脑图链接
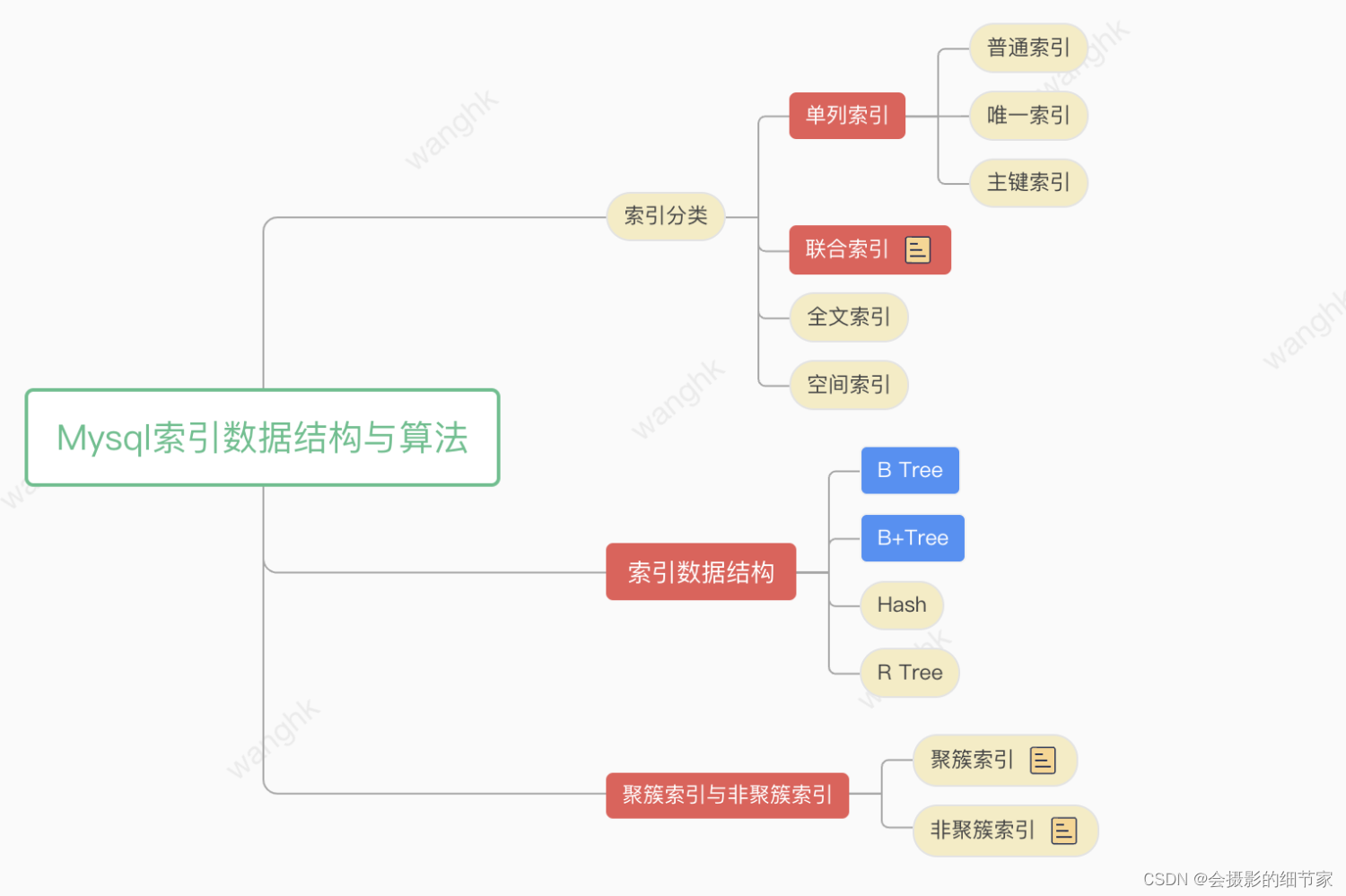
一、索引
什么是索引
索引指的是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中的数据。类似于书籍的目录,用于快速定位到所需内容、数据的页码位置。
优点:提高数据检索的效率,降低数据库的IO成本
缺点:维护索引要耗费时间和额外的磁盘空间 ,并且随着数据量的增加,所耗费的时间也会增加
索引分类
索引一般可以分为四类
● 单列索引:单列索引指的是只包含一列的索引,又可分为三种:
○ 普通索引:普通索引是最基本的索引类型,没有什么限制,且允许空值和重复值。
○ 唯一索引:唯一索引列中的值必须是唯一的,允许存在一个空值。多个空值仍然会视为重复
