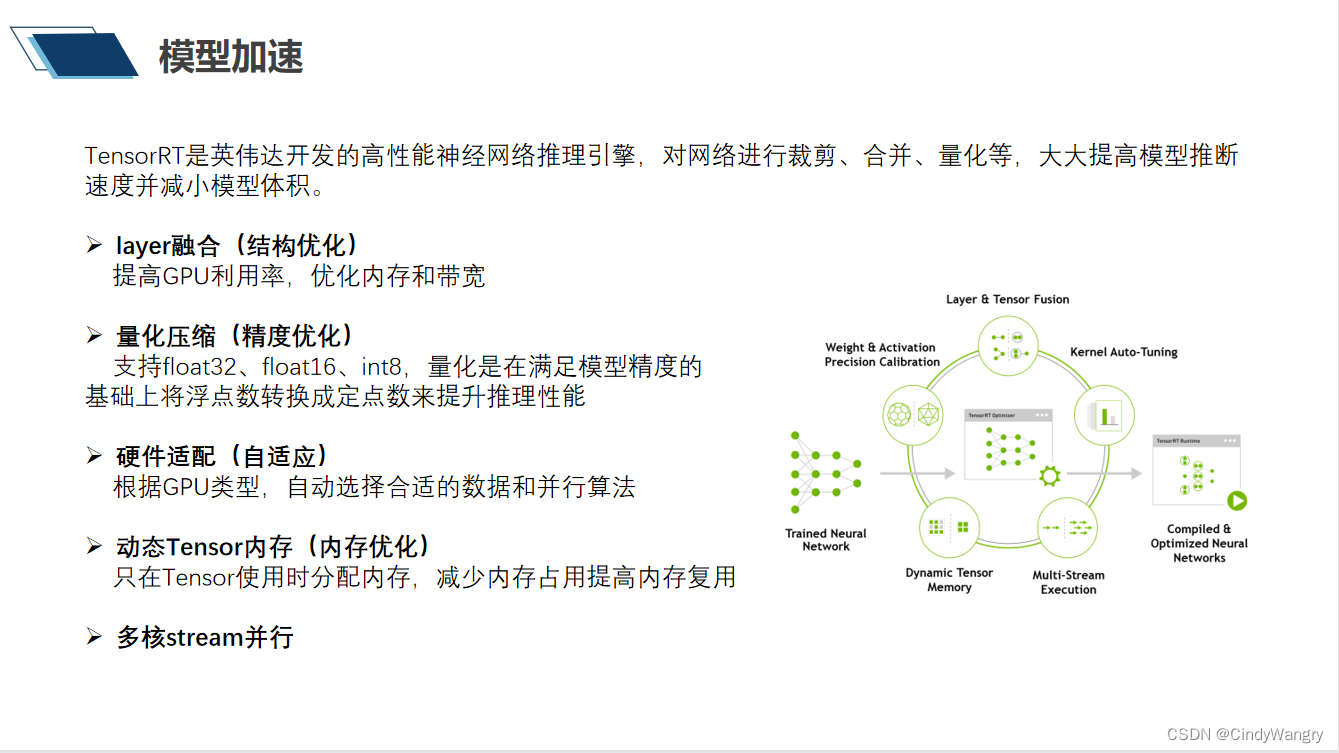
讲解: 模型经过训练之后终端部署之前都会有一个模型转换的过程,英伟达也不例外, 模型转换的过程其实是一个模型优化与加速的过程,里面包含着引擎对模型的一系列操作, 比如说layer 级的融合,权重的量化、图层的切割,子图硬件层面的自适应、内存的分配等等

讲解: 这里说的就是layer级的融合,左边是训练出来的模型,右边是将卷积、偏置、激活层进行了一个融合之后的模型, 对比一下少了三分之二的layer,这样的做的目的是为了实现推理时减少内存的来回拷贝,提高线程数学计算量
 讲解: 这里罗列了模型量化的一些方法,每个计算平台都大同小异,绿色是NV平台支持的
讲解: 这里罗列了模型量化的一些方法,每个计算平台都大同小异,绿色是NV平台支持的

