github开源代码地址:
https://github.com/meiqua/shape_based_matching
针对匹配精度问题,原作者采用了sub-pixel + icp的方法进行了最后的finetune,涉及到的相关原理可以查看:亚像素边缘提取与ICP2D的理解 - 知乎
涉及到的论文:
[1] Carsten Steger:Unbiased extraction of curvilinear structures from 2D and 3D images.
[2] Linear Least-Squares Optimization for Point-to-Plane ICP Surface Registration
https://download.csdn.net/download/lipeng19930407/87932688
简单记录一下查看代码过程中存在疑惑的点:
1、linemod论文中,梯度扩散是以当前像素为中心点,从r范围的邻域进行梯度扩散。
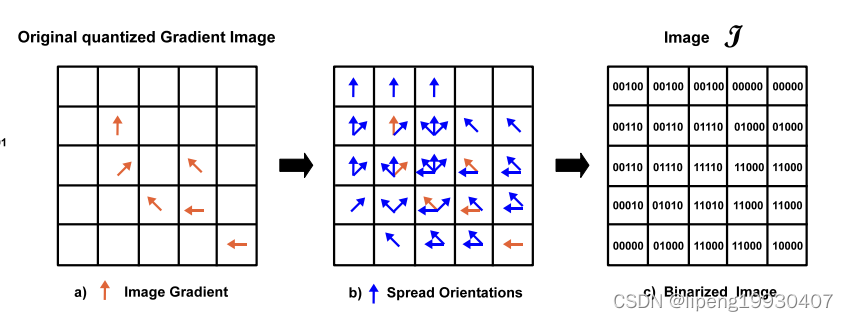
而代码中的实现:
/**
* \brief Spread binary labels in a quantized image.
*
* Implements section 2.3 "Spreading the Orientations."
*
* \param[in] src The source 8-bit quantized image.
* \param[out] dst Destination 8-bit spread image.
* \param T Sampling step. Spread labels T/2 pixels in each direction.
*/
static void spread(const Mat& src, Mat& dst, int T)
{
// Allocate and zero-initialize spread (OR'ed) image
dst = Mat::zeros(src.size(), CV_8U);
// Fill in spread gradient image (section 2.3)
for (int r = 0; r < T; ++r)
{
int height = src.rows - r;
for (int c = 0; c < T; ++c)
{
orUnaligned8u(&src.at<unsigned char>(r, c), static_cast<int>(src.step1()), dst.ptr(),
static_cast<int>(dst.step1()), src.cols - c, height);
}
}
}
此处的实现,目标点位将其右下[0,T]范围内的梯度都进行了或操作,即某梯度只向其左上方T大小的范围内进行了扩散,与下文中的T间隔采样暗合,
 类似于粗略匹配,且针对噪音或微小形变具备较好的鲁棒性,但因此匹配精度上有所欠缺,才有了后续的icp+subpixel finetune。
类似于粗略匹配,且针对噪音或微小形变具备较好的鲁棒性,但因此匹配精度上有所欠缺,才有了后续的icp+subpixel finetune。
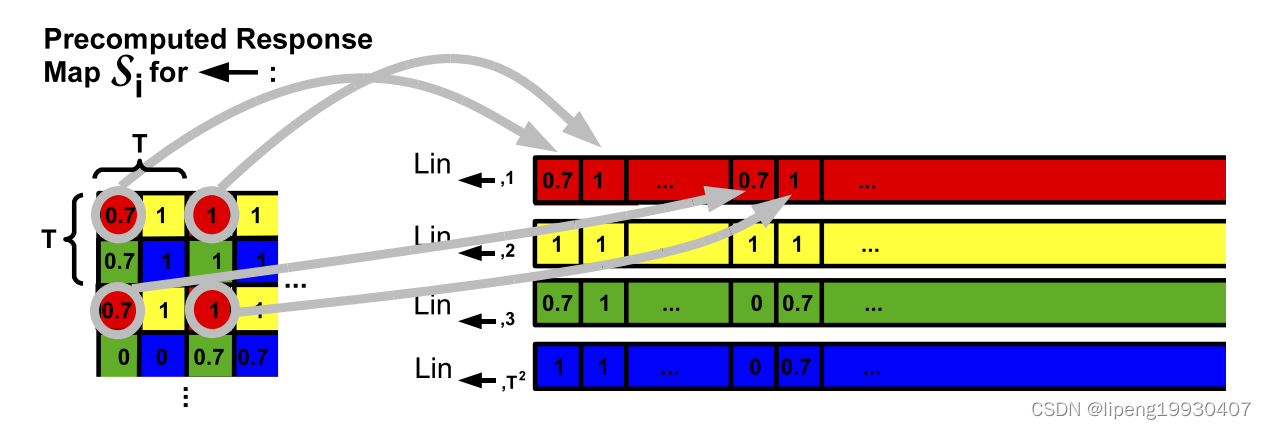
2、similarity计算的位置点数
代码如下:
/**
* \brief Compute similarity measure for a given template at each sampled image location.
