大家好,我是千与千寻,好久不见了,很多粉丝私信我说,千寻哥这是去哪了?难道被野外捕捉了。
哈哈哈,当然不是了,千寻依然在学习ChatGPT的道路上和大家一起学习,一起搞钱!
但是我觉得无论作为一名出色的研发工程师还是自媒体博主,都需要经常的对自己过去的生活以及工作输出进行总结。
千寻对多去的一段时间的输出内容进行了反思,同时也和星主进行了沟通。我发现的我输出的技术文章,存在两个明显的弊端:
1.技术门槛略高
我本人目前在互联网大厂担任算法工程师,所以我的思维就是程序员思维,觉得越复杂的项目,才有意义。但是代码门槛越高,同时受众群体也就越少,很多同学表示看不懂。
2.实用性不强
这里我觉得说白了,就是不赚钱,就想我们对自己不关心的事情,往往没有什么热情。所以我准备将后续的ChatGPT项目全部融入“使用价值”,同时照顾“非程序员”群体。
简单来说,就是后续的ChatGPT项目我将赋予更强的使用价值。不是项目可以用来赚钱,要不就是可以自己DIY,发挥星友们的创造力!
好的,我们直接进入正题,今天千寻哥给大家带来的ChatGPT项目,Audiocraft智能音乐生成工具!
Audiocraft的应用
拒绝废话!Audiocraft 是一个PyTorch的代码库,其内部包含用于音频生成的深度学习研究。
今天主要讲解的是MusicGen的代码工具,这是一种目前为止,最先进的可控文本到音乐模型。
MusicGen模型简单理解为是一个单级子回归的 Transformer 生成模型,在32kHz EnCodec 分词器上训练得到,具备 4 个以 50Hz 采样的码本。
MusicGen的模型训练
所有算法模型的训练,包括我们所使用的ChatGPT模型都是需要海量数据的。MusicGen的训练集是“两万小时时长的音乐数据集”,全部的数据集都是在32kHz下重新采样,每一个音乐都有对应的文本描述。
除训练数据集以外,Meta官方还搭配了测试数据集MusicCaps。
MusicCaps 由 5500 条专业作曲家谱写的 10 秒长的音乐构成。
音乐的编码阶段,通过实验对四种不同的方式进行了测试。
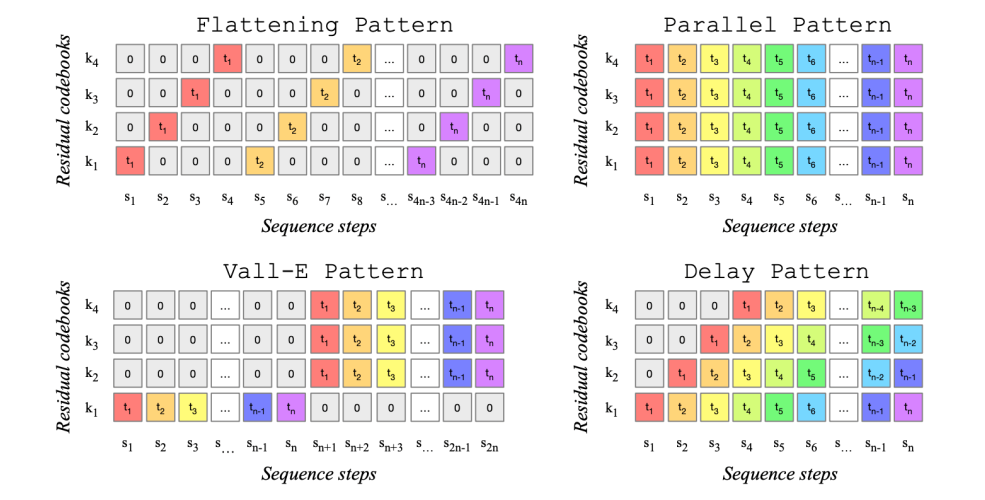
Transformer 部分训练了 300M、1.5B、3.3B 三个不同参数量的自回归式 Transformer。
Audiocraft的功能演示
Audiocraft模型与musicGen音乐生成工具到底有什么功能?