讲解: NV 平台量化原理:首先将模型量化成定点数(指定位数的数,包括整型和浮点型)去做模型推理, 以节省数据计算量,之后将推理结果反量化为浮点型数据得到推理结果。浮点数=量化缩放scale 因子 *量化定点数, 量化的过程就是得到一个最优的scale(实数和整数的对应关系)和zero point (表示实数中的0经过量化后的对应整数)去取代浮点数, 这个任务就落到了怎么去选最优的量化阈,量化阈就是上面说的阈值 当S取大时,可以扩大量化域,但同时,单个INT8数值可表示的FP32范围也变广了,因此INT8数值与FP32数值的误差(量化误差)会增大; 而当S取小时,量化误差虽然减小了,但是量化域也缩小了,被舍弃的参数会增多。
讲解: 阈值选择原理,基于相对熵,来衡量消除两个概率分部之间的差异所需要付出的努力值的大小
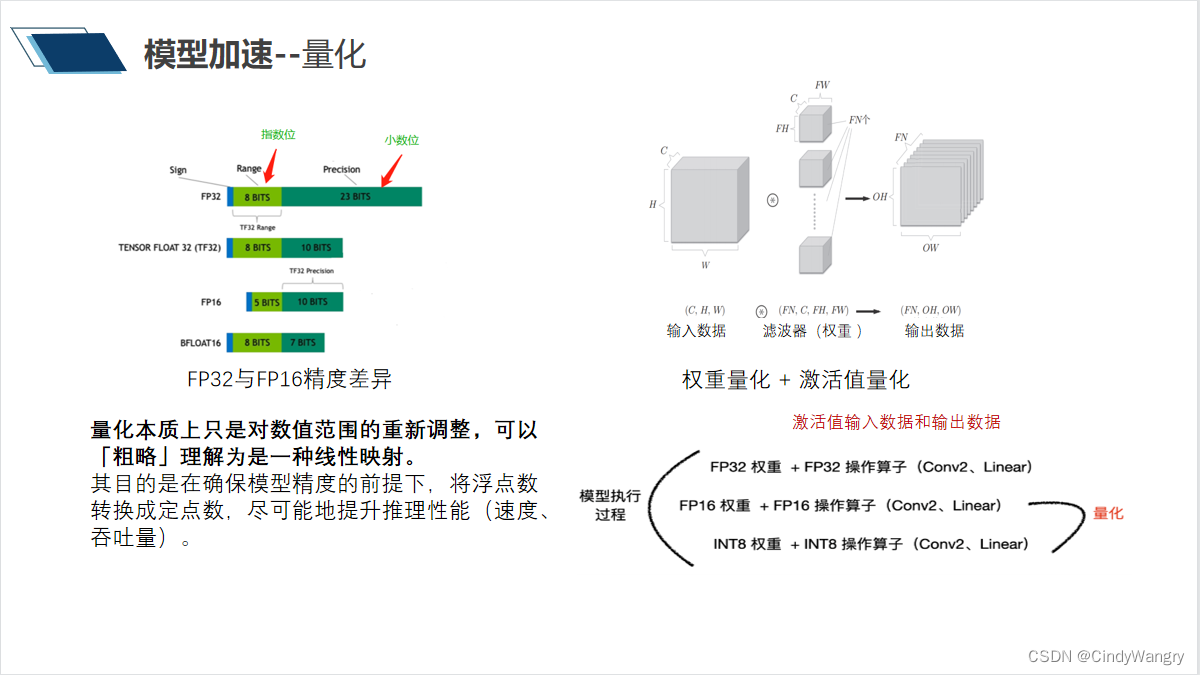
