欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/131312366
LLaMA 和 Vicuna 都是大语言模型(LLM),两者的差异如下:
-
LLaMA (Large Language Model Meta AI):开放和高效的基础语言模型,这是一系列从7B到65B参数的语言模型,使用公开可用的数据集进行训练,没有使用专有和无法获取的数据集。LLaMA-13B在大多数基准测试中超越了GPT-3 (175B),LLaMA-65B 与最好的模型 Chinchilla-70B 和 PaLM-540B 相当。预训练数据集是多个来源的混合,包括CommonCrawl、C4、Github、Wikipedia、Gutenberg、Books3、ArXiv和Stack Exchange等,总共包含约1.4T个标记。论文:LLaMA: Open and Efficient Foundation Language Models
-
Vicuna: 由 UC伯克利、CMU、斯坦福等机构的学者,在 2022 年发布的一种改进版的 LLaMA,使用了用户共享的对话数据(约70K samples)来进行全量微调,并且降低了训练成本。通过在来自 ShareGPT 的用户共享对话上微调 LLaMA 而训练的,使用 GPT-4 作为评判标准的初步评估显示,Vicuna-13B 在 OpenAI ChatGPT 和 Google Bard 的质量上达到了 90% 以上,同时在 90% 的情况下超过了其他模型,如 LLaMA 和 Stanford Alpaca。
这两种算法都在一些对话任务上表现出了优异的效果,但是也存在着一些局限性,比如编程、推理、数学以及事实准确性等方面的不足。目前,很多大语言模型算法都是基于 Vicuna 进行对齐,例如 DrugChat 等。因此,需要配置 Vicuna 的模型参数。
1. 配置工程
需要配置的工程有2个,都来源于 Hugging Face:
- Vicuna-13B:https://huggingface.co/lmsys/vicuna-13b-delta-v0
- LLaMA-13B-hf:https://huggingface.co/decapoda-research/llama-13b-hf
下载方式,可以参考 Server - 使用网盘快速下载 Hugging Face 大模型,使用网盘下载速度要快于Git LFS。
普通方式:
git lfs install
git clone https://huggingface.co/lmsys/vicuna-7b-delta-v0.git
cd vicuna-7b-delta-v0
git lfs pull
git lfs install
git clone https://huggingface.co/decapoda-research/llama-13b-hf.git
cd llama-13b-hf
git lfs pull
其中,bin 文件 和 model 文件较大,可以离线下载之后,再覆盖。
git clone 如果遇到 Bug,TCP connection reset by peer,建议使用 ssh 的方式下载,需要简单配置一下,参考 Server - 使用网盘快速下载 Hugging Face 大模型。
2. 组合权重
不同版本的 Vicuna,使用不同的 FastChat 版本,例如v0,使用 FastChat 版本是v0.1.10。
具体配置参考:GitHub - vicuna_weights_version.md
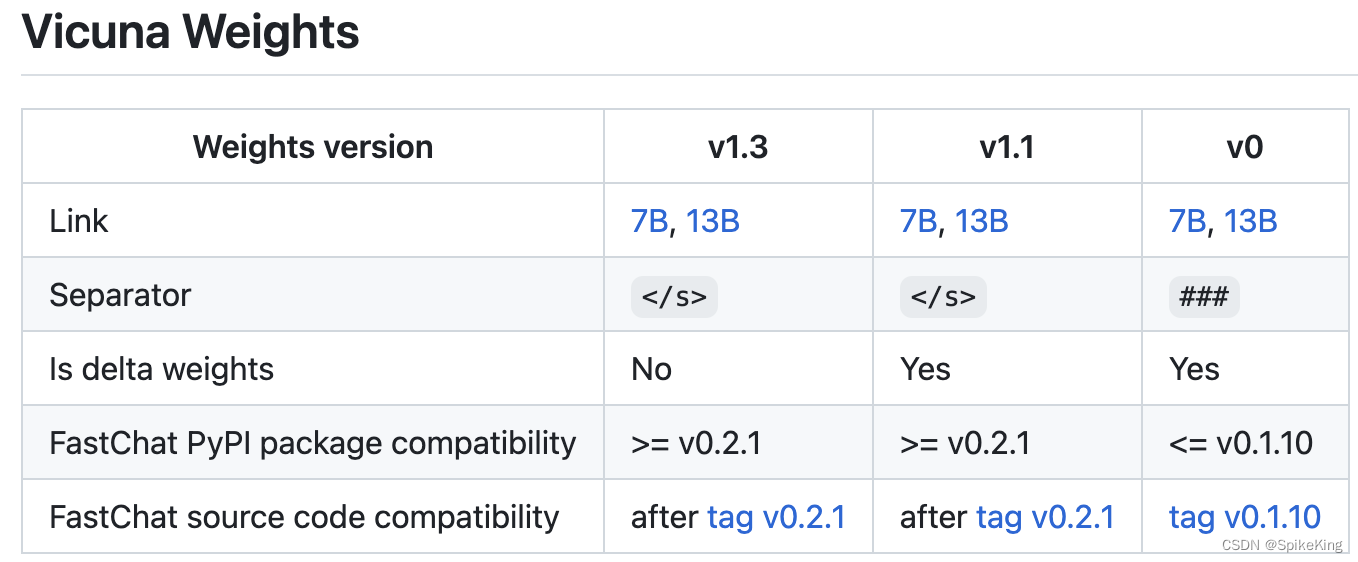
配置环境:
conda create -n vicuna python=3.8
source activate vicuna
pip install fschat==0.1.10 # 注意版本
下载工程,注意切换版本:
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
git checkout v0.1.10 # 注意版本
更新 transformers 库,因为 transformers 库,随着版本不同,包括的 Tokenizer 和 Model 的函数不同:
