一、第三代YAF
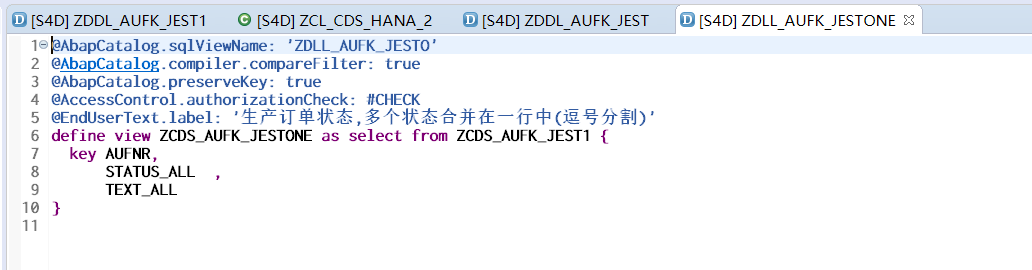
YAF(Yet Another Flowmeter)是作为CERT NetSA安全工具套件的传感器部分存在的,支持输入实时数据流和PCAP文件,解析并输出流数据,或针对特定协议的深包检测元数据。目前,YAF在整个系统的作用如下图所示:
其中Pipeline和SiLK都存在好多年了,用起来也算熟悉,SPARK这一块支持的时间不长(至少从软件的发布时间来说),算是 跟随现在的大数据潮流吧。
YAF 3 和之前的版本有了很大的区别,在于YAF 3开始支持应用标签(APPLabel)和深包检测(DPI)这2项在内网网络安全工具中最为常见的功能,要么说明US-CERT现在拥有更多的算力,要么就是当前的恶意行为使用原先的Netflow V9已经不足以应对。总之一点就是,这两项极为拉性能的东西出现在了CERT这样需要监视海量网络数据的组织的视野范围。
1. 应用标签 APPLabel
YAF — YAF: Application Labeling (cert.org)
这个所谓的应用标签其实更像是一个协议识别器。YAF可以通过检查数据包的有效载荷,确定流中使用的应用协议类型,并通过一个16位的应用标签进行标识。通常情况下,这个标签使用识别出的协议的周知端口号(IANA指定的那些),如果没有周知端口号,则使用当时数据传输时的实际标签,如果还遭遇与其他协议标识重合情况,则使用自定义标签。比如,若负载被识别为HTTP,则对应流量的APPLabel会被标识为80。
在YAF3中,APPLabel和DPI使用同一个lua配置文件,文件默认在路径:/usr/local/etc/yafDPIRules.conf上。也可以在运行yaf时通过命令行参数--dpi-rules-file来指定。
默认情况下,yaf工具并不支持APPLabel功能,所以编译时需要增加--enable-applabel参数。从命令行运行时,至少需要指定--applabel 和 --max-payload参数。由于识别协议类型所需要的数据远小于执行DPI,所以在只使用applabel时,可以设置较小的max-payload参数以获得较高的性能。官方推荐在仅使用applabel功能时,设置max-payload为384。
2. 深包检测 DPI
YAF — yafdpi(1) (cert.org)
YAF3可以监测网络数据包的负载,针对指定协议抓取所需要的信息,并将其保存在协议对应的IPFIX模板里。DPI功能直接与AppLabel功能相关,因为YAF3仅仅在APPLabel的打标处理过程中且发生命中的情况下才会执行DPI处理。
由于默认状态下,YAF3并不主动支持这么损耗性能的玩意儿。因此,要使YAF3支持APPLabel功能和DPI功能,需要在编译过程中为configure指定--enable-applabel和--enable-dpi标签。也就是说,如果要使用这个功能,直接从官网下载镜像是没戏的,需要我们从源代码编译干起。
另外,在运行YAF时,除了原先使用的--live pcap等参数外,至少还需要加入--dpi 和--max-payload=2048(或4096)两样参数。从性能角度看,2048是比较合适的,不过若想得到比较理想的结果,这个参数应该被设置为4096。
在这种情况下,YAF命令可能是这个样子:
yaf --daemonize --live pcap --in eth0 \
--out localhost --ipfix-port=18000 --ipfix tcp \
--dpi --max-payload=4096或者,加入--dpi-select参数,通过指定端口来明确需要DPI的协议:
yaf --daemonize --live pcap --in eth0 \
--out localhost --ipfix-port=18000 --ipfix tcp \
--dpi --dpi-select=25,53,80 --max-payload=4096或者,加入--dpi-rules-file参数,通过指定一个类似APPLabel所用的Lua文件的方式:
yaf --daemonize --live pcap --in eth0 \
--out localhost --ipfix-port=18000 --ipfix tcp \
--dpi --dpi-rules-file=*FILE* --max-payload=40963. 配置文件
(1)配置项
如果使用配置文件方式来指定DPI的行为,则文件中可能出现如下配置项:
per_field_limit: 定义输出的DPI字段的最大长度,默认为200字节,最大为65536字节,超出该长度的数值会被认为是指定默认值。另外,DNS和SSL/TLS证书的输出不受该配置项限制。
per_record_limit: 定义整条DPI记录输出的最大值,即对于一个会话,不论字段最大长度如何定义,最终形成的记录的长度总数不能超过该值。最大为65536字节,超出该长度的数值会被认为是指定默认值。默认值为1000字节。
cert_export_enabled: 如果被设置为true,则指示YAF3关闭X.509证书的正常解码和导出,改为导出完整的X.509证书到sslCertificate字段。这样做的好处在于将证书处理工作向下游工具卸载,比如Super Mediator。该配置项默认值为false。
cert_hash_enabled: 默认为false。如果设置为true,则指示YAF3输出X.509证书的Hash值到sslCertificateHash字段。Hash算法可以有sslCertSignature设置。默认设置为false,Hash算法为SHA-256。如果cert_export_enabled和cert_hash_enabled均为true,则YAF3不仅会输出完整证书,也会执行常规的证书解码导出流程,这会导致不必要的性能消耗,所以官方并不推荐。