讲解: 量化的本质,激活值与权重量化 权重量化: 即仅仅需要对网络中的权重执行量化操作。由于网络的权重一般都保存下来了,因而我们可以提前根据权重获得相应的量化参数S和Z,而不需要额外的校准数据集。 一般来说,推理过程中,权重值的数量远小于激活值,仅仅对权重执行量化的方法能带来的压缩力度和加速效果都一般。 权重激活量化,即不仅对网络中的权重进行量化,还对激活值进行量化。 由于激活层的范围通常不容易提前获得,因而需要在网络推理的过程中进行计算或者根据模型进行大致的预测。 激活值的量化: 分在线和离线 在线量化,即指激活值的S和Z在实际推断过程中根据实际的激活值动态计算; 离线量化,即指提前确定好激活值的S和Z,需要小批量的一些校准数据集支持。 由于不需要动态计算量化参数,通常离线量化的推断速度更快些。

讲解: 如果模型量化之后是int8 模型校准,为甚么? 为什么对于不同模型都可行?如果有些模型缩小量化域导致的精度下降更明显,那INT8量化后的精度是不是必然有大幅下降了呢? 量化属于浮点数向定点数转换的过程,由于浮点数的可表示数值间隙密度不同, 导致零点附近的浮点数可表示数值很多,大约2^31个,约等于可表示数值量的一半。 因此,越是靠近零点的浮点数表示越准确,越是远离原点的位置越有可能是噪声, 并且网络的权重和激活大多分布在零点附近,因此适当的缩小量化域能提升量化精度几乎是必然的。

讲解: 模型加速优化的过程:优先PTQ 不满足精度之后再QAT
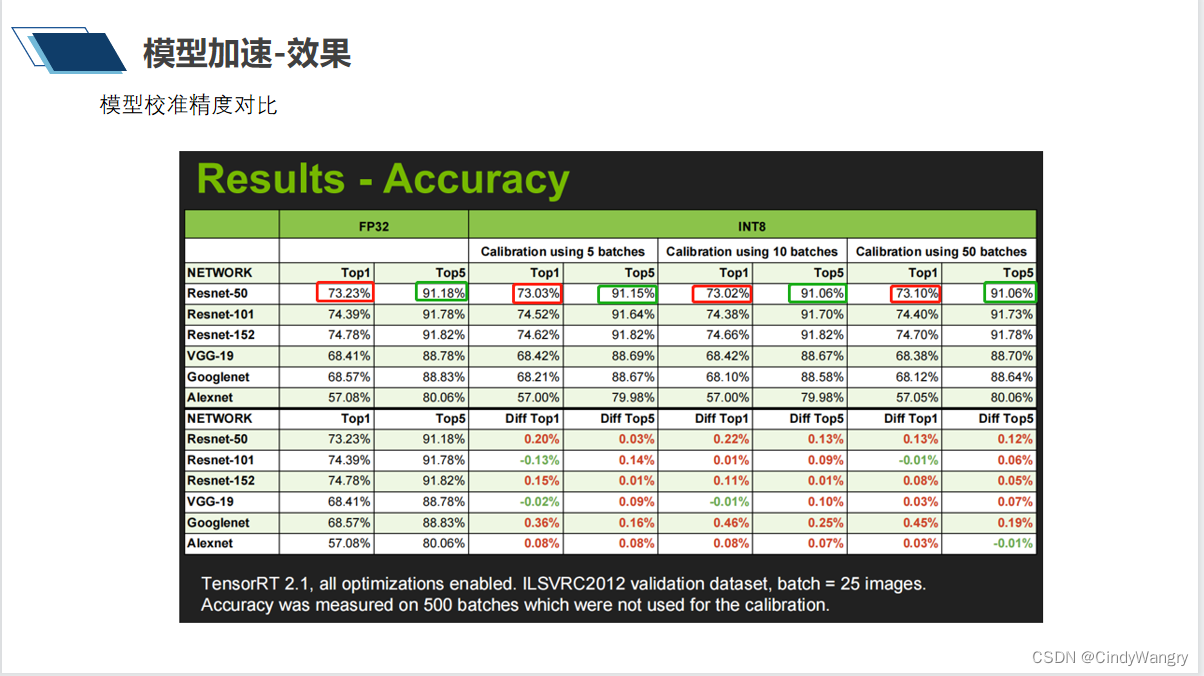
讲解: 模型校准精度对比:int8 与FP32,精度下降不会高于0.5%,推理速度以yolov5为例,推理时间下降为fp32 时的1/4左右
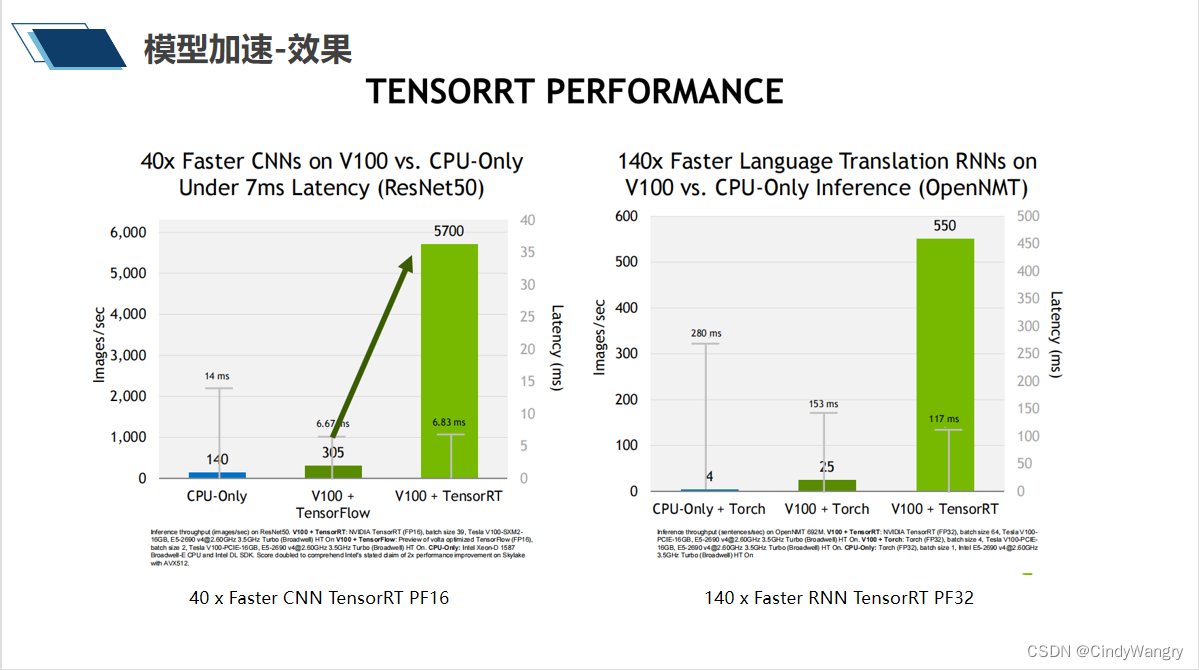
讲解: cpu-only 与trt 模型吞吐量与延时对比

讲解:pytorch自定义算子的流程,继承torch.autograd.Function,重写forward和backward 方法,定义symbolic()来导出onnx