○ 主键索引:主键索引是特殊的唯一索引,不允许存在空值。
● 联合索引:组合索引也就是多列索引,由多列组合创建的索引,使用的时候遵循最左前缀原则。
● 全文索引:全文索引只有MyISAM引擎支持,且只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引,主要用于做文章的关键字搜索的
● 空间索引:空间索引是对空间数据类型的字段建立的索引
二、索引数据结构
B Tree
特点:
● 叶节点具有相同的深度,叶节点的指针为空
● 所有索引元素不重复
● 节点中的数据索引从左到右递增排列
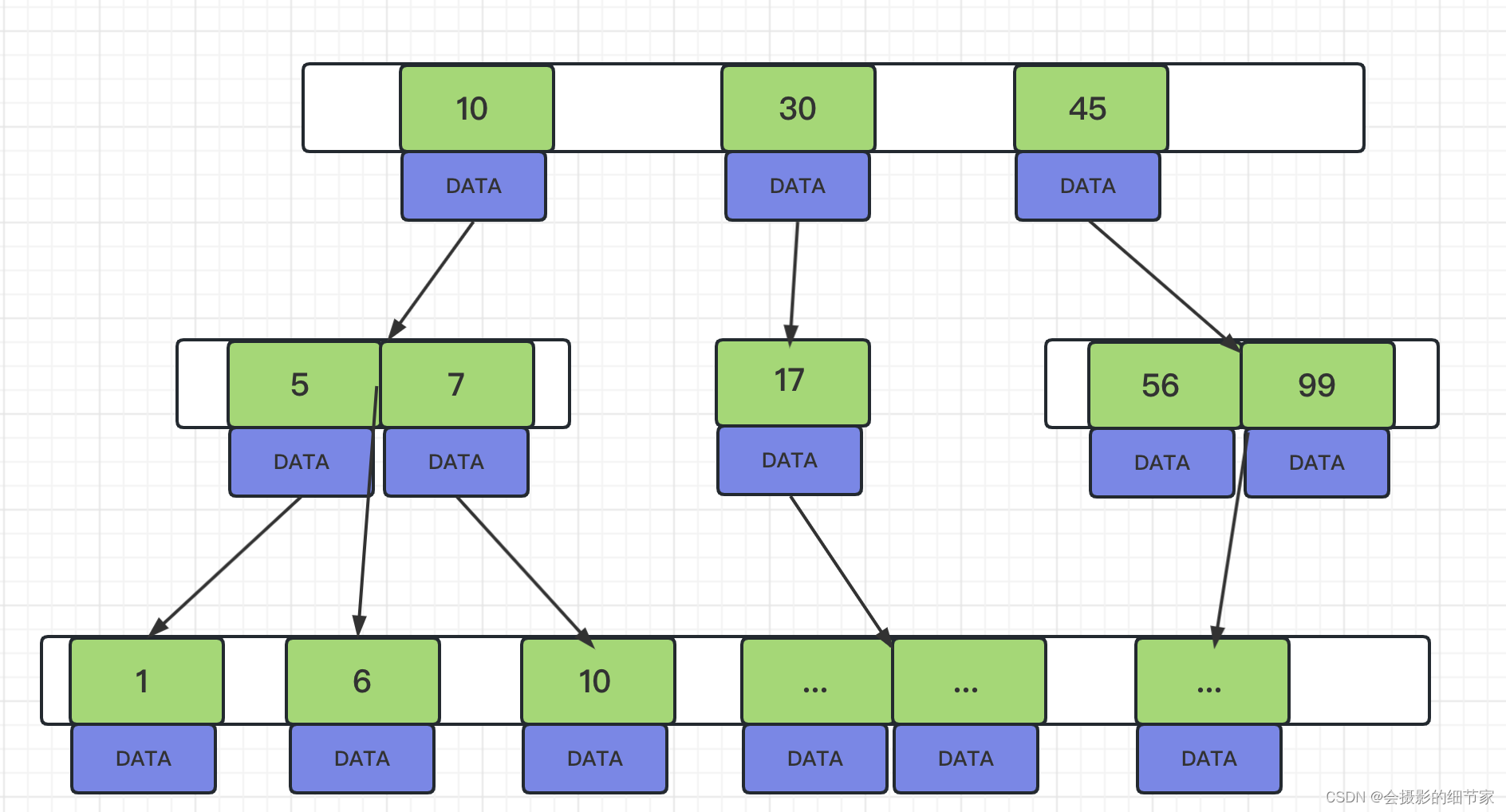
