用到环境
1、pycharm community edition 2022.3.2
2、Python 3.10
整篇内容都已上传至我的csdn资源中,想用的请移步。
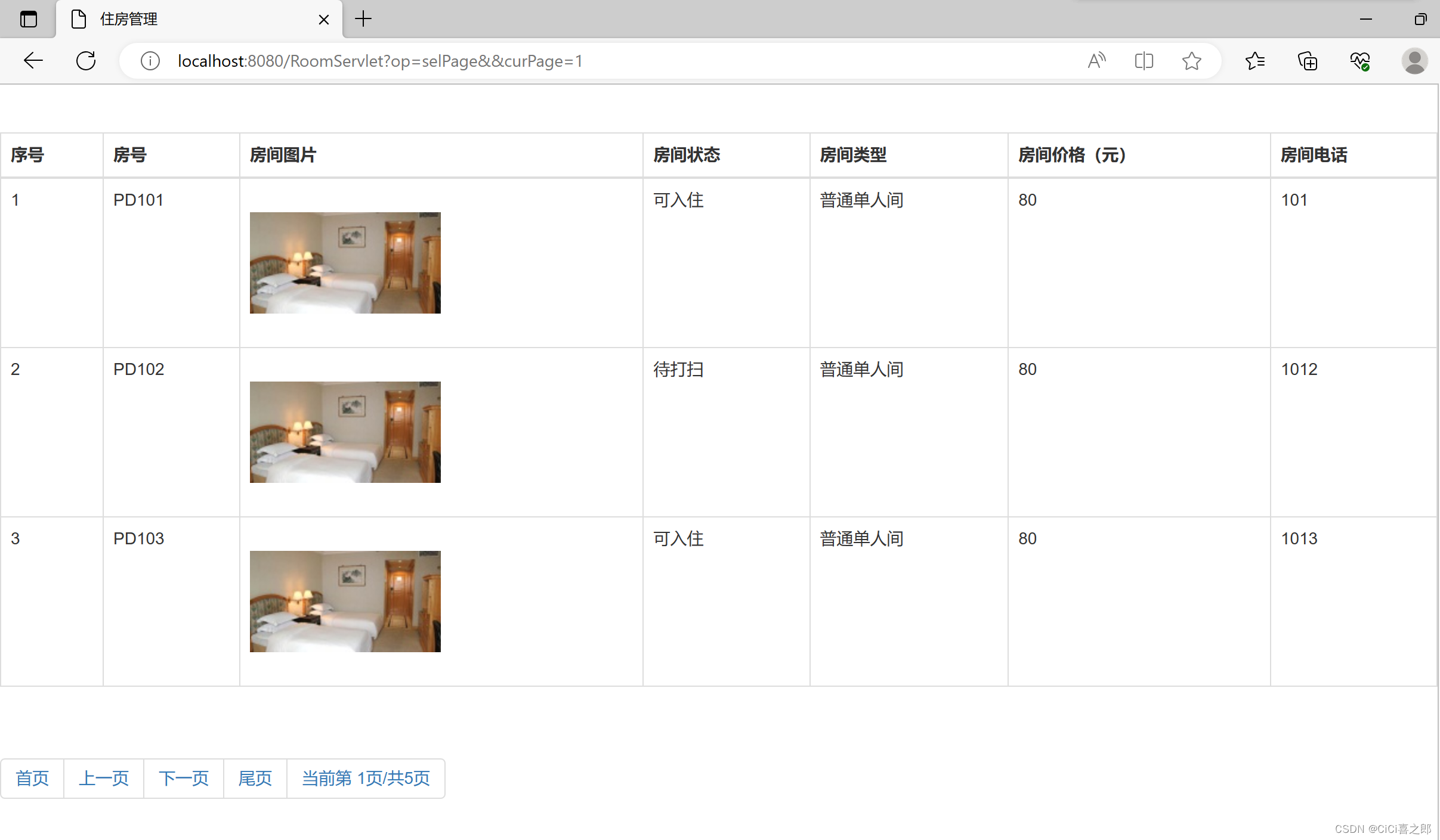
流程
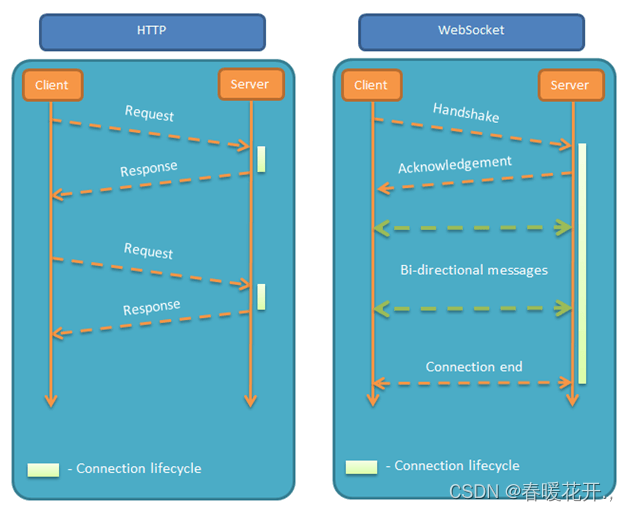
多任务级联卷积神经网络(Multi-task Cascaded Convolutional Networks, MTCNN)算法进行人脸检测
普通人脸检测
单人人脸检测

