前言:kafka 诞生于需要处理大数据量的背景下,在当前的开发中,数据量的量级也是不断的提高,所以就非常有必要去研究一下kafka 的模型了;
kafka 的官网先放一下:
1 英文官网;
2 中文网站;
1 kafka 简单介绍:
Kafka 是一个高吞吐量和低延迟分布式的消息队列系统,由 Apache 软件基金会开发并开源。它最初由 LinkedIn 公司开发,交由Apache 软件基金会开源。Kafka 采用了分布式的架构,消息数据被分散存储在多个节点上,可以支持数千台服务器同时工作。同时 Kafka 提供了多种在集群环境下保证数据一致性和可用性的机制。
它给出的特定就是高吞吐量和低延迟分布式,至于为什么能做到这些,下面进行一步步的探究;
2 kafka 主要组件:
kafka 既然作为一款主流的生产者消费者模型,我们要使用它之前,也是先要去部署一下kafka的服务的,部署出来的kafka 服务端就可以被各个客户端进行连接,然后完成消息的发送和接收;
kafka 阿里云docker 安装可以参考:阿里云轻量服务器–Docker–Zookeeper&Kafka安装
2.1 kafka 模型流程图:
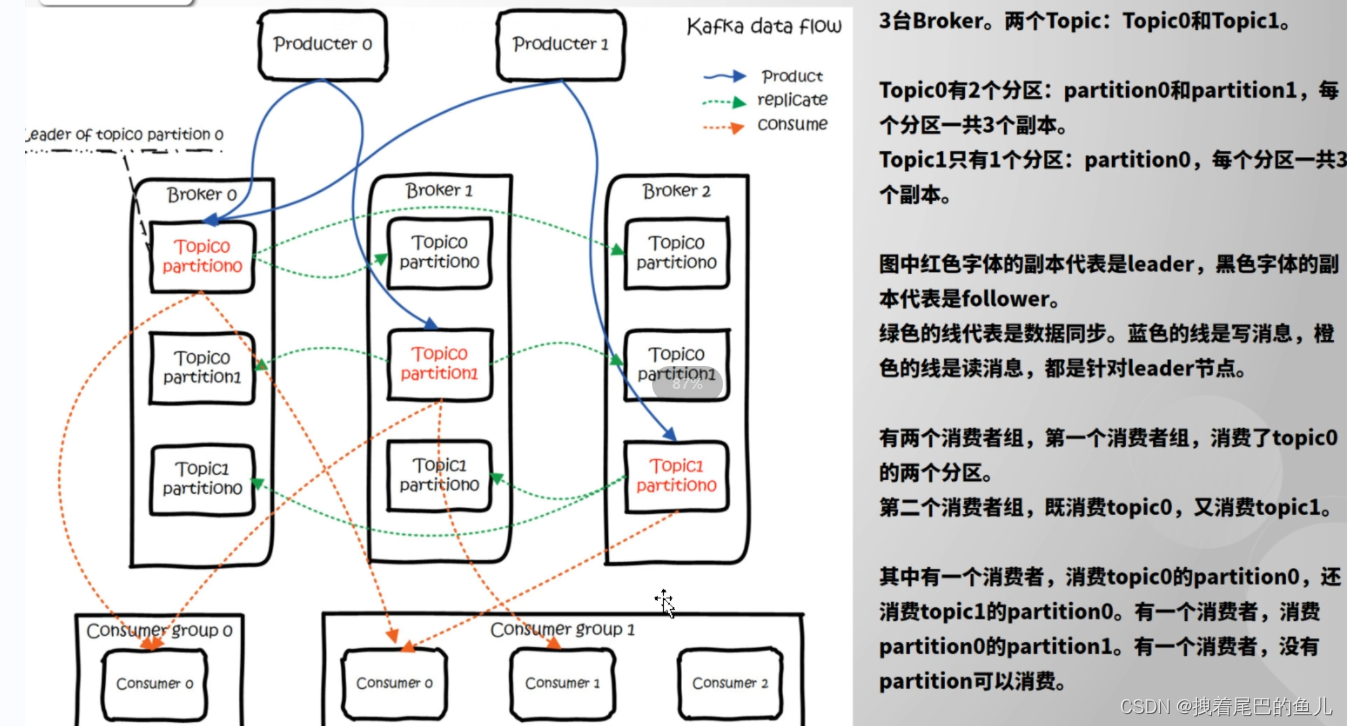
途中包含了必要的一些组件如 生产者,消费者,以及消息存储的topic 和partiton ;
2.2 Kafka 中主要有以下几个组件:
- Producer:消息生产者,用于向 Kafka 集群中的 Topic 发送消息。
- Consumer:消息消费者,从 Topic 订阅消息并进行处理。
- Broker:Kafka 集群中的消息服务器,用于存储和分发消息。
- Topic:消息主题,一个逻辑概念,类似于一个消息队列。
- Partition:一个 Topic 可以被分成多个 Partition,每个 Partition 存储一部分消息,Partition 中的消息是有序的。
- Offset:消息在 Partition 中的编号,由 Consumer 维护。
- Consumer Group:一个 Consumer Group 包含多个 Consumer,共同消费同一个 Topic,每个消息只会被 Consumer Group 中的一个 Consumer 消费,即负载均衡的实现。
其中Producer和Consumer 作为客户端连接到kafka 服务端,Broker,Topic,Partition,Offset 都是交由服务端进行维护。 下面分步对每个组件进行探究;
2.2.1 生产者:
生产者主要作为消息的发起者,产生消息,并将消息通过kafka 提供的api 方法,将消息发送到连接kafka broker 服务上,下面按照消息的场景进行分别介绍,以springboot 中kafka 提供的KafkaTemplate 模版进行消息的发送:
为了更贴近与实际应用,这里定义一个实体来对消息进行封装:
MessageDto.java
import lombok.AllArgsConstructor;
import lombok.Data;
import java.io.Serializable;
@Data
@AllArgsConstructor
public class MessageDto implements Serializable {
/**
* 消息业务类型
*/
private String type;
/**
* 消息体
*/
private Object body;
}
1) 普通消息发送:
KafkaTemplate 发送消息走的都是异步线程,当然我们也可以同步获取消息发送的结果:
消息同步发送demo:通过发送返回的ListenableFuture 直接调用get() 方法实现
/**
* 同步发送消息
*
* @param topic 主题
* @param message 消息
*/
public boolean sendSyncMsg(String topic, MessageDto message) {
// 通过阿里的格式化转换工具 将message 对象转为json 字符串
ListenableFuture<SendResult> data = kafkaTemplate.send(topic,JSONObject.toJSONString(message));
try {
Object obj = data.get();
} catch (Exception ex) {