dnssec_enabled: 指示YAF3输出DNSSEC Resource Record的DPI处理。默认为false。
(2) 规则格式
要使YAF3能够对我们感兴趣的会话执行DPI操作,我们首先需要确保这些会话被AppLabel命中,这是通过在yafDPIRules.conf中配置规则实现的。在yafDPIRules.conf中,需要定义一个名为applabels的变量,其作为一个数组,包含一系列applabel规则。每个applabel规则用来定义yaf的打标动作。一个典型的applabel规则定义如下:
applabels{
{
label=<APP>,
label_type="<LABEL_TYPE>",
value=[=[<EXPRESSION>]=],
ports={<PORTS>},
protocol=<PROTO>,
active=<true|false>,
<DPI-RELATED-ENTRIES>
}
}一个applabel规则,至少需要包含label、label_type和value 3项 。
label:<APP>是一个16位整型数字,从1到65535。由于label用于唯一标识被命中的一类数据,所以这个数值在整个规则空间内必须唯一。
label_type:<LABEL_TYPE>是一个字符串,可取值regex,plugin,signature,none。其中,regex标识value字段中是一个用于匹配的正则表达式;plugin标识value中是一段用于匹配的用户自定义lua代码,用不带后缀(so)的动态链接库的名称字符串来标识,该动态链接库的路径应该由环境变量LD_LIBRARY_PATH、LTDL_LIBRARY_PATH指示,或干脆放到系统的库路径中;signature通常在regex、plugin之前处理,一般在不需要DPI操作及不需要绑定端口的正则表达式处理时,直接使用signature,用其指定的正则表达式直接匹配会话负载即可;none取值代表该条规则被忽略。
value:[=[<EXPRESSION>]=],其中<EXPRESSION>是一个字符串,用于定义识别协议的方法,比如label_type是regex的时候,这个字符串就是一个正则表达式。官方建议这个字符串使用Lua的“Long literal”语法表示,这样可以规避使用转义符。这个“Long Literal”语法就是在字符串的外面加上如上的由方括号和等号组成的“双边框线框框”,等号还可以再多些,只要保持两边相等即可。
ports:{<PORTS>}一组用花括号括起来的端口号,端口号和端口号之间用逗号隔开;端口号和regex、plugin类型配合使用。如果ports没有被设置,则仅使用label的值作为端口进行匹配;所以即时ports出现时,其值也不能和已定义的label及ports重叠。
protocol:<PROTO>是一个8位整型数字,对应IP协议中的proto字段。虽然proto有0到255的取值,但由于yaf仅针对TCP、UDP和ICMP进行applabel操作,所以只有0、6、17可取。对于plugin类型的applabel,protocol是被忽略的,此时由用户自定义代码来确定协议的种类。
active:表示是否使用该条规则,true表示是,false则屏蔽该规则。
<DPI_RELATED_ENTRIES>,即applabel命中后,标识所进行的DPI操作。
applabels = {
{label=80, label_type="regex", value=[=[^HTTP/\d]=]}
}如上,对80端口使用正则表达式搜索负载以“HTTP/”加数字开头的会话,对于匹配的会话,使用80作为applabel来标识。
4. 已支持的协议
对于DNS协议,默认情况下YAF3的DPI将提取所有的DNS应答。如果希望改变默认的DNS提取行为,可以在编译过程中通过configure设置及进行改变。
--enable-exportDNSAuth 仅打开DNS Authoritative 应答,可能包括其后续包
--enable-exportDNSNXDomain 仅打开DNS NXDomain 应答,可能包括其前序包
5. 命令行参数释义
yaf 运行时主要需要通过命令行参数指定输入和输出关系,并可以设置一些可选项来调整yaf的解析行为。
(1)--in INPUT_SPECIFIER
--in 参数后面的INPUT_SPECIFIER指定输入源。当--live参数出现的时候,输入源应该时一个网络接口,名字类似于(eth0,ens33)之类;否则,它就是一个pcap文件的路径名,可以带通配符;当--caplist参数出现的时候,则对应一个列表txt文件,其中每一行都是一个pcap文件的路径,yaf会按顺序读入这些文件进行处理。
当使用--caplist参数的时候,可以使用--noerror参数避免因为个别文件错误造成整个处理流程退出。
(2)--out OUTPUT_SPECIFIER
如果--ipfix参数出现,OUTPUT_SPECIFIER指定采集器所在的主机名或IP地址,伴随--ipfix参数指定协议,--ipfix-port参数指定端口;否则,如果--rotate参数出现,OUTPUT_SPECIFIER代表循环输出文件的前缀。
(3)解析器(Decoder)可选项
1)--no-frag
如果出现,标识忽略所有的碎片包。默认情况下,yaf会以30秒为间隔重新组装碎片包
2)--max-frag FRAG_TABLE_MAX
