注:以下知识点总结是将数据转为DataFrame格式数据的基础之上进行操作的
(首先需要做的是将数据转为DataFrame格式)
DataFrame格式示例:
import pandas as pd
data = {
"code": ['000008', '000009', '000021', '000027', '000034', '000058', '000062', '000063', '000063', '000063', '000063'],
"name": ['神州科技', '中国宝安', '深科技', '深圳能源', '神州数码', '深赛格', '深圳华强', '中兴通讯', '中兴通讯', '中兴通讯', '中兴通讯'],
"concept": ['5G', '创投', '芯片概念', '创投', '网络安全', '创投', '创投', '芯片概念', '边缘计算', '网络安全', '5G'],
}
stock_df = pd.DataFrame(data=data)
print(stock_df)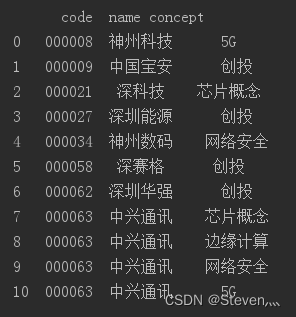
1、对某列字符替换
比如:将编码‘ys4ng35toofdviy9ce0pn1uxw2x7trjb’替换为 ‘娱乐’(较多替换建议使用该方法)
dicts = {'ys4ng35toofdviy9ce0pn1uxw2x7trjb':'娱乐',
'vekgqjtw3ax20udsniycjv1hdsa7t4oz':'经济',
'vjzy0fobzgxkcnlbrsduhp47f8pxcoaj':'军事',
'uamwbfqlxo7bu0warx6vkhefigkhtoz3':'政治',
'lyr1hbrnmg9qzvwuzlk5fas7v628jiqx':'文化',
}
res['name'] = res['name'].map(lambda x:dicts[x] if x in dicts else x)
print(res)或者:
比如:将5G 替换为 6G,创投 替换为 创业投资(个别需要替换建议此方法)
stock_df['concept'] = stock_df['concept'].str.replace('5G', '6G').str.replace('创投', '创业投资')
print(stock_df) 2、分组统计
name value
0 娱乐 8
1 经济 5
2 军事 3
3 政治 3
4 娱乐 2
5 文化 1
6 政治 1
7 经济 1
8 军事 1
9 文化 1#分组统计 一列分类统计求和用sum
result = res.groupby(['name']).sum().reset_index()
print(result)
运行结果:
name value
0 军事 4
1 娱乐 10
2 政治 4
3 文化 2
4 经济 63、聚合统计(按多个列多层分组)
# 聚合统计 多列分类聚合求和用size()
data = result.groupby(['name', 'type']).size().reset_index(name='value')4、根据某列进行排序
#排序
result = result.sort_values(['value'], ascending=False)5、dataframe格式转字典
# 输出为list,前端需要的数据格式
data_dict = result.to_dict(orient='records')
print(data_dict)
# 指定某两列转字典
res_df = res_df[['zhongzhi_date', 'cumsum']].to_dict(orient='records')
# 结果
[{'name': '娱乐', 'value': 10}, {'name': '经济', 'value': 6},
{'name': '军事', 'value': 4}, {'name': '政治', 'value': 4},
{'name': '文化', 'value': 2}]6、datafrane 多行合并为一行

def ab(df):
return','.join(df.values)
df = df.groupby(['code','name'])['concept'].apply(ab)
df = df.reset_index()
print(df)
7、新增一列与删除一列
# 新增一列
stock_df['new_column'] = '股票'
print(stock_df)
# 删除一列法一
stock_df.pop('new_column')
print(stock_df)
# 删除一列法二
stock_df = stock_df.drop('new_column', axis=1)
print(stock_df)8、删除某列字符大于8的行
# 删除字符大于8的行
text_data = text_data.drop(text_data[text_data['name'].str.len() > 8].index) 9、dataframe某列转字符串、整型
