硬件选择:
1.求出一天kafka会产出大概多少的消息,然后平均到每一秒,要多少的消息,然后一条消息大概就是0.5-2k的大小,求出,每秒占用多少内存
2.求购买服务器数量=(上边求出的效率 * 副本数/100)+1
如果除不尽,则向上取整
3.磁盘选择,因为机械硬盘和固态硬盘的顺序读取速度一致,所有机械硬盘即可,kafka是按顺序追加log文件
所有服务器加起来的总内存=(一天的大概条数 * 每条占用的内存 *3 )/0.7
4.内存选择
堆内存(kafka的内部缓存)+页缓存(系统内存,前边kafka存储结构中讲过)
- 堆内存,在 kafka-server-start.sh中配置
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70" export JMX_PORT="9999" #监控kafka运行情况的端口号 #export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" fi一般生产环境10-15g即可,可以通过查看实际的堆内存使用情况,通过如下命令
jmap -heap 进程号
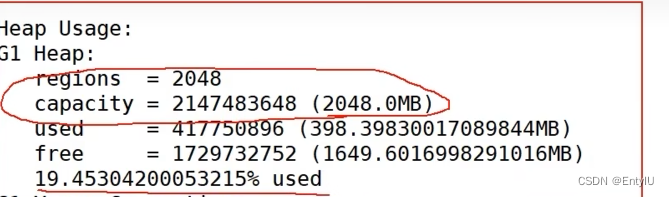
上边是我们在配置文件中配置的2g总内存,下边是占用情况,如果到70%以上,就要考虑加一点堆内存了
- 页缓存 选择
(分区数 * 1g *25% )/3=每台的页缓存内存需求
总的来说,两个加起来就是我们的内存最佳值
5.cpu

生产者优化:

broker优化:
增加主题分区
消费者优化:
(1)调整参数

(2)多增加消费者数量,但也要根据实际分区数来定,多了就会闲置