如果出现,则要求对在碎片表中维护的尚未完成组装的碎片表设置上限。这样做的目的时为防止在大吞吐网络中耗尽yaf所在处理器的资源。通常情况下,yaf每5秒修剪一次碎片表,因此吞吐量较大时,滞留在表中的碎片会过多。默认情况下,没有碎片表的限制,碎片表会自行增长直到资源耗尽。
3) --ip4-only
4)--ip6-only
5)--gre-decode
如果出现,将尝试解析GRE封装,从GRE隧道中的数据包开始建流
(4)流表(Flow Table)可选项
1)--silk
如果出现,将以silk模式输出流,在yaf2.0中,这标识输出TCP信息(flags,ISN)。由于--silk会导致totalOctetCount和reverseTotalCount计时器被限定在32位,溢出时截断生成新的流等,于标准IPFIX不太兼容原因,所以仅在向rwflowpack、flowcap或者rwipfix2silk写文件时使用。
2)--idle-timeout IDLE_TIMEOUT
如果出现,则指定流过期的时间,当流超过该时间没有收到新的包时,认为结束。默认5分钟。
3)--active-timeout ACTIVE_TIMEOUT
如果出现,则指定流的维持时间,当流超过该时间没有中断时,截断生成新的流表。默认30分钟。
4)--max-payload PAYLOAD_OCTETS
如果出现,从每条流的上下行方向的起始点开始抓取最大PAYLOAD_OCTETS字节。非TCP流仅抓取第一个包的负载,除非--udp-payload参数也被设置。默认情况下,该参数不出现,yaf不会尝试抓取负载。当输出payload参数--export-payload被设置时,或者-applabel、--entropy等参数被设置时,该参数必须设置。
5)--max-flows FLOW_TABLE_MAX
如果出现,限制出现在解析中维持的流的个数,超出这个限制将会触发解析器过期所维持的流。默认情况下,没有该限制,直到资源耗尽。
6)force-read-all
如果出现,yaf将会强制处理失序的数据包,但其仍然会抛弃失序的碎片。
二、Super Mediator
YAF解析流量并生成IPFIX数据流/文件,Super Media则用来接受来自YAF或者另一个Super Mediator的IPFIX数据,以进行路由、聚合、格式化、去重、富化、过滤和内积等操作。
Super Mediato包含3个组件: 采集器、核心和输出器。采集器负责从文件或套接字摄取IPFIX记录,并将其提供给核心处理单元。超级调解器的核心处理每一条记录,根据记录的类型进行处理,并将其传递给输出器。输出器负责将记录写入输出流,如文件或套接字,并为该输出流生成特定的派生记录,并根据配置文件对输出的记录进行整理。
在命令行中启动时,Super Mediator可以使用命令行参数来配置,也可以使用--config参数来指定配置文件,当指定配置文件时,其它命令行参数就不再管用了。不过,官方推荐使用配置文件方式来启动。和YAF一样,当使用配置文件时,可以很方便的将YAF和Super Mediator当作服务来启动。比较符合我们将NetSA容器化的目标。
1. 输入配置
通过命令行,可以启动多个Super Mediator的采集器实例。Super Mediator的采集方式包括实时流、文件夹和文件3种,适用于不同的场合。
以下示例没有显示指定输出,输出会被定位到标准输出stdout接口。
(1)实时流监听
通过配置--ipfix-input指定传输协议,要么tcp,要么udp;通过配置--ipfix-port指定监听端口,读入IPFIX数据。
super_mediator --ipfix-input=tcp --ipfix-port=7777 localhost(2)文件夹拉取
通过配置一个或多个输入文件夹路径,Super Mediator会以--polling-interval为间隔,时刻监视文件下的文件,一旦有,就读取解析;如果设置了--move,解析完了就搬到move-dir;如果没有,解析完了就直接删掉。
super_mediator --move=/var/sm/complete /var/sm/incoming
super_mediator --move=/var/sm/complete --polling-interval=5 /var/sm/incoming
super_mediator --polling-interval=30 /var/sm/incoming /var/sm/incoming2(3)指定文件
这个没啥好说的,指定并处理一个已经存在的文件。
2. 输出配置
Super Meidator可以将IPFIX发送到其它主机和端口上,也可以将其输出为IPFIX、Json和其它指定大小的文件,当记录超过指定大小时,会自动生成新的文件。
以下示例没有指定输入,所以默认从标准输入stdin读取IPFIX数据。
(1)通过网络发送
可以使用--output-mode设置tcp或udp协议,通过--export-port指定发送的目的端口,通过--out指定发送的目的IP或者目的主机的主机名。
super_mediator --output-mode=tcp --out=localhost
super_mediator --output-mode=tcp --export-port=7788 --out=127.0.0.1(2)输出到文件夹
当指定--rotate参数的时候,Super Meidator将向指定的文件夹输入一个文件序列,输出的时间间隔由--rotate参数指定,官方建议为30秒。输出路径由--out参数指定,文件序列会以“YYYYmmddHHMMSS-NNNNN.扩展名”的方式进行编号命名。输出文件类型由--output-mode决定,输出类型可以为text、json等。
