二分查找被定义为在排序数组中使用的一种搜索算法,它通过重复将搜索间隔分成两半来实现。二分查找的思想是利用数组被排序的信息,将时间复杂度降低到O(log N)。
在数据结构中应用二分查找的条件
- 数据结构必须排序。
- 访问数据结构的任何元素都需要恒定的时间。
二分查找算法
在该算法中,
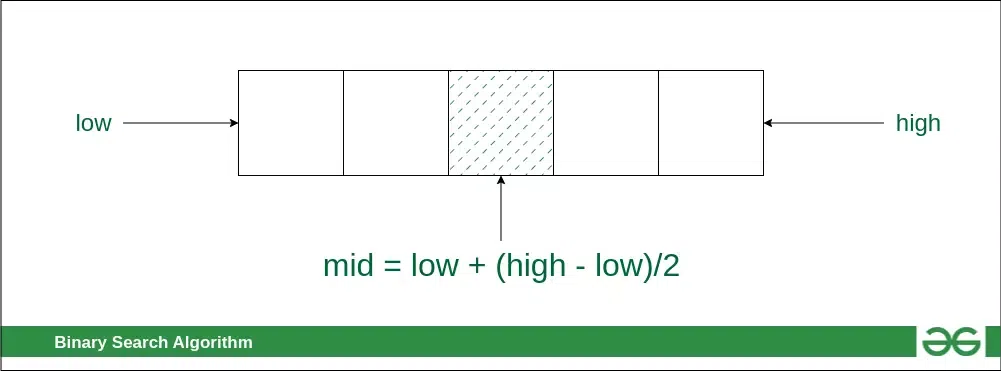
- 通过查找中间索引“mid”将搜索空间分成两半。
- 将搜索空间的中间元素与键进行比较。
- 如果在中间元素处找到键,则终止该过程。
- 如果在中间的元素处没有找到键,请选择将哪一半用作下一个搜索空间。
-
- 如果关键字小于中间的元素,则左侧用于下一次搜索。
-
- 如果关键字大于中间的元素,则右侧用于下一次搜索。
- 这个过程一直持续到找到关键字或耗尽总搜索空间。
二分查找是如何工作的?
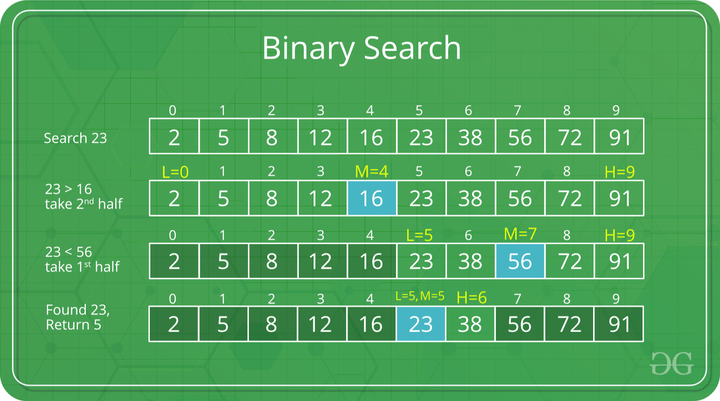
考虑一个数组arr[] = {2,5,8,12,16,23,38,56,72,91},目标= 23。
第一步:计算mid并将mid元素与目标key进行比较。如果键小于mid元素,则向左移动,如果键大于mid元素,则向右移动搜索空间。
-
key(23)大于当前的中间元素(16)。搜索空间向右移动。
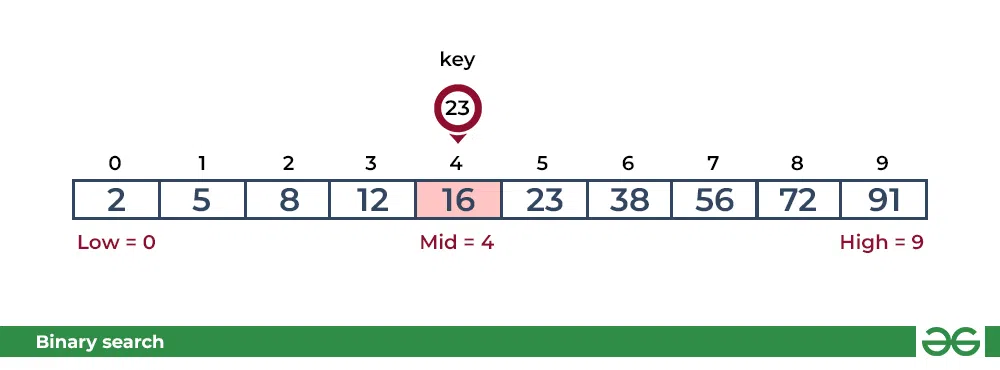
-
key小于当前的中位56。搜索空间向左移动。
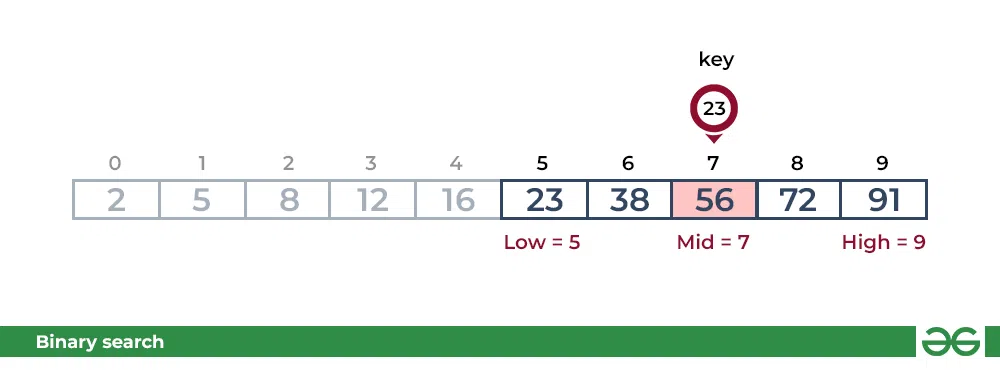
第二步:如果键与mid元素的值匹配,则找到该元素并停止搜索。
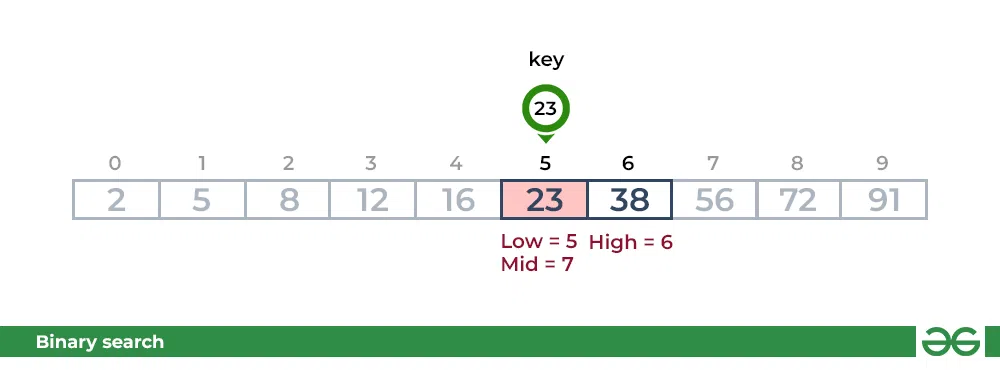
如何实现二分查找?
二进制搜索算法可以通过以下两种方式实现
- 迭代二分查找算法
- 递归二分搜索算法
下面给出的是这些方法的伪代码。
1.迭代二分查找算法:
在这里,我们使用一个while循环来继续比较键并将搜索空间分成两半的过程。
迭代二分查找python实现:
# It returns location of x in given array arr
def binarySearch(arr, l, r, x):
while l <= r:
mid = l + (r - l) // 2
# Check if x is present at mid
if arr[mid] == x:
return mid
# If x is greater, ignore left half
elif arr[mid] < x:
l = mid + 1
# If x is smaller, ignore right half
else:
r = mid - 1
# If we reach here, then the element
# was not present
return -1
# Driver Code
if __name__ == '__main__':
arr = [2, 3, 4, 10, 40]
x = 10
# Function call
result = binarySearch(arr, 0, len(arr)-1, x)
if result != -1:
