我写这篇文字,实属无奈,在目前很多企业都依赖云的情况下,数据库的很多事情都是身不由己,发生问题,你查看日志,分析日志可能你连日志都不是全部的,并且想通过程序来过滤这个日志很多情况下都有限制或根本不行。这些都是其次,今天要说的是 云的 RDS 产品的高可用的问题,无法信任。
首先还是要说两句,1 这个帖子不会说是那个云,读者你也不要问是那个云, 2 丢数,我个人认为在云上这是必然的,不是偶然,只是触发概率的问题。(原因很清楚,我说的这个问题,到那个云都一样,越先进的越会有这个问题)
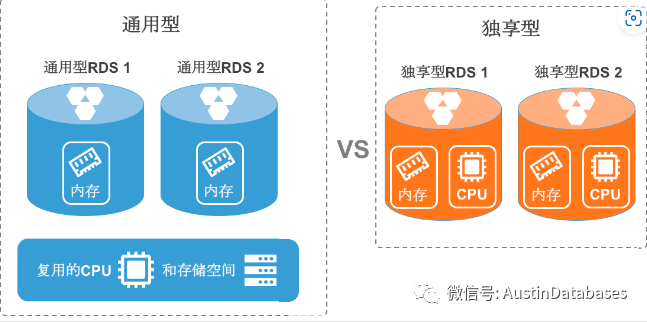
需要注明的是,云上RDS 系统的高可用,和咱们实体机的高可用不是一个概念,形成的方式也不一样,我们先熟悉一下云上RDS 产品的形成方式,主要RDS 有两种
1 通用性产品,产品本身主要的共享部分是CPU ,实际上就是你花钱买的4 核心的CPU 在某个时间段是你的,而在另一个时间段是别人的,所以如果有的别人在拼命的用这些CPU ,那么你的任务很可能会等待,等空余出4 CORE CPU 才能给你进行运算。
2 独享性产品 独享的产品本身与共享型产品的核心不同就是CPU ,CPU是自己独有的所以相关的价格也必然比通用性的要高。
当然这个和我说的这个问题么有太大的关系,我们来说说 RDS OF MYSQL 的在某云的高可用方式。画一个大致的图。在云内,每个部分都是由不同的部门进行负责的,而高可用这个部分,他就不属于mysql rds or postgresql rds 他是一个独立的部门或组,也就是和美国三权分立一样,各管各的,这就导致一个问题,如何判断数据库死掉了。
