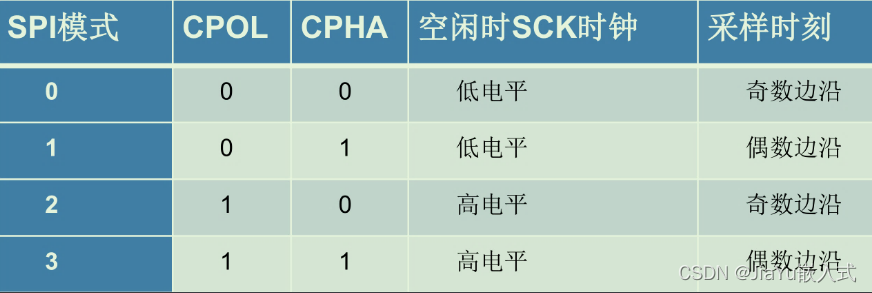
4. 启动Spark Shell编程
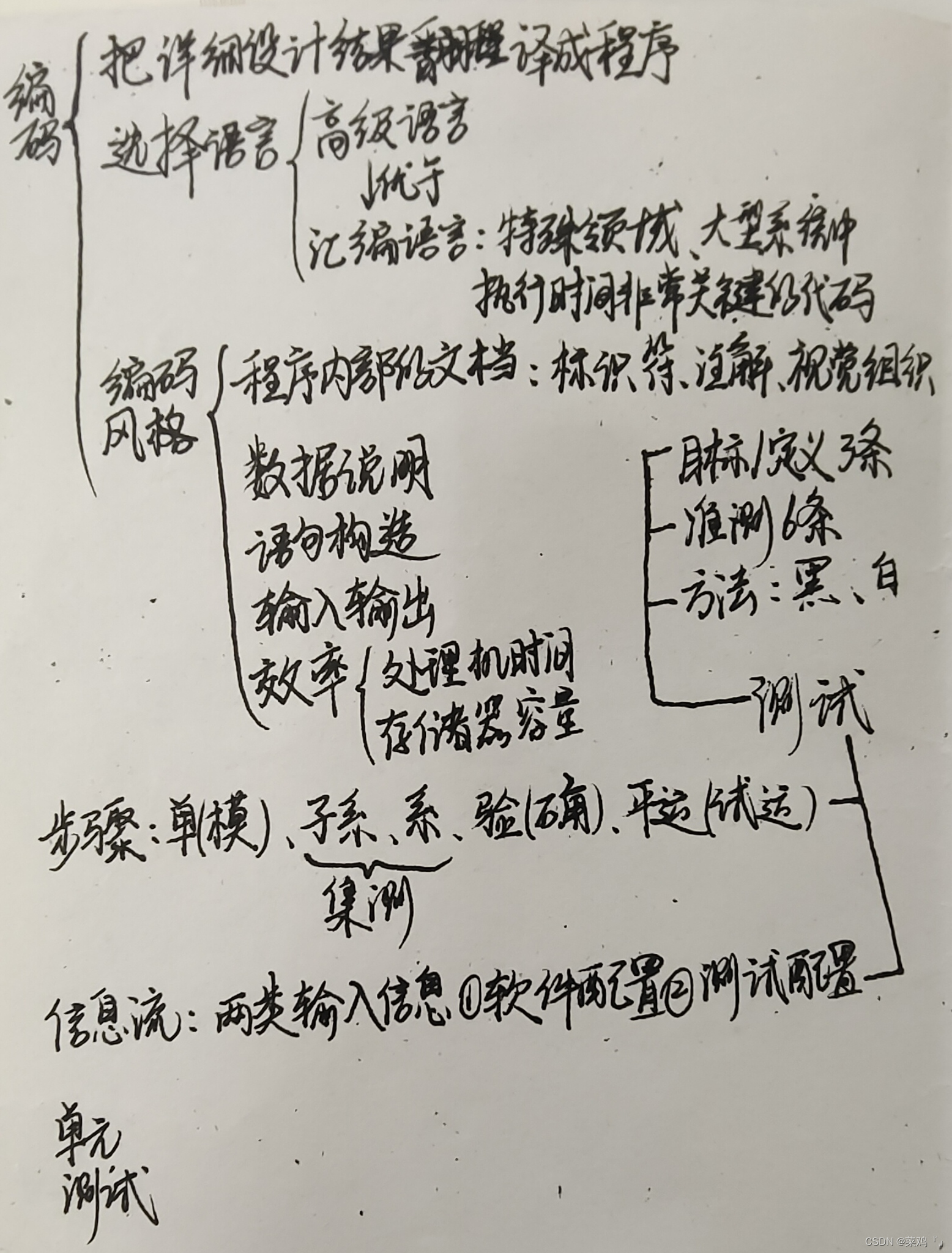
4.1 什么是Spark Shell
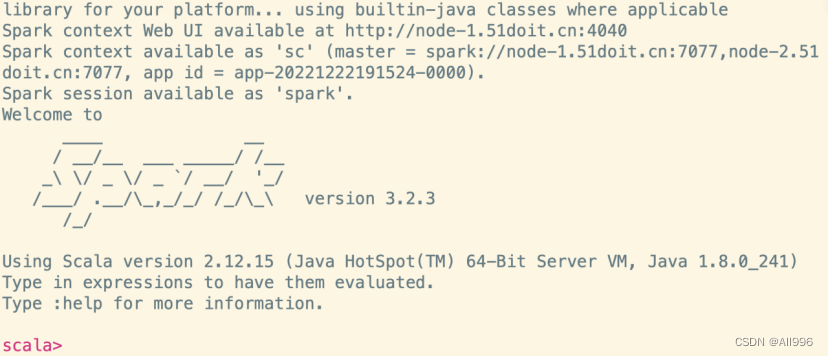
spark shell是spark中的交互式命令行客户端,可以在spark shell中使用scala编写spark程序,启动后默认已经创建了SparkContext,别名为sc
4.2 启动Spark Shell
Shell
如果Master配置了HA高可用,需要指定两个Master(因为这两个Master任意一个都可能是Active状态)
Shell
参数说明:
--master 指定masterd地址和端口,协议为spark://,端口是RPC的通信端口
--executor-memory 指定每一个executor的使用的内存大小
--total-executor-cores 指定整个application总共使用了cores
Shell
5. Spark编程入门
5.1 Scala编写Spark的WorkCount
5.1.1 创建一个Maven项目
5.1.2 在pom.xml中添加依赖和插件
XML
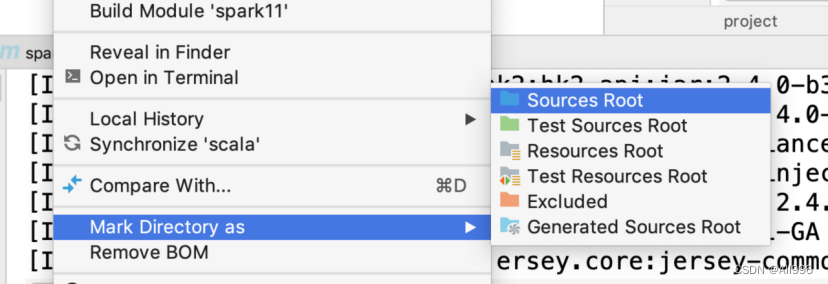