我们进行AI音乐生成工具的训练过程,我们使用的训练数据集是音乐描述转为音乐生成。其音乐生成工具的预测过程则是“根据音乐描述生成对应的音乐配乐”。
PC端本地部署应用
这个就是为算法工程师的程序员朋友们准备的了,使用huggingface社区的模型部署工具可能效果不是很理想。
这里同时也准备了如果自己进行本地PC端的部署教程
1.使用Anaconda工具创建一个虚拟环境 命名为“musicgen”,python版本为3.9。执行命令行:
conda create -n musicgen python=3.9
-
安装模型运行的环境依赖
pip install 'torch>=2.0'
# Then proceed to one of the following
pip install -U audiocraft # stable release
pip install -U git+https://git@github.com/facebookresearch/audiocraft#egg=audiocraft # bleeding edge
pip install -e . # or if you cloned the repo locally
3.下载模型的配置权重
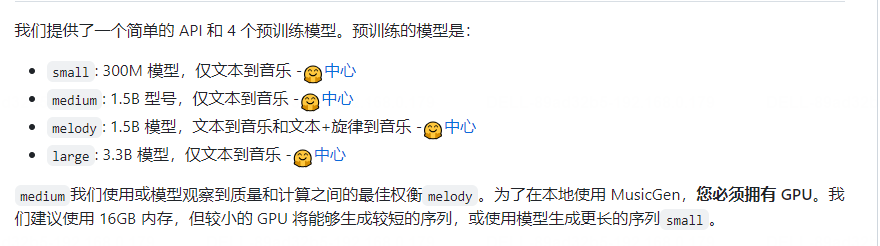
4.使用API接口进行指定音乐的生成
import torchaudio
from audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
model = MusicGen.get_pretrained('melody')
model.set_generation_params(duration=8) # generate 8 seconds.
wav = model.generate_unconditional(4) # generates 4 unconditional audio samples
descriptions = ['happy rock', 'energetic EDM', 'sad jazz']
wav = model.generate(descriptions) # generates 3 samples.
melody, sr = torchaudio.load('./assets/bach.mp3')
# generates using the melody from the given audio and the provided descriptions.
wav = model.generate_with_chroma(descriptions, melody[None].expand(3, -1, -1), sr)
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness", loudness_compressor=True)
5.谷歌实验室运行应用
执行全部以下命令:
# Adapted from https://github.com/camenduru/MusicGen-colab
%cd /content
!git clone https://github.com/facebookresearch/audiocraft
%cd /content/audiocraft
!pip install -r requirements.txt
# Click on the gradio link that appear.
!python app.py --share
colab环境中的运行效果:
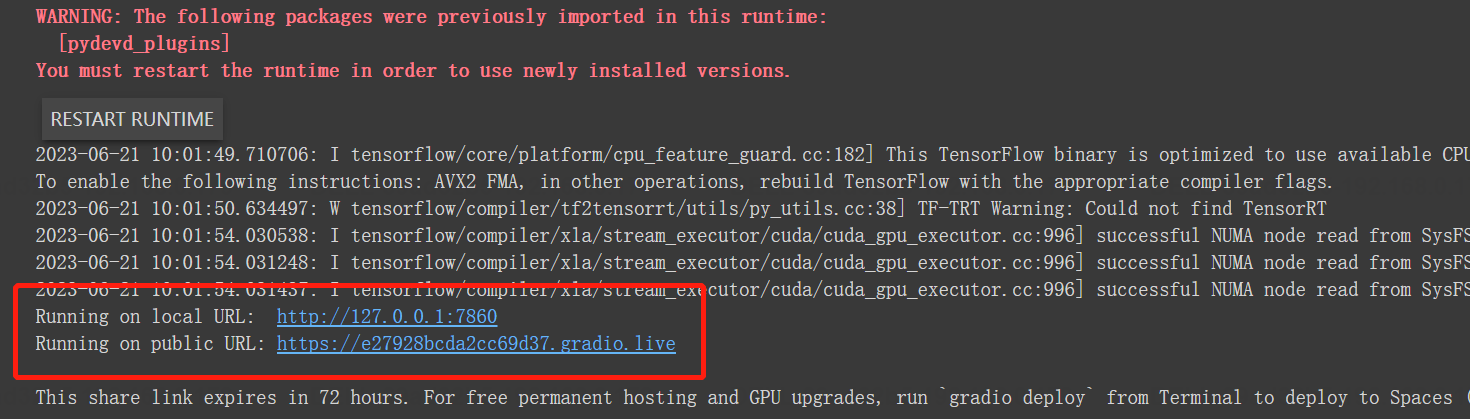
矩形方框中表示模型部署于以上链接之中。点击链接,即可进入网页中进行点击调用,十分方便,如下图为点击链接后的界面画面。

正好进入我们的重点,MusicGen这个GPT模型到底怎么用,实现什么功能,怎么为我们产业(搞钱)赋能?