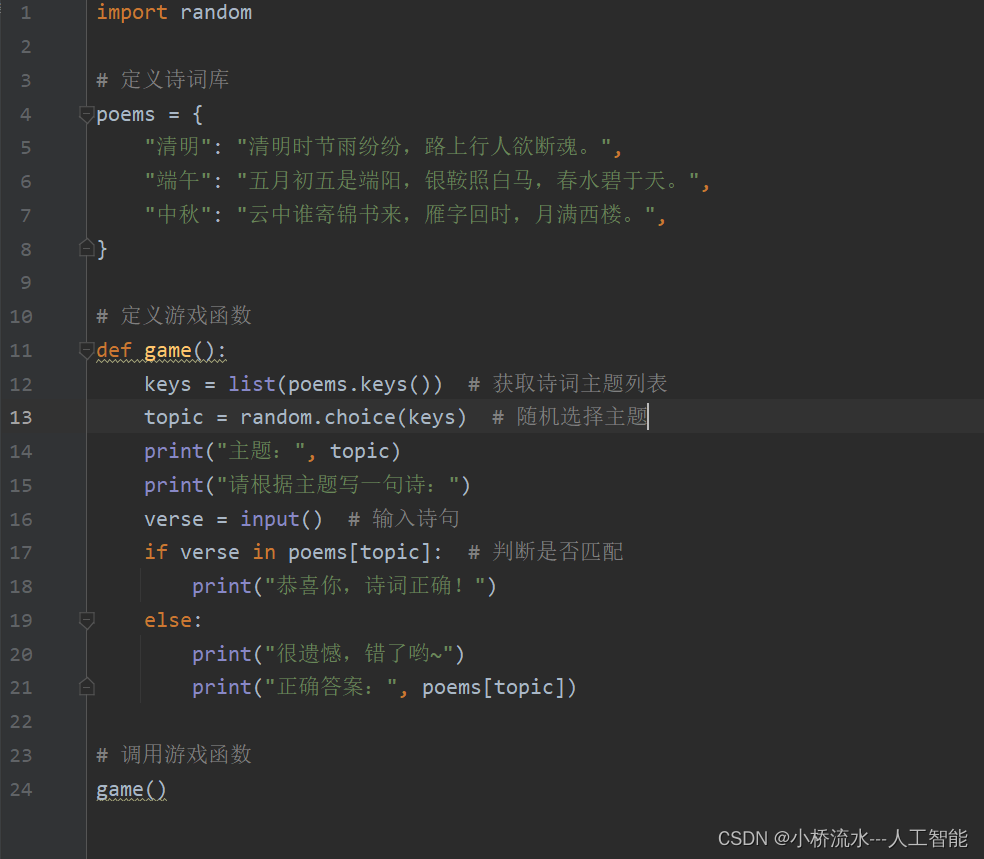
分析:可以看出在单人人脸检测时,MTCNN方法很好的画出了人脸的检测框以及很准确的检测出了眼睛、笔尖、嘴角的一共五个点,实现效果很好。
双人人脸检测

分析:可以看出在双人人脸检测时,MTCNN方法很好的画出了人脸的检测框以及不管是张嘴还是闭嘴都很准确的检测出了眼睛、笔尖、嘴角的一共五个点,实现效果很好。
多人人脸检测

图3 多人人脸检测
分析:可以看出在多人人脸检测时,MTCNN方法依然能很好的画出了人脸的检测框以及准确的检测出了眼睛、笔尖、嘴角的一共五个点,实现效果很好。
特殊情况的人脸检测
侧拍

分析:可以看出在即使在侧拍角度,五官的位置相较于普通情况很不一样,MTCNN方法还是可以很好的画出了人脸的检测框以及很准确的检测出了眼睛、笔尖、嘴角的一共五个点,实现效果很好。
在侧拍照片中,由于人脸的姿态发生了变化,传统的基于Haar或者HOG特征的人脸检测算法可能无法准确地检测出人脸区域,而MTCNN可以通过多尺度的滑动窗口搜索技术,在不同尺度下对人脸进行全局检测。同时,MTCNN中的关键点回归模块可以通过学习人脸形态学信息,准确地预测出人脸的五个关键点位置,即左眼、右眼、鼻子、左嘴角和右嘴角。
因此,即使是在侧拍照片中,MTCNN也可以通过深度神经网络的强大表征能力和多任务学习的方法,实现对人脸区域的准确检测和关键点的精确定位。
有遮挡

可能原因是:虽然戴着眼镜的人脸与不戴眼镜的人脸在外观上存在差异,但是这些关键点位置通常是比较稳定的,并且MTCNN在训练过程中已经学习到了戴眼镜人脸的特征,所以在实际应用中,MTCNN可以很好地检测带眼镜的人脸关键点。
类人生物