*
* Uses linear memories to compute the similarity measure as described in Fig. 7.
*
* \param[in] linear_memories Vector of 8 linear memories, one for each label.
* \param[in] templ Template to match against.
* \param[out] dst Destination 8-bit similarity image of size (W/T, H/T).
* \param size Size (W, H) of the original input image.
* \param T Sampling step.
*/
static void similarity(const std::vector<Mat>& linear_memories, const Template& templ,
Mat& dst, Size size, int T)
{
// 63 features or less is a special case because the max similarity per-feature is 4.
// 255/4 = 63, so up to that many we can add up similarities in 8 bits without worrying
// about overflow. Therefore here we use _mm_add_epi8 as the workhorse, whereas a more
// general function would use _mm_add_epi16.
CV_Assert(templ.features.size() <= 63);
/// @todo Handle more than 255/MAX_RESPONSE features!!
// Decimate input image size by factor of T
int W = size.width / T;
int H = size.height / T;
// Feature dimensions, decimated by factor T and rounded up
int wf = (templ.width - 1) / T + 1;
int hf = (templ.height - 1) / T + 1;
// Span is the range over which we can shift the template around the input image
int span_x = W - wf;
int span_y = H - hf;
// Compute number of contiguous (in memory) pixels to check when sliding feature over
// image. This allows template to wrap around left/right border incorrectly, so any
// wrapped template matches must be filtered out!
int template_positions = span_y * W + span_x + 1; // why add 1?
//int template_positions = (span_y - 1) * W + span_x; // More correct?
/// @todo In old code, dst is buffer of size m_U. Could make it something like
/// (span_x)x(span_y) instead?
dst = Mat::zeros(H, W, CV_8U);
uchar* dst_ptr = dst.ptr<uchar>();
#if CV_SSE2
volatile bool haveSSE2 = checkHardwareSupport(CV_CPU_SSE2);
#if CV_SSE3
volatile bool haveSSE3 = checkHardwareSupport(CV_CPU_SSE3);
#endif
#endif
// Compute the similarity measure for this template by accumulating the contribution of
// each feature
for (int i = 0; i < (int)templ.features.size(); ++i)
{
// Add the linear memory at the appropriate offset computed from the location of
// the feature in the template
Feature f = templ.features[i];
// Discard feature if out of bounds
/// @todo Shouldn't actually see x or y < 0 here?
if (f.x < 0 || f.x >= size.width || f.y < 0 || f.y >= size.height)
continue;
const uchar* lm_ptr = accessLinearMemory(linear_memories, f, T, W);
// Now we do an aligned/unaligned add of dst_ptr and lm_ptr with template_positions elements
int j = 0;
// Process responses 16 at a time if vectorization possible
#if CV_SSE2
#if CV_SSE3
if (haveSSE3)
{
// LDDQU may be more efficient than MOVDQU for unaligned load of next 16 responses
for ( ; j < template_positions - 15; j += 16)
{
__m128i responses = _mm_lddqu_si128(reinterpret_cast<const __m128i*>(lm_ptr + j));
__m128i* dst_ptr_sse = reinterpret_cast<__m128i*>(dst_ptr + j);
*dst_ptr_sse = _mm_add_epi8(*dst_ptr_sse, responses);
}
}
else
#endif
if (haveSSE2)
{
// Fall back to MOVDQU
for ( ; j < template_positions - 15; j += 16)
{
__m128i responses = _mm_loadu_si128(reinterpret_cast<const __m128i*>(lm_ptr + j));
__m128i* dst_ptr_sse = reinterpret_cast<__m128i*>(dst_ptr + j);
*dst_ptr_sse = _mm_add_epi8(*dst_ptr_sse, responses);
}
}
#endif
for ( ; j < template_positions; ++j)
dst_ptr[j] = uchar(dst_ptr[j] + lm_ptr[j]);
}
}模板也是T间隔滑动后,在采样点位置计算similarity的。这样可以充分使用 Spread T 以及 Restructuring the way the response images S 所带来的便利,使得匹配速度更快。
以上是阅读论文+代码时存在疑惑,记录一下