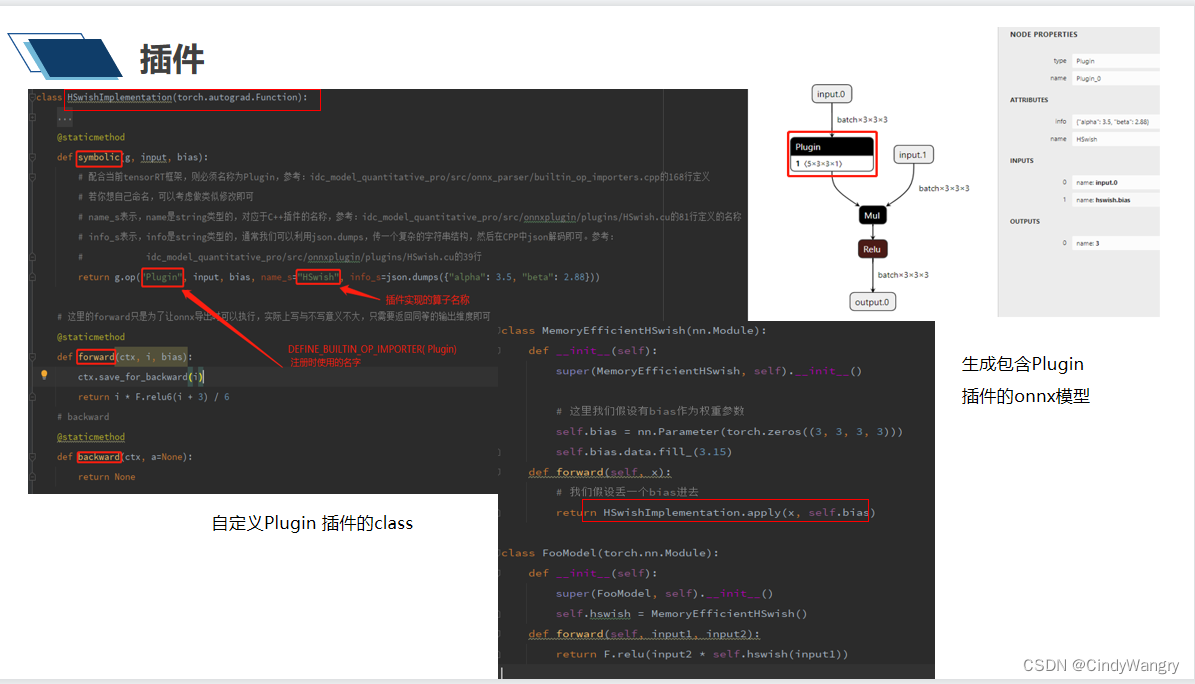
讲解: pytorch 端自定义算子的举例,这里自定义了一个名字为Plugin 的节点,该节点实现的算子名称为HSwish
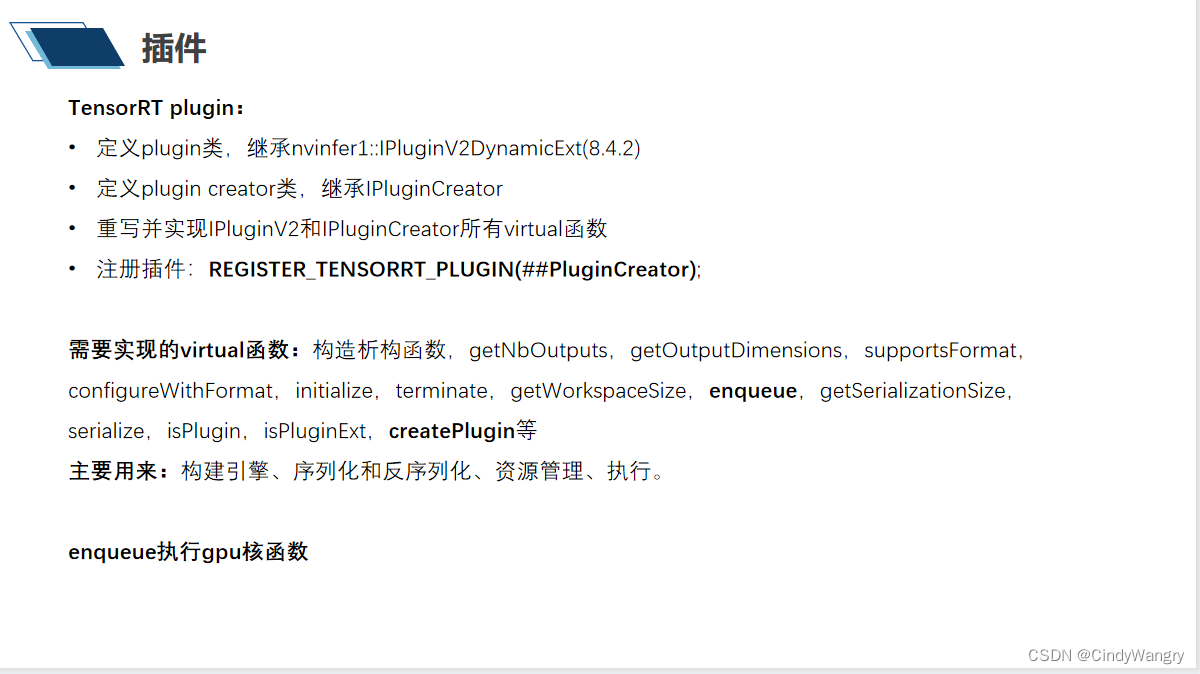
讲解: tensorRT 自定义算子流程,
1、重写creator 和nvinfer1::IPluginV2DynamicExt 类,实现类中的虚机函数
2、实现enqueue 中GPU 的核函数
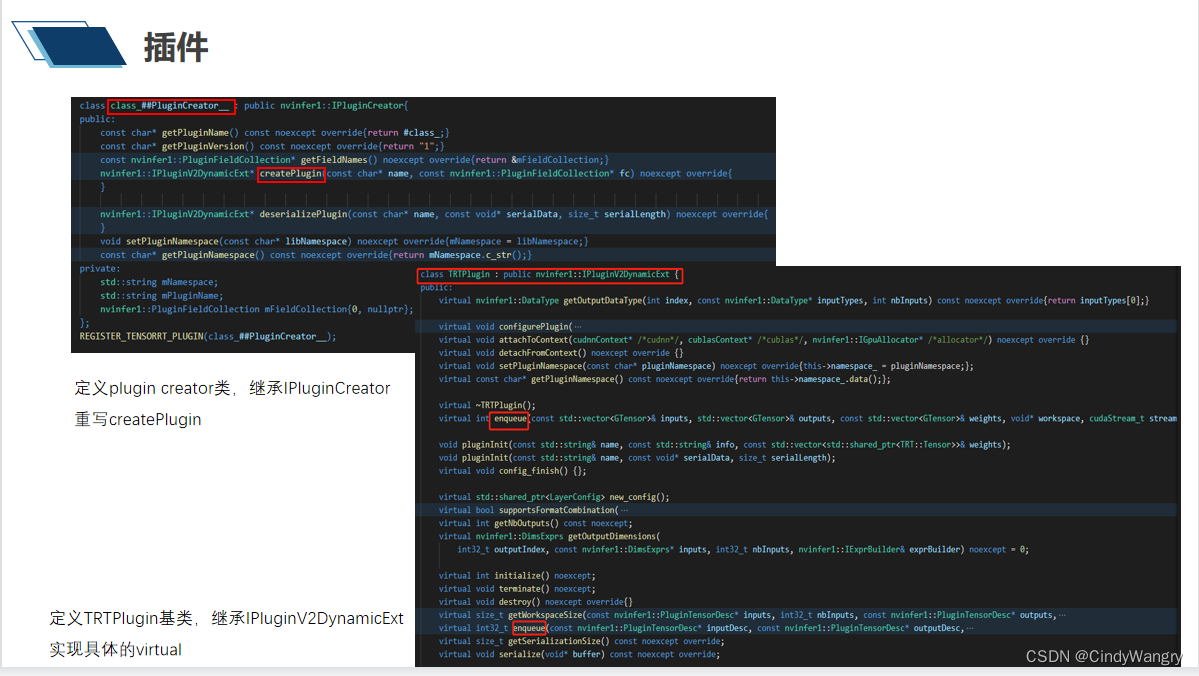
讲解: tensorRT 自定义插件类的实现具体op的creator 和 Plugin 类

讲解: 添加onnx parser支持新增Plugin 支持 引入开源项目 onnx-tensorRT ONNX