在神经网络的学习中,权重的初始值特别重要。实际上,设定什么样的权重初始值,经常关系到神经网络的学习能否成功。本节将介绍权重初始值的推荐值,并通过实验确认神经网络的学习是否会快速进行。
可以将权重初始值设为0吗
后面我们会介绍抑制过拟合、提高泛化能力的技巧 —— 权值衰减。
权值衰减就是一种以减小权重参数的值为目的进行学习的方法。
如果想减小权重的值,一开始就将初始值设为较小的值才是正途。实际上在这之前的权重初始值都是像0.01 * np.random.randn(10,100)这样,使用由高斯分布生成的值乘以0.01后得到的值(标准差为0.01的高斯分布)。
如果我们把权重初始值全部设为0以减小权重的值,会怎么样呢? 事实上,将权重初始值设为0的话,将无法正确进行学习。
为什么不能将权重初始值设为0呢? 严格地说,为什么不能将权重初值设成一样的值?
这是因为在误差反向传播法中,所有的权重值都会进行相同的更新。
比如,在2层神经网络中,假设第1层和第2层的权重为0。这样一来,正向传播时,因为输人层的权重为0,所以第2层的神经元全部被传递相同的值。第2层的神经元中全部输入相同的值,这意味着反向传播时第2层的权重全部都会进行相同的更新。因此,权重被更新为相同的值,并拥有了对称的值(重复的值)。这使得神经网络拥有许多不同的权重的意义丧失了,所以必须随机生成初始值。
隐藏层的激活值的分布
各层的激活值的分布都要求有适当的广度。因为通过在各层间传递多样性的数据,神经网络可以进行高效的学习。反过来,如果传递的是有所偏向的数据,就会出现梯度消失或者“表现力受限”的问题,导致学习可能无法顺利进行。
现在,在一般的深度学习框架中,Xavier初始值已被作为标准使用,比如,Cafe框架中,通过在设定权重初始值时赋予xavier参数,就可以使用Xavier初始值。Xavier的论文中,为了使各层的激活值呈现出具有相同广度的分布,推导了合适的权重尺度。推导出的结论是,如果前一层的节点数为n,则初值使用标准差为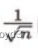
的分布
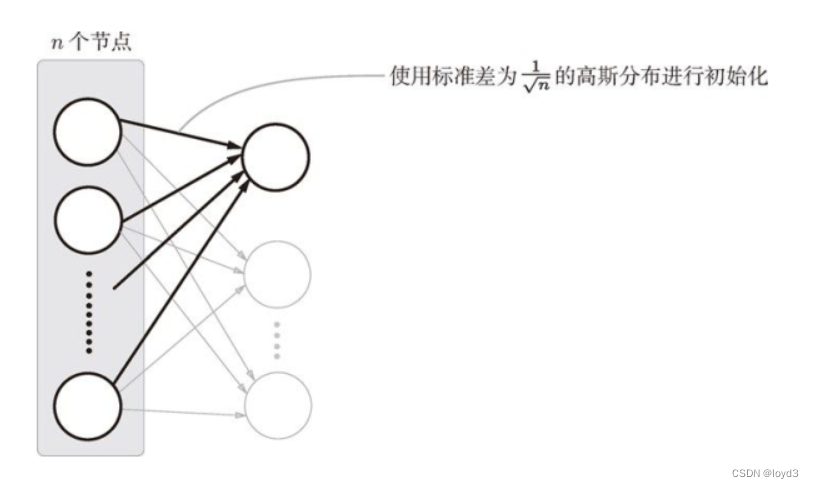
使用Xavier初始值后,前一层的节点数越多,要设定为目标节点的初始值的权重尺度就越小。
ReLU的权重初始值
Xavier初始值是以激活函数是线性函数为前提而推导出来的。因为sigmoid函数和tanh函数左右对称,且中央附近可以视作线性函数,所以适合使用Xavier初始值。但当激活函数使用ReLU时,一般推荐使用ReLU专用的初始值也就是“He初始值”,即:当前一层的节点数为n时,He初始值使用标准差为 的高斯分布。
的高斯分布。
总结一下,当激活函数使用ReLU时,权重初始值使用He初始值,当激活函数为sigmoid或tanh等S型曲线函数时,初始值使用Xavier初始值。这是目前的最佳实践。
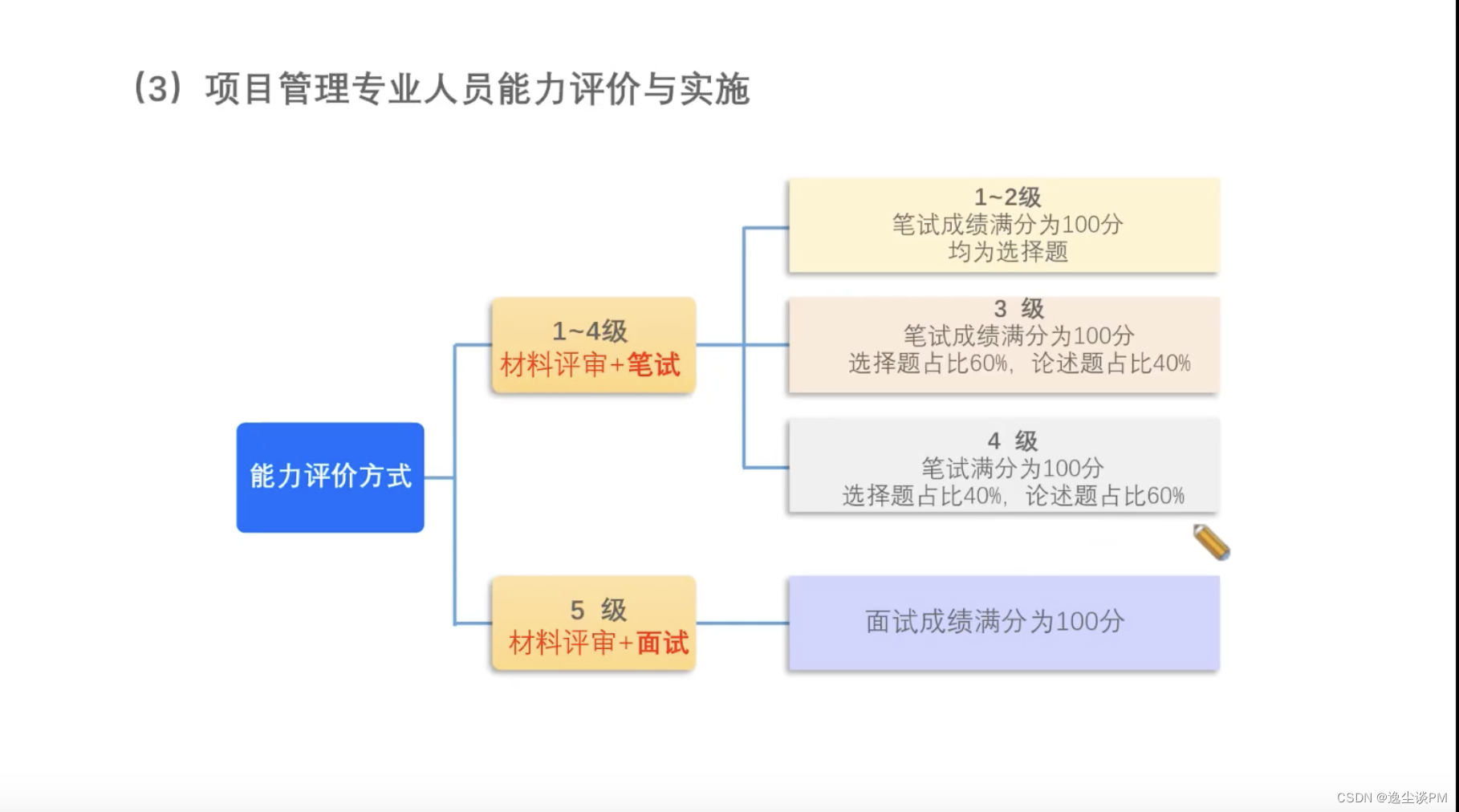
基于MNIST数据集的权重初始值的比较
下面通过实际的数据,观察不同的权重初始值的赋值方法会在多大程度上影响神经网络的学习。这里,我们基于std=0.01、Xavier初始值、He初始值进行实验,测试代码如下:
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet
from common.optimizer import SGD