# 将code列转字符串
stock_df['code'] = stock_df['code'].astype(str)
# 将code列转整型
stock_df['code'] = stock_df['code'].astype(int)10、删除包含某特殊字符的行
# 去掉包含'null'的行
result = result[~ result['name'].str.contains('null')]
# 去掉包含'0'的行
result = result[~ result['name'].str.contains('0')] 11、对某列文本中包含的字符进行替换删除
text_data['name'] = text_data['name'].map(lambda x: x.replace('罪', ''))12、dataframe截取某列字符
例如:casenumber列格式: ***刑通[3099]第666号
result['category'] = result['casenumber'].map(lambda x:str(x)[3:5])
result['category'] = result['category'].replace('刑通', '刑事案件').replace('民申', '民事案件').replace('刑申', '刑事案件').replace('行申', '行政案件').replace('刑认', '刑事案件')
print(result)13、指定时间格式
result['noticetime'] = result['noticetime'].dt.strftime('%Y%m%d')14、两个dataframe格式合并,并对空值/缺失值进行填充
可以根据一个或多个键将不同的DataFrame中的行连接起来,并将空值填充为‘不详’
1、根据单个或多个键将不同的DataFrame的行连接起来
2、类比sql join操作
3、默认将重叠列的列名作为“外键”进行连接
on 显式的指定 “外键”result = pd.merge(res2, res, how='outer').fillna('不详')
left_on 左侧数据的外键
right_on 右侧数据的外键
4、默认是 “内连接”(inner),即结果中的键是交集
result = pd.merge(res2, res, how='outer').fillna('不详') - concat:可以沿一条轴将多个对象连接到一起
- merge:可以根据一个或多个键将不同的DataFrame中的行连接起来。
- join:inner是交集,outer是并集。
15、 在某列数据末尾添加特殊字符
stock_df['new_column'] = stock_df['new_column'].map(lambda x: str(x) + '年')16、dropna 丢弃缺失数据(处理缺失数据)
# 删除
stock_df.dropna()
# 填充
stock_df.fillna('null')17、获取索引和数据 预览数据,默认打印前五个
#获取索引
print(stock_df.index)
# 获取数据
print(stock_df.values)
# 预览数据,默认是前5个
print(stock_df.head(3))
# 预览数据,默认是后5个
print(stock_df.tail(3))18、删除重复数据
#重复数据
df_obj.duplicated()
#删除重复数据
df_obj.drop_duplicates()
#删除指定列重复数据
df_obj.drop_duplicates('data2')19、常用的统计计算:sum、mean、max、min
axis=0 按列统计,axis=1 按行统计(axis=0时,表示最后的数据是一行,所以需要按列统计,axis=1时,表示最后的数据是一列,所以需要按行统计)
stock_df.sum()
stock_df.max()
stock_df.min(axis=1)
# 统计描述
print(stock_df.describe())20、聚合aggregation
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randint(1,10, 8),
'data2': np.random.randint(1,10, 8)}
df_obj5 = pd.DataFrame(dict_obj)
print(df_obj5)
# 内置的聚合函数
print(df_obj5.groupby('key1').sum())
print(df_obj5.groupby('key1').max())
print(df_obj5.groupby('key1').min())
print(df_obj5.groupby('key1').mean())
print(df_obj5.groupby('key1').size())
