背景
SRE和程序在测试DDos多EIP防御方案的过程中,发现多EIP模式下, 监听的UDP端口连接会出现客户端访问异常。 表现为客户端发送一次数据后服务端这边主动断开了,或是客户端和服务端同时断开。
该问题会导致业务在多EIP方案下无法达到预期效果,无法进行自动切换EIP对外提供服务。
环境
- 业务场景:对外的进程默认走udp协议通信,UDP失败后会尝试走TCP协议。
- 监听方式:0.0.0.0:端口。
- 防火墙:对外提供的端口全开放。
- 网络:云(单网卡多EIP)、物理机(多网卡/IP)。
问题定位
抓包发现通信异常的时候,数据包中间会有一个icmp数据包,而我们并没有使用icmp相关协议,并且是icmp unreachable提示。
$tcpdump -nvv -i any |grep 128.1.208.1 02
tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 2621 44 bytes
128.1.208.102.44731 > 128.1.208.149.3000: [udp sum ok] UDP, length 2
13.250.175.90.53 > 128.1.208.30.59236: [udp sum ok] 36073 q: A? ******. (148)
128.1.208.102.44731 > 128.1.208.149.3000: [udp sum ok] UDP, length 2
128.1.208.149 > 128.1.208.102: ICMP 128.1.208.149 udp port 3000 unreachable, length 38
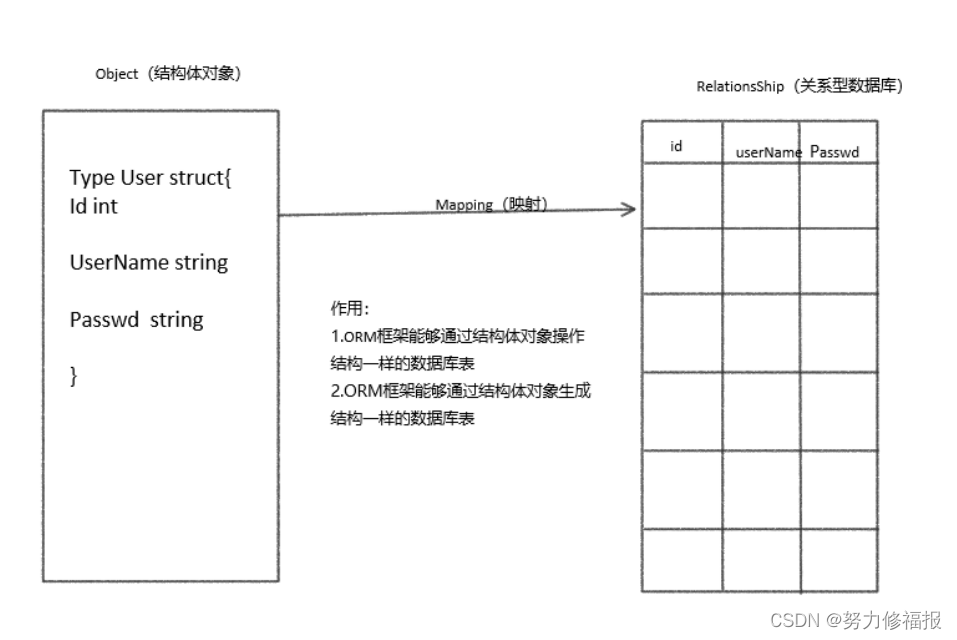
128.1.208.102.44731 > 128.1.208.149.3000: [udp sum ok] UDP, length 2当服务器创建 UDP socket 时,它可以把其中一个主机本地 IP 地址(包括广播地址)指定为 socket 的本 地 IP 地址。那么,只有当 UDP 包的目的 IP 地址与指定的地址相匹配时,该包才能被送到创建该 UPD socket 的业务层。否则,内核将返回一个 ICMP 端口不可达差错,而服务器(业务层)永远看不到该数 据报。
如果存在一个通配的 IP 地址,那么就隐含了一种优先级关系。如果为 UDP socket 指定了特定 IP 地址,那 么在匹配目的地址时,始终优先匹配该 IP 地址。只有在匹配不成功时才使用通配 地址进行匹配。
经常可以看到远端 IP 地址和远端端口号都显示为 .(或 0.0.0.0:*),其意思是该 socket 将接受来自任何 IP 地址和任何端口号的 UDP 数据报。大多数系统允许 UDP socket 对远端地址进行限制,以令其只能接收 来自特定 IP 地址和端口号的 UDP 数据报。
在伯克利派生系统中存在如下副作用:如果在指定远端地址(IP 和 PORT)时没有选择本地地址,那么内 核将自动选择本地地址。其值就成为“选择到达远端 IP 地址路由时”用于做路由判定的 IP 地址。
问题复现
服务端
import socket
ADDR = ('0.0.0.0', 12345) BUFSIZ = 65535
udpSerSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) udpSerSock.bind(ADDR)
while True:
print 'waiting for connection...'