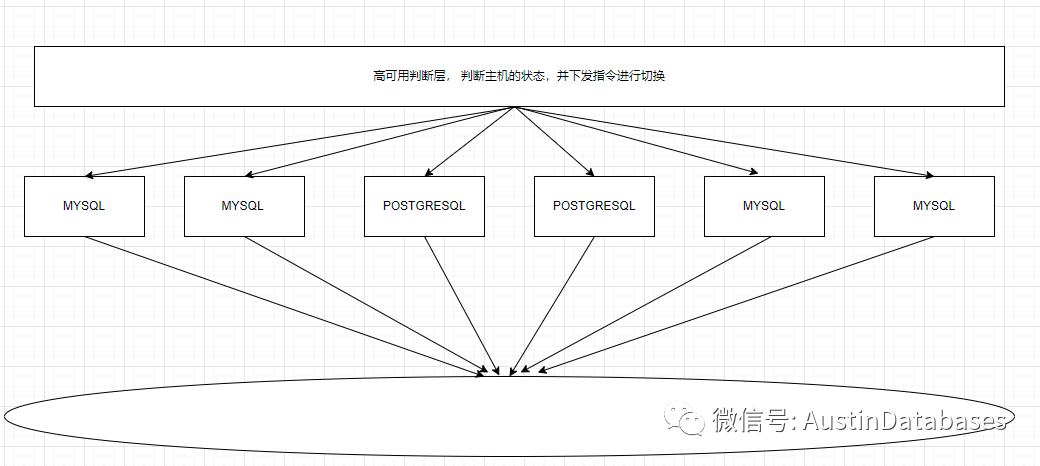
传统的数据库中我们判断数据库的服务是否在,有很多方法,如PING 法,访问数据库法, 或者判断服务运行法,等等,同时辅助与多个点来进行判断。 一般来说出现问题后,不会出现太多误报的问题。
而云上不是,云上的节点众多,而判断节点的高可用程序和数据库必然不在一个层面中,具体是不是在一个网段中,我不知道,但是如果在一个网段,则这个高可用的部署成本会很高。假设他不在一个网段,则网络的问题必然会导致误判节点DOWN机。同时判断一个数据库服务是否存在,在云上的数据库也只能弄一个大概,太敏感了,容易切换,导致用户不满意, 而不敏感不切换,长时间数据库无法响应,客户还是不满意,实际上在线下的问题,不会因为你的数据库迁移到了线上,这个问题就解决了,从成本的角度考虑,不会有技术上的提高,所以失败的概率必然是有的。
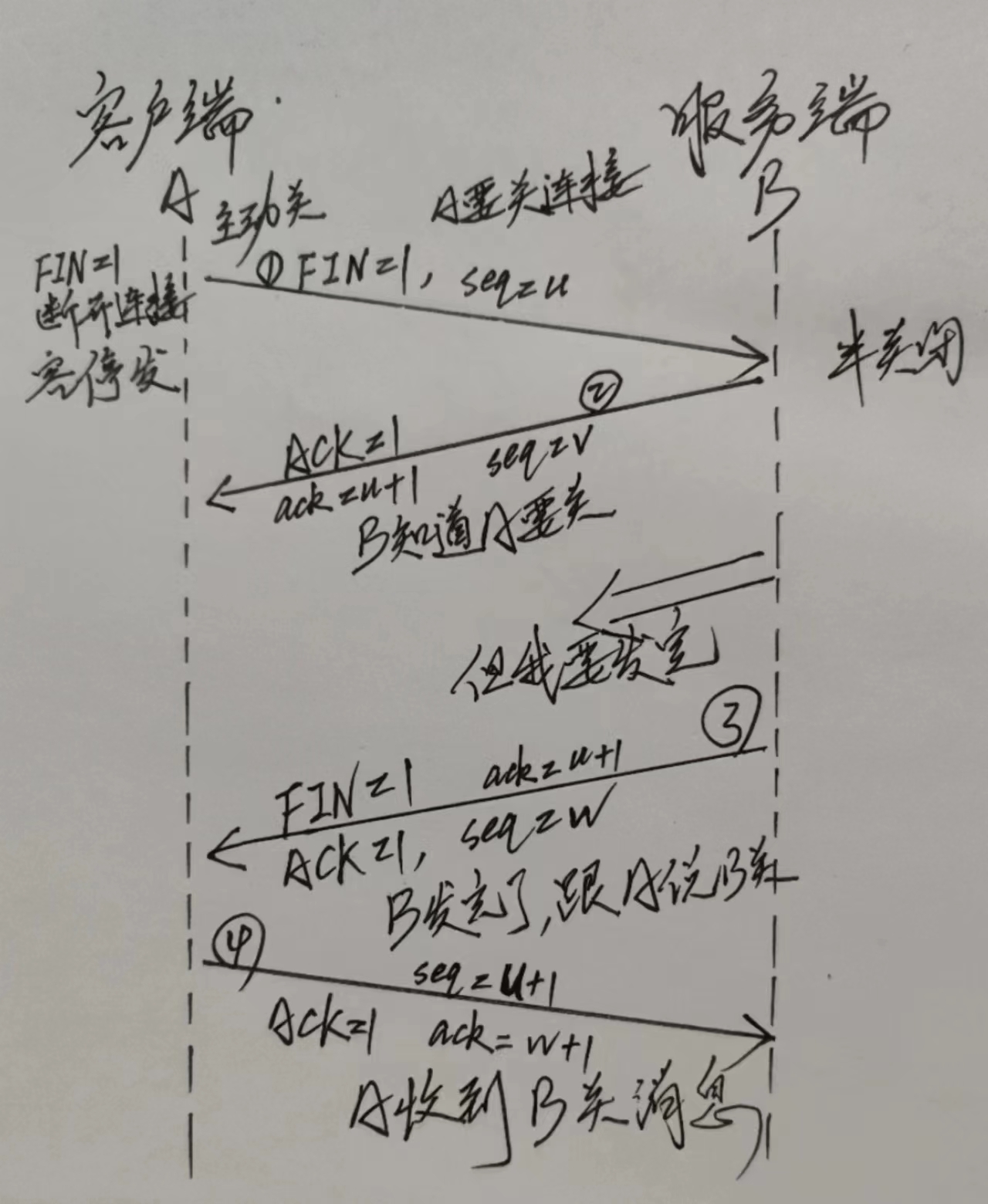
下面我来说说我们遇到的问题:还的用一个图来进行描述
在说此事之前需要注明---此文不针对任何一个云,同时此文仅仅是在技术上和实例上的讨论,云上是否可以做到无主从切换后带来的数据损失,实际上是可以的,但成本太高,大部分应用是无法承受相关的成本。
我们发生问题的整体过程这里描述一下,MYSQL RDS 一台,在凌晨进行数据的删除,因为开发处理的语句粗糙,并未进行事务大小的评估,导致产生了一个大事务,大事务中,产生了大量的BINLOG ,BINLOG 将整体的磁盘空间挤满,数据库没有磁盘空间在去写数据,数据库HANG住,此时高可用程序对数据库开始判断是否工作,发现无法登陆和操作数据库,或判断数据库无法正常提供服务的情况下,开始计时 600秒,数据库一直HANG住,主从产生切换。