ex.getMessage();
return false;
}
return true;
}
消息异步发送demo:通过增加监听器实现
/**
* 异步发送消息
*
* @param topic 主题
* @param message 消息
*/
public void sendAsyncMsg(String topic, MessageDto message) {
ListenableFuture<SendResult<String, String>> future =
kafkaTemplate.send(topic, JSONObject.toJSONString(message));
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
log.debug("Message sent successfully:{}", result.getRecordMetadata().toString());
}
@Override
public void onFailure(Throwable ex) {
log.error("Failed to send message:{}", ex.getMessage());
}
});
}
2) 事务消息发送:针对该批次消息要么全都成功,要么全都失败
2.1)首先KafkaTemplate 它默认没有开启事务的支持,所以需要先开启事务(事务开启的方式可能跟kafka客户端的版本有关,此处不在进行列举 本篇的demo 通过配置transactional.id 参数开启事务消息),需要注意的是当一个 KafkaTemplate 对象开启了事务之后,仅可以发送事务消息,而不能发送非事务消息,所以需要在项目中定义两个KafkaTemplate ,一个用来发送普通消息,一个用来发送事务消息;
2.2) 开启式事务定义kafka 的事务管理器:
@Bean
public KafkaTransactionManager kafkaTransactionManager(ProducerFactory<?, ?> producerFactory) {
KafkaTransactionManager transactionManager = new KafkaTransactionManager(producerFactory);
return transactionManager;
}
2.3)发送消息:借由KafkaTemplate的executeInTransaction 方法实现:
/**
* 发送事务消息
*
* @param topic 主题
* @param messages 消息
*/
@Transactional(rollbackFor = Exception.class)
public void sendTransactionalMessage(String topic, List<MessageDto> messages) {
kafkaTemplate.executeInTransaction(operations -> {
messages.stream().forEach(message->{
operations.send(topic, JSONObject.toJSONString(message));
// 其它业务处理 如对mysql 进行操作 如果topic 或则mysql 操作失败,会进行事务回滚
});
return true;
});
}
以上消息发送方式对于业务端应该基本满足了,需要注意的是不同的客户端在开启事务时,需要设置不同的transactional.id;对于transactional.id 官文给出的解释很少,只是告诉设置transactional.id 以开启事务,并且多个客户端使用相同的transactional.id 将导致两个生产者互相干扰,导致意想不到的结果(如多个相同transactional.id 客户端,最终只能有一个发送事务消息),这个参数博主也没有搞的很明白,欢迎大家讨论,在此不在过多阐述以免误导他人 ;
2.4) 发送消息ack 确认:
Kafka 生产者在发送消息后,会收到一个来自 Kafka 服务端的确认消息,该消息被称为“ACK”,即表示消息已经被成功发送到 Kafka 服务端。Kafka 的生产者有三种类型的 ACK,根据业务进行选择:
-