可能原因:虽然猪鼻子和人的鼻子的人脸以及睁眼和闭眼在外观上存在差异,但是这些关键点位置通常是比较稳定的,并且MTCNN在训练过程中已经学习到了戴眼镜人脸的特征,所以在实际应用中,MTCNN可以很好地检测带眼镜的人脸关键点。
人脸对齐问题

分析:以上是两组人脸对齐的实验结果,可以看出通过将检测到的人脸关键点与参考关键点进行比较的方法可以很好的进行人脸对齐。

分析:以上是一组人脸对齐的实验结果,可以看出通过将检测到的人脸关键点与参考关键点进行比较的方法可以很好的进行人脸对齐,只是对齐结果的图片顶部出现不明黑色区域。出现原因是人脸对齐的框的大小是实现给定的固定值,当人脸对齐的结果在边缘(这里在顶部)且小于给定值时,会用黑色填充空白区域。
更多面部特征点提取问题

分析:以上是dlip更多面部特征点提取结果,左边是单人的面部特征点提取结果,右边是多人的面部特征点提取结果。可以看出与MTCNN相比,DLIP确实可以检测更多的面部特征点,而且实现效果好。
代码:
主函数
import cv2
from mtcnn import MTCNN
detector = MTCNN()
image = cv2.cvtColor(cv2.imread("12.jpg"), cv2.COLOR_BGR2RGB)
result = detector.detect_faces(image)
# Result is an array with all the bounding boxes detected. We know that for 'ivan.jpg' there is only one.
for person in result:
bounding_box = person['box']
keypoints = person['keypoints']
cv2.rectangle(image,
(bounding_box[0], bounding_box[1]),
(bounding_box[0]+bounding_box[2], bounding_box[1] + bounding_box[3]),
(0,155,255),
2)
cv2.circle(image,(keypoints['left_eye']), 2, (0,155,255), 2)
cv2.circle(image,(keypoints['right_eye']), 2, (0,155,255), 2)
cv2.circle(image,(keypoints['nose']), 2, (0,155,255), 2)
cv2.circle(image,(keypoints['mouth_left']), 2, (0,155,255), 2)
cv2.circle(image,(keypoints['mouth_right']), 2, (0,155,255), 2)
cv2.imwrite("12_draw.jpg", cv2.cvtColor(image, cv2.COLOR_RGB2BGR))
print(result)
人脸对齐
import cv2
import numpy as np
from mtcnn import MTCNN
# Define the reference landmarks that the face will be aligned to
ref_landmarks = np.array([
[30.2946, 51.6963],
[65.5318, 51.5014],
[48.0252, 71.7366],
[33.5493, 92.3655],
[62.7299, 92.2041]
], dtype=np.float32)
def align_face(img, landmarks):
# Convert landmarks to a NumPy array
landmarks = np.array([list(landmarks.values())], dtype=np.float32)
# Calculate the transformation matrix using the reference and detected landmarks
M, _ = cv2.estimateAffinePartial2D(landmarks, ref_landmarks)
# Apply the transformation matrix to the image
aligned_img = cv2.warpAffine(img, M, (96, 112), flags=cv2.INTER_CUBIC)
return aligned_img
# Load the input image
img = cv2.imread('3.jpg')
# Initialize MTCNN
detector = MTCNN()
# Detect faces using MTCNN
faces = detector.detect_faces(img)
# For each detected face, align the face and save the result
for face in faces:
landmarks = face['keypoints']
aligned_face = align_face(img, landmarks)
cv2.imwrite('3_aligned_face.jpg', aligned_face)
更多面部特征点提取问题
import cv2
import dlib
# 读取图片
img_path = "1.jpg"
img = cv2.imread(img_path)
# 转换为灰阶图片
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 正向人脸检测器
detector = dlib.get_frontal_face_detector()
# 使用训练完成的68个特征点模型
predictor_path = "shape_predictor_68_face_landmarks.dat"
predictor = dlib.shape_predictor(predictor_path)
# 使用检测器来检测图像中的人脸
faces = detector(gray, 1)
for i, face in enumerate(faces):
# 获取人脸特征点
shape = predictor(img, face)
# 遍历所有点
for pt in shape.parts():
# 绘制特征点
pt_pos = (pt.x, pt.y)
cv2.circle(img, pt_pos, 1, (255,0, 0), 2)
cv2.imshow('opencv_face_laowang',img) # 显示图片
cv2.waitKey(0) # 等待用户关闭图片窗口
cv2.destroyAllWindows()# 关闭窗口
编写不易,求个点赞!!!!!!!
“你是谁?”
“一个看帖子的人。”
“看帖子不点赞啊?”
“你点赞吗?”
“当然点了。”
“我也会点。”
“谁会把经验写在帖子里。”
“写在帖子里的那能叫经验贴?”
“上流!”
cheer!!!