别急,我们进入重点环节!
Audiocraft模型社区使用教程
进入MusicGen社区应用,点此链接
首先是界面应用的功能介绍,如下图所示
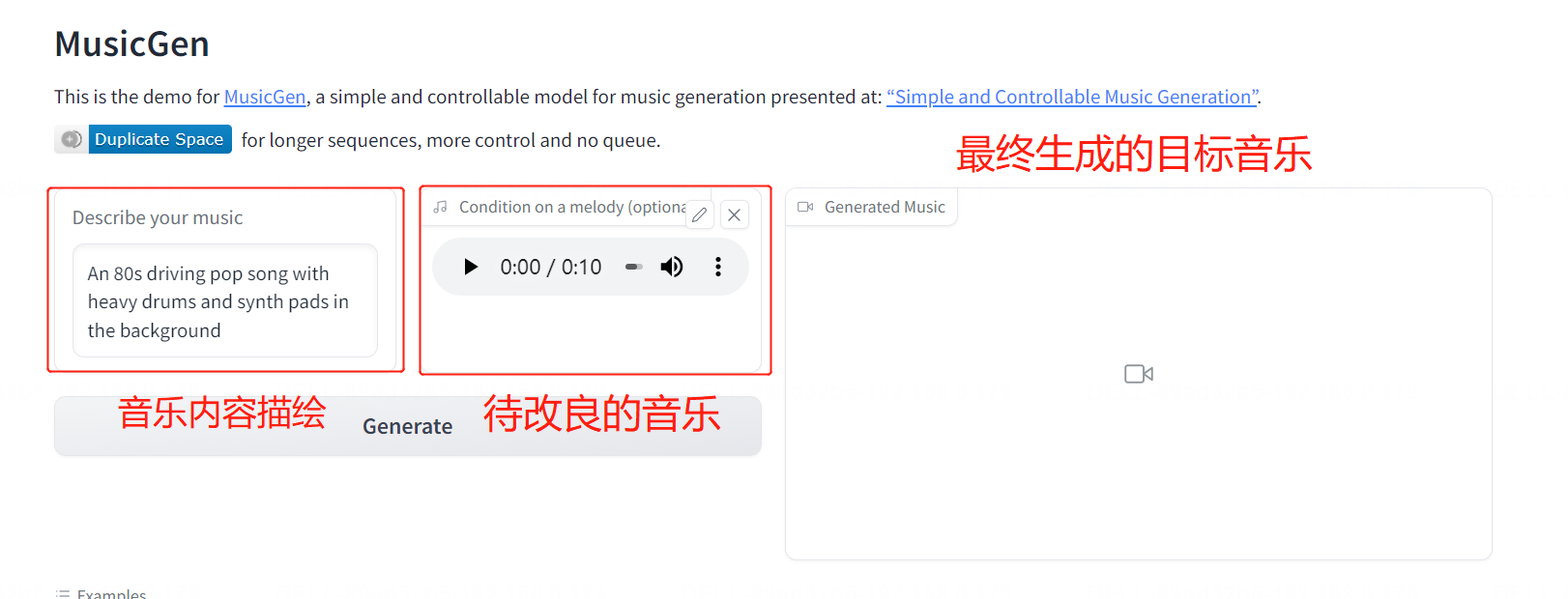
(1)音乐内容描绘:
文本描述生成音乐的特点,英文最好,中文也可以识别,描述待生成的旋律特点,比如摇滚,流行,沉重。
(2)待改良的音乐:
原始的音乐,文件格式为.mp3格式文件,可以理解为原始的旋律音乐。
(3)最终生成的目标音乐:
最终的目标,验证是否满意。
好玩的来了!精彩测试项目效果!