https://github.com/onnx/onnx-tensorrt 修改 onnx-parser 部分,在builtin_op_importers.cpp 部分新增名字为Plugin 的onnx 节点,在onnx模型转trt中该节点才会得以通过
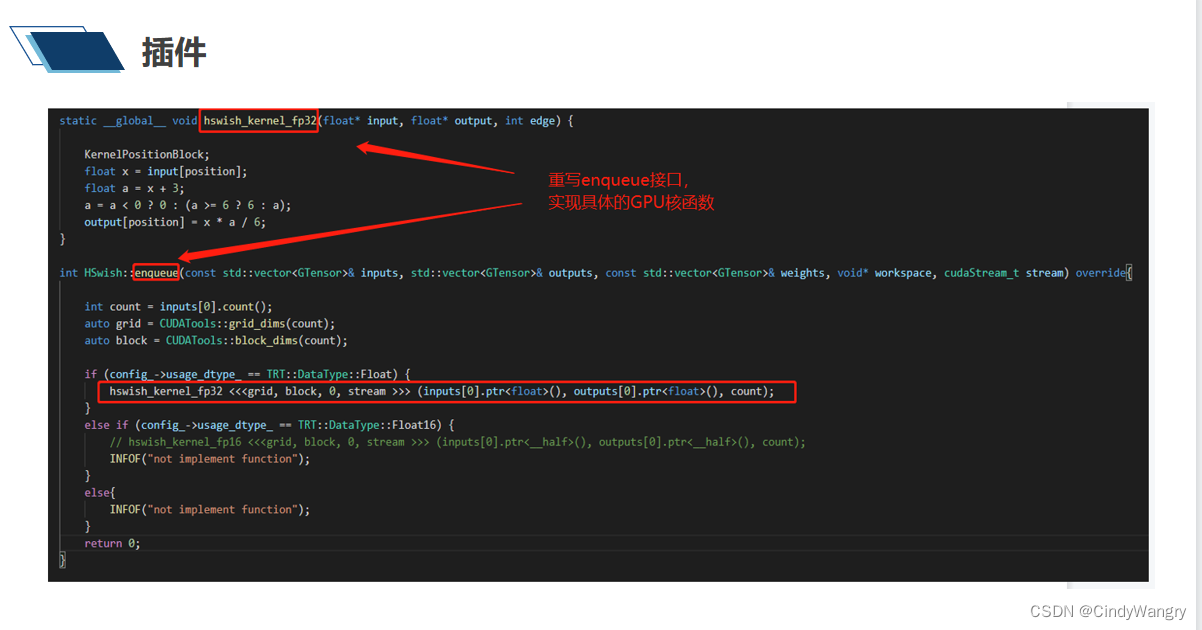
讲解: 实现具体的kernel 在enqueue 中调用
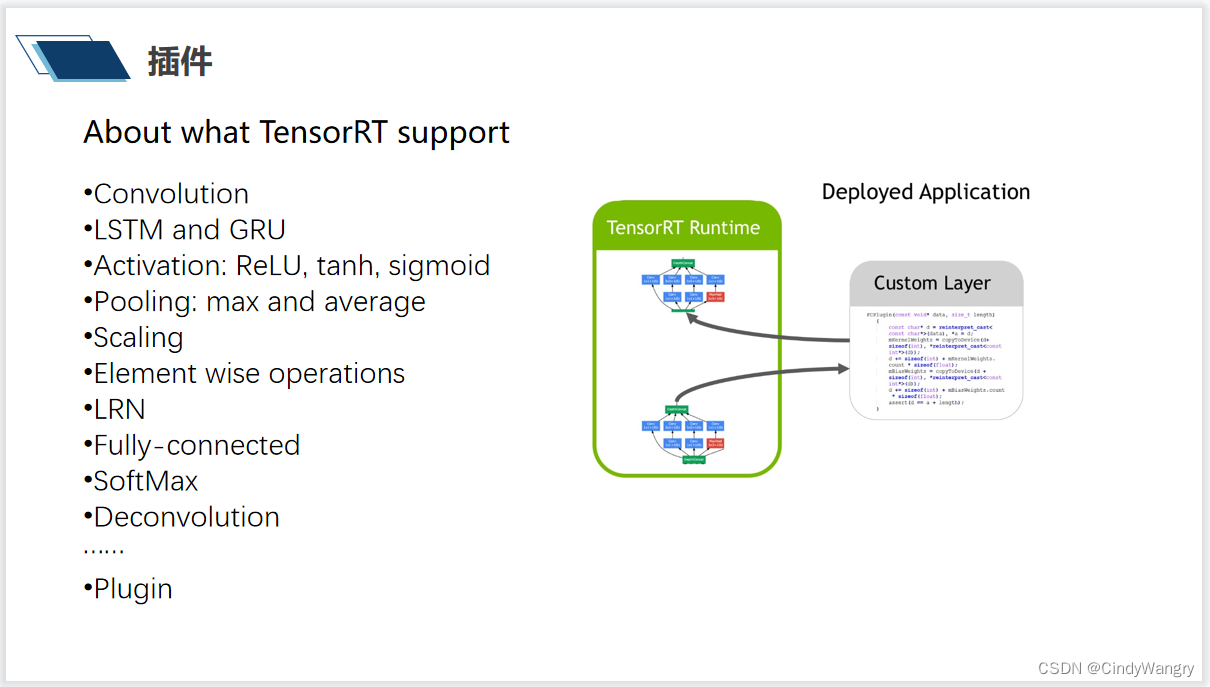
讲解: tensorRT 支持的算子轮子,在不断更新中
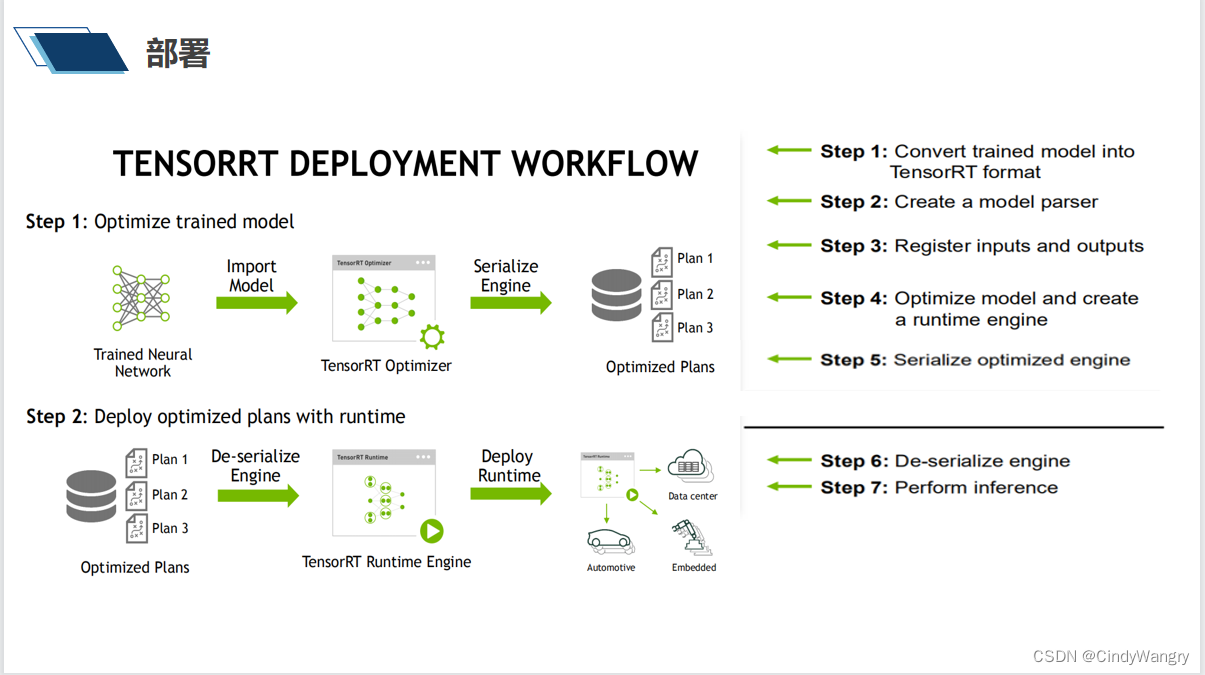 讲解: 模型部署的流程
讲解: 模型部署的流程
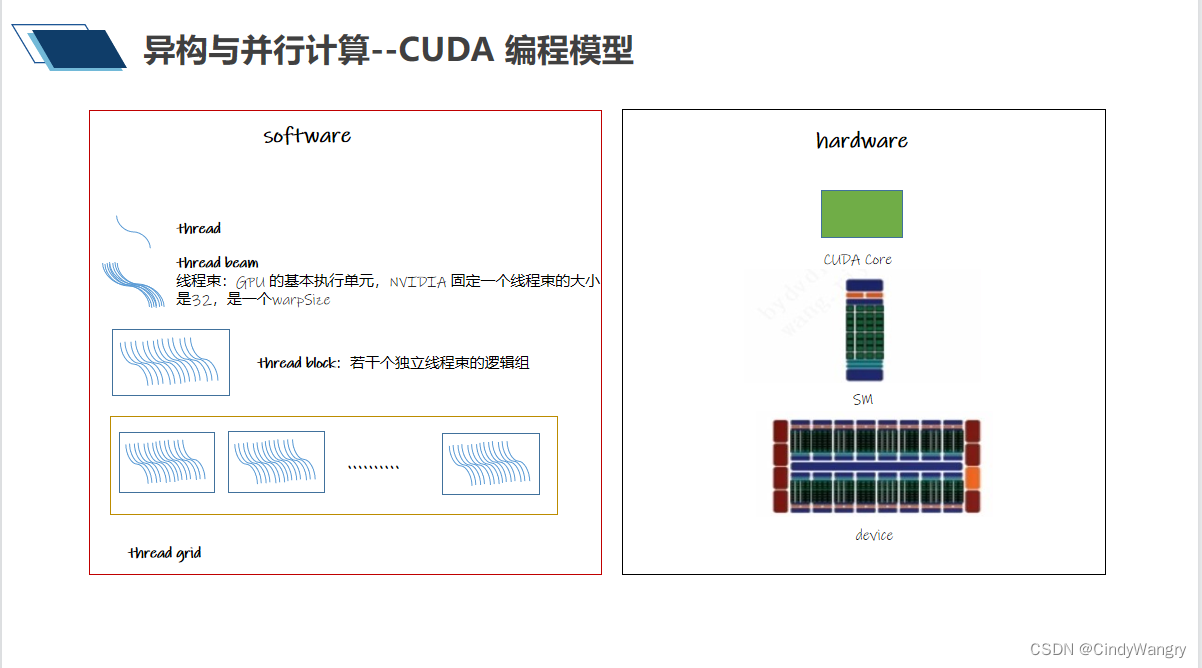
讲解:CUDA编程模型 ,一些术语线程、线程束、 线程块 、网格、SM