super_mediator --rotate=30 --out=/data/fccx
super_mediator --rotate=30 --output-mode=json --out=/data/fccx
super_mediator --rotate=30 --output-mode=text --out=/data/fccx(3)单个文件
当不指定--rotate参数时,输出单个文件
super_mediator --out=/data/my-file.ipfix
super_mediator --output-mode=json --out=/data/my-file.json
super_mediator --output-mode=text --out=/data/my-file.txt三、 rwflowpack
rwflowpack在CENTOS上的网络安全工具(三)NetSA SiLK离线部署 中没有深挖,毕竟能用就好。这里为了能够构建更加复杂的处理框架,所以打算深挖一下。
rwflowpack在NetSA工具集中,是作为SiLK流数据的收集器和封装器存在的,它的主要工作是将每个传入的流记录转换为SiLK的流格式,并且按照流的方向(就是那个twoway模板代表的含义)进行分类,对每条流标记其所属的传感器,进一步确定流需要存储到那个“小时文件”(SiLK是按照小时分割存储文件的)。
rwflowpack用来分类每条流记录的方式,使用2个文本形式的配置文件进行定义:
1. silk.conf
站点配置文件silk.conf用于定义classes、types、sensors。该配置文件的位置由rwflowpack命令的--site-config-file参数确定。如果该参数没有指定,则站点配置文件的位置将按找如下顺序搜索:
${SILK_CONFIG_FILE}
ROOT_DIRECTORY/silk.conf
${SILK_PATH}/share/silk/silk.conf
${SILK_PATH}/share/silk.conf
/usr/share/silk/silk.conf
/usr/share/silk.conf
ROOT_DIRECTORY要么由环境变量SILK_DATA_ROOTDIR指出,要么就使用硬编译到rwflowpack命令中的位置(/data)。
在silk.conf中,每一个非空行都由一个“命令名”开始,后面跟随一个或多个参数。主要的几个顶级命令如下:
(1)class
class class-name
class命令用于开始一个class定义块,其后跟随一个标识类型名称的参数。每个class必须有唯一的类型名称。定义块使用end class命令结束。如果一个站点不使用多类型定义,可以使用 class all或者class default来定义。且一个站点配置文件必须至少包含一行class定义。
default-types type-name
当在rwfilter和rwfglob命令中,没有指定type类型时,将使用所选定class的默认types;所以在此处的types将会被在这种场合下使用——如果啥都没定义的话,相当于rwfilter的时候没有任何type被允许pass,结果就是你看不到结果。
sensors sensor-name-or-group-ref
用于将sensor绑定到class中。这样使用在rwfilter中使用class参数进行过滤时就可以过滤到对应的sensors。支持使用名称绑定,也可以使用@引用group中的定义。
type flowtype-id type-name [flowtype-name]
type命令定义当前class的一个type的名字,并指定一个flowtype ID用于class/type对。进一步,可以设定一个flowtype-name。flowtype-id和flowtype-name在整个站点配置文件中应该是唯一的,但type-name只需要在类中保持唯一即可。
class all
sensors S0 S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
end class
(2)group
group用于为定义一个sensors列表提供方便的方式。
sensors sensor-name-or-group-ref
定义完成后使用end group结束
(3)sensor
sensor sensor-id sensor-name
sensor sensor-id sensor-name "sensor-description"
用于定义sensor的ID和名称。
sensor 0 S0 "Description for sensor S0"
sensor 1 S1
sensor 2 S2 "Optional description for sensor S2"
sensor 3 S3
sensor 4 S4
sensor 5 S5
sensor 6 S6
sensor 7 S7
sensor 8 S8
sensor 9 S9
sensor 10 S10
sensor 11 S11
sensor 12 S12
sensor 13 S13
sensor 14 S14packing-logic "filename"
该命令为rwflowpack命令的--packing-logic参数,指向一个插件的so文件。这个插件提供决定流记录如何被分类到class和type的函数。
比如默认的type的值,实在packlogic-twoway.c的代码中定义的。也就是说,如果想自定义type-id,那么packing-logic也是需要修改的