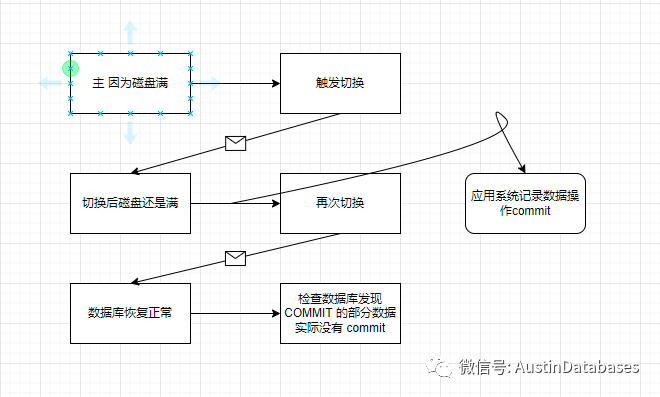
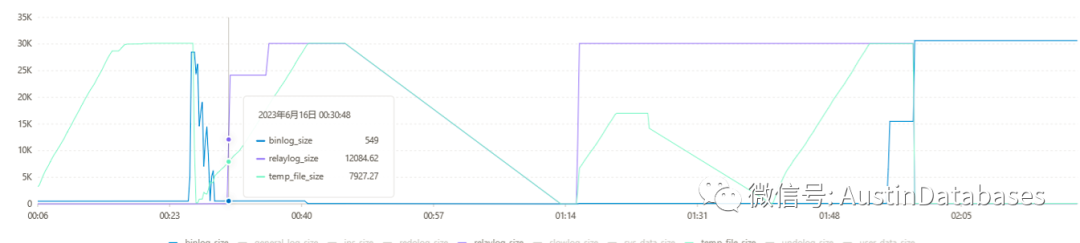
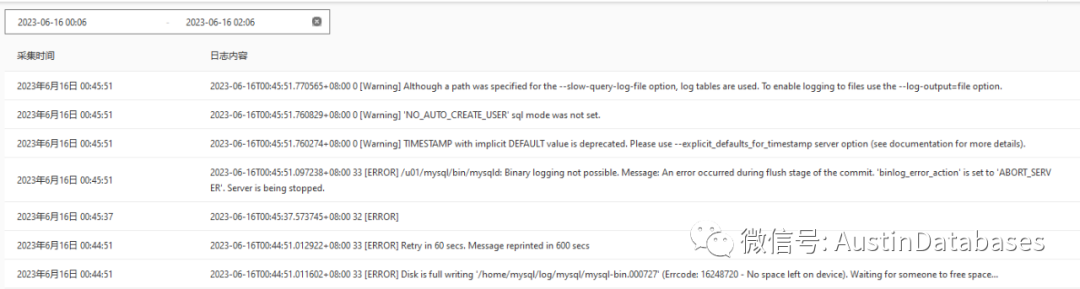
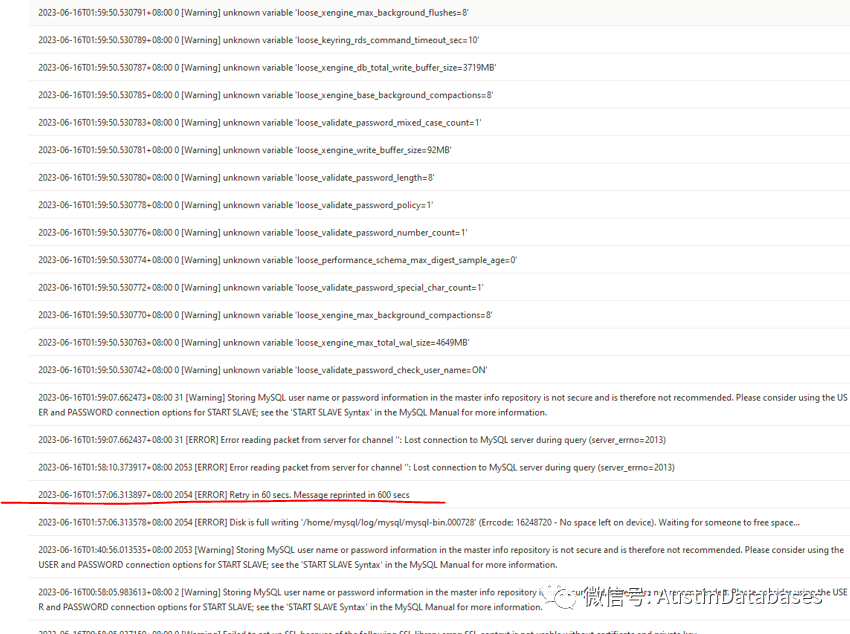
实际上这个问题很容易解释清楚
1 从上图中的 RELAY LOG BINLOG 等日志的在切换前和切换后的容量的大小上可以进行判断。
2 在切换时,需要做出牺牲,是等着BINLOG 都传输完毕,还是让系统尽快进行恢复,需要系统做出一个选择
3 切换过程中,如果原主库就是无法唤起,那么从库必然在缺少数据的情况下,成为主库,所以数据COMMIT 但未在从库应用,从库又缺少BINLOG,所以导致在应用端有COMMIT 成功的反馈,但是数据没有。
所以云数据库不是万能的良药,云数据库只是将一些高概率发生的问题在云端进行解决,但是解决的方式粗狂,并且成本高,不是针对任何企业都能接受这个事情,这才有了金融级的数据库产品,金融级别的产品在这个方面,原则上是 100%不能发生数据丢失的问题。
另外在云端除了 MYSQL RDS 产品可能会在突发情况下丢数据,PG 会不会,PG 可以不会丢数据,因为PG 有强制数据同步到从库后ACK ,但是你可以去看看主流云在 PG 方面的设定,有没有使用这个部分,使用了你的性能会降低多少。所以在不使用这个部分,PG 高可用在云上丢数据那是太正常了