print("Element is present at index", result)
else:
print("Element is not present in array")
输出:
Element is present at index 3
时间复杂度:O(log N)
空间复杂度:O(1)
2.递归二分查找算法:
创建一个递归函数,并将搜索空间的中点与键进行比较。并根据结果返回找到键的索引或调用下一个搜索空间的递归函数。
递归二分查找python实现:
# Returns index of x in arr if present, else -1
def binarySearch(arr, l, r, x):
# Check base case
if r >= l:
mid = l + (r - l) // 2
# If element is present at the middle itself
if arr[mid] == x:
return mid
# If element is smaller than mid, then it
# can only be present in left subarray
elif arr[mid] > x:
return binarySearch(arr, l, mid-1, x)
# Else the element can only be present
# in right subarray
else:
return binarySearch(arr, mid + 1, r, x)
# Element is not present in the array
else:
return -1
# Driver Code
if __name__ == '__main__':
arr = [2, 3, 4, 10, 40]
x = 10
# Function call
result = binarySearch(arr, 0, len(arr)-1, x)
if result != -1:
print("Element is present at index", result)
else:
print("Element is not present in array")
输出:
Element is present at index 3
二分查找的复杂度分析
时间复杂度:
最佳情况:O(1)
平均情况:O(log N)
最坏情况:O(log N)
空间复杂度:O(1),如果考虑递归调用栈,那么空间复杂度为O(logN)。
二分查找的优点
- 二分查找比线性搜索更快,特别是对于大型数组。
- 比具有类似时间复杂度的其他搜索算法(例如插值搜索或指数搜索)更有效。
- 二分查找非常适合搜索存储在外部存储器中的大型数据集,例如硬盘驱动器或云中。
二分查找的缺点
- 数组应该排序。
- 二分查找要求被搜索的数据结构存储在连续的存储器位置中。
- 二分查找要求数组的元素是可比较的,这意味着它们必须能够被排序。
二分查找的应用
- 二分查找可以用作机器学习中使用的更复杂算法的构建块,例如用于训练神经网络或找到模型的最佳超参数的算法。
- 它可以用于计算机图形学中的搜索,例如光线跟踪或纹理映射算法。
- 它可以用来搜索数据库。