# Be sure you understand the workings of the packing system before
# editing the class and type definitions below. In particular, if you
# change or add-to the following, the C code in packlogic-twoway.c
# will need to change as well.
class all
type 0 in in
type 1 out out
type 2 inweb iw
type 3 outweb ow
type 4 innull innull
type 5 outnull outnull
type 6 int2int int2int
type 7 ext2ext ext2ext
type 8 inicmp inicmp
type 9 outicmp outicmp
type 10 other other
default-types in inweb inicmp
end class
2. sensor.conf
sensor.conf文件的位置可以由rwflowpack命令的--sensor-configuration参数指定。如果没有指定,则rwflowpack使用环境变量SILK_PATH中定义的位置来搜索该配置文件。SILK_PATH实际则是用来定义silk的安装目录的。
sensor.conf文件包含多个名为“sensor”的定义块,每个定义块定义了对应的sensor用来分类所捕获流记录的配置信息;同时,该文件也定义了多个名为“probe”的块,该定义块定义的是流记录的采集方式(NetFlow v5,IPFIX,NetFlow v9),并定义probe映射到sensor的方式。
(1)probe
probe定义流量数据的来源,其名称必须唯一。一般来说是定义一个本机用于监听的端口,rwflowpack从该段偶以指定的形式监听从Netflow或IPFIX流数据。这些流数据是路由器或者yaf软件生成的。
probe P1 ipfix
listen-on-port 18001
protocol tcp
listen-as-host pignode1
end probe
probe也可以用来监视目录,对目录中的循环生成文件(比如来自yaf)进行处理。
(2)sensor
sensor用来定义一个用于分析的逻辑收集点。按照sensor定义的配置,rwflowpack可以根据流记录在收集站点Site处的传输(出站、入站)方式,对每个流量记录进行分类。由于传感器信息和类别信息(称为flowtypes或作为class/type对)本身也可被用于分析,在站点配置文件中对它们也进行了定义。配置文件将sensor映射到probe,并指定对数据进行分类所需的规则。通常一个sensor对应一个probe;但是,也可以一个sensor由多个probe组成,或者在一个probe上收集的流数据可能由多个sensor处理。
sensor S1
ipfix-probes P1
internal-ipblocks 192.168.65.0/24
external-ipblocks remainder
end sensor
例如在该站点,定义192.168.65.0 /24为内网,其余为外网。rwflowpack即根据该数值对跨sensor的流数据进行分类。
(3)group
group就是一个名字列表,可以把它看作是环境变量定义,只不过这个环境变量需要用@进行引用。通常group会被用于定义CIDR网段,IPset名单和SNMP、VLAN编号等。
如,一个完整的配置文件定义示例:
probe S3 ipfix
listen-on-port 9903
protocol tcp
listen-as-host 192.168.1.92
end probe
group my-network
ipblocks 128.2.0.0/16
end group
sensor S3
ipfix-probes S3
internal-ipblocks @my-network
external-ipblocks remainder
end sensor四、单机镜像制作
1. CENTOS7上添加LIFTeR库
参考CENTOS上的网络安全工具(三)NetSA SiLK离线部署这篇很早以前的文章,其实在Centos7上构建NetSA的环境还是比较费劲的。主要原因在于Centos7停更之后,造成一些镜像源失效。完全按照官方的给出的步骤安装,会碰到一些不可名状的问题。
在容器中,这一问题会更甚:在我们直接导入的centos:centos7的容器里,repos库中是不可能有NetSA工具的安装地址的。这个地址要安装过cert-forensics-tools的rpm包才会有,具体长这样:
[root@5f8c7b1c9a94 /]# cd /etc/yum.repos.d/
[root@5f8c7b1c9a94 yum.repos.d]# ls
CentOS-Base.repo CentOS-Debuginfo.repo CentOS-SCLo-scl-rh.repo CentOS-Vault.repo CentOS-x86_64-kernel.repo epel-testing.repo
CentOS-CR.repo CentOS-Media.repo CentOS-Sources.repo CentOS-fasttrack.repo cert-forensics-tools.repo epel.repo
[root@5f8c7b1c9a94 yum.repos.d]# cat cert-forensics-tools.repo