acks=0:不进行任何确认的消息发送模式,为最低的发送延迟方式。生产者在将消息发送到网络缓存后便认为发送完成,并不等待任何确认消息。这种模式下,最好能够使用高可靠性的网络连接,例如 TCP。 -
acks=1:启用 Leader Broker 的 ACK 确认消息。Leader 在将消息写入其本地日志后,会发送一条确认消息。如果 Leader Broker 挂掉,但是 Replicas Broker 还能正常工作,那么该消息也不会丢失。这是默认的 ACK 配置。 -
acks=all:启用 ISR (in-sync replicas) 的 ACK 确认消息。Leader 发送消息后,必须等待所有 In-Sync Replicas Broker 都已经成功复制该消息到其本地副本,并在日志中写入了一条确认消息后,才认为该消息的发送完成。ISR 是高可用性的副本集,它包括了所有和 Leader Broker 同步的 Replicas Broker。
2.5) 批量发送消息:kafka 默认就是批量进行消息 的发送,不过可以通过参数进行调整:
- batch.size 该参数控制 KafkaProducer 的缓冲区大小,即 KafkaProducerBatch 的最大记录数。一旦缓冲区达到指定大小,KafkaProducer 就会将缓冲区中的所有记录一起发送到 Kafka 集群,默认值16384;
- buffer.memory 用于控制 Producer 的发送缓冲区大小。Kafka Producer 将记录保存在缓冲区中,然后批量发送到 Kafka Broker,以提高数据传输效率。该参数表示 Producer 缓存区的总大小,单位是字节,默认值为 32MB,建议将缓冲区的大小设置为可用内存的 25% - 50%;
- linger.ms : Kafka Producer 的一个配置参数, producer 会将两个请求发送时间间隔内到达的记录合并到一个单独的批处理请求中;默认值为 0;
不过这些参数的效果是叠加的,linger.ms 因为会将设置时间段内的消息进行合并,所以会延迟发送消息,不过如果此时消息的数量已经达到了batch.size 则会直接发送改批次请求,而忽略这个参数; buffer.memory 用来缓冲等待被发送到服务器的记录的总字节数,改值越大意味着缓存的消息也就越多,不过当消息的条数达到了batch.size 也会直接发送改批次请求;
2.6) 消费发送失败的重试:
retries :若设置大于0的值,则客户端会将发送失败的记录重新发送;
这些参数的解释都可以在 :https://kafka.apachecn.org/documentation.html 看到;
就是由于kafka 的客户端可以批量并且异步的发送数据,所以效率提高的很多,这也是它吞吐量高一个重要原因;
2.7) 消费发送前拦截器,可以对消息进行加工编码等:
2.7.1) 定义生产者消费拦截器:
package com.example.springkafka.interceptor;
import com.alibaba.fastjson2.JSONObject;
import com.example.springkafka.util.DateUtil;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
public class ProducerClientInterceptor implements ProducerInterceptor<String, String> {
private static ThreadLocal<SimpleDateFormat> local = new ThreadLocal<SimpleDateFormat>();
private int errorCounter = 0;
private int successCounter = 0;
/**
* 该方法会在消息被序列化和分区之前被调用。开发者可以在该方法中修改消息的内容或者添加元数据。
* 该方法需要返回一个新的 ProducerRecord,如果无需修改消息内容,直接返回原始 ProducerRecord 即可。
*
* @param record
* @return
*/
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
Map<String, Object> mapData = JSONObject.parseObject(record.value(), Map.class);