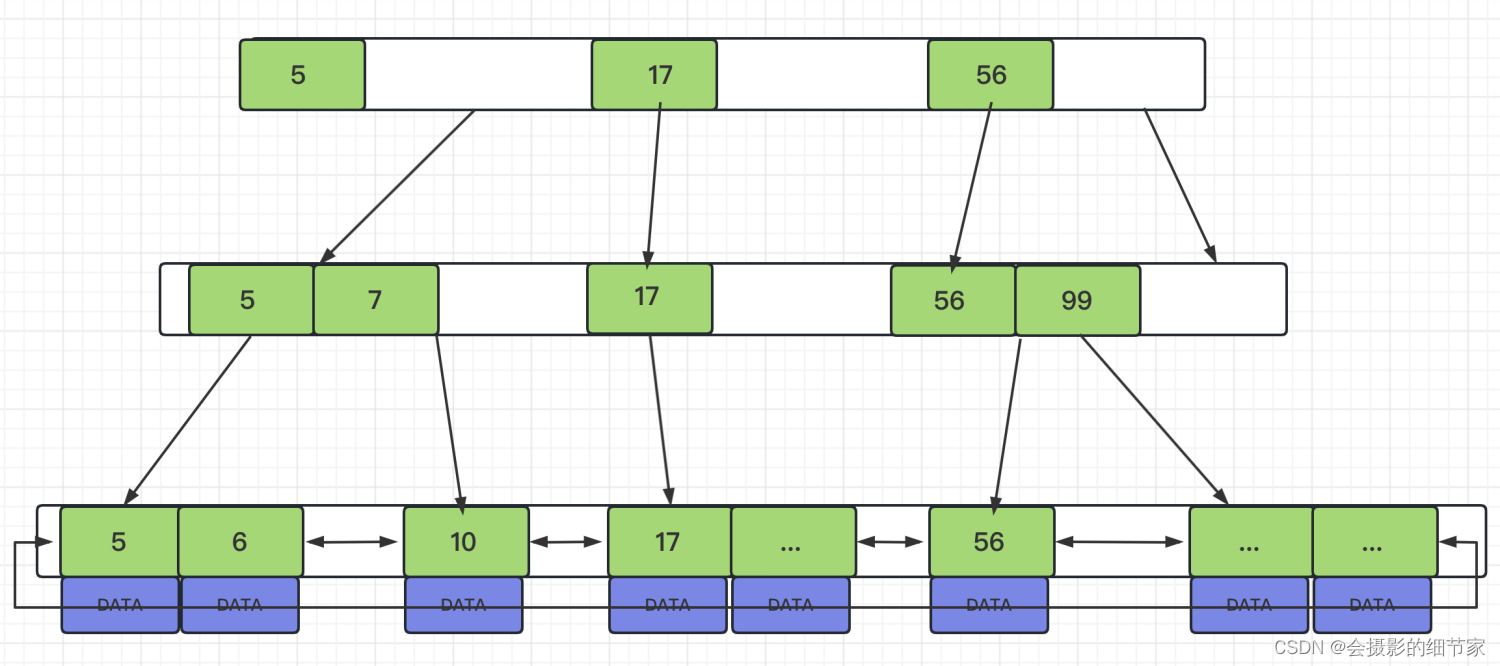
B+Tree
特点:
● 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
● 叶子节点包含所有索引字段
● 叶子节点用指针连接,提高区间访问的性能
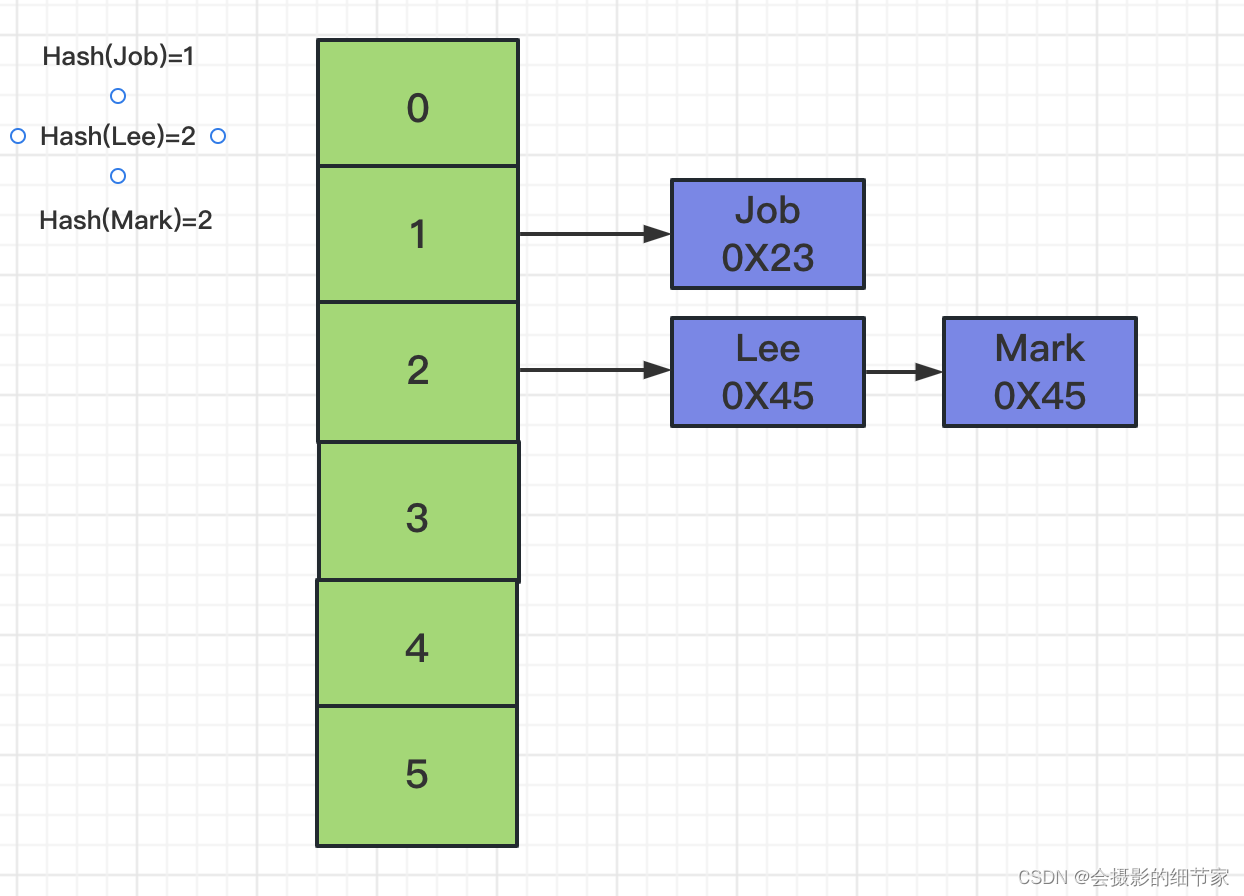
Hash
特点:
● 对索引的key进行一次hash计算就可以定位出数据存储的位置
● 很多时候Hash索引要比B+ 树索引更高效
● 仅能满足 “=”,“IN”,不支持范围查询
● hash冲突问题
R Tree