[forensics]
name=CERT Forensics Tools Repository
baseurl=http://www.cert.org/forensics/repository/centos/cert/$releasever/$basearch
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-cert-forensics-2025-03-24
gpgcheck=1
[forensics-test]
name=CERT Forensics Tools Test Repository
baseurl=http://www.cert.org/forensics/repository/centos/cert-test/$releasever/$basearch
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-cert-forensics-2025-03-24
gpgcheck=1
[forensics-splunk]
name=CERT Forensics Tools Repository - Splunk
baseurl=http://www.cert.org/forensics/repository/centos/splunk/$releasever/$basearch/
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-splunk
enabled=1
gpgcheck=1
[forensics-sip]
name=CERT Forensics Tools Repository - SiLK, IPA, and Postgresql
baseurl=http://www.cert.org/forensics/repository/centos/sip/$releasever/$basearch
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-cert-forensics-2025-03-24
gpgcheck=1
但是按照官网的安装指南,在yum install epel-release 和 yum -y install centos-release-scl-rh之后,继续拓展到netsa的库,执行yum install CERT-Forensics-Tools就会出问题,找不到镜像。这个问题应该是因为Centos7不再支持的原因:使用官方镜像源安不下去,使用国内镜像源当然不可能包含NesSA的源。死锁……
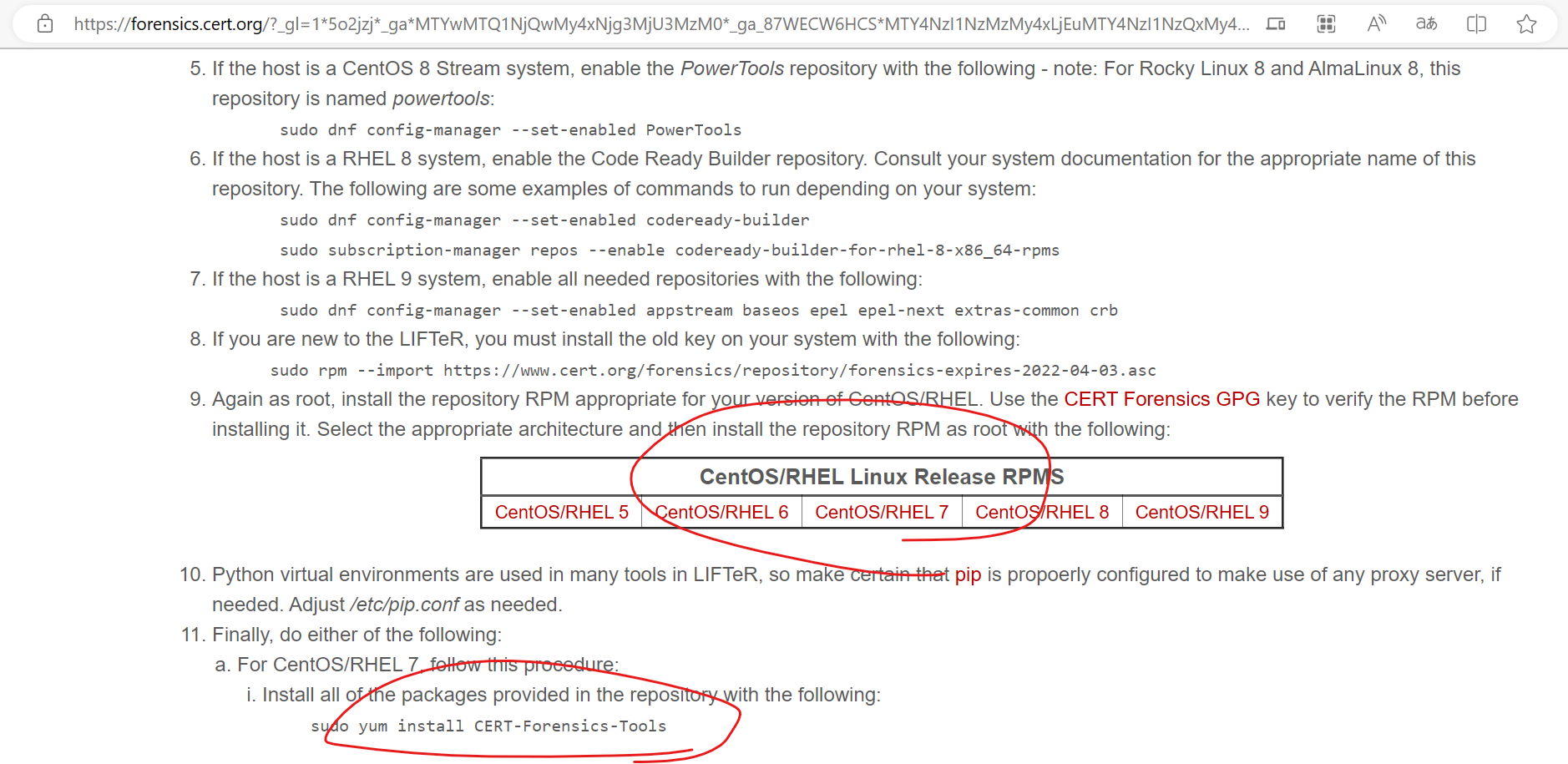
不过好在这个rpm包在LIFTeR - The CERT Linux Incident Response and Forensics Tools Repository上可以下载得到,直接安装即可添加如上的repo库。当然,按照上面的内容,手工添加repo库,我猜想也没问题。
2. 构建基础镜像
参考CENTOS上的网络安全工具(三)NetSA SiLK离线部署中需要安装的组件——其实也就是官方文档中给出的安装步骤,将所有可能用到的组件先打包到一个基础容器里面。之所以要多出这么一部,主要是NetSA的镜像太不稳定了,诸多的安装包命令甚至无法一路RUN到底,随机性因为网络连接的问题安装错误,导致我还不得不分作几段安装。所以还是先整个基础镜像把它们都下载好了慢慢折腾来得靠谱些。
Dockfile:
FROM centos:centos7
COPY rpm/cert-forensics-tools-release-el7.rpm /root/.
RUN yum install epel-release -y \
&& yum install centos-release-scl-rh -y \
&& rpm -ivh /root/cert-forensics-tools-release-el7.rpm \
&& yum install epel-release -y \
&& yum install centos-release-scl-rh -y \
&& yum install cert-forensics-tools-release -y
RUN yum install libfixbuf -y \
&& yum install silk-common -y \
&& yum install silk-analysis -y \
&& yum install silk-rwflowpack -y \
&& yum install yaf -y
RUN yum install libfixbuf-ipfixDump -y \
&& yum install silk-flowcap -y \
&& yum install silk-rwflowappend -y \
&& yum install silk-rwpollexec -y \
&& yum install silk-rwreceiver -y \
&& yum install silk-rwsender -y
RUN yum install super_mediator analysis-pipeline -y \
&& rm -rf /root/cert-forensics-tools-release-el7.rpm
CMD ["/bin/bash"]
将其打包成silkbase镜像以待后用
[root@pighost Dockerfile-silk]# docker build -t pig/silkbase .