mapData.put("sendTime", getDateFormat().format(new Date()));
return new ProducerRecord(record.topic(), record.partition(), record.timestamp(), record.key(),
JSONObject.toJSONString(mapData));
}
/**
* 该方法会在 Producer 发送消息到 Kafka Broker 后,如果有相应的 ack 则会被调用。在该方法中,开发者可以将成功发送到 Kafka Brokers
* 或者失败的消息记录到日志中,或者执行其他的操作。如果消息发送成功,参数 exception 为 null,否则为包含异常信息的对象。
*
* @param recordMetadata
* @param exception
*/
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception exception) {
if (exception == null) {
successCounter++;
} else {
errorCounter++;
}
}
/**
* 该方法会在 Kafka Producer 被关闭之前调用,开发者可以在该方法中进行一些清理工作。
*/
@Override
public void close() {
}
/**
* 该方法会在 Kafka Producer 启动时被调用,并传入一些配置信息。开发者可以在该方法中获取和存储一些相关的变量。
*
* @param map
*/
@Override
public void configure(Map<String, ?> map) {
}
public static SimpleDateFormat getDateFormat() {
SimpleDateFormat dateFormat = local.get();
if (dateFormat == null) {
dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
local.set(dateFormat);
}
return dateFormat;
}
public static String format(Date date) {
return getDateFormat().format(date);
}
public static Date parse(String dateStr) throws ParseException {
return getDateFormat().parse(dateStr);
}
}
2.7.2) 在kafka 配置属性增加拦截器:
// 加入拦截器
List<Object> interceptors = new ArrayList<>();
interceptors.add(ConsumerClientInterceptor.class);
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
3) 一些原理介绍:
3.1) 消息的事务提交: kafka 的事务提交使用的是2阶段提交;
事务提交的流程如下:
-
开启事务:在生产者客户端中,开启一个事务,这个事务会在多个 Kafka 发送请求之间连续传递,并且直到该事务被提交才算完成。
-
创建、发送事务消息:在事务内,使用 Kafka 生产者 API 发送多个消息。这些消息在发送时不会被立即提交,而会暂时存储在事务缓冲区中。
-
预提交事务:在事务内,使用 Kafka 生产者 API 执行预提交操作。一旦调用了此操作,事务内的消息将不能再次修改或回滚,只能提交或终止事务。
-
提交事务:使用 Kafka 生产者 API 执行事务提交操作。此时,所有在事务内已经发送并预提交的消息将被标记为已提交,并释放事务缓冲区,这些已提交的消息将会发送到 Kafka Server。
-
如果提交事务操作失败,会抛出 ProducerFencedException 异常。在这种情况下,客户端可以选择重试事务或者终止事务。
-
结束事务:一旦事务提交成功,执行事务结束操作。这个操作会清空事务缓冲区并释放相应的资源。
3.2) kafka 的 KafkaTransactionManager 为什么能够管理到mysql 中的事务?
