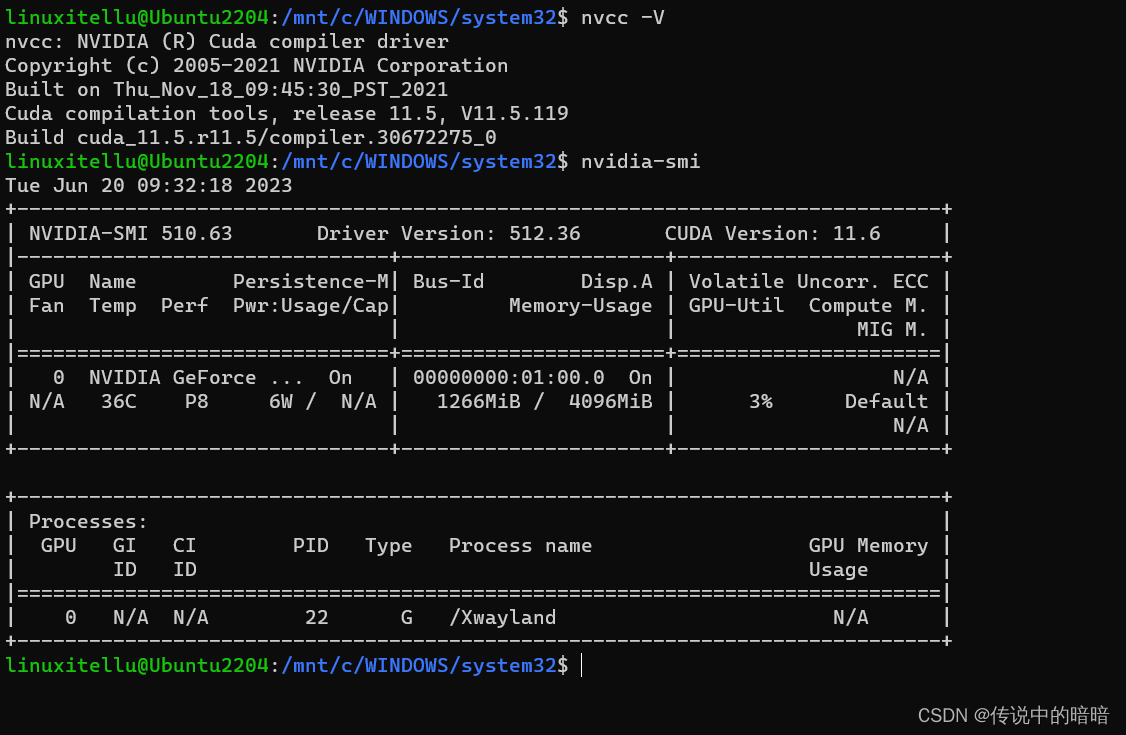
注1:本文系“简要介绍”系列之一,仅从概念上对CUDA的底层原理进行非常简要的介绍,不适合用于深入和详细的了解。
CUDA底层原理:加速高性能计算的关键技术
CUDA Refresher: The GPU Computing Ecosystem | NVIDIA Technical Blog
1 背景介绍
CUDA (Compute Unified Device Architecture) 是由英伟达(NVIDIA)开发的一种并行计算平台和编程模型,可充分利用图形处理器(GPU)的强大计算能力,从而实现高性能计算。CUDA为各种科学研究和高性能计算任务提供了一个通用平台,使得程序员可以有效地利用GPU资源,显著提高程序的执行速度。
2 原理介绍和推导
2.1 CUDA架构概述
CUDA的核心概念是 并行计算能力 。在CUDA架构中,程序被分解成许多小的任务,这些任务可以在GPU的多个处理单元上同时执行。这使得程序能够更快地完成复杂计算任务,如图形渲染、物理模拟和机器学习。CUDA架构将GPU的处理器核心组织成一个层次结构,包括线程、线程块、网格和流多处理器。下图展示了CUDA架构的层次结构:

Introduction to CUDA Programming - GeeksforGeeks
2.2 线程、线程块和网格
线程 是CUDA计算的基本单位。一个线程负责执行一个任务,而一个任务可能是一个简单的计算操作或一个复杂数学运算。线程通过CUDA内核函数(即在GPU上执行的函数)进行创建。线程被逻辑地组织成 线程块 ,线程块中的线程可以协同工作,共享数据和同步执行。线程块进一步组织成 网格 ,网格是线程块的集合,可并行处理更大的问题。
2.3 内存管理
CUDA提供了多种内存类型,以实现不同级别的数据共享和存储。这些内存类型包括 全局内存、共享内存、局部内存和常量内存 。全局内存可供所有线程访问,但访问速度较慢;共享内存可供线程块内的线程访问,访问速度较快,但容量有限;局部内存为每个线程提供私有存储空间;常量内存为所有线程提供只读存储空间,用于存储不变的数据。
3 研究现状
CUDA技术已经在许多高性能计算领域取得了重要的突破,如科学模拟、数据分析和机器学习。许多开源库和框架,如 TensorFlow 和 PyTorch ,已经采用CUDA加速计算,从而显著提高了这些库和框架在处理复杂任务时的性能。

Beyond3D - Tesla 10 & CUDA 2.0: Real-World Applications & Financials
4 挑战
尽管CUDA技术在高性能计算领域取得了显著的成功,但仍然存在一些挑战,如:
- 编程复杂性:CUDA编程模型相对复杂,需要程序员具备并行编程和GPU架构的深入理解。
- 硬件限制:CUDA技术仅支持NVIDIA GPU,这限制了其在非NVIDIA硬件上的普及。
- 优化困难:在CUDA程序中实现高效的内存访问和并行计算需要对GPU架构进行深入优化,这对于许多开发者来说可能是一项具有挑战性的任务。
5 未来展望
尽管存在挑战,CUDA技术在高性能计算领域仍具有巨大的潜力。未来的研究和开发可能会关注以下几个方向:
- 更高级别的抽象:为了降低CUDA编程的复杂性,未来可能会出现更多高级别的抽象,使程序员能够更容易地利用GPU的计算能力。
- 跨平台兼容性:为了克服硬件限制,未来可能会出现更多跨平台的并行计算框架,以支持不同厂商的GPU。
- 自动优化:通过自动优化技术,未来的CUDA编译器和运行时系统可能会更智能地优化程序的执行,从而降低开发者的优化负担。
6 代码示例
以下是一个使用 Python 和 PyCUDA 库编写的简单CUDA程序示例,用于计算两个向量的点积:
import numpy as np
import pycuda.autoinit
import pycuda.driver as drv
from pycuda.compiler import SourceModule
mod = SourceModule("""
__global__ void dot_product(float *a, float *b, float *result) {
int idx = threadIdx.x + blockDim.x * blockIdx.x;
result[idx] = a[idx] * b[idx];
}
""")
dot_product = mod.get_function("dot_product")
N = 1024
a = np.random.randn(N).astype(np.float32)
b = np.random.randn(N).astype(np.float32)
result = np.empty_like(a)
block_size = 256
grid_size = N // block_size
dot_product(drv.In(a), drv.In(b), drv.Out(result), block=(block_size,1,1), grid=(grid_size,1))
print("Dot product:", np.sum(result))
这个示例展示了如何在Python中编写CUDA内核函数、编译和执行该函数,以及如何处理GPU内存和数据传输。