R-Tree在MySQL很少使用,仅支持 geometry数据类型 ,支持该类型的存储引擎只有myisam、bdb、innodb、ndb、archive几种。
举个R树在现实领域中能够解决的例子:查找20英里以内所有的餐厅。如果没有R树你会怎么解决?一般情况下我们会把餐厅的坐标(x,y)分为两个字段存放在数据库中,一个字段记录经度,另一个字段记录纬度。这样的话我们就需要遍历所有的餐厅获取其位置信息,然后计算是否满足要求。如果一个地区有100家餐厅的话,我们就要进行100次位置计算操作了,如果应用到谷歌、百度地图这种超大数据库中,这种方法便必定不可行了。R树就很好的解决了这种高维空间搜索问题。它把B树的思想很好的扩展到了多维空间,采用了B树分割空间的思想,并在添加、删除操作时采用合并、分解结点的方法,保证树的平衡性。
R树就是一棵用来存储高维数据的平衡树 。相对于B-Tree,R-Tree的优势在于范围查找
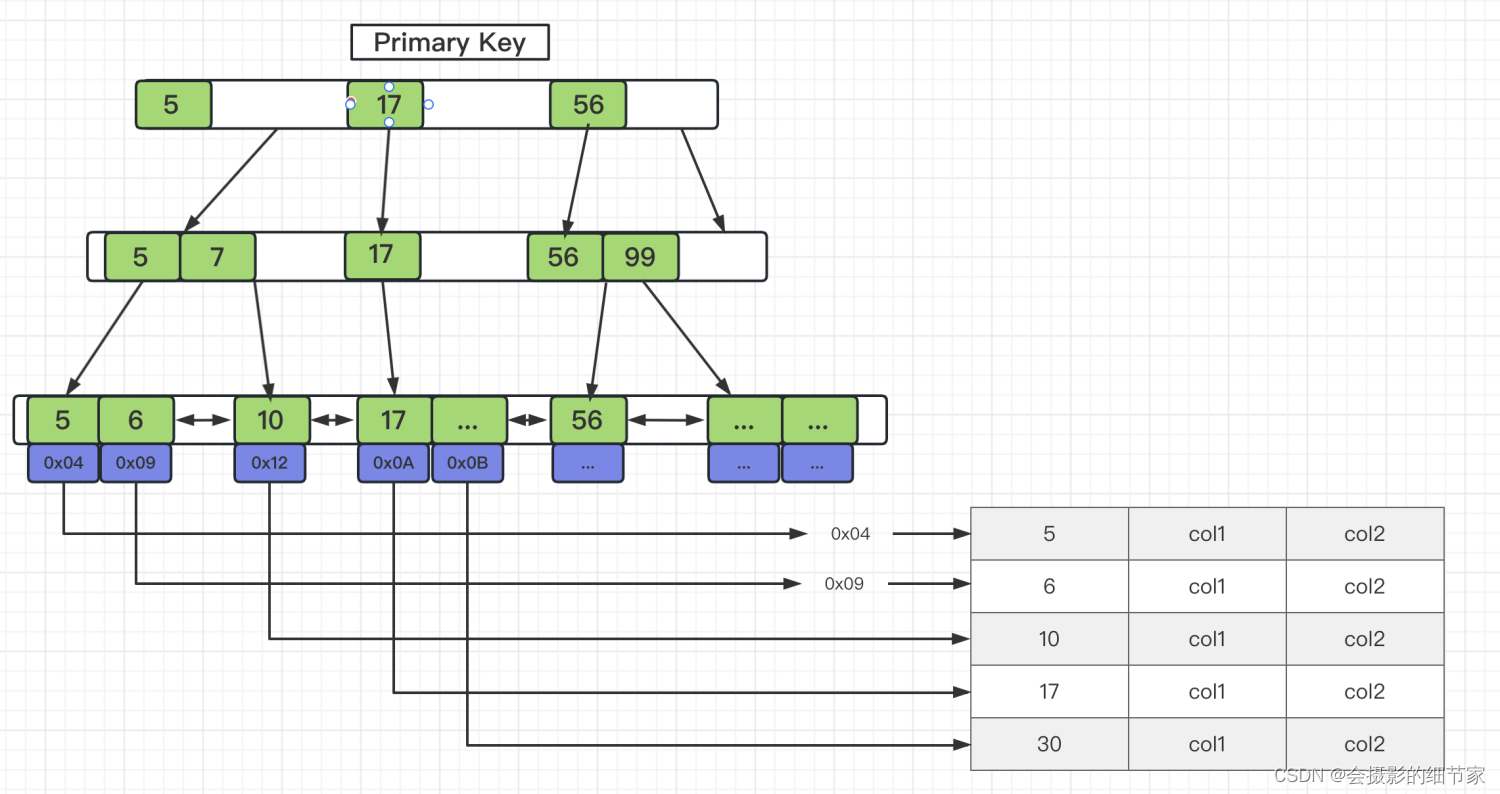
三、聚簇索引与非聚簇索引
聚簇索引
innoDB引擎下主键索引
○ 索引和数据存放在同一个文件中
○ 通过索引树遍历到叶子结点可以查询到完整数据
优点:数据访问更快,索引和数据保存在同一个B+Tree中
缺点:
○ 插入速度严重依赖于插入顺序 ,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键(为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?)