-
KafkaTransactionManager 本身并不会管理到 MySQL 中的事务。实际上,KafkaTransactionManager 能够提供分布式事务管理功能,主要依赖于 Spring 的事务管理机制和 KafkaProducer 的事务性发送机制。
-
KafkaProducer 的事务性发送机制采用了 Kafka 新引入的事务 API,利用事务 ID 和分布式锁机制,确保 Kafka 生产者发送的消息具有事务性。KafkaTransactionManager 利用这一约束,将 Kafka 生产者的事务性发送形成的生产者端事务和 Spring 管理的本地事务绑定起来,实现分布式事务管理的完整性和一致性。同时,KafkaTransactionManager 还重写了 Spring 的事务管理接口,支持 Kafka 生产者端事务和本地事务的协同传播和控制。
-
KafkaTransactionManager 的主要作用是将 Kafka 生产者端事务与本地事务绑定起来,并确保事务性发送在分布式环境中的原子性和可靠性。对于多数据源事务管理场景,需要使用其他的分布式事务管理工具,例如:Atomikos、Bitronix、Narayana 等,通过对多个数据源的事务进行协调,支持 ACID 特性的分布式事务管理。
-
综上所述,KafkaTransactionManager 并不能直接管理到 MySQL 中的事务,而是通过协同 KafkaProducer 的事务性发送机制和 Spring 的事务管理机制,实现对 Kafka 生产者的事务性发送和本地事务进行统一管理和控制。
2.2 消息的存储:
kafka 是一个基于发布-订阅topic(主题)模式的分布式消息系统,消息的存储也是基于topic 展开;为了更好的管理消息,每个topic 会有若干个分区,每个分区存储的消息都是不同的,为了消息的可靠性,还需要对每个分区进行备份(新创建 Topic 默认只有 1 个 Partition 和 1 个副本),需要注意的是:分区副本的数量要小于等于broker 节点的数量;并且只有主分区可以对客户端提供读写服务,分区副本只是作为数据备份使用;
2.2.1 消息体的结构:
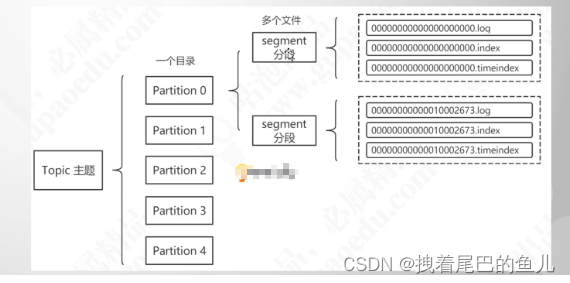
消息会议topic 分区数量创建对应的目录,假如 我们创建2个分区1个副本的topic 名称为topic2part1rep,那么在kafka log 目录下就会生成两个分区的目录分别为topic2part1rep-0,topic2part1rep-1,如下图:

进入topic2part1rep-0 可以看到消息真实情况:
 - index结尾的为 消息的索引
- index结尾的为 消息的索引
- timeindex为 发送消息的时间索引
- log 结尾的为消息存储的地方
上面的几个目录实际上是一个分期下的一段消息存储结果,随着消息的累加kafka 会按照log大小分为好几个段进行存储,每个段中都有上面4个文件,且每个段中存储的消息也是不相同的;为了便于消息的检索,为其创建了消息索引,消息的存储可以参考下图。
2.2.2 消息的清除:
kakfa topic 中的没有消费过的消息默认是不会进行清理的,对于消息的保存时效性,可以通过参数控制消息的保留策略:
- log.cleaner.enable 参数是 Kafka 中用来指定是否启用日志清理(log cleaning)功能,默认为true;
- log.cleanup.policy 超出保留窗口期的日志段的默认清理策略。用逗号隔开有效策略列表。有效策略:“delete”和“compact”,默认为delete;
- log.retention.check.interval.ms eck.interval.ms 日志清理器检查是否有日志符合删除的频率(以毫秒为单位)默认值 300000,定时器每隔5分钟,执行一次,按照设置的策略对消息进行删除或压缩;
- log.retention.hours ;log.retention.minutes; log.retention.ms 时间过期策略hours 为小时(默认值158),minutes为分钟(默认值null),ms 为毫秒(默认值null);
-消息文件大小过期策略 log.retention.bytes 分区的占用空间的最大值(默认值 -1 不限制);log.segment.bytes 单个日志段文件最大大小(默认值1073741824字节 即 1GB);
