【多智能体合作】Self-Organized Group for Cooperative Multi-agent Reinforcement Learning
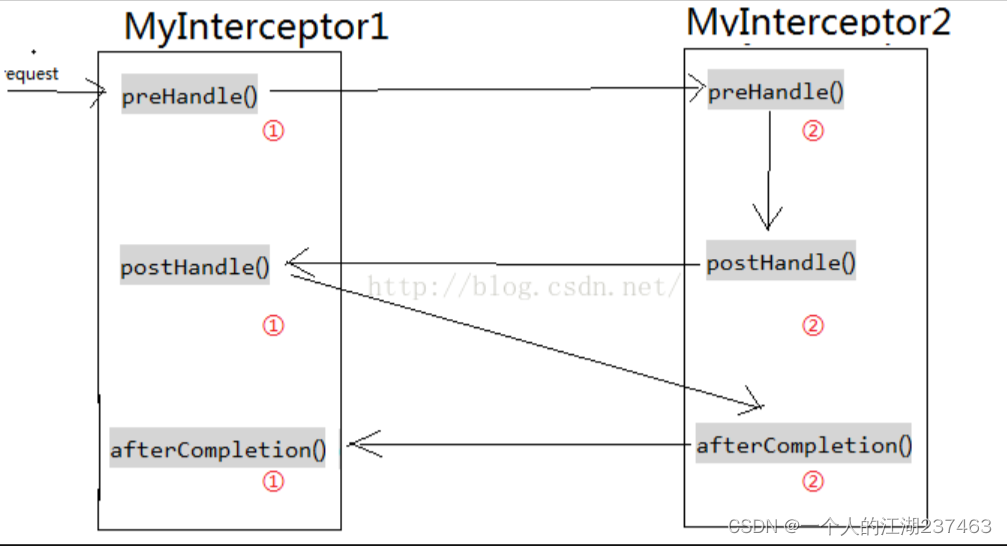
本文提出了一个自主分组机制,这种机制具有 选举指挥官(CE) 和 消息总结(MS) 的功能。
- 在 CE 中,每隔 T个时间步,选举出一定数量的指挥官来暂时构建群组,每个群组都具有 指挥官-追随者 的共识,追随者只能与其指挥官进行通信。
- 在 MS 中,每个指挥官对接收到的消息进行总结并分发给所有隶属群组成员,以进行统一的调度。
作用:当面对未知情景时,每个智能体的行为很容易偏离训练模式。它们可能表现出矛盾的行为方式,并对系统的稳定性构成威胁。相反,指挥官可以发送统一的指令,使每个智能体有序地行动,从而 避免整体训练模式的崩溃。同时,本文的方法大大 减少了通信所需的带宽和成本。为了实现高效且经济的消息传递,本文还设计了一种变分消息总结器(MS),它压缩了局部观测信息,并有助于预测未来的轨迹。
本文解决了什么问题?
现有的基于 集中式训练分布式执行方法(CTDE) 的协同多智能体方法的泛化性较差,主要体现在团队成员数量变化和可变的局部观测的泛化性较差。
经典的 CTDE 算法,如QMIX 和MADDPG,受限于固定数量的智能体。然而,在现实世界的多智能体场景中,参与的智能体数量往往是变化的。最近,一些方法引入了注意力机制 ,以同时训练不同数量的智能体。它们只寻求解决方案覆盖一定范围内的变化团队规模,无法提供对超出该范围的情况的泛化能力。
以下图简单任务为例,该任务仅在三个按钮同时按下时才能完成 。

因此,智能体 A、B 和 C 分别需要按下三个不可重复的按钮。按钮 1 和 2 相距十米,而按钮 3 位于它们的中点位置。每个智能体的视野范围是一个 半径为六米 的圆。因此,负责按钮 2 的智能体无法感知到是否有其他智能体按下按钮 1,因为受到视野范围限制。
如果使用常规的集中式训练分散执行(CTDE)方法,例如 QMIX ,处理这个任务,这些智能体在超出个体视野范围时无法有效协调,因为每个智能体的执行都取决于其自己的行动-观察历史 。智能体之间的通信是处理部分可观测性的一种简单而灵活的解决方案之一。
本文的解决方法是什么?
针对具有动态团队组成的合作多智能体任务,每隔 T 个时间步长,选举出一定数量的指挥者,并相应地构建分组。
由于本文的主要任务是多智能体强化学习,简化了通信过程,假设所有消息都可以准确无误地传递且没有延迟,并且每个智能体可以同时处理所有接收到的消息。本文的目标是构建一个满足以下特性的通信机制:
- 轻量级。通信消息应简洁而具有信息量,例如,智能体当前状态的三维摘要向量。
- 鲁棒性。分组应能够处理 不同数量的群体成员 和 不熟悉的环境条件 (例如不同的视野范围)。
通信协议的设计



通信内容设计:消息总结(Message Summary)

指挥官选举(Conductor Election)