# 0:读入MNIST数据==========
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000
# 1:进行实验的设置==========
weight_init_types = {'std=0.01': 0.01, 'Xavier': 'sigmoid', 'He': 'relu'}
optimizer = SGD(lr=0.01)
networks = {}
train_loss = {}
for key, weight_type in weight_init_types.items():
networks[key] = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100],
output_size=10, weight_init_std=weight_type)
train_loss[key] = []
# 2:开始训练==========
for i in range(max_iterations):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for key in weight_init_types.keys():
grads = networks[key].gradient(x_batch, t_batch)
optimizer.update(networks[key].params, grads)
loss = networks[key].loss(x_batch, t_batch)
train_loss[key].append(loss)
if i % 100 == 0:
print("===========" + "iteration:" + str(i) + "===========")
for key in weight_init_types.keys():
loss = networks[key].loss(x_batch, t_batch)
print(key + ":" + str(loss))
# 3.绘制图形==========
markers = {'std=0.01': 'o', 'Xavier': 's', 'He': 'D'}
x = np.arange(max_iterations)
for key in weight_init_types.keys():
plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 2.5)
plt.legend()
plt.show()
结果如下:
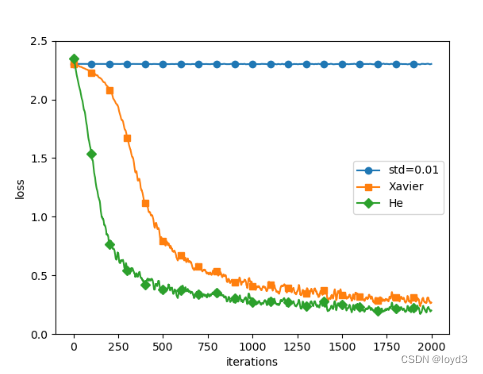
std =0.01时完全无法进行学习。这和才观察到的激活值的分布一样,是因为正向传播中传递的值很小(集中在附近的数据)。因此,逆向传播时求到的梯度也很小,权重几乎不进行更新。
相反,当权重初始值为Xavier初始值和He初始值时,学习进行得很顺利并且,我们发现He初始值时的学习进度更快一些。
综上,在神经网络的学习中,权重初始值非常重要。很多时候权重初值的设定关系到神经网络的学习能否成功。权重初始值的重要性容易被忽视而任何事情的开始(初始值)总是关键的,因此在结束本节之际,再次强调权重初始值的重要性。


![C国演义 [第六章]](https://img-blog.csdnimg.cn/cc166de3ce3144f0a40216160c3b8d2b.png)