print(df_obj5.groupby('key1').count())
print(df_obj5.groupby('key1').describe())
# 自定义聚合函数,传入agg方法中
def peak_range(df):
"""
返回数值范围
"""
#print type(df) #参数为索引所对应的记录
return df.max() - df.min()
print(df_obj5.groupby('key1').agg(peak_range))
print(df_obj5.groupby('key1').agg(lambda df : df.max() - df.min()))21、使用countains可以用来正则匹配筛选
#使用countains可以用来正则匹配筛选 (将 合计 列中包含change值的行 数量列 值改为C)
df.loc[df['合计'].str.contains('change'), '数量'] = 'C'
# print(df)#某些列满足特定条件,然后改变另外的某些列的值(先定位到 数量 列中为A的行,再将对应该行以及对应 合计 列中的值改为changed )
df.loc[df['数量'] == 'A', '合计'] = 'changed' # 关键句,直接改变df的值22、某列累计求和 cumsum函数
res_df['cumsum'] = res_df['data_num'].cumsum()
print(res_df)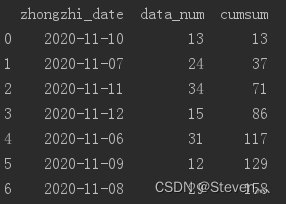
23、某列整体计算 (整体加上一个数)
res_total[0] = 7131
res_df['cumsum'] = res_df['cumsum'] + res_total[0]
print(res_df)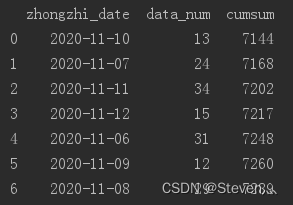
24、 根据某一列值得范围,对另一列进行赋值
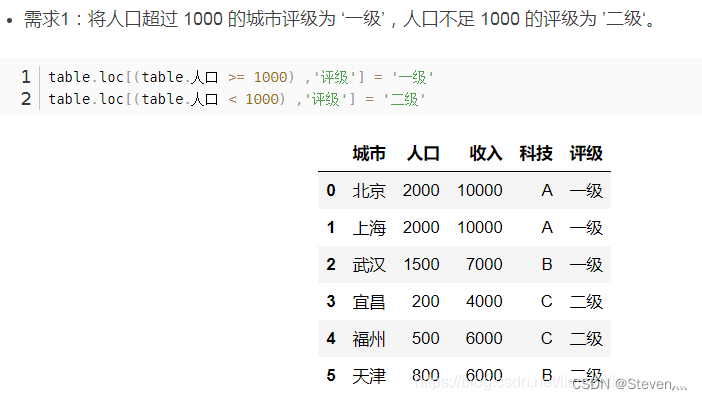
25、根据某几列值的范围,对另一列进行赋值
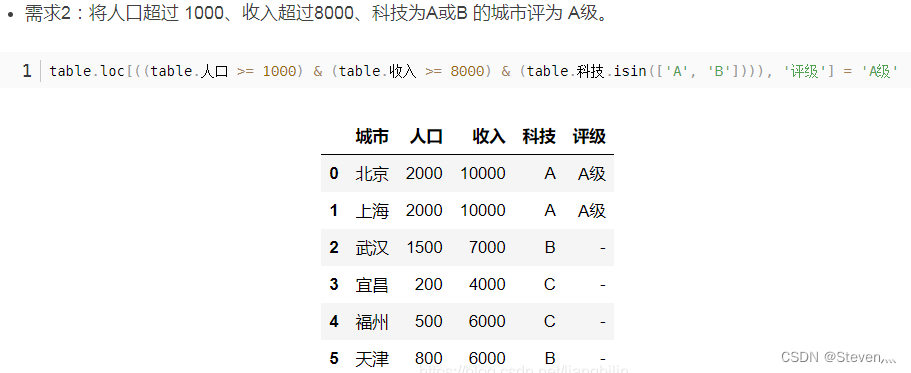
26、 比较Pandas中的当前行和上一行
Open High Low Close Volume Position
0 1.20821 1.20821 1.20793 1.20794 138.96 -
1 1.20794 1.20795 1.20787 1.20788 119.61 DOWN
2 1.20788 1.20793 1.20770 1.20779 210.42 DOWN
3 1.20779 1.20791 1.20779 1.20789 77.51 DOWN
4 1.20789 1.20795 1.20789 1.20792 56.97 DOWNdf['Position'] = np.where((df['Volume'] > df['Volume'].shift(-1)) &
((df['Close'] >= df['Close'].shift(-1)) & (df['Open'] <= df['Open'])),
"UP","DOWN")27、对某一列进行处理(对某列的时间格式进行处理)
concat_df['changed_on'] = concat_df['changed_on'].apply(lambda x: str(x)[:19])28、多列合并为一列
res_df['huji_address'] = res_df['huji_name']+res_df['hujisuozaidi']29、根据某列中的记录,删除重复项
res_df = res_df.drop_duplicates(['p_name'], keep='last').reindex()30、某两列时间相减
df_data['new_time'] = pd.DataFrame(pd.to_datetime(
df_data['target_time']) - pd.to_datetime(df_data['start_time']))31、pandas dataframe 删除去掉默认索引 、取消索引、重置索引
删除默认索引(给其设置新的索引,则默认索引就去除了):
res_df.set_index(['report_time'], inplace=True)取消索引(取消所有索引,恢复到默认索引):
res_df = res_df.reset_index()重置索引:
res_df = res_df.reset_index(drop=True)32、pandas 统计某一列中各个值的出现次数
#可以通过df.colname 来指定某个列,value_counts()在这里进行计数,其中city为某一列的字段名
df2 = df1.city.value_counts()
print(df2)pandas官方文档:Pandas: 强大的 Python 数据分析支持库 | Pandas