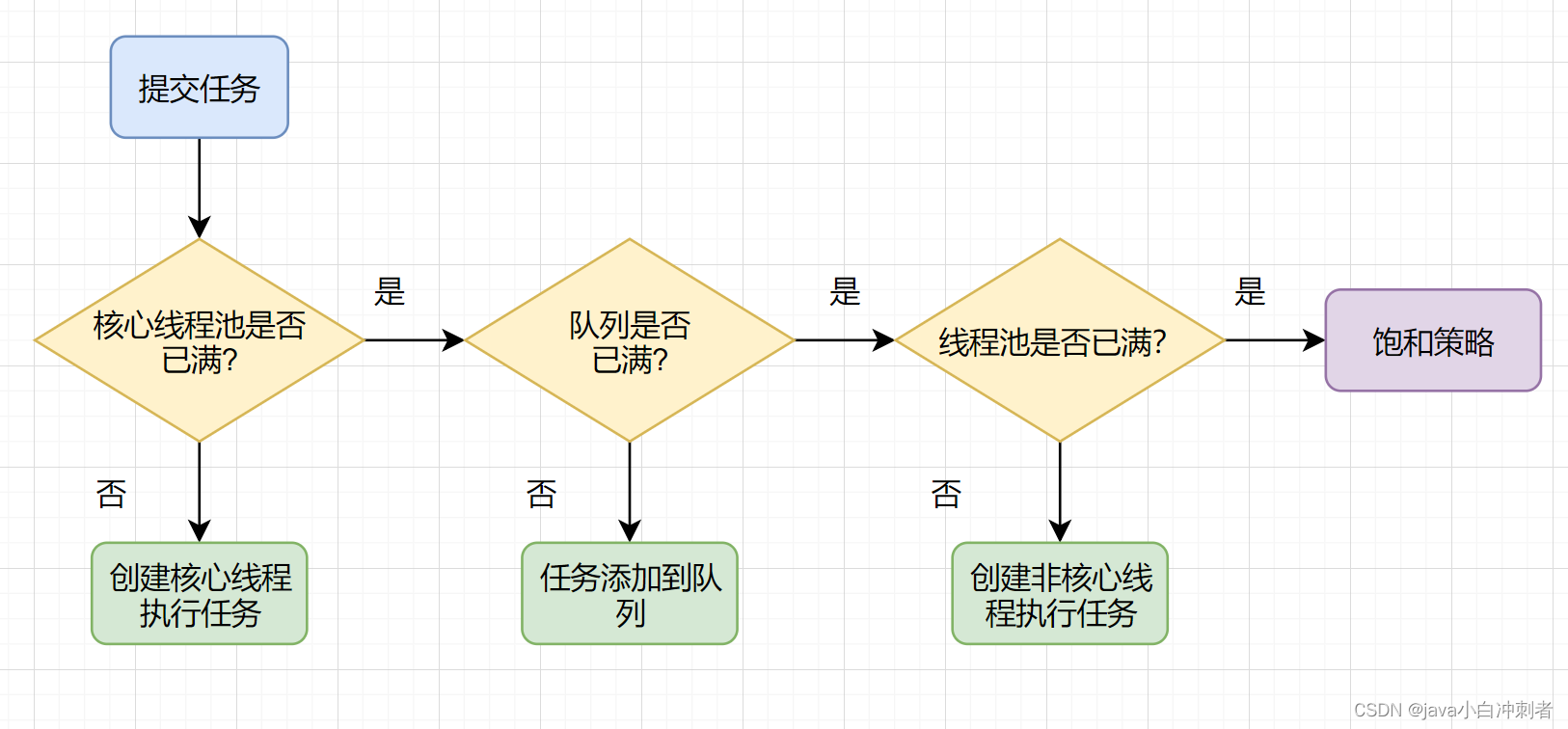
Faster R-CNN(Region-based Convolutional Neural Network)是一种基于区域的卷积神经网络用于目标检测任务的模型。它是一种两阶段的目标检测方法,主要包含以下几个步骤:
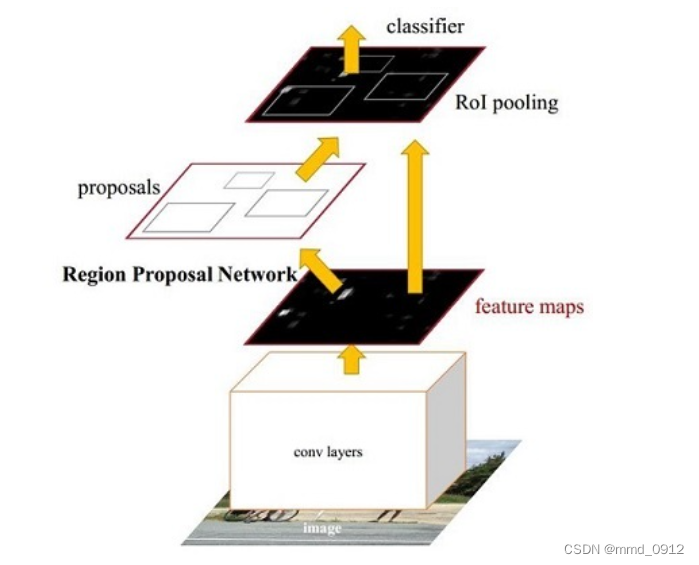
- Region Proposal Network(RPN): Faster R-CNN首先通过共享卷积层对输入图像进行特征提取,然后通过Region Proposal Network生成候选目标边界框。RPN会在每个位置上滑动一个固定大小的窗口,在窗口上生成多个不同尺寸和比例的锚框,然后通过分类网络和回归网络对锚框进行分类和精细化调整,生成候选目标边界框。
- Region of Interest Pooling(RoI Pooling): 在RPN生成的候选目标边界框上进行RoI Pooling操作,将每个候选边界框划分为固定大小的特征图区域,将这些区域映射到固定大小的特征图上。
- Classification and Regression: 将划分后的固定大小的特征图区域输入到分类网络和回归网络中。分类网络用于判别每个区域是否包含目标,回归网络用于对每个候选边界框进行位置和大小的微调。
Faster R-CNN通过这样的两阶段方式实现目标检测,相比于之前的方法,它在准确性和速度上都有很大的提升。这种方法的主要优势在于可以共享特征提取的卷积层,减少了计算量,并且通过RPN生成候选边界框,可以更准确地定位目标。
faster rcnn网络架构图如下所示: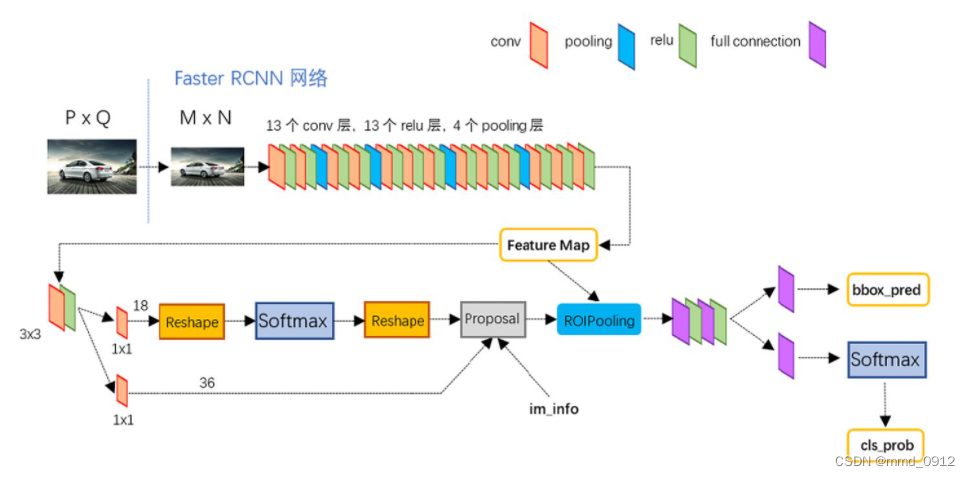
RPN的流程如下所示:
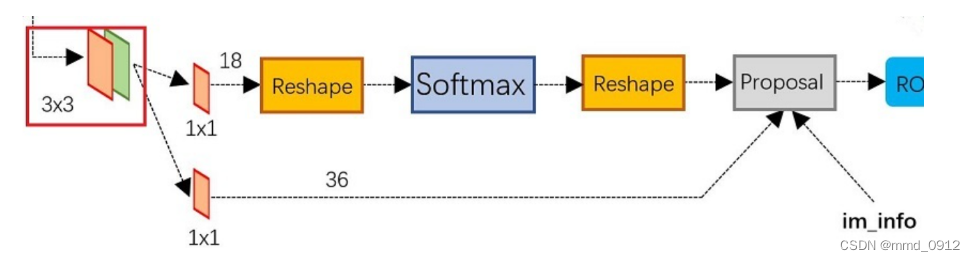
网络流程如下所示:
faster rcnn训练流程:
Faster R-CNN的训练流程主要包括以下步骤:
1.数据准备:首先需要准备好训练数据集和测试数据集,并对其进行注。标注包括每个物体的位置和类别信息,在训练阶段使用标注信息来计算损失并更新模型。
2.提取特征:使用特定的卷积神经网络模型(如VGG,ResNet等)作为特征提取器,对输入的图像进行特征提取。特征提取的方式可以是预训练的模型,也可以是现场训练的模型。
3.生成候选区域:使用区域提议网络(Region Proposal Network, RPN)来生成候选区域。RPN是一个用于检测各种大小和宽高比的物体的深度卷积神经网络。
4.区域分类:对候选区域进行分类,得出每个候选区域包含物体的类别概率。