5.1.3 创建一个scala目录
选择scala目录,右键,将目录转成源码包,或者点击maven的刷新按钮
5.1.4 编写Spark程序
Scala
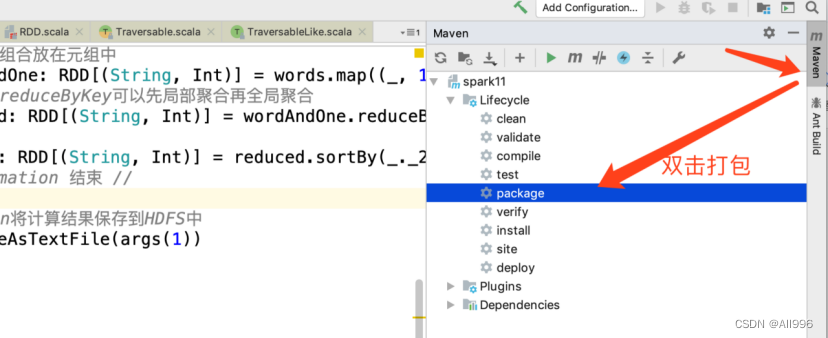
5.1.5 使用maven打包
使用idea图形界面打包:
5.1.6 提交任务
上传jar包到服务器,然后使用sparksubmit命令提交任务
Shell
参数说明:
--master 指定masterd地址和端口,协议为spark://,端口是RPC的通信端口
--executor-memory 指定每一个executor的使用的内存大小
--total-executor-cores 指定整个application总共使用了cores
--class 指定程序的main方法全类名
jar包路径 args0 args1
5.2 Java编写Spark的WordCount
5.2.1 使用匿名实现类方式
Java
5.2.2 使用Lambda表达式方式
Java
5.3 本地运行Spark和Debug
spark程序每次都打包上在提交到集群上比较麻烦且不方便调试,Spark还可以进行Local模式运行,方便测试和调试
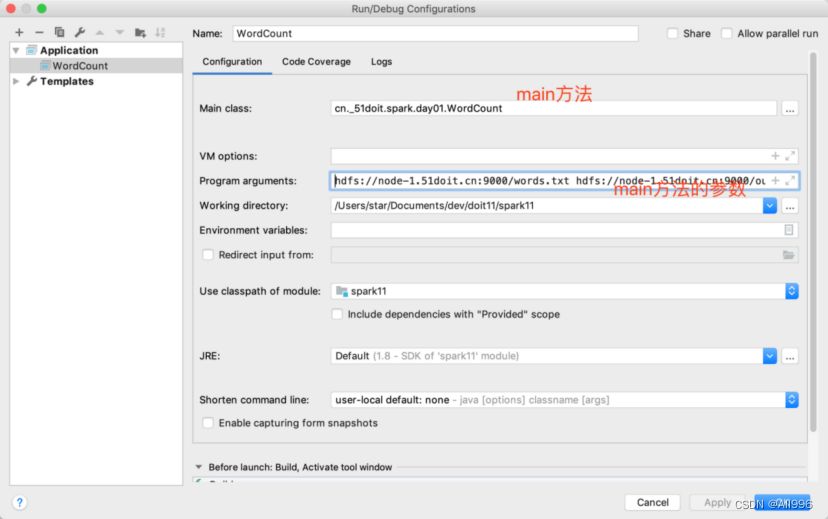
5.3.1 在本地运行
Scala
5.3.2 读取HDFS中的数据