测试用例1:
An 80s driving pop song with heavy drums and synth pads in the background
翻译:一首 80 年代流行歌曲,背景是沉重的鼓和合成器垫
原始音乐文件:
改良音乐文件:
测试用例2:
A cheerful country song with acoustic guitars
翻译:一首带有原声吉他的欢快乡村歌曲
原始音乐文件:
改良音乐文件:
除了改良已有音乐旋律的功能,MusicGen大模型还可以凭空生成描述的音乐旋律。
测试用例3:
lofi slow bpm electro chill with organic samples
翻译:lofi 慢速 bpm 电冷却有机样品
生成音乐文件:
MusicGen赋能短视屏制作
小红书、抖音,快手是目前做流量首选的平台,很多时候,小红书采用图片+配乐+文本,这种看似简单的方式。
但是别忘了,正因为组成结构的简单,所以想在目前日益火爆的短视频市场,能够称为“黑马”。这里举一个例子,做一个很简单的短视频Demo。

这张图片,希望配乐一个“励志,并且感动的音乐”,使用基础的底层音乐进行改良。
使用MusicGen进行短视频的配乐生成:
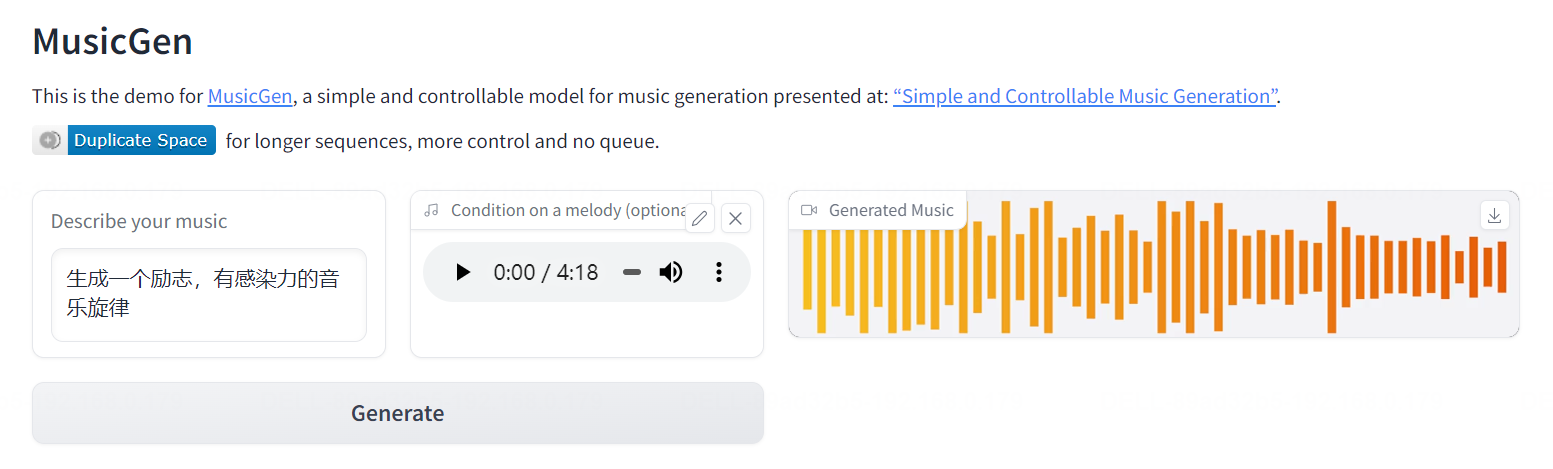
最终的短视频效果:
希望这次星主能给一个精华,哈哈哈,用了飞书文档优化体验,对内容进行深入的价值挖掘。
其实人生不就是一场“边学习,边进步”,不断找回正确方向的旅程吗,大家端午安康!
我是千与千寻,一个只讲干活的码农,我们下期见!
本文由 mdnice 多平台发布