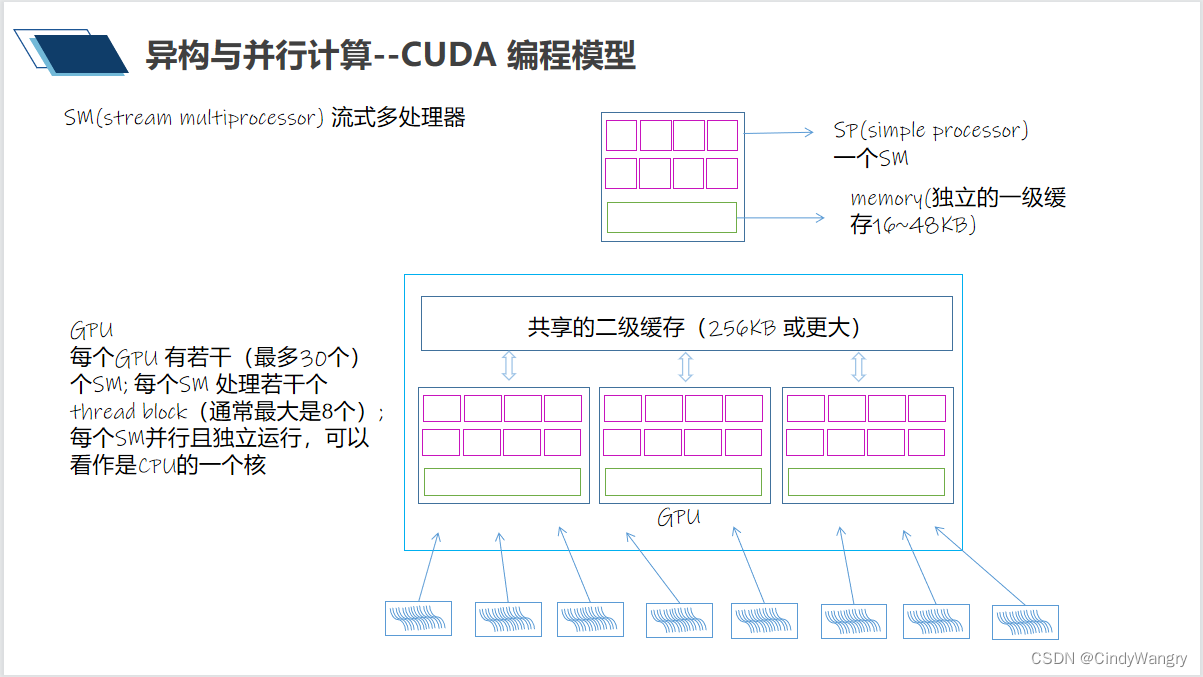
讲解:流式多处理器SM 一个SM 相当于CPU的一核 线程(块)在SM中执行,每个SM 的执行相互独立,他们共享着二级缓存
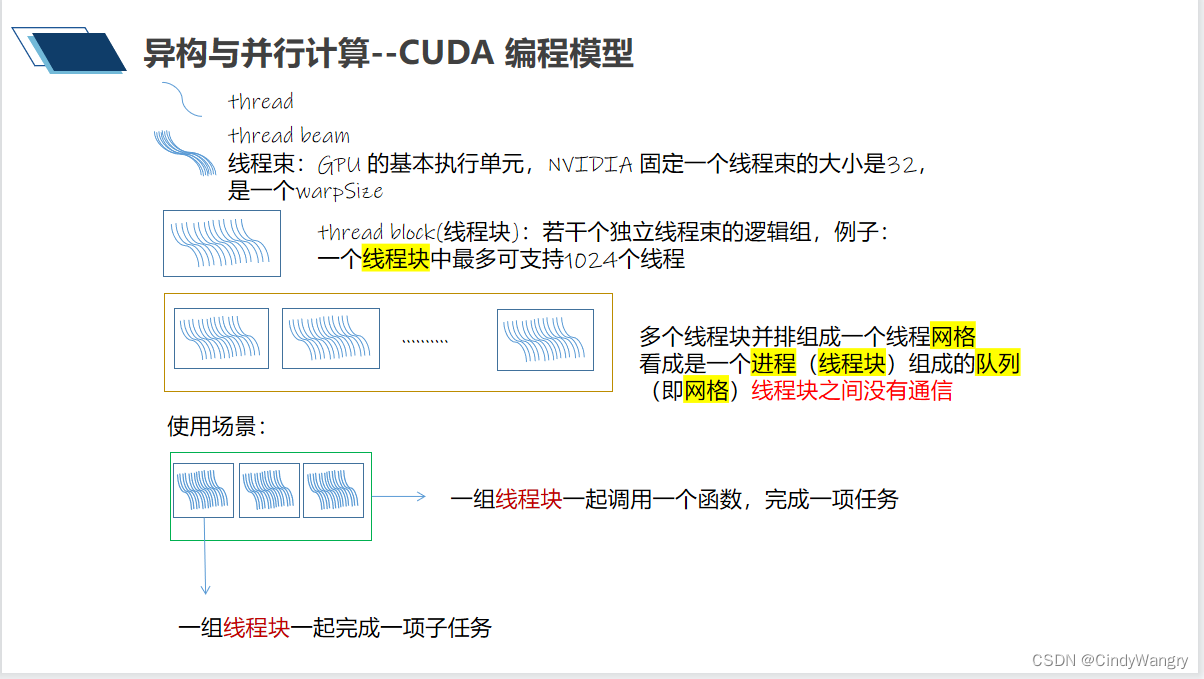
讲解: 通常GPU 执行的最小线程基本单元为线程束,若干个线程束构成线程块, 多个线程块在一起组成了线程网格,可能的应用场景为多个线程块一起完成一项任务,比如执行某个CUDA 核
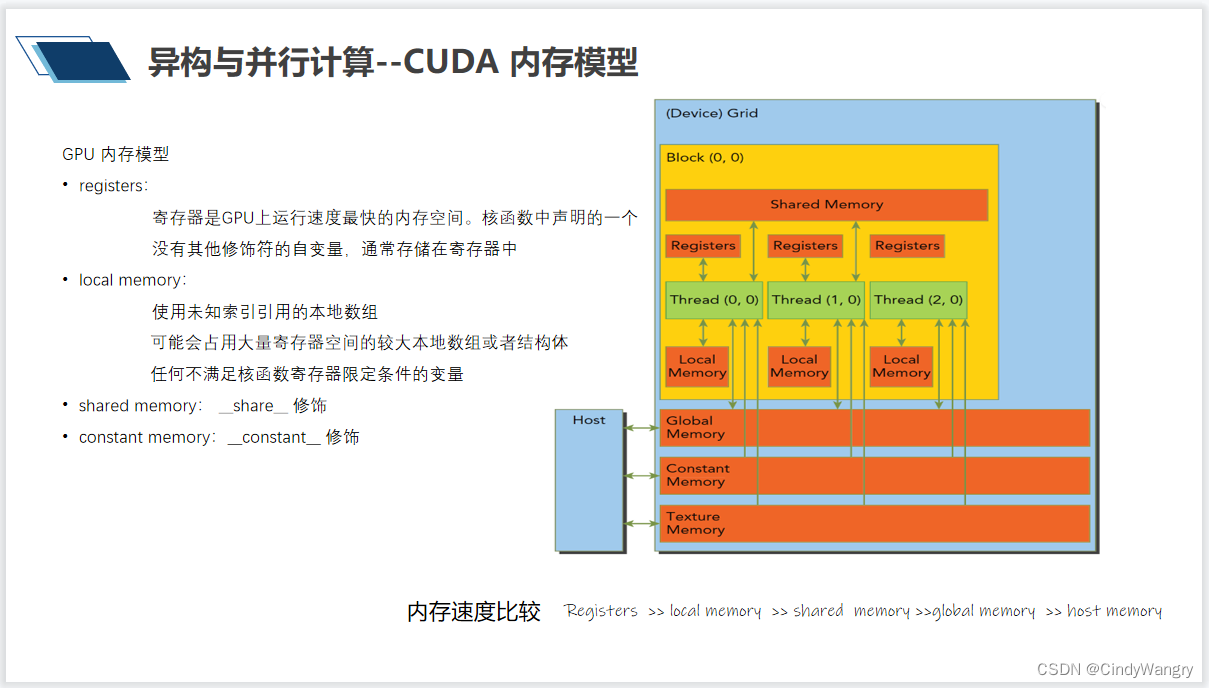
讲解:GPU 内存模型 __global__ :修饰函数,可以从主机上调用并在设备上运行。 __device__ :表示以设备函数的形式编写,设备函数即只能被GPU内核调用的函数,只能从其他__device__函数或者从___global___函数中调用它们。