搞定以后,大概这个样子:
[root@pighost Dockerfile-silk]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
pig/silkbase latest 198af61934b0 8 minutes ago 1.34GB
centos centos7 eeb6ee3f44bd 21 months ago 204MB
3. 在基础镜像上进行配置
在基础镜像的基础上,我们首先将单机版的yaf+rwflowpack+silk构建起来。这涉及到几个配置文件和文件夹。
(1)目录映射
首先将基础镜像使用交互式方式运行起来:
docker run -it --name pig \
-v ./pcap:/pcap:ro \
-v ./data:/data:rw \
-v ./conf:/var/silk/conf:ro \
-v './rwflowpack/rwflowpack.conf':'/etc/sysconfig/rwflowpack.conf':ro \
pig/silkbase bash
这里需要做4个映射。分别是
1)映射yaf数据输入目录 /pcap
这是我们自己取名的目录,提供给yaf程序监控。如果我们需要把文件放到这个目录下,yaf就会自动处理,则不能设置只读,且必须在设置一个空目录,确保yaf处理完该目录中的文件后,能够把处理后的文件搬走。
2)映射rwflowpack处理结果输出目录/data
这个就是存放IPFIX数据的地方,将其映射出来,一个是考虑到这个数据量也会很大;另一个,是方便带走,只要设定好SILK_DATA_ROOTDIR,rwfilter就可以直接处理。
3)映射配置文件目录(包括站点配置文件和传感器配置文件)/var/silk/conf
包括了站点配置文件和传感器配置文件。把编辑好的配置存档,以只读映射的方式提供给容器使用再合适不过。
4)映射rwflowpack配置文件
和上面相同的考虑,先编辑好,再映射。
(2)站点配置文件及其映射位置
站点配置文件会被2个程序使用:一个是rwflowpack,其搜索站点文件的方法在其自身的配置文件/etc/sysconfig/rwflowpack.conf中指定;另一个是rwfilter,其搜索站点文件的方法在前面有描述,也就是如果不显式指定的话,会使用SILK_CONFIG_FILE环境变量指定的文件,或者是在SILK_DATA_ROOTDIR环境变量指定的目录下,SILK_PATH环境变量对应的安装目录搜索silk.conf。
所以,站点配置文件的地址需要在2个地方设置:
1)在/etc/sysconfig/rwflowpack.conf中设置
# The full path to the site configuration file. Used by
# --site-config-file. If not set, defaults to silk.conf in the
# ${DATA_ROOTDIR}.
SITE_CONFIG=/var/silk/conf/silk.conf2)在环境变量SILK_CONFIG_FILE中设置
[root@a32e6d256dd8 silk]# export SILK_CONFIG_FILE=/var/silk/conf/silk.conf
这样,rwfilter就不会在启动时报告找不到站点文件:
[root@a32e6d256dd8 silk]# rwfilter --type=all --start-date=2022/11/15 --end-date=2022/11/16 --all=stdout|rwstats --field=dip --count=10
rwfilter: Site configuration file not found
rwstats: Error processing headers on file '-': Unexpected end of file while reading header
(3)传感器配置文件
sensors.conf主要由rwflowpack文件使用。所以在/etc/sysconfig/rwflowpack.conf中设置它的位置就行:
# The full path to the sensor configuration file. Used by
# --sensor-configuration. YOU MUST PROVIDE THIS (the value is ignored
# when INPUT_MODE is "respool").
SENSOR_CONFIG=/var/silk/conf/sensors.conf(4)rwflowpack的配置文件
如前所述,rwflowpack以服务模式运行,开放用户指定的端口接受网络流记录并将其按照规定的格式分类存储。其运转除了需要配置站点配置文件、传感器配置文件的目录地址外,还需要其它的配置项,这些在/etc/sysconfig/rwflowpack.conf文件中指定:
1)使能rwflowpack
# Set to non-empty value to enable rwflowpack
ENABLED=1
2)状态文件目录
# These are convenience variables for setting other values in this
# configuration file; their use is not required.
statedirectory=/var/silk/staterwflowpack会在这个目录下建立error目录和log目录,以记录rwflowpack的处理状态
3)创建文件夹
# If CREATE_DIRECTORIES is set to "yes", the directories named in this
# file will be created automatically if they do not already exist
CREATE_DIRECTORIES=yes对于不存在的目录,比如上面提到的error和log,自动创建文件夹,否则需要手工创建,不然会报告文件夹不存在的错误。
4)输出分类数据的目录
# Flow files will be written. Used by --root-directory.
DATA_ROOTDIR=/data即输出结果的路径。这个输出结果时rwfilter的输入位置,所以需要和SILK_DATA_ROOTDIR环境变量保持一致。故而,对于rwfilter的使用来说,就需要如下设置
[root@a32e6d256dd8 silk]# export SILK_DATA_ROOTDIR=/data其余目前保持默认设置即可。
(5)测试运行情况
我们将测试用的pcap包放在映射的目录中,使用yaf进行处理(当然需要先将rwflowpack服务启动起来,如何启动放在下一节讲)
[root@a32e6d256dd8 /]# yaf --in /pcap/*.pcap --silk --out localhost --ipfix tcp --ipfix-port 18001
[2023-06-22 03:18:37] Rejected 62016 out-of-sequence packets.