由于往HDFS中的写入数据存在权限问题,所以在代码中设置用户为HDFS目录的所属用户
Scala
5.4 使用PySpark(选学)
5.4.1 配置python环境
① 在所有节点上按照python3,版本必须是python3.6及以上版本
Shell
② 修改所有节点的环境变量
Shell export PYSPARK_PYTHON=python3
5.4.2 使用pyspark shell
Shell
在pyspark shell使用python编写wordcount
Python
5.4.3 配置PyCharm开发环境
①配置python的环境
②配置pyspark的依赖
点击Project Structure将Spark安装包下python/lib目录的py4j-*-src.zip和pyspark.zip添加进来
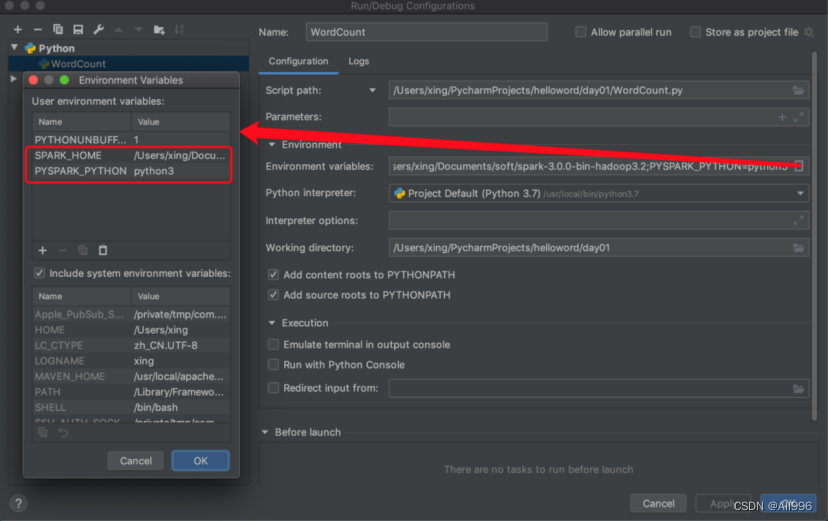
③添加环境变量
点击Edit Configuration
在pycharm中使用python编写wordcount
Python











![[学习笔记] [机器学习] 13. 集成学习进阶(XGBoost、OTTO案例实现、LightGBM、PUBG玩家排名预测)](https://img-blog.csdnimg.cn/501c3f355f084d4980b202cb08356348.png#pic_center)