表。
- 使用Hive Catalog可以将Iceberg表的管理与Hadoop生态系统相集成,方便用户进行操作和管理。
九、Hadoop Catalog
- Hadoop Catalog是在Iceberg中使用Hadoop元数据存储的一种Catalog实现。
- 它使用Hadoop文件系统(HDFS)来存储Iceberg表的元数据,包括表的Schema、Partition信息、快照等内容。同时,它还实现了Iceberg的API(Application Programming Interface),使得用户可以通过使用相同的方法来管理和查询Iceberg表。
- 使用Hadoop Catalog可以方便地将Iceberg表与Hadoop生态系统相集成,使用Hadoop相关的工具来操作和管理Iceberg表。
十、Hive Catalog和Hadoop Catalog之间的关系
- 在Iceberg中,Hive Catalog和Hadoop Catalog的本质区别是它们管理和存储表格数据的方式和元数据信息的组织形式。
- Iceberg的Hive Catalog是建立在Hadoop之上的数据仓库,专门用于管理和处理大规模数据集。它允许用户定义表格和数据类型,并支持高效的SQL查询。
- Iceberg的Hadoop Catalog是一个组件,用于管理Hadoop分布式文件系统(HDFS)中的数据。它提供了一个文件系统接口,可以帮助用户使用和管理Hadoop文件系统中的数据,并且可以支持多种数据存储格式和编码方法。
- 在Iceberg中,Hive Catalog和Hadoop Catalog被用作管理和存储Iceberg表格数据的中央服务。
它们的区别在于:
- Hive Catalog使用Hive元数据存储库来组织表格数据的元数据信息,而Hadoop Catalog则依赖于Hadoop HDFS来管理数据文件、记录表格分区信息等元数据信息。
- 因此,Hive Catalog和Hadoop Catalog在Iceberg中的区别在于它们管理和存储表格数据的方式和元数据信息的组织形式,但它们都是用于管理和存储Iceberg表格数据的重要组件。
十一、创建数据库和iceberg表
创建Hive Catalog数据库。使用以下命令创建一个名为“my_db”的数据库,并将Hive Catalog作为元数据存储库。
创建my_db数据库
hive> CREATE DATABASE my_db
WITH DBPROPERTIES (
'iceberg.catalog'='hadoop.catalog',
'iceberg.catalog.hive_db'='my_db'
);
创建Iceberg表。使用以下命令创建一个名为“my_table”的Iceberg表。
创建了一个包含id和name字段的表,并且定义了以id字段为分区键的分区规则。
CREATE TABLE my_db.my_table (
id INT,
name STRING
)
PARTITIONED BY (id);
十二、插入数据
INSERT INTO my_table
VALUES (1, 'John'),
(2, 'Mary'),
(3, 'Peter');
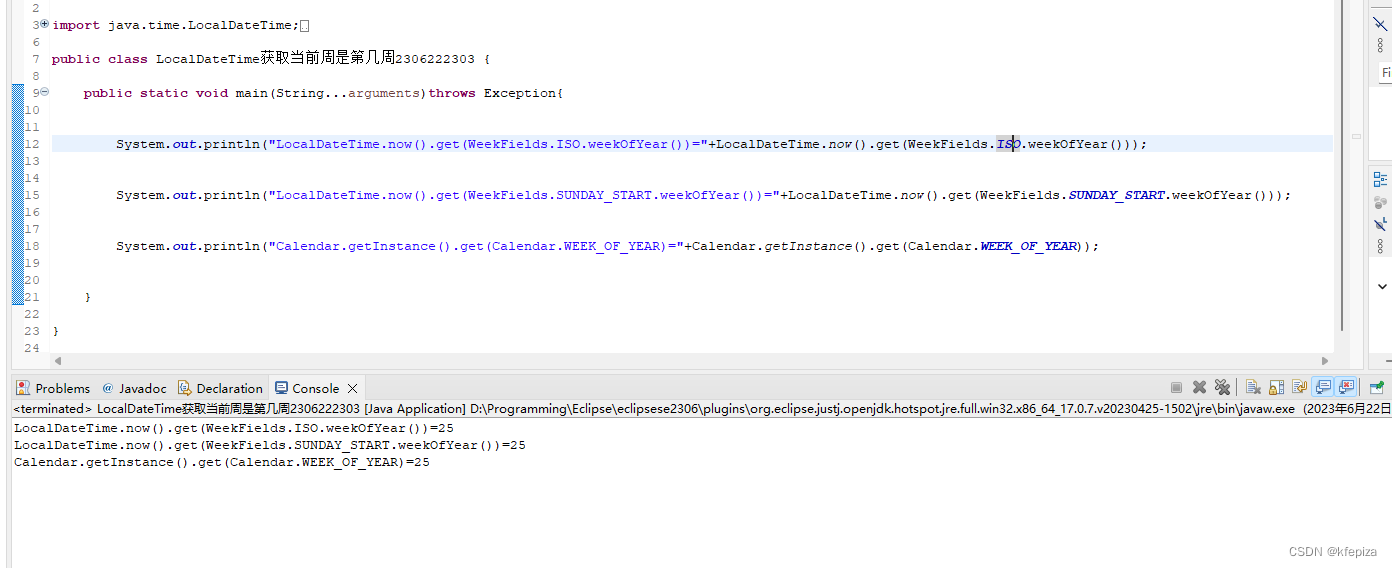
十三、查询表的信息
describe formatted iceberg_test1;