同时启用了基于事件和基于文件大小的保留策略,两个策略的限制条件相互独立,Kafka 会同时考虑这两个策略,并且以先达到限制条件的策略为准进行删除消息;
注意:
Kafka 中默认启用日志清理功能,并且保留策略默认是 delete,log.retention.hours 默认值是 168(即 7 天)。这意味着未被消费并且已经超过 7 天的消息会被删除。
2.2.3 kafka broker 宕机,主/分区的选举:
- 主分区的选举:
第一个主节点随机在多个broker 中选取一个,作为改topic 的第一个主分区 partition0,然后改topic 下其它的主分区选举从当前broker,依次向后+1 partition1 , partition2 ,,,;
2)副本存储位置:
副本存储位置是kafka自动选择副本在集群中的位置,然后将它们分配给相应的 Broker;
3)当主分区所在的broker 挂掉后,副本分区的选举,kafka 内部自己进行选举:
- 选举出一个领导者,broker通过zk 注册临时节点,谁注册完成谁就成为领导者,后续由领导者指挥完成选举;
- 选举的候选人时从isr ,即和之前leader 保持数据同步的节点;
- 选举的策略为leade副本编号最小的成为新的leader 节点;
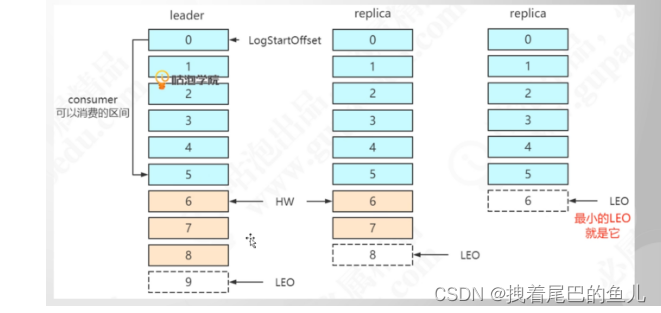
在原有leader 挂掉后,中间的副本分区因为分区编号最小成为新的leader 节点;然后其它的副本分区以新的leader 为标准进行数据同步;所以可以看到kafka 这样处理 只保证了 各个分区数据的一致性,并没有对消息的可靠性,也即选举有可能造成数据丢失;
2.3 消费者:
消费者组中的消费者通过订阅感兴趣的topic ,从而获取消息进行消费;kafka客户端只支持poll 拉取消息模式,在消费端一般在消费完消息后手动提交ack;
2.3.1 客户端消费消息:
在springboot 中我们可以通过kafka 提供的@KafkaListener 注解进行消费;下面是一个demo:
1) 定义一个消费者的工厂:
/**
* 消费者批量工程
*/
@Bean
public KafkaListenerContainerFactory<?> batchFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(batchConsumerConfigs()));
//设置为批量消费,每个批次数量在Kafka配置参数中设置ConsumerConfig.MAX_POLL_RECORDS_CONFIG
factory.setBatchListener(true);
factory.setConcurrency(1);
//设置提交偏移量的方式为手动
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
2)消费消息:
@KafkaListener(topics = "test1",containerFactory = "batchFactory")
public void articleConsumerWx(List<ConsumerRecord<?,?>> records, Consumer consumer){
Long time1 = System.currentTimeMillis();
records.stream().forEach(e->{
System.out.println("e.value() = " + e.value());
});
// 异步提交偏移量
consumer.commitAsync();
// 同步提交偏移量
// consumer.commitSync();
Long time2 = System.currentTimeMillis();
log.debug("消费{}条数据,耗时:{}",records.size(),(time2-time1)/1000);
}
3)消费ack 的策略选择:
- 手动提交:消费者可以通过手动调用 commitSync() 或 commitAsync() 方法将消费的消息提交到 Broker。手动提交的优点是可以更细粒度地控制 ack 的粒度,从而保证消费者在处理消息时不会出现重复或缺失的情况。但手动提交需要消费者自己管理 ack 的状态和提交时间,因此相对来说比较繁琐;