由于采样时数据有截断,所以这里抛弃了一些失序的包。执行完成后,在我们映射的data目录下可以看到处理的结果:
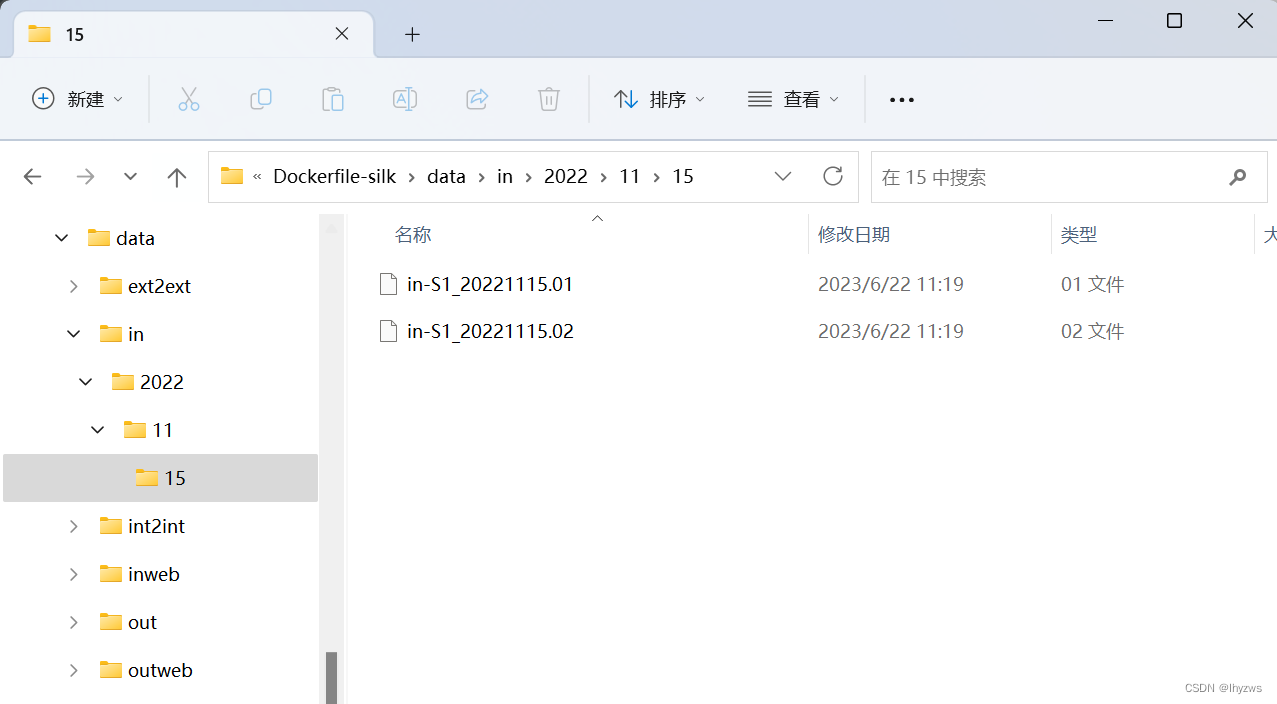
可以看到数据按照站点配置文件中定义的type分类方式以小时文件的方式,按照时间归档存储了。
此时执行rwfilter(注意SILK_DATA_ROOTDIR配置好,否则找不到数据):
[root@a32e6d256dd8 data]# rwfilter --type=all --start-date=2022/11/15 --end-date=2022/11/16 --all=stdout|rwstats --field=dip --count=10
INPUT: 8929 Records for 521 Bins and 8929 Total Records
OUTPUT: Top 10 Bins by Records
dIP| Records| %Records| cumul_%|
192.168.182.76| 1525| 17.079180| 17.079180|
239.255.255.250| 1307| 14.637697| 31.716878|
ff02::1:3| 1018| 11.401053| 43.117930|
192.168.137.113| 947| 10.605891| 53.723821|
224.0.0.252| 915| 10.247508| 63.971329|
183.47.103.43| 204| 2.284690| 66.256020|
192.168.182.255| 149| 1.668720| 67.924740|
114.114.114.114| 126| 1.411132| 69.335872|
224.0.0.251| 125| 1.399933| 70.735805|
ff02::fb| 107| 1.198342| 71.934147|
4. 在基础镜像上构建单机镜像
(1)yaf + rwflowpack + rwfilter
在基础镜像上构建yaf+rwflowpack+rwfilter的单机镜像,主要就是提前设置好环境变量、映射好配置文件和数据目录,然后启动rwflowpack服务。
1)Dockerfile
#从silk基础镜像开始,跳过上面需要网络下载的过程
FROM pig/silkbase
COPY ./init-silk.sh /root/.
#配置环境变量
RUN chmod +x /root/init-silk.sh \
&& echo 'export SILK_DATA_ROOTDIR=/data' >> /root/.bashrc \
&& echo 'export SILK_CONFIG_FILE=/var/silk/conf/silk.conf' >> /root/.bashrc
CMD ["/root/init-silk.sh"]
2)初始化脚本
#! /bin/bash
#启动rwflowpack服务
/etc/rc.d/init.d/rwflowpack start
tail -f /dev/null
rwflowpack服务并不是像我们在CENTOS上的网络安全工具(十四)搬到Docker上(2)?_ 里面描述的那样,是通过service配置文件指定的启动方法,而是使用了init.d脚本的方式。也就是在/etc//rc.d/init.d目录下放置了一个脚本文件rwflowpack,这个脚本文件支持使用start stop等作为参数。实际上,service start ……也是使用这种脚本方式启动的服务。
3)启动命令
[root@pighost Dockerfile-silk]# docker run -itd --name pig \
-v /root/share/pcap:/pcap \
-v /root/share/data:/data \
-v ./conf:/var/silk/conf \
-v './rwflowpack/rwflowpack.conf':'/etc/sysconfig/rwflowpack.conf' \
pig/silk:single
Starting rwflowpack: rwflowpack: Ignoring --error-directory since no probes use directory polling
[OK]
然后使用docker exec -it pig bash进去后,执行yaf,处理文件并发送到本机18001接口即可完成数据处理,进而使用rwfilter进行分析。
(2)yaf + super mediator + mothra
话说,如果只是希望如之前一样,使用标准的流数据和silk工具进行分析,那么yaf+rwflowpack+rwfilter的组合就可以了,之所以要在yaf和rwflowpack之间加入一个super-mediator,主要是需要super-mediator进行DPI解析——官方就这么说的。
由于这个组合需要我们自行编译yaf,super mediator还有大量的参数需要学习,所以我们需要另开一贴,不然这篇文章就太长不过了。