相当于c语言函数声明之前添加一个static 或C++中的private __share__ :将该关键字添加到变量声明中,这将使这个变量驻留在共享内存中。 __constant__: 常量内存、声明一块常量内存 __syncthreads() : 线程同步
 讲解: 内存申请与拷贝, 由host 来主导
讲解: 内存申请与拷贝, 由host 来主导
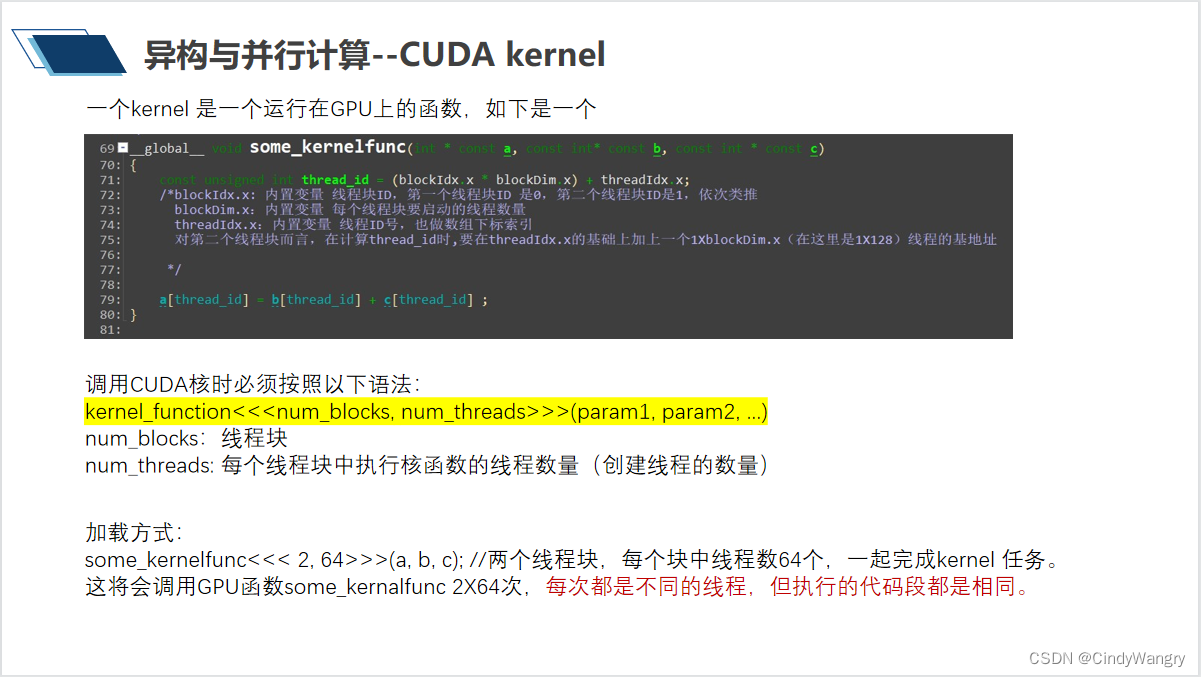
讲解:CUDA 核的加载方式

讲解:GPU线程索引,可123D

yolo_pose decode 后处理并行计算举例分析
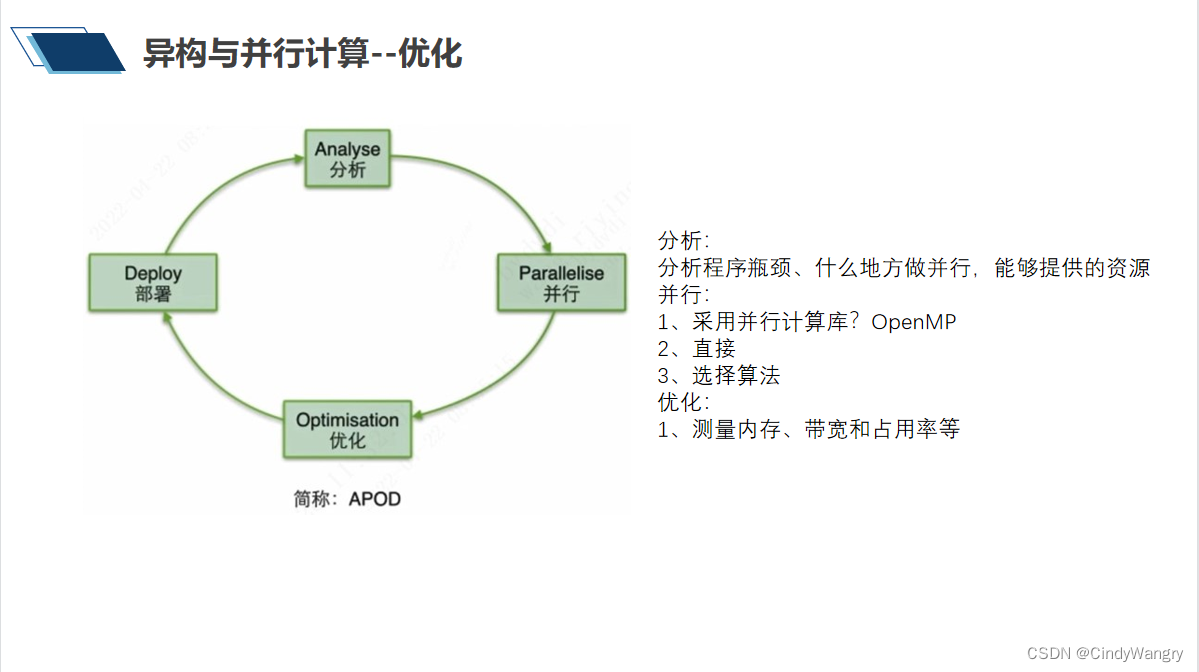
 优化原则、等级 1、选择好的算法(运输复杂度、是否适合并行化) 2、代码层面的优化,充分利用缓存 3、指令集的优化
优化原则、等级 1、选择好的算法(运输复杂度、是否适合并行化) 2、代码层面的优化,充分利用缓存 3、指令集的优化