pip install --upgrade transformers
查看 fschat 和 transformers 的版本,如下:
pip show fschat transformers
Name: fschat
Version: 0.1.10
---
Name: transformers
Version: 4.28.1
修改 FastChat 工程的 fastchat/model/apply_delta.py 文件,版本不同,函数不同:
AutoTokenizer 全部替换为 LlamaTokenizer
AutoModelForCausalLM 全部替换为 LlamaForCausalLM
即:
...
from transformers import LlamaTokenizer, LlamaForCausalLM
def apply_delta(base_model_path, target_model_path, delta_path):
print(f"Loading the base model from {base_model_path}")
base = LlamaForCausalLM.from_pretrained(
base_model_path, torch_dtype=torch.float16, low_cpu_mem_usage=True)
print(f"Loading the delta from {delta_path}")
delta = LlamaForCausalLM.from_pretrained(delta_path, torch_dtype=torch.float16, low_cpu_mem_usage=True)
delta_tokenizer = LlamaTokenizer.from_pretrained(delta_path, use_fast=False)
DEFAULT_PAD_TOKEN = "[PAD]"
base_tokenizer = LlamaTokenizer.from_pretrained(base_model_path, use_fast=False)
num_new_tokens = base_tokenizer.add_special_tokens(dict(pad_token=DEFAULT_PAD_TOKEN))
...
否则报错:
ValueError: Tokenizer class LLaMATokenizer does not exist or is not currently imported.
接着,组合模型权重:
- 脚本:
apply_delta.py - llama权重:
llama-13b-hf/ - vicuna权重:
vicuna-13b-delta-v0/ - 输出权重:
vicuna-13b-weight/
CUDA_VISIBLE_DEVICES=1 python FastChat/fastchat/model/apply_delta.py --base-model-path llama-13b-hf/ --delta-path vicuna-13b-delta-v0/ --target-model-path vicuna-13b-weight/
3. 测试权重
执行脚本,即可命令行,使用:
CUDA_VISIBLE_DEVICES=3,4 python -m fastchat.serve.cli --model-path ./vicuna-13b-weight --style rich --num-gpus 2
运行如下:
- 问题1:let’s talk something about biological pharmacy ?
- 问题2:What are the big pharmaceutical companies in the world ?
日志如下:

测试成功。
参考:
- CSDN - Vicuna 模型学习与实战
- GitHub - lm-sys/FastChat
- GitHub - vicuna_weights_version.md
- 知乎 -【LLMs 入门实战 —— 八 】MiniGPT-4 模型学习与实战
- GitHub - Vision-CAIR/MiniGPT-4
- Server - 使用网盘快速下载 Hugging Face 大模型