data, addr = udpSerSock.recvfrom(BUFSIZ) udpSerSock.sendto(data, addr)
print '...recevied from {0}: {1}'.format(addr, data)
udpSerSock.close()客户端
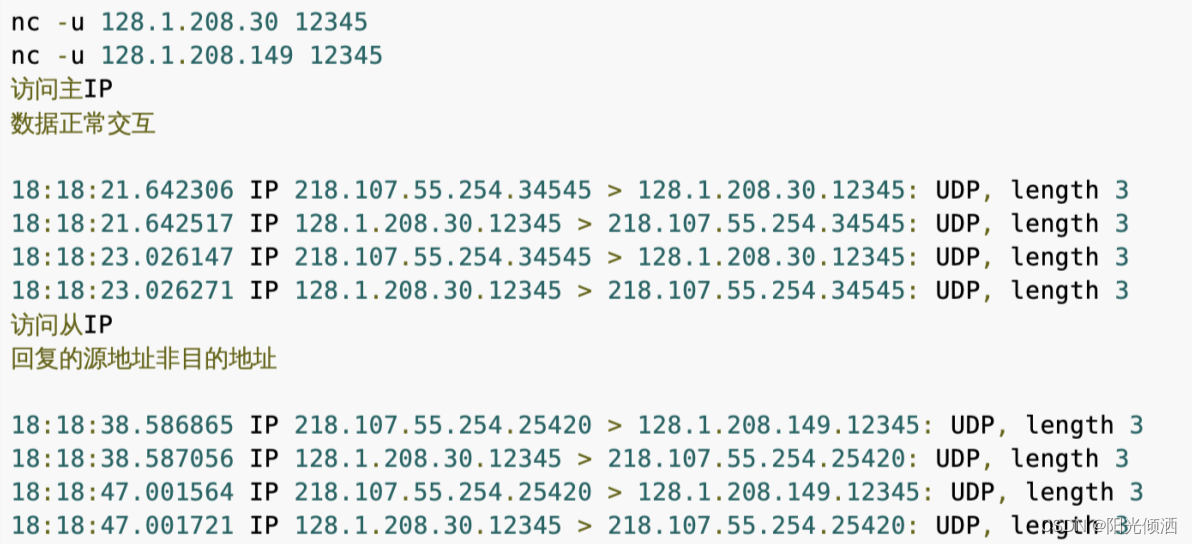
结论
在多IP且UDP的场景下, 如果使用了bind 0.0.0.0 这种方式, 操作系统会自动选择数据包回复的源地址, 默认 为默认路由对应接口的主IP。
解决方案
方案1:
更新服务端逻辑, 对进来的数据包进行目的地址判断, 使用正确的目的地做为发送数据的源地址, 避免系统自动选择出错(socket中的recvmsg).
但是该方式改动较大、这个因为我们用的是boost的asio库,asio库不支持获取和修改IP_PKTINFO信息。
方案2
代码层实现分别bind 所有外网ip地址,达到和bind 0.0.0.0一样的效果。
该方式相比原方式改动最小。