- 自动提交:消费者也可以选择打开自动提交功能(enable.auto.commit=true),这样就可以让 Kafka 自动管理 ack 的状态和提交时间。自动提交的优点是操作简单,无需关心 ack 的状态和细节,但可能出现消息重复消费或消息丢失的情况。因此,建议在一些重要的应用场景中使用手动提交机制;
4) 消费失败的重试策略:
默认情况下,Kafka 消费端收到消息后,如果处理失败,是不会自动重试的。如果需要自动重试,需要在代码中进行相应的处理;
5)消费者拦截器:消费者消费消息之前对消息进行操作:
5.1) 定义拦截器:
package com.example.springkafka.interceptor;
import org.apache.kafka.clients.consumer.ConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.util.Map;
public class ConsumerClientInterceptor implements ConsumerInterceptor<String, String> {
/**
* 该方法会在消息被消费之前被调用,开发者可以在该方法中修改消息的内容或者添加元数据。
* 该方法需要返回一个新的 ConsumerRecords,如果无需修改消息内容,直接返回原始 ConsumerRecords 即可。
*
* @param consumerRecords
* @return
*/
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> consumerRecords) {
for (ConsumerRecord<String, String> record : consumerRecords) {
String modifiedValue = record.value();
// 对value 操作
}
// 构造修改后的 ConsumerRecords 返回
return consumerRecords;
}
/**
* 该方法会在消息被提交之前被调用。在该方法中,开发者可以将成功提交的消费偏移量记录到日志中,或者执行其他的操作。
*
* @param map
*/
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> map) {
}
/**
* 该方法会在 Kafka Consumer 被关闭之前调用,开发者可以在该方法中进行一些清理工作。
*/
@Override
public void close() {
}
/**
* 该方法会在 Kafka Consumer 启动时被调用,并传入一些配置信息。开发者可以在该方法中获取和存储一些相关的变量。
*
* @param map
*/
@Override
public void configure(Map<String, ?> map) {
}
}
5.2) 配置中增加拦截器:
// 加入拦截器
List<Object> interceptors = new ArrayList<>();
interceptors.add(ConsumerClientInterceptor.class);
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
2.3.2 客户端消费者消费消息的偏移量保存:
消费者偏移量的存储:消费者和偏移量的topic 共有50 个分区来存储每个消费与分区 消费的偏移量,通过消费者hash 后% 50 的数字决定改消费者的偏移量存储在哪个分区中:

3 总结:
上面的介绍基本涵盖了kafka 各个组件的使用以及特性,现在对kakfa 特性进行一下总结;
- kafka 默认批量发送,并且还可以开启消息的压缩,消费者也可以批量消费消息,并且这是其高吞吐量低延迟的原因之一;
- kafka 的消息虽然都存在与磁盘上 ,但是 进行顺序读写;从磁盘中的扇区完成读写,数据在磁盘集中存储;而不是随机存储,并且消息都进行了索引的存储,对于消息的检索速度也是非常快的;
- kafka 在读取消息的时候使用零拷贝 技术,这些也是其高吞吐量低延迟原因;
- kafka 的消息内部进行分区分段存储,并且每个分区的数据都有备份,在主分区挂掉后可以通过选举进行顶替,这是其高可用的重要条件;
4 参考:
4.1 kafka 的介绍和使用;
4.2 kafka 生产者api、消费者api;