○ 更新主键的代价很高 ,因为将会导致被更新的行移动
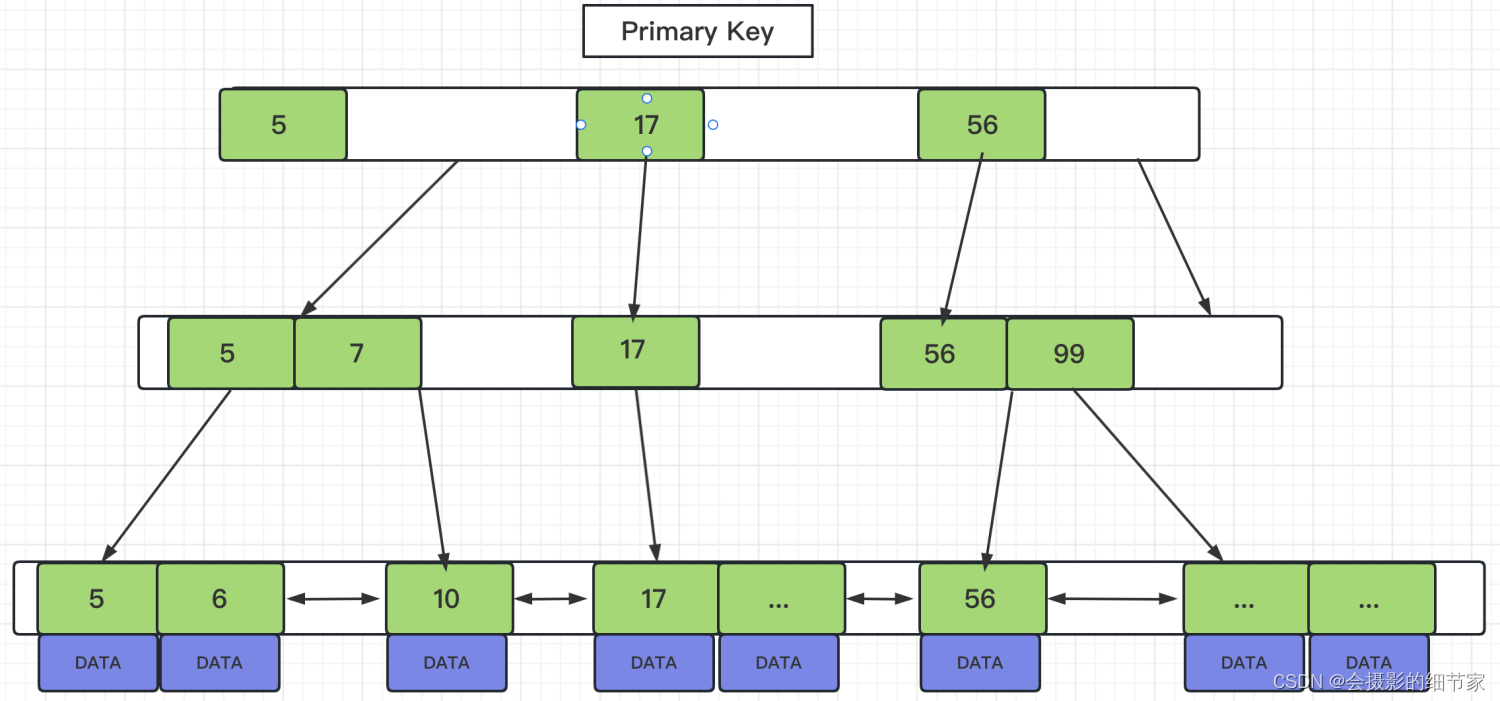
非聚簇索引
索引文件与数据文件分开存储,通过索引树遍历到叶子节点查询到主索引树的索引,通过主索引树索引回表查询到完整数据
优点:索引覆盖的情况下数据访问快
缺点:需要进行回表查询
四、联合索引解析
怎么使用联合索引
在建立索引的时候,尽量在多个单列索引上判断下是否可以使用联合索引。联合索引的使用不仅可以节省空间,还可以更容易的使用到索引覆盖(查询字段被联合索引字段覆盖,查询联合索引树就可以拿到需要数据,不再需要回表查询)。
联合索引数据结构
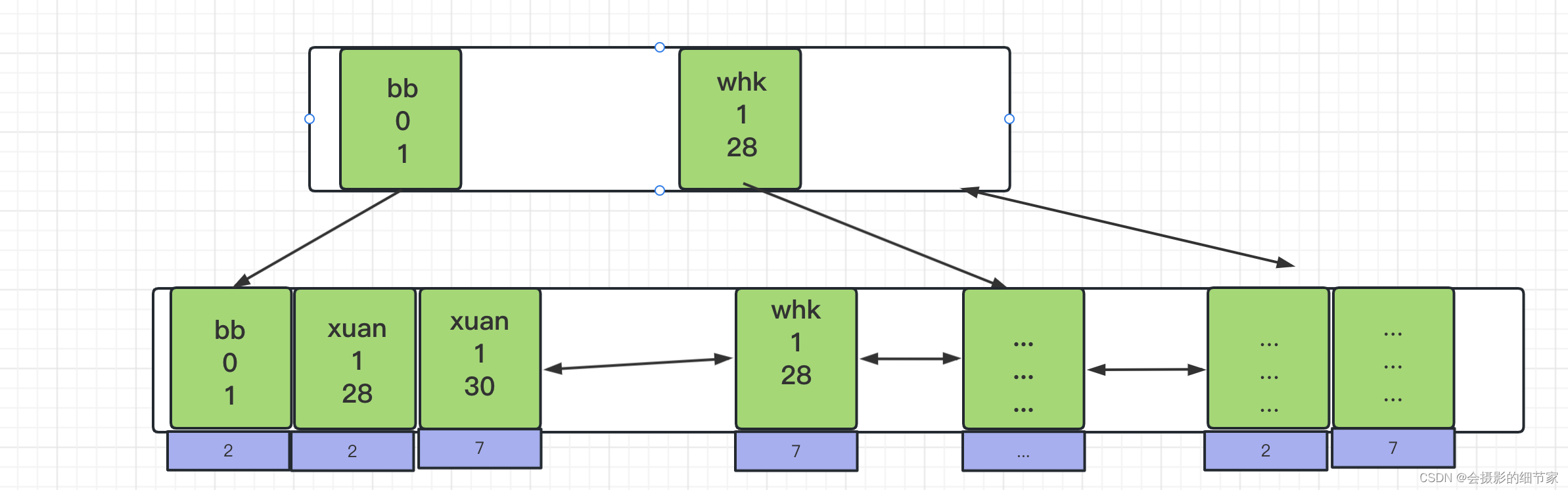
最左前缀匹配原则
最左优先,以最左边的为起点任何 连续 的索引都能匹配上,但遇到范围查询 (>、<、between、like) 就会停止匹配。之所以会有最左前缀匹配原则和联合索引的索引构建方式及存储结构是有关系的,联合索引是使用多列索引的第一列(最左)构建的 B+ Tree
测试建表及数据sql
create table user
(
id int auto_increment
primary key,
age int not null comment '年龄',
name varchar(50) not null comment '姓名',
hobby int comment '爱好',
sex int not null comment '0-未知 1男 2女'
);
create index index_name_sex_age on user (name, sex, age);
INSERT INTO user (id, age, name, sex, hobby) VALUES (1, 18, 'zk', 1, 1);
INSERT INTO user (id, age, name, sex, hobby) VALUES (2, 28, 'xuan', 1, 1);
INSERT INTO user (id, age, name, sex, hobby) VALUES (3, 28, 'whk', 1, 2);
INSERT INTO user (id, age, name, sex, hobby) VALUES (4, 18, '赵美美', 2, 2);
INSERT INTO user (id, age, name, sex, hobby) VALUES (5, 40, '李mm', 0, 1);
INSERT INTO user (id, age, name, sex, hobby) VALUES (6, 1, 'bb', 0, 1);
INSERT INTO user (id, age, name, sex, hobby) VALUES (7, 30, 'xuan', 1, 1);
explain -- 走索引
select * from whk_db.user a where a.name='zk';
explain -- 走索引
select * from whk_db.user a where a.name='zk' and a.sex=1;
explain -- 不走索引,不满足最左前缀
select * from whk_db.user a where a.age=18 ;
explain -- 走索引
select * from whk_db.user a where a.name='zk' and a.sex=1 and a.age<20;
explain -- 走索引
select * from whk_db.user a where a.name='zk' and a.age=18 and a.hobby=1;



![[进阶]网络通信:概述、IP地址、InetAddress](https://img-blog.csdnimg.cn/b16a2a67ac0140b58a55f8319cbd51b9.png)