我们在某云上做的相关测试,如果我们开启这个参数,在某云的性能直接 CUT OFF 50% ,对没有错误,性能损失 50%。
而MOGNODB 在某云也有问题,按照MONGODB 的本身设定,这个数据库算是数据库里面高可用做的最好的,没有一直,他就是这个LEVEL 里面的高可用做的最好,最妙,最无法丢数据的存在,但是在某云由于成本的原因,也造成这个产品,有可能在特殊的情况下,丢数据或导致业务DOWN机,虽然这个概率触发的可能性不大,但是也要看实际的情况,这里就不细说了,以免 某云 变成一个 标定的名词。
最后重申,不要在问这是哪个云,我可以负责的说,如果这云不行,那么基本上你哪个云都没戏,只是你没发现而已。同时不要责怪云上的技术人员,他们没有错误,错误的是云的成本要求和一些云上在硬件上的,和架构上的对他们的限制,云上也有金融级的数据库,不过你看完价格你在想想。
最后,如何进来避免云上丢数据
1 控制好你的事务大小,开发人员使用云数据库的肆无忌惮,导致在云上发生大事务的可能性更高,尤其在某些不负责的人士下的,互吹乱捧下。
2 在云上的数据库本身不要太大,很多云上的MYSQL 数据库在 1T 以上,POSTGRESQL 在 3T 以上 等等,这让云进行切换或者进行数据恢复的时候,困难度很大,因为云不是一个万能的避风港,你在线下的问题,不会上云后消失,只不过,多了一个背锅侠,并且这个背锅侠还是不负责的。具体原因和信息 参见 云SLA是不是安慰剂 ?这篇文章
3 对于云上的空间管理,不要算计的太厉害,有一定的RDS 产品的冗余空间在一些大事务滥用或者 BINLOG WAL OPLOG 猛增的时候能抗一下,避免因为磁盘空间导致的切换。