5.边框回归:对候选区域进行边框回归,得出物体的准确位置(即左上角坐标和右下角坐标)。
6.损失计算:将分类和边框回归的结果与标注信息进行比较,计算分类损失和边框回归损失,并将两者相加得到总损失。
7.参数更新:使用总损失来更新模型参数,使得模型在下一轮迭代中能够更好地预测物体位置和类别。
faster rcnn的网络结构:
model = dict(
type='FasterRCNN',
pretrained='torchvision://resnet101',
backbone=dict(
type='ResNet',
depth=101,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.2, 0.5, 1.0, 2.0, 5.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=3,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))))
train_cfg = dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.55,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_across_levels=False,
nms_pre=2000,
nms_post=1000,
max_num=1000,
nms_thr=0.7,
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False))
test_cfg = dict(
rpn=dict(
nms_across_levels=False,
nms_pre=1000,
nms_post=1000,
max_num=1000,
nms_thr=0.7,
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100))
dataset_type = 'VOCDataset'
data_root = 'VOC2007'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='Resize', img_scale=(1600, 928), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.8),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1600, 928),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=1,
workers_per_gpu=0,
train=dict(
type='VOCDataset',
ann_file=
'VOC2007/ImageSets/Main/train.txt',
img_prefix='VOC2007',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1600, 928), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.8),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]),
val=dict(
type='VOCDataset',
ann_file=
'VOC2007/ImageSets/Main/train.txt',
img_prefix='VOC2007',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1600, 928),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='VOCDataset',
ann_file=
'VOC2007/ImageSets/Main/train.txt',
img_prefix='VOC2007',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1600, 928),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
evaluation = dict(interval=1, metric='mAP')
optimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
total_epochs = 16
checkpoint_config = dict(interval=1)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
dist_params = dict(backend='nccl')
log_level = 'INFO'
work_dir = './'
load_from = None
resume_from = None
workflow = [('train', 1)]
gpu_ids = range(0, 1)