自动化测试的每次执行,都会产生大量的日志信息。特别是当执行发生错误,比如数据库异常、通讯异常等情况的时候,大量执行的自动化测试用例会报错。
实际上,很多错误的类型是比较类似的,但由于测试用例的数量很大,比如一次执行20,000个测试用例,可能会产生500个错误。逐个分析500个错误日志,是一件非常消耗时间的工作。

因此,TestOne提供了自动分类算法,帮助我们首先把错误的日志分成不同的类型,这样我们就可以批量处理相同类型的日志,从而大大节省了处理时间。
TestOne是泽众软件自主研发的一体化测试系统,基于B/S 体系结构,集自动化项目管理、测试需求管理、测试用例管理、缺陷问题管理、自动化测试执行管理、远程真机调试、移动脚本设计等功能于一体,覆盖了GUI界面功能自动化测试、接口自动化测试、移动自动化测试、移动APP性能测试等测试类型,完整覆盖自动化测试项目的全过程,可快速将自动化测试管理体系建立,提高测试效率与质量。

下面,我们就来介绍一下TestOne的日志处理。
日志存放
当我们执行海量的自动化测试用例,就会生成海量的错误日志,比如日志文件、错误截图、错误的视频等等。
海量日志数据带来的问题是:导致整个系统的效率变得低下,系统卡顿。会严重影响测试用例设计者的工作效率。
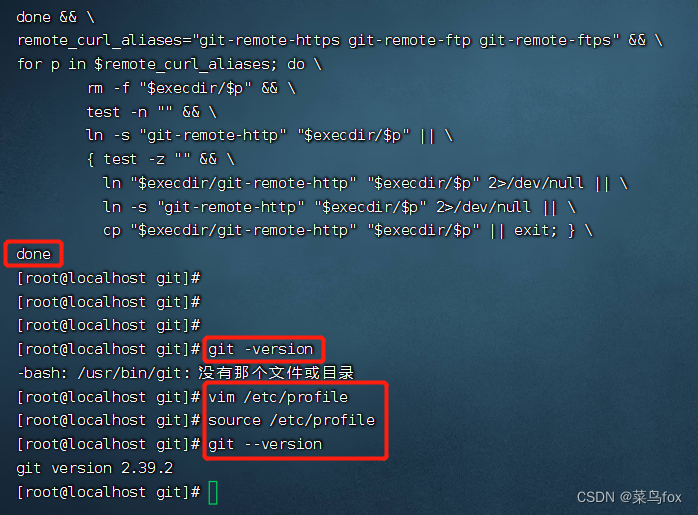
因此,TestOne采用了“外挂式”的日志模式,即:错误日志存放在独立E/S系统内,不影响用户的检索效率,也不影响日常系统的使用。
E/S日志系统,还带来了额外的两个特性:日志分布式存储和智能化检索。
分布式日志系统,能够把海量的日志信息存放在分布式系统下的不同节点之下,防止频繁和大量的访问带来的性能瓶颈。此外,对于日志清理工作,也可以独立执行,不影响主系统的功能操作。
智能化检索,就是E/S系统自带的一个功能,通过定义日志中出现的特征字符串,来自动化的检索日志,查找自己需要的信息,而不需要用户逐个查看。
错误自定义
对于经常发生的错误,或者发现了某个错误,用户就可以定义一个“特征字符串”,来“扫描”整个日志,并且根据扫描结果来自动匹配。
错误自定义,就是指用户可以通过定义一个“特征字符串”,来智能扫描和分析日志。
错误归类
在用户定义了“特征字符串”集合,系统就可以根据扫描结果,对错误进行归类。
对于用户而言,就可以看到不同错误的集合,每个集合匹配了一类的错误。
从自动化测试的实践而言,一类的错误,往往都出自于一个原因,比如:网络异常断开、数据库突然无法访问、文件系统异常、被测试系统(AUT)出错等,处理的方式都是一样的。这样,我们就从逐个查看和处理错误的过程,变成了只需要处理一类的错误,就可以完成所有的、海量的错误处理,从而把工作效率提升了几十倍。
什么Elasticsearch? (来自百度百科)
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。

Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。