实验结果如何?
本文实验设计回答以下问题:
- SOG 是否比 全连接通信 方法更好地帮助多智能体协调?
- SOG 能否促进对于 动态团队组成 和 不断变化的部分可观察性 的零样本泛化?
- SOG 中选举指挥官的方式对结果有什么影响?
- 哪一个因素对 SOG 的影响最大?
实验环境
-
资源收集
智能体需要从 6 个资源点收集资源并将货物运送回家。训练时智能体的数量从
{2,3,4,5}中均匀采样,而测试时从{6,7,8}中采样。每个智能体有一个视野范围 S R SR SR 。对于智能体 i i i 来说,超出其视野范围的其他智能体和资源点对智能体 i i i 是不可见的。 -
捕食者-猎物
智能体扮演捕食者的角色,旨在捕捉一些进行随机行走的猎物。训练时,捕食者的数量从
{3,4}中进行采样,同时只有1个猎物。在执行过程中,我们初始化5 或 6个捕食者,以及1 或 2个猎物。 -
星际争霸2
在每个回合的开始,地图会随机初始化
3-8个智能体和相同数量的敌人。我们将训练过程中的智能体数量限制在3-5个,并使用智能体数量为6-8的情况测试模型。
在上述每个场景中,智能体的数量是不固定的,也就是在 每个场景的每个回合 开始前会对当前回合的智能体数量进行采样。测试任务比训练任务更加复杂,需要处理在训练阶段没有遇到的情况。
实验结果
-
Resource Collection
作者在两种视野范围(SR)0.5和1.0上进行训练。在图4(a-b)中展示了所有方法的结果。当SR=0.5和SR=1.0时,SOG明显优于其他方法。考虑到测试场景包含6/7/8个智能体,而训练场景只有2/3/4/5个智能体,SOG的通信机制极大地增强了其对动态团队组成的零-shot泛化能力。当团队规模变化时,指挥官选举(CE)方法之间没有明显差异。
然后,作者在不同的环境条件下测试零样本泛化能力。我们保存了之前用固定视野范围 0.5 或 1.0 训练的模型,并在不同的智能体视野范围设置上进行评估。每个设置重复进行160个测试回合,结果是在具有不同种子的3个模型上进行平均。我们在图4(c-d)中展示了每种方法的表现。**除了SR = 0.2这种困难的设置,所有方法在从SR = 0.5到SR = 1.0的不同情景中表现出与训练情景相似甚至更好的性能。**SOG_rl甚至在从SR = 1.0转换到SR = 0.8时表现更好。与此同时,其他方法在从训练设置转换到其他设置时都显示出明显的性能下降。结果显示了SOG在未知情景下的强大适应能力。

- StarCraft Micromanagement Tasks
首先,作者探讨了对于 动态团队组成的适应性 。如图5(a)所示,在4个地图上的结果表明,当以比训练时更多的智能体和敌人数量进行模型测试时,我们的方法在与预设AI对战时具有最高的测试胜率。而基于PG的指挥官选举策略在3-8sz上改善了性能。结合资源收集的结果,我们得出结论:基于PG的指挥官选举策略可以在许多情况下提高智能体对于动态团队组成的零样本泛化能力,这是由于相较于随机选举,基于PG的策略具有更合理的指挥官选举机制 。
接下来,作者研究了对于 不同环境条件的适应性 。作者保存了在3-8sz_D地图上以视野范围为3训练的模型,这是一个难度较高的情况,智能体被分散并且视野受限。然后我们在其他初始条件和视野范围下评估这些模型的性能。结果如图5(b)所示。初始条件(Gather或Disperse)对于所有四种方法的性能都没有明显影响。然而,当智能体能够看到比训练时更多的实体时,其他三种方法的性能都大幅下降,而我们的方法在性能上与训练中的表现相当。这可能是由于群组内的统一消息传递机制所致。有趣的现象是,随机CE在2个场景中的性能与基于RL的CE相当或更好。作者推测这是由于不同环境设置下随机CE的相似模式所导致的

- Predator Prey
首先,作者探索了 消息总结器 的效果。除了LFP和LCEB之外,我们还尝试了类似于Wang等人的熵正则化器。它旨在通过最大化消息的熵来促进探索。如表1所示,LFP和LCEB的组合获得了最佳的平均测试回报,超过了CTDE方法A-QMIX和通信方法EMP的性能。虽然熵正则化器有助于稳定训练(与正则化器结合时降低了方差),但对于平均性能没有贡献。因此,我们将LF P + LCEB作为消息总结器的默认损失函数。请注意,在训练场景中,EMP的性能与SOG相似。然而,当应用于复杂的评估场景时,SOG表现更好。

在表2中分析了与通信相关的选择,包括期望中的 群组数量、消息维度 和 通信间隔 。群组数量为2的性能优于数量为1或4的情况。由于猎物需要同时被 3 个捕食者捕捉的规则,将 5 或 6 个智能体分成 2 组是合适的。当消息维度从10降低到3时,结果并没有明显下降。然而,当消息维度设置为1时,结果大幅下降。结果表明,对于捕食者-猎物任务,3维消息足够进行通信。至于通信间隔,T = 2比T = 4稍好,而T = 10对于充分的通信来说不够。








![[学习笔记] [机器学习] 13. 集成学习进阶(XGBoost、OTTO案例实现、LightGBM、PUBG玩家排名预测)](https://img-blog.csdnimg.cn/501c3f355f084d